この記事は、【Sisenseはじめの一歩】の第3回の記事です。 目次はこちら。
こんにちは、Sato-Gです。
「Sisenseはじめの一歩」第2回では、ElastiCubeをWeb Data Designerで作成した。今回は、前回の内容を復習しつつ、カスタムフィールドを作成しデータモデルを完成させたいと思う。
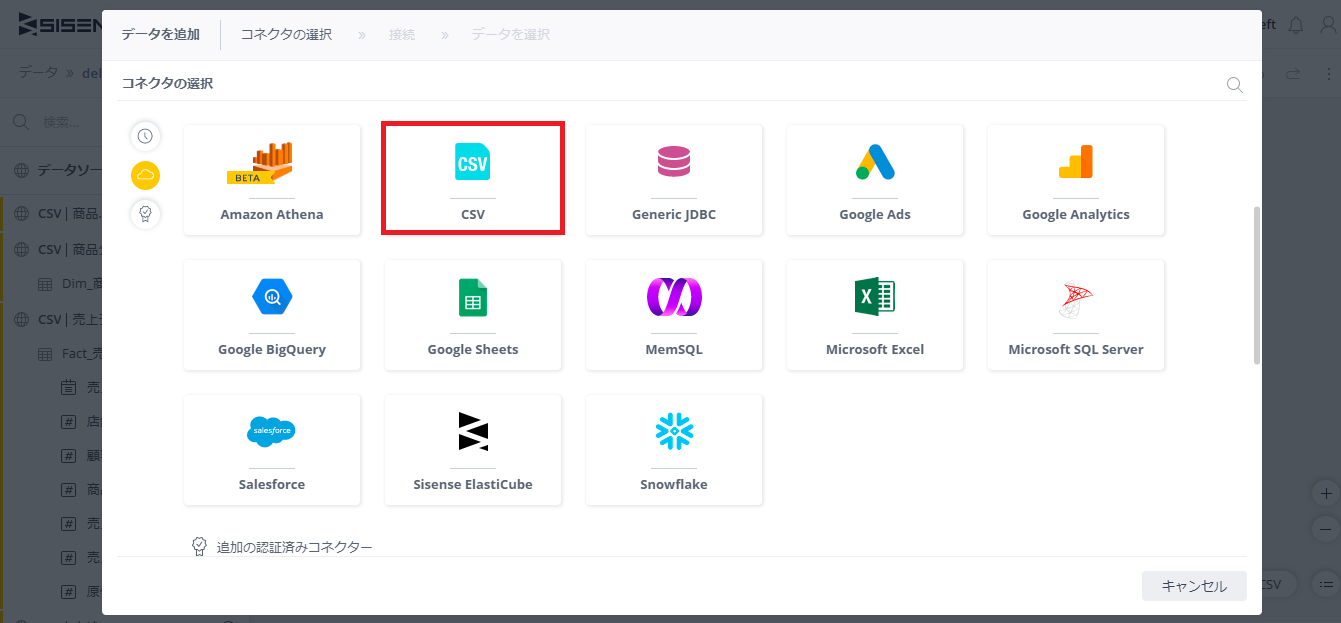
ElastiCubeのメニューから + データ を選択し、CSVを指定する。
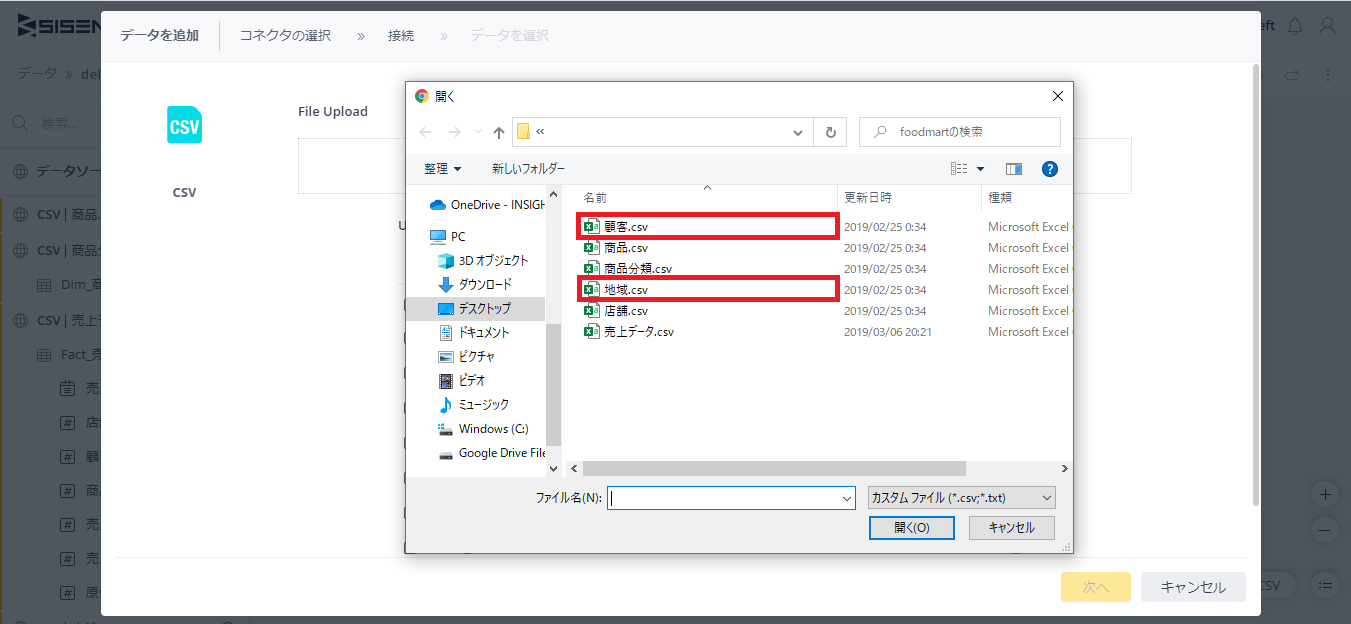
まだ取り込んでいない「顧客.csv」「地域.csv」の2つのCSVファイルを追加する。まずは「顧客.csv」。
