こんにちは。Turtleです。
最近、天気の変動が激しいですね。晴れたと思ったら急に雨が降ってきたり、雨が降ったと思ったら1時間後には快晴になっていたり...とてもじゃないがついていけない。
こういった状況なのでiPhoneの天気は良く見るのだが...iPhoneの天気って見ていて楽しいよね。同じような天気でも微妙にバックグラウンドが違ったりする工夫や、綺麗な演出を見るのが好きで、ついついiPhone天気で世界旅行してしまうのはぼくだけでしょうか。
話を本題に。今回は、標準偏差を求めるSTDEV・STDEVP関数を紹介し、そのあとにそれを用いて偏差値を算出していく。実際の業務で偏差値を求めることはなかなかないと思うのだが、たまには慣れないことをするのも良いことだよね。笑
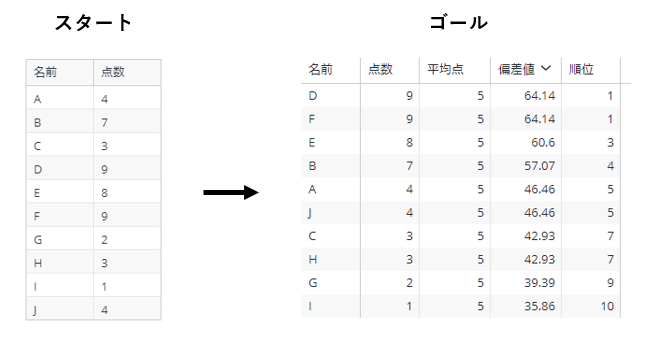
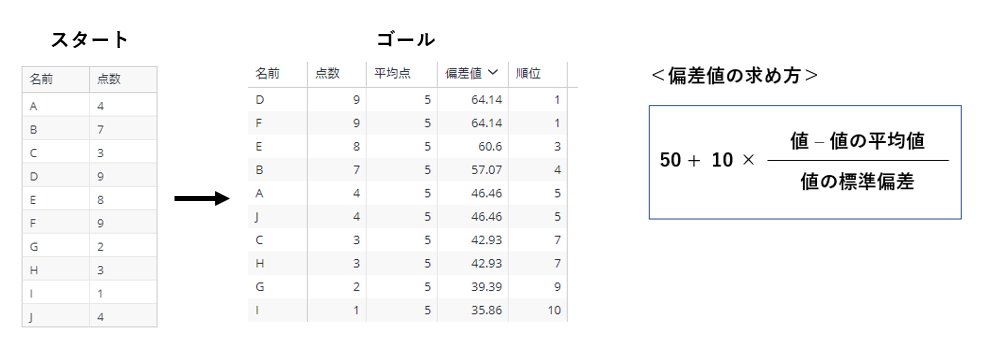
今回やりたいことは下図の通り。
A~Jの10人に対し、10点満点のテストを実施した。その結果を記録した「名前」「点数」のカラムがあるデータ(母集団データ)を使い、「平均点」「偏差値」「順位」の3つを新たに算出したピボットウィジェットを作成する。
「なんだ、そんなことか」と思ったそこのあなた!それぞれどの関数を使えば良いか分かっていても、Sisense独特の記述の仕方があるために苦労するかもしれないよ...とだけ伝えておきます。笑
「平均点」「順位」は分かるけど、「偏差値」ってどうやって算出するんだっけ?って思う方もいると思われるので、以下に算出方法を載せておく。「偏差値」は以下のように算出する。
数式を見ると、新たに「標準偏差」というものが登場した。そうすると、次は「標準偏差」ってどうやって算出するんだっけ?という問いが新たに浮上してくる。先ほどのように数式でさらっと記述してもいいのだが、「標準偏差」の算出には「分散」「偏差」についても知っておく必要があるので、ここでまとめて触れておく。
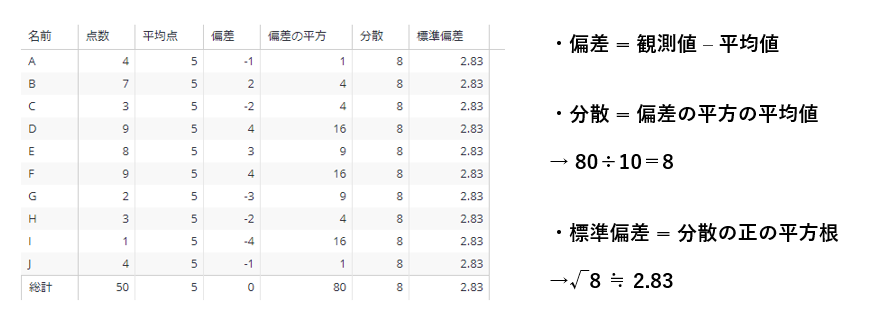
せっかくなので、先ほどのデータを使って見ていきたいと思う。下のピボットは、数式エディタで数式を書いてそれぞれ「偏差」「偏差の平方」「分散」「標準偏差」を算出したものだ。
少し長くなるのでSisenseの数式については割愛させていただく。気になる方は是非試してみてほしい。なお、「標準偏差」については後ほど紹介する。
・偏差(観測値 - 平均値)
各観測値から平均値を引いたもの。
・分散(偏差の平方の平均値)
偏差の平方(2乗した値)の平均値のこと。
・標準偏差(分散の正の平方根)
標準偏差の平方根のうち、正のものを指す。
ひとつひとつ「偏差」「分散」「標準偏差」と順番に見ていくと、求め方はそれほど難しくないことが分かる。それを踏まえた上で、「では、Sisenseは標準偏差を求める際に今のように順番に出していかなくちゃいけないの?」と思うのは自然な流れだと思う。
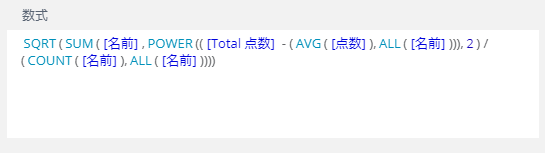
もちろん、数式を今のように「偏差」→「分散」→「標準偏差」という流れで計算していくように書けば求めることはできる。できるのだが...
