こんにちは。Deckです。
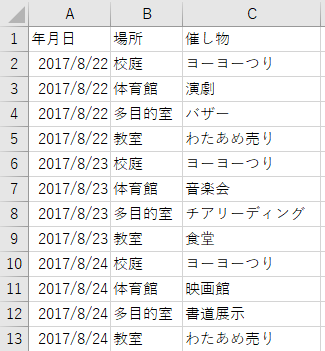
例えばこのようなデータを見てみましょう。
上はとある学校祭の予定ですが、場所や催し物にいくつか重複がありますね。
Qlik Senseを使い、重複する値を取り除いてみましょう。
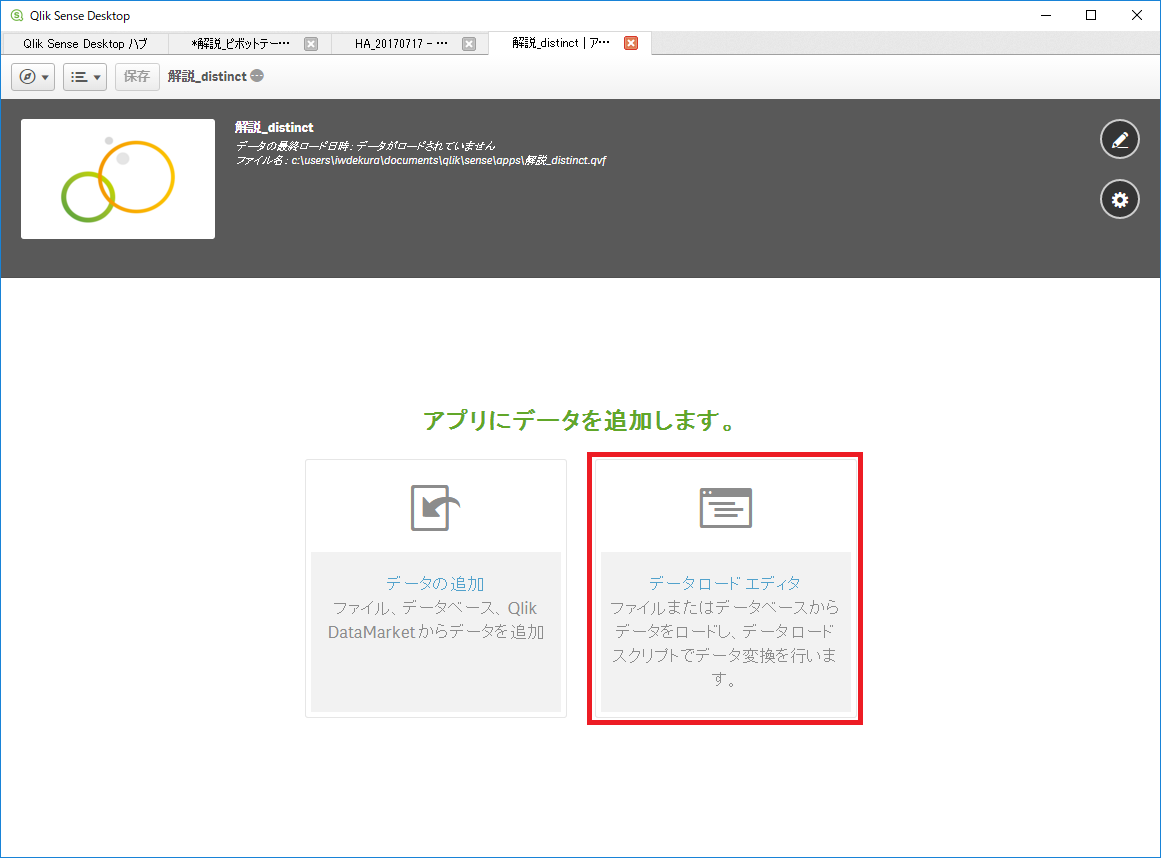
新規アプリを作成し、データ ロード エディタを開きましょう。
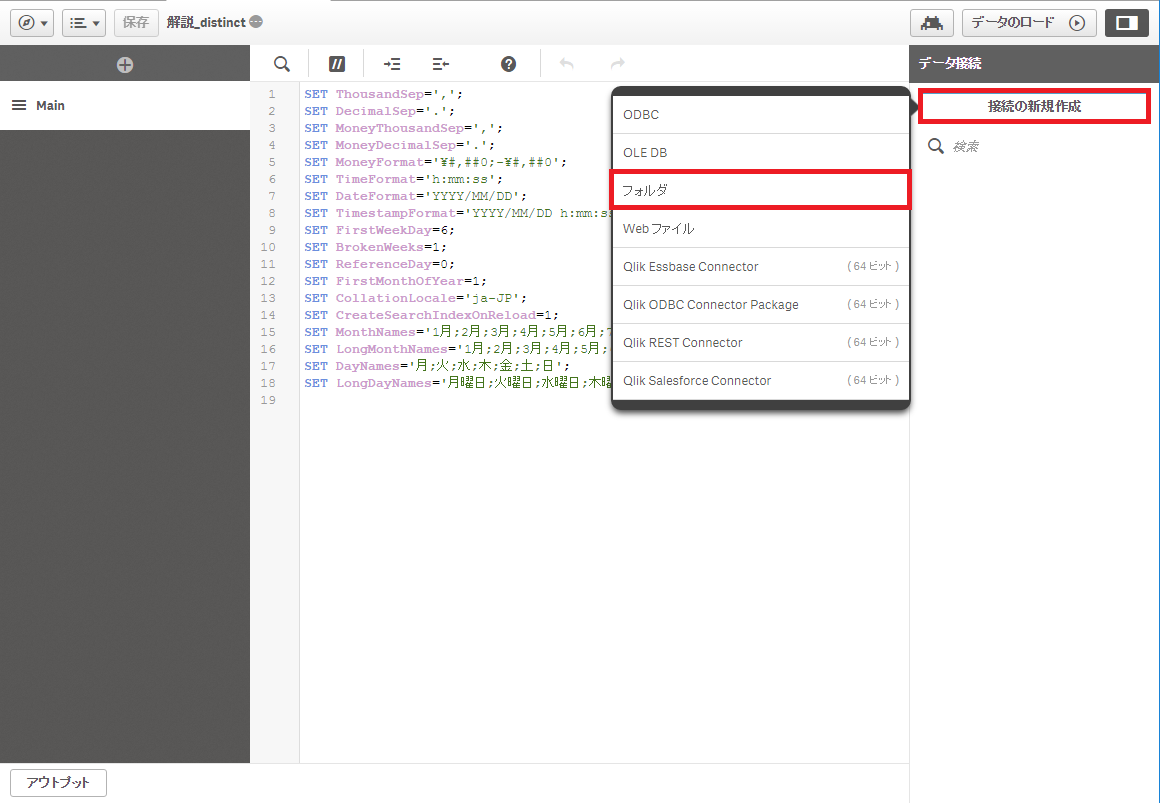
「接続の新規作成」→「フォルダ」をクリックします。
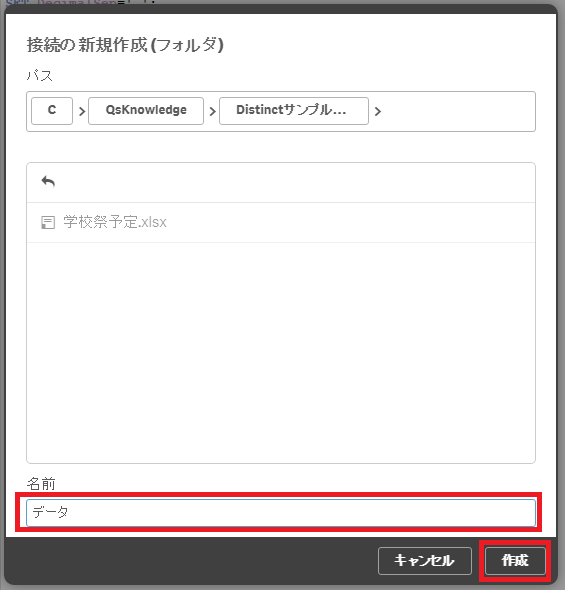
データが入っているフォルダに移動し、接続に名前をつけて「作成」をクリックします。
まず、読み込む項目が1つだけのLOAD文を作ってみましょう。
「データを選択」をクリックします。