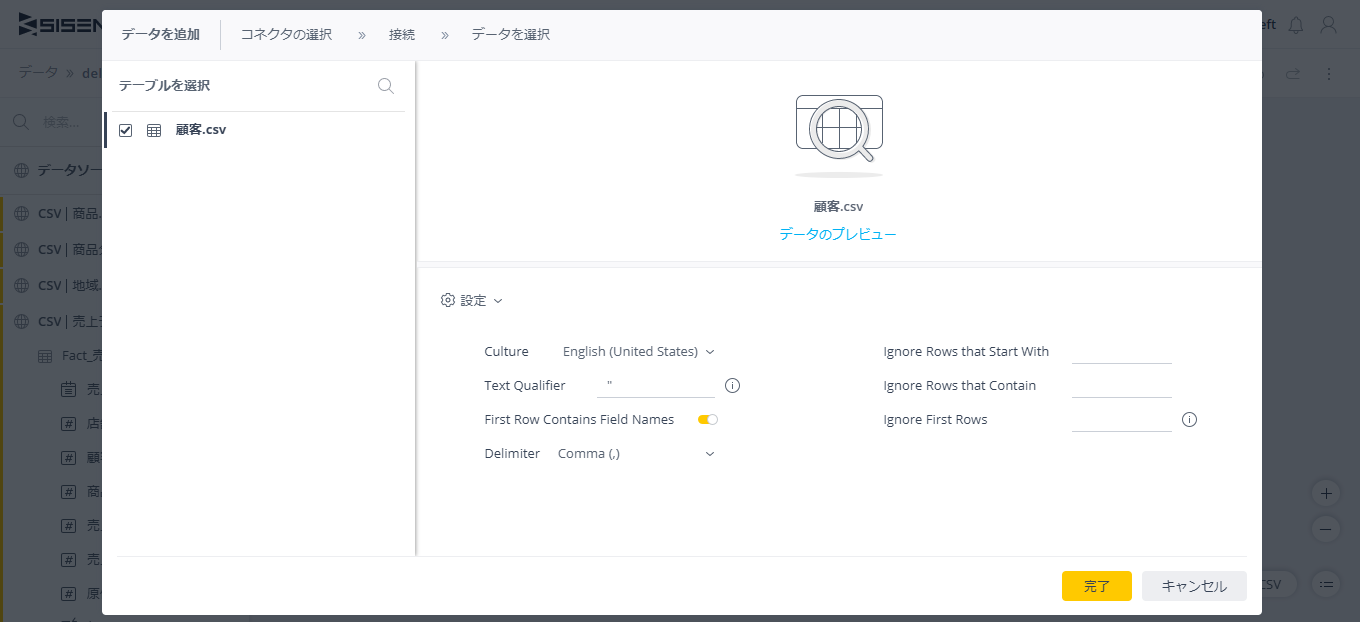
ファイルを選択すると、下記のような画面が表示される。前回の復習として、簡単な説明を再度載せておく。
・Culture: 国固有の表記に対応(おそらくここはデフォルトで問題ない、JapaneseにするとGMT +9:00の表示になって紛らわしかった)
・Text Qualifier: テキストのダブルクォート括りなどの設定
・First Row Contains Field Names: 1行目をフィールド名とするかの設定
・Delimiter: 区切り文字の設定(今回はCSVなのでカンマ区切り)