こうなる。(もしかしたらもう少し簡単に書けるのかもしれないけど...ちなみに、ピボットだから長くなっているという点は大いにある)
さすがに標準偏差を算出するのにこんなに長い数式を書くのはちょっと躊躇うよね。「標準偏差でこれなら偏差値を算出する数式はどれだけ長くなるんだ...?!」となる。
安心してほしい。Sisenseには標準偏差を求める関数が存在する。それが、STDEV・STDEVP関数である。馴染みのない方にとっては、「こんなのあったの?」と思ってしまう関数ではないだろうか。(ちなみに、ぼくもほとんど使ったことはない)
STDEV(<数値>)
所定の値の標準偏差(標本)を返す
STDEVP(<数値>)
所定の値の標準偏差(母集団)を返す
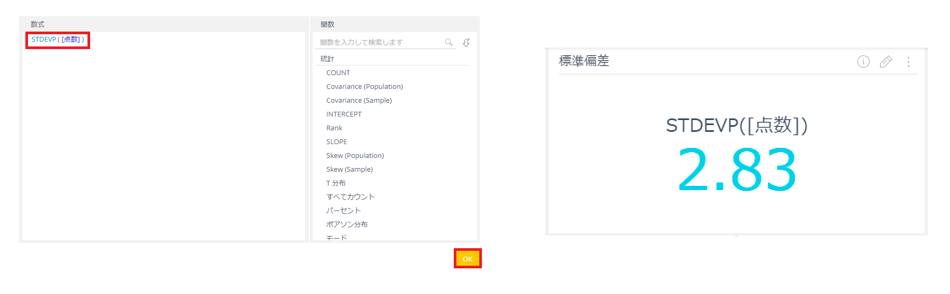
ご覧の通り、使い方はまったく難しくない。試しに、インジケータで値に STDEVP([点数]) と入れたものを作成してみるとわかるように、簡単に標準偏差を算出することができる。
なお、今回取り扱うデータは母集団データという設定なので、STDEVではなくSTDEVPを使用している。
さて、標準偏差についての確認が終わったところで、冒頭で確認したピボットウィジェットの作成に入る。おさらいとして、今回のスタート & ゴールと偏差値の求め方を再掲しておく。
標準偏差がSTDEVPで簡単に求められるようになったので、偏差値の算出もそれほど難しくはないはずだ。まずは自分で数式を書いて、ゴールのピボットウィジェットが作成できるよう試してみてほしい。
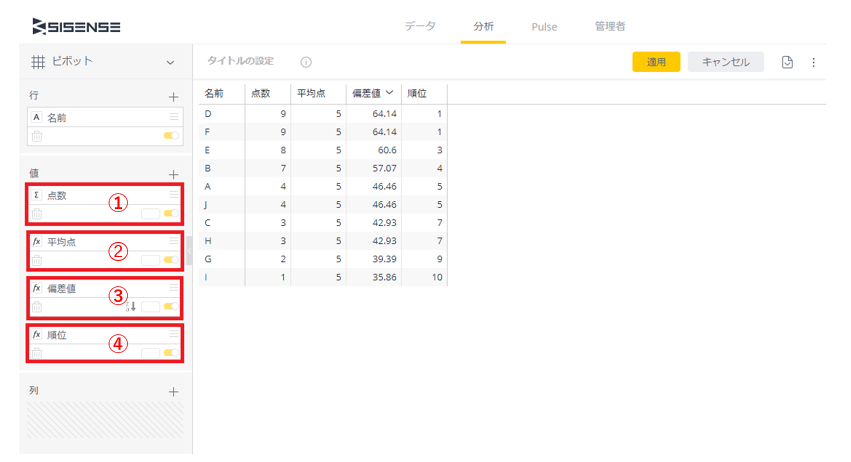
...できたでしょうか。それでは答え合わせといきますか。行の「名前」以外の4つについて見ていく。
①点数
答え:SUM([点数]) ※SUMではなくAVGやMAX/MINなどでも可
値 に入れるものは必ず何らかの計算を伴う必要があるため、ここではSUMを用いている。名前と点数が1:1なので、集計関数を使っても値は元データと同じものが表示されるため問題はない。ちなみに、ここで行 に点数を入れると、その他がうまく表示されなくなってしまう。
➁平均点
答え:(AVG([点数]), ALL([名前]))