読み込むファイルをクリックして「選択」をクリックします。
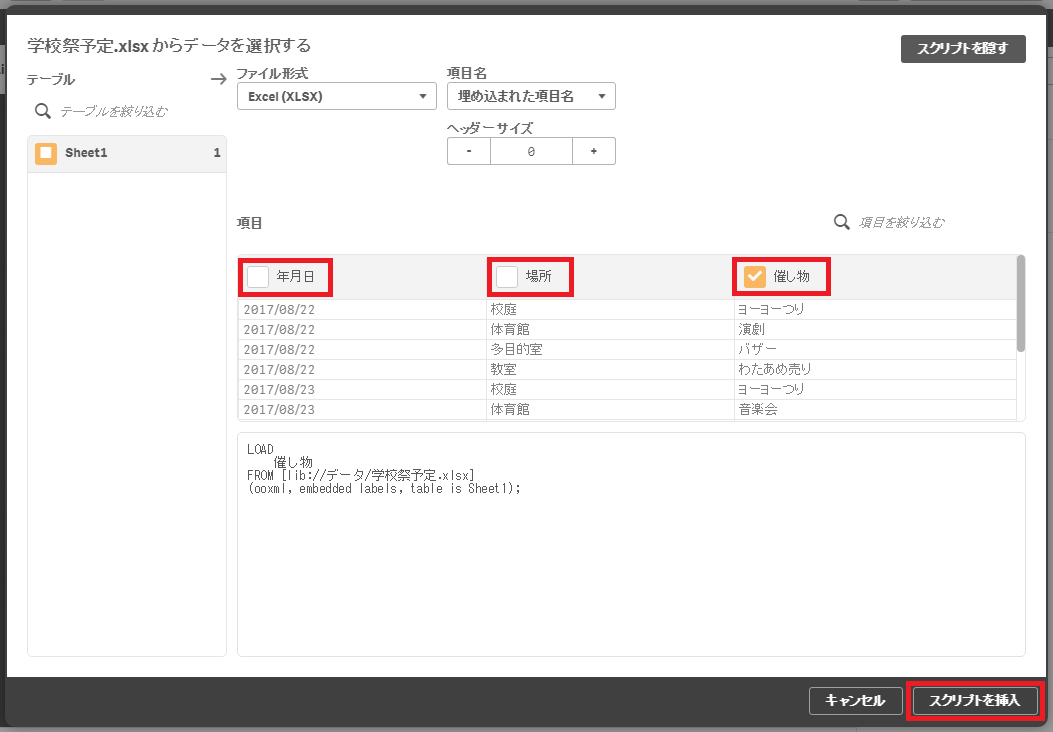
読み込む項目を1つだけに絞ってスクリプトを生成します。
「催し物」のみチェックオンの状態にして「スクリプトを挿入」をクリックします。
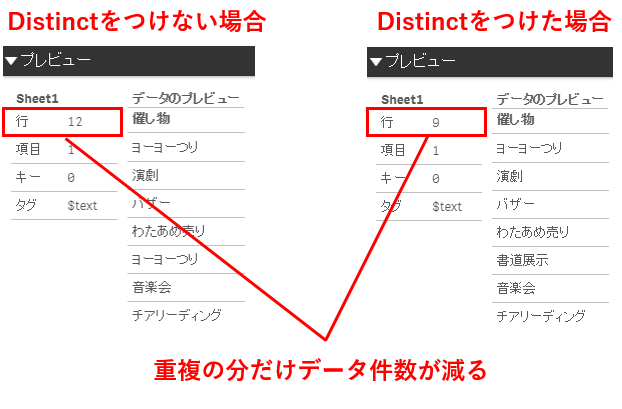
生成されたスクリプトの画像の位置にDistinctを追加します。
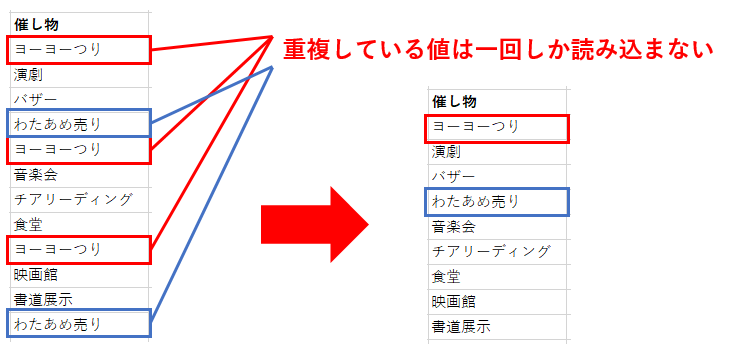
Distinctは重複しているデータをそれぞれ1回のみ読み込みするようにする指定です。
今回のサンプルデータでは取り込みが以下のように行われます。
重複している行は1回だけ読み込まれるため、データ モデル ビューワで確認するとDistinctをつけてロードした場合はとDistinctをつけない場合と比べて件数が異なっていることがわかります。