・Ignore…: 読み込まない行の設定(Ignore First Rowsの場合は何行目から読み込むかを設定できる)
設定が完了し、[完了]ボタンをクリックすると、「顧客.csv」テーブルが追加される。
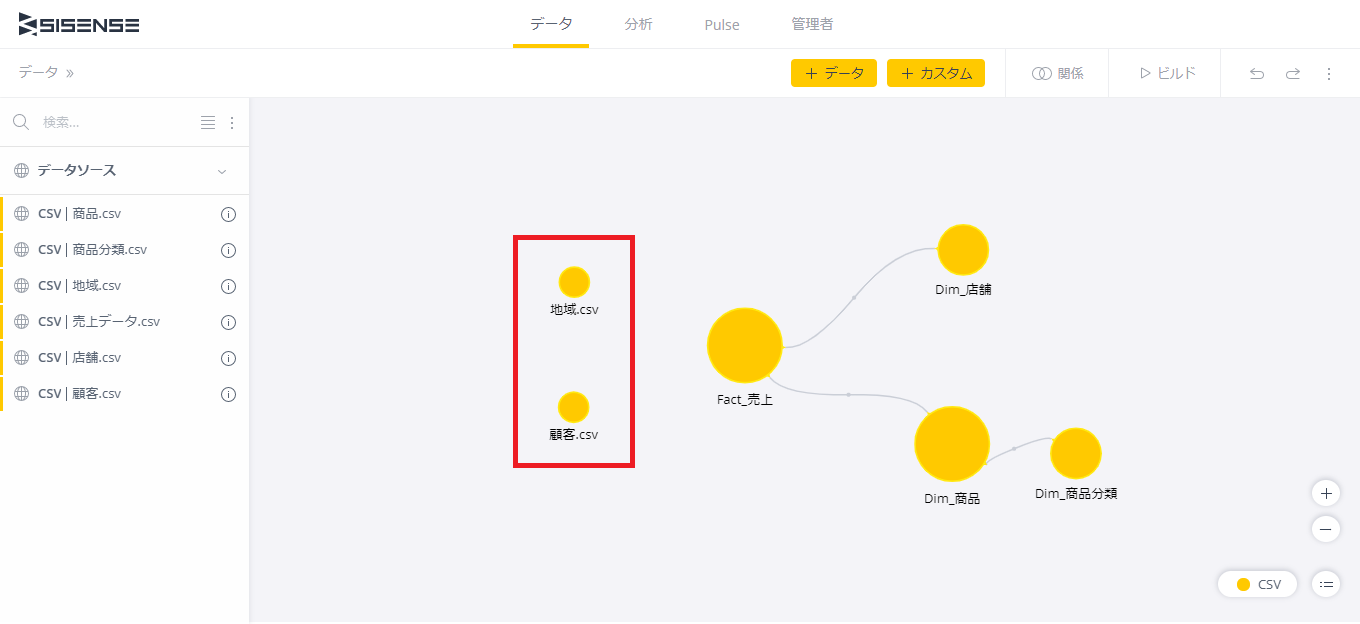
さらに「地域.csv」データも「顧客.csv」と同様に設定を行い、追加する。
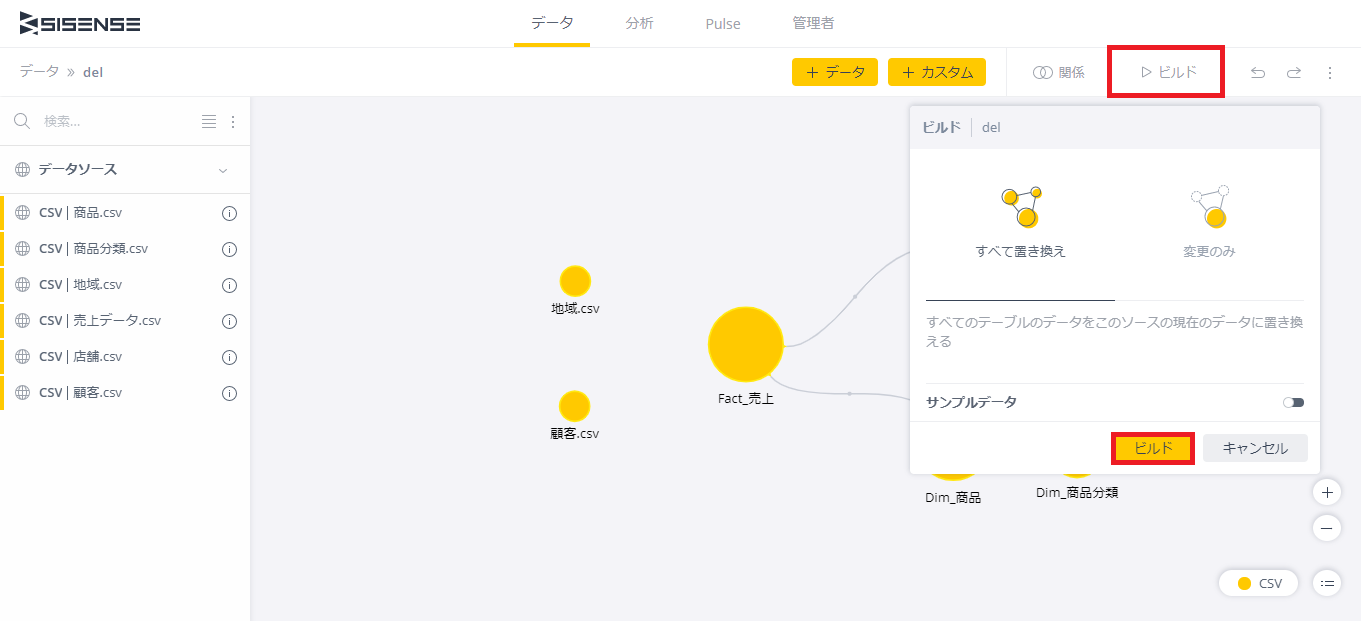
「ビルド」アイコンをクリックし、「すべて置き換え」に設定してビルドを実行する。
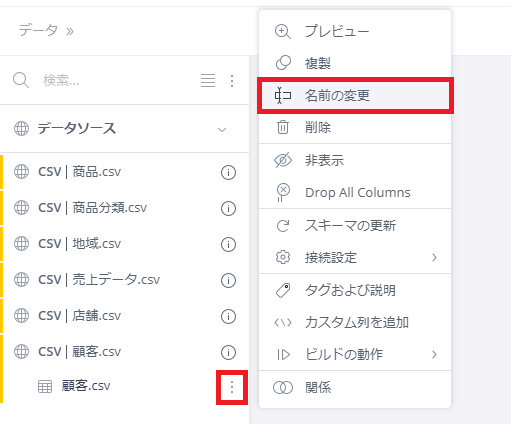
・テーブル名の変更