先ほど少し触れたが、ここでそのままAVG([点数])と入れてしまうと、それぞれの点数がそのまま表示されてしまう(平均を算出する集合が1人だけだから)。そのため、全体の平均を算出するためにALL関数を使用している。全体平均の算出については、【Formula】~ごとの平均、最大、最小ってどうやって求めるの? で詳しく書かれているので、こちらを参照されたい。
③偏差値
答え:(SUM([点数]) - (AVG([点数]),ALL([名前]))) *10 / (STDEVP([点数]),ALL([名前])) + 50
ここでいよいよ偏差値の登場。基本的には算出式に代入していくだけでOK。平均点((AVG([点数]),ALL([名前])) の部分)と標準偏差((STDEVP([点数]),ALL([名前])) の部分)はどちらも「全体の」平均点及び標準偏差でなければならないので、ALL関数を使う必要があるということが分かっていれば問題なく算出できると思う。
④順位
答え:RANK([Total 点数],"DESC")
今回は点数が高い順にランキングをつけていくので、"DESC"と記述する必要がある。RANK関数についてはこちらを参照されたい。
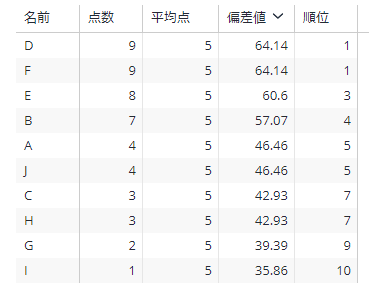
これで、目的物の完成!
今回は、STDEVP関数を使って標準偏差、および偏差値を求めた。なんだか、ピボットとALL関数についての記事のような気がしないでもないが...(笑)
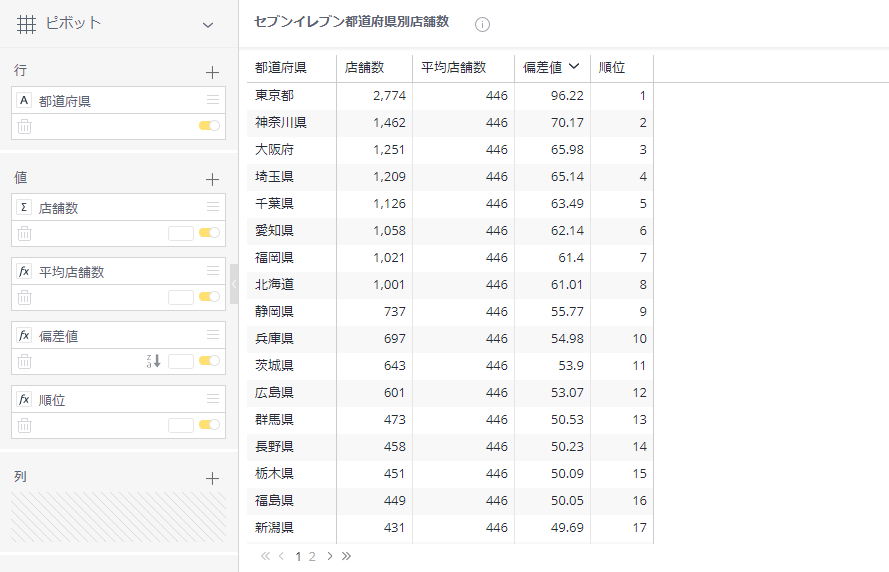
同じような求め方で、セブンイレブンの店舗数の偏差値を算出してみた。(各都道府県の店舗数については、セブンイレブン「国内都道府県別店舗数」を参考にさせていただきました)
こうしてみると、東京がやはりずば抜けているが、それよりも、ぼくの出身地である北海道が8位と思ったより奮闘していることに驚いた。とはいえ北海道となるとさすがに広すぎるので、面積で割って算出してみると結果はまた変わってきそう...
ちなみに、ぼくは「蒙古タンメンのカップ麵を売っている」「杏仁豆腐が美味しい」という理由でセブンイレブンが好きです。(何の情報)
...それでは。(笑)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}