では、複数の項目を読み込むLOAD文ではどうなるかを見てみましょう。
先ほどのLOAD文を次のように修正します。
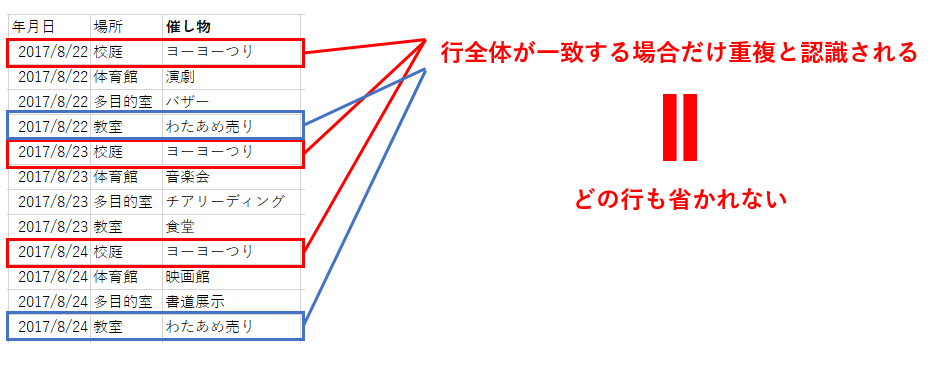
データ ロード エディタでLOADに続くDistinctは読み込まれる項目全体が重複しているかをチェックするため、一部分のみが重複する行は省かれずに読み込みが行われます。
ここまでは「データ ロード エディタ」上での「Distinct」の使い方でした。
続いて「シート上の数式で使われるDistinct」について解説します。
ここからは、「シート上の数式で使われるDistinct」について解説します。
前準備として、ここまでの記事でデータの読み込みを行ったアプリで「テーブル」を作成し、軸に「年月日」「場所」「催し物」を追加しておきましょう。
先ほど作成したテーブルにメジャーを2つ追加します。