まず、テーブル名を変更する。テーブル名の右をクリックすると、上部にメニューアイコンが現れる。「名前の変更」を選択してテーブル名を変更する。
「顧客.csv」→「Dim_顧客」
「地域.csv」→「Dim_地域」
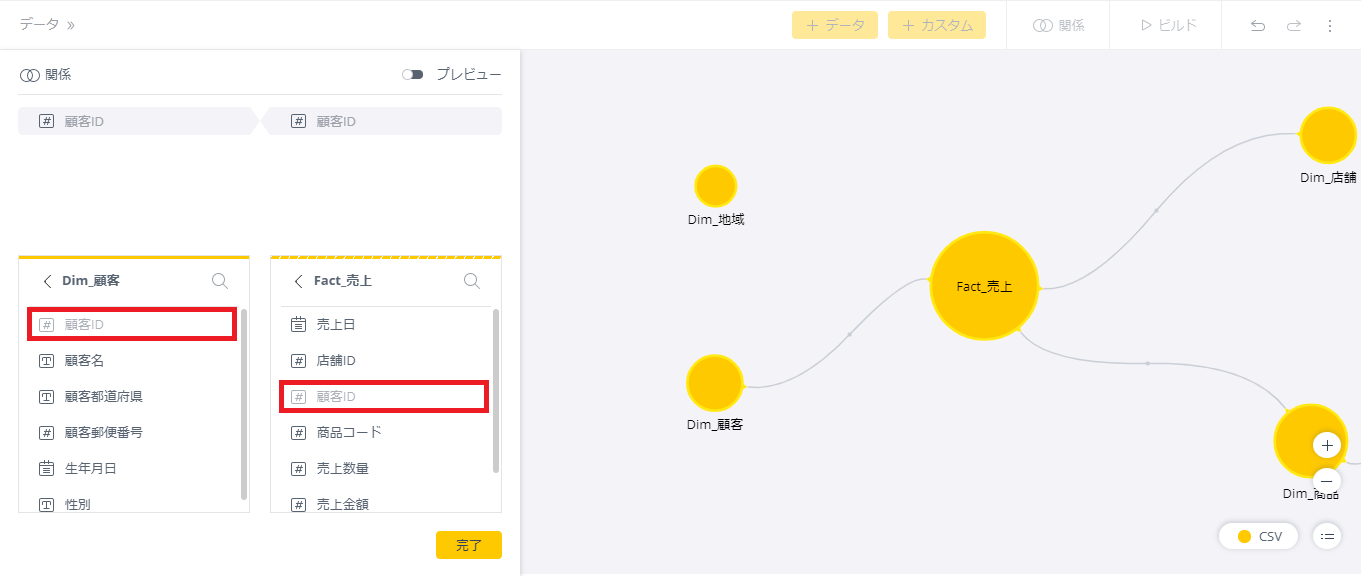
・リレーションシップの設定
「Dim_顧客」テーブルを選択し、「Fact_売上」テーブルにドラッグし、両テーブルの「顧客ID」をキーにしてリレーションを設定する。
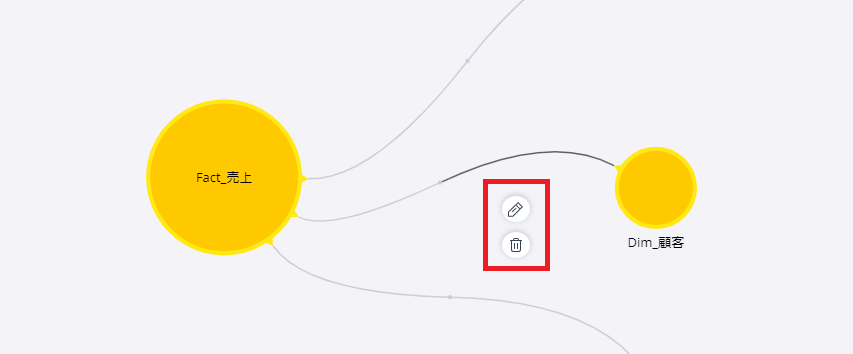
もし誤って繋いでしまった時は、下記のように繋いだ線をクリックすると「エンピツ」アイコンと「ゴミ箱」アイコンが出てくるので、クリックして編集・削除し、再度結合し直す。
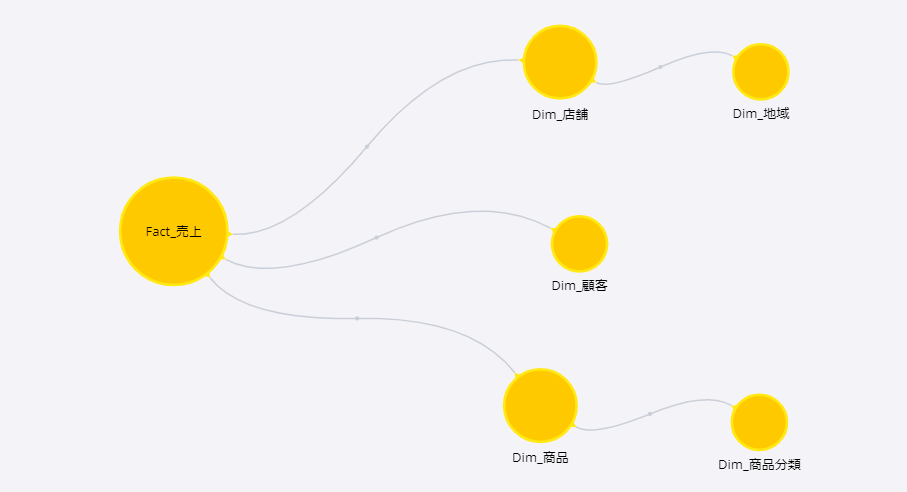
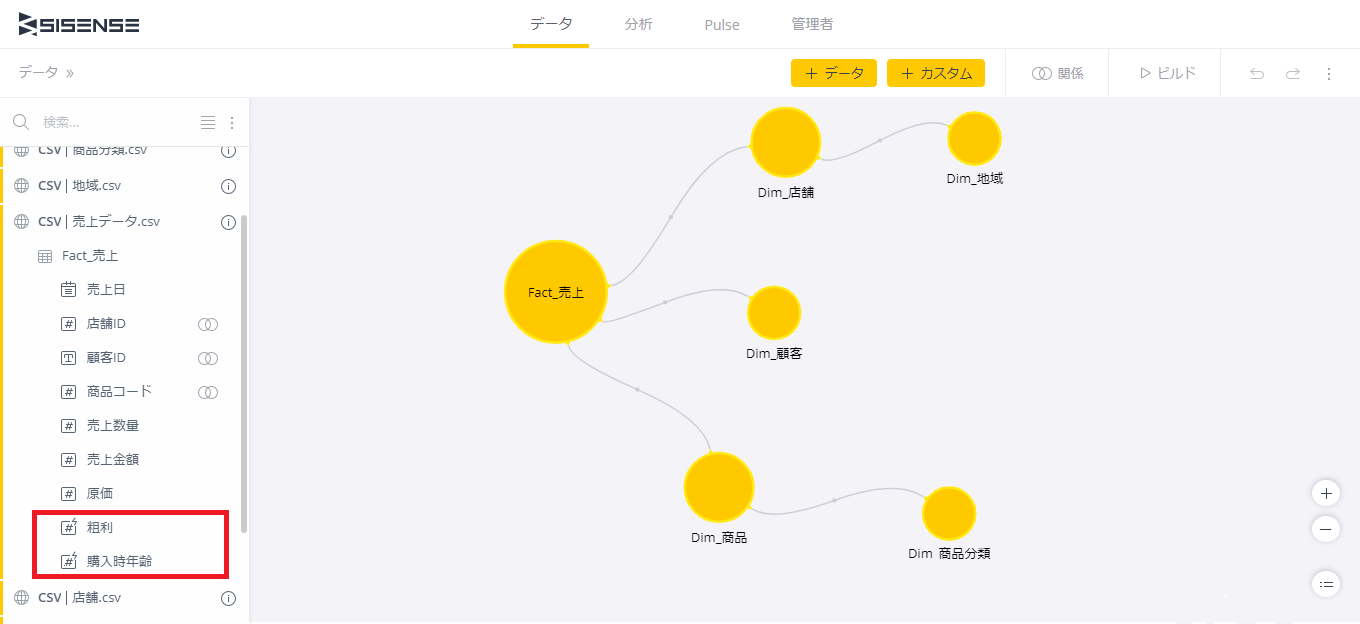
これで、取り込むデータ全てのデータモデルが一旦完成した。ファクトテーブルである「Fact_売上」を中心し、3系統のディメンションが繋がるスタースキーマモデルになっている。
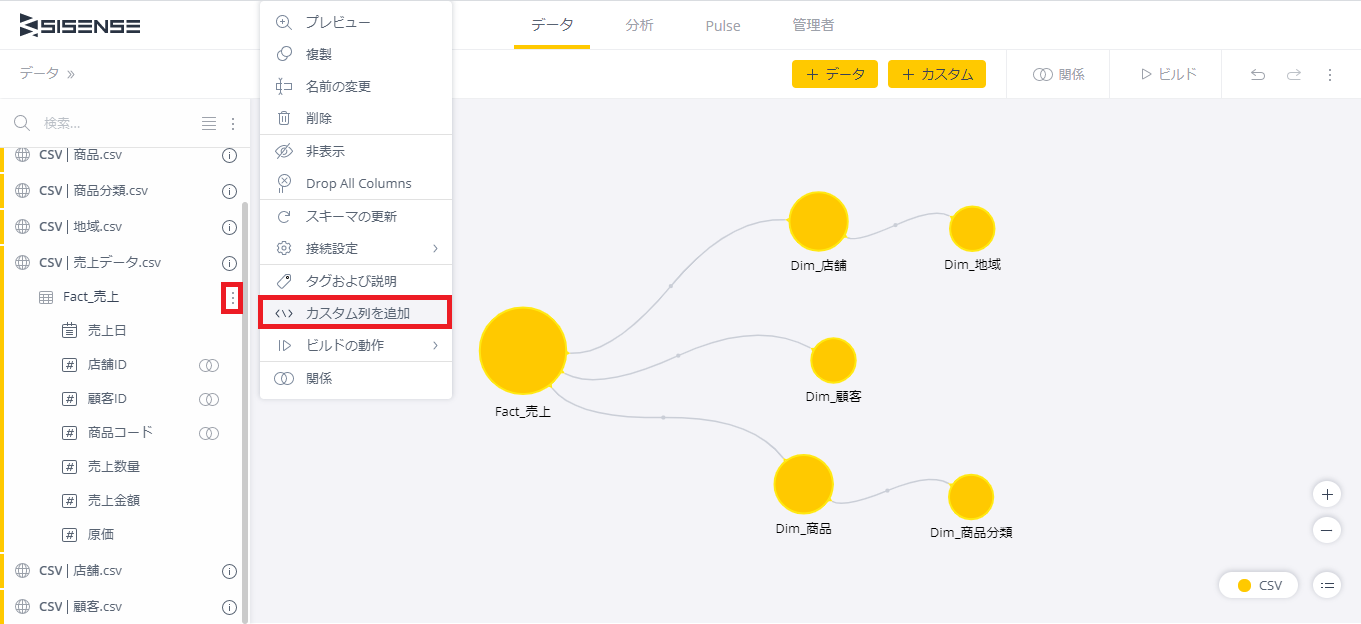
・「粗利」の追加
Sisenseでは、テーブル内に「カスタムフィールド」という、計算式で作成するフィールドを作成することができる。
テーブルの右をクリックしてメニューを表示し、「カスタム列を追加」をクリックすると自動で数式エディタが開く。