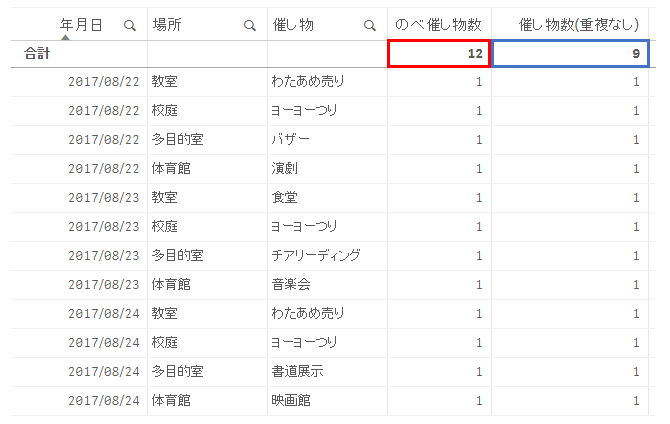
数式中のDistinctによって重複している値は一度しかカウントされずに集計されます。
結果は以下のようになります。
重複をカウントするかどうかで集計結果が異なっていますね。
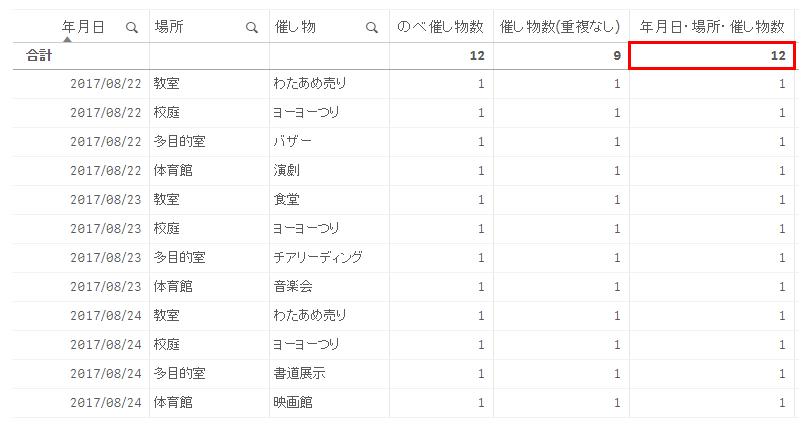
ここまでの解説では「催し物に被っているものがあるかどうか」に注目していましたが、今度は「年月日・場所・催し物すべてが同じ行があるか」の数式を組み立てます。
テーブルにメジャーを追加します。
集計を実行すると結果は以下のようになります。
メジャー③では年月日・場所・催し物がすべて重複するかどうかをチェックするため、集計結果はメジャー①の重複チェックを行わないものと同じになりました。
この記事は、以上となります。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}