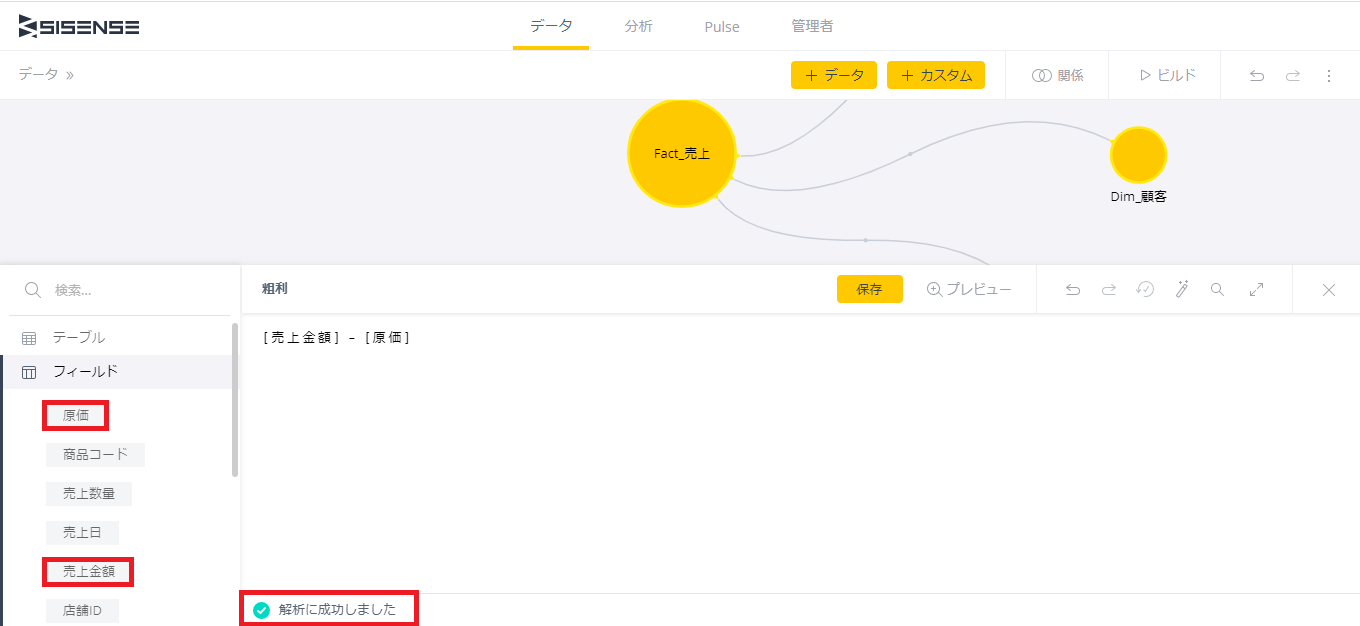
タイトルを「粗利」に変更し、左側の「フィールド」からフィールドを選択しながら、[売上金額] - [原価]と入力する。数式のチェックは自動で行われ、エラーがなければ左下に「解析に成功しました」と表示される。
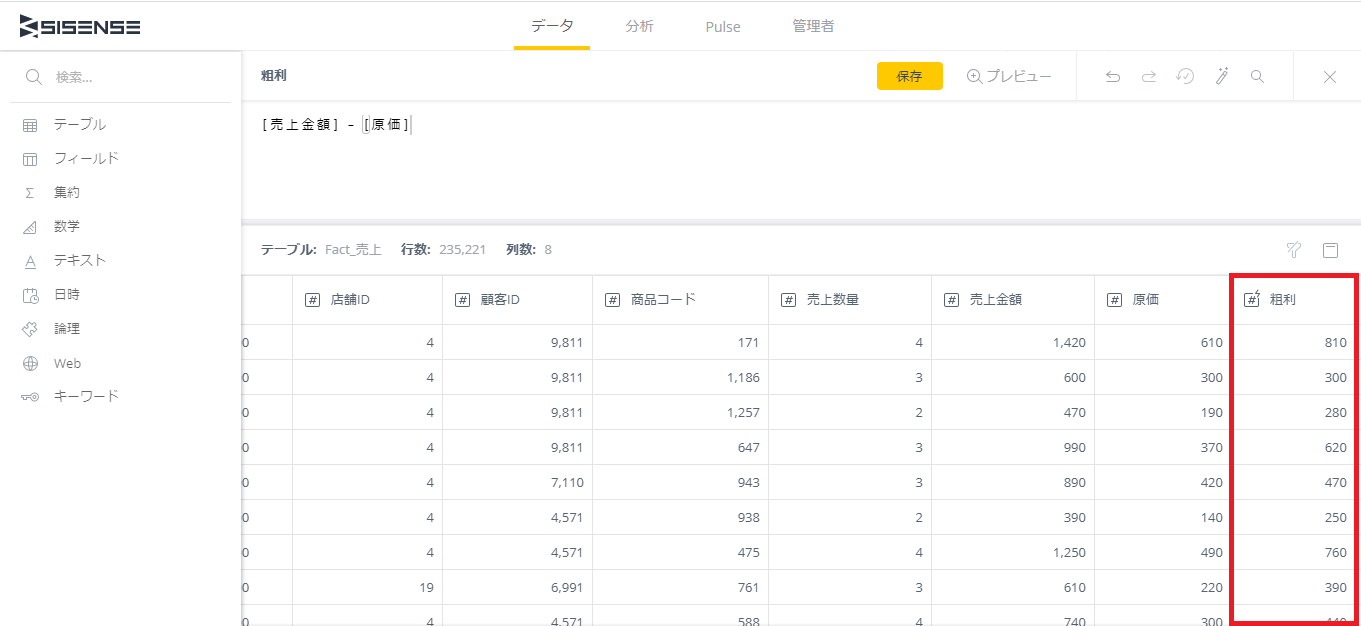
右上の「プレビュー」ボタンで結果をプレビューする。
エディタの下にプレビューが表示される。ここでは「粗利」というフィールドが追加され、「売上金額」から「原価」を引いた金額が正しく表示されていることを確認できる。
・「購入時年齢」の追加
「Dim_顧客」テーブルには「生年月日」フィールドがあるため、年齢を求めることができるが、いつを基準に年齢を計算すればよいだろうか?現在の年齢という視点もあるだろうが、顧客にとっては売上があった時点で年齢が異なるため、売上日と生年月日から「購入時年齢」を求めたい。
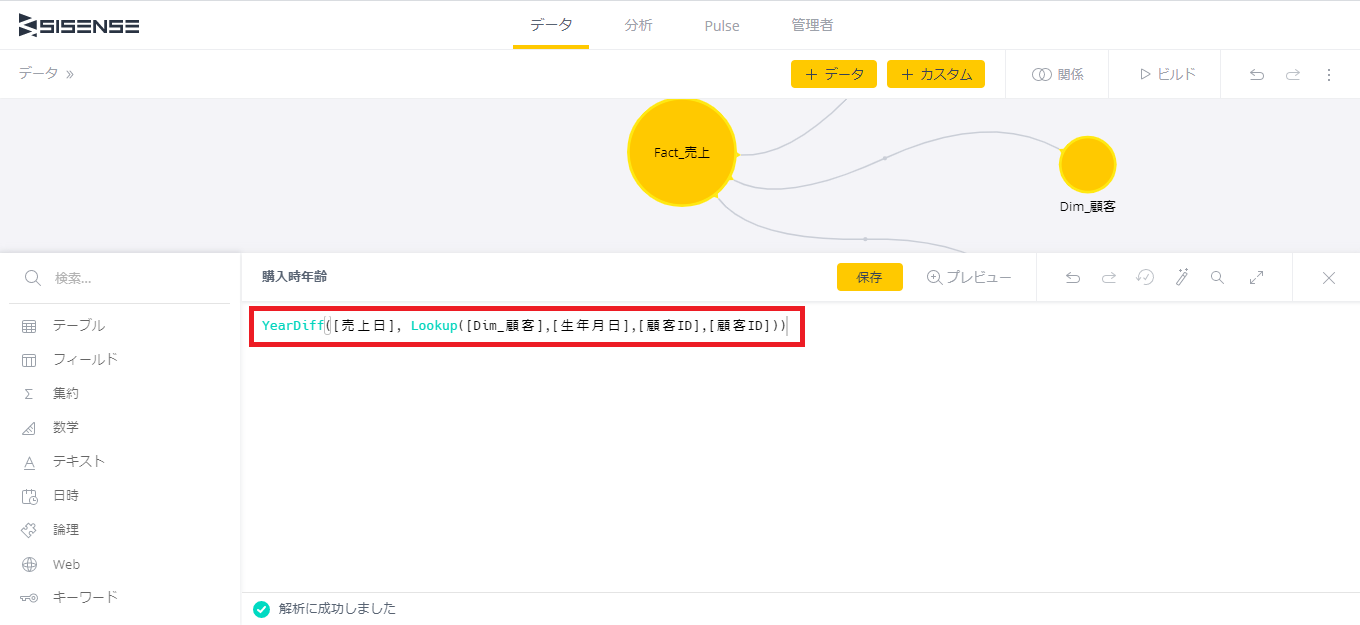
「Fact_売上」に上と同じ方法で「購入時年齢」というカスタムフィールドを追加する。
数式では
YearDiff([売上日], Lookup([Dim_顧客],[生年月日],[顧客ID],[顧客ID]))
と入力する。
YearDiffとLookupという2つの関数が使われているが、関数の使い方はそれぞれ以下のとおりである。
YearDiff(end,start)
startからendまで何年かを求める。ここでは生年月日から売上日までの年数を算出する。
LOOKUP(remote_table,remote_result_column,current_match_column, remote_match_column)
ExcelのVLOOKUP関数のようにキーフィールドを使用して別テーブルから参照したい値を取得する。ここではDim_顧客テーブルから、顧客IDをキーとして、生年月日を取得するよう設定している。顧客IDが2つ指定されているが、最初の顧客IDはFact_売上の顧客IDで、後の顧客IDはDim_顧客の顧客IDである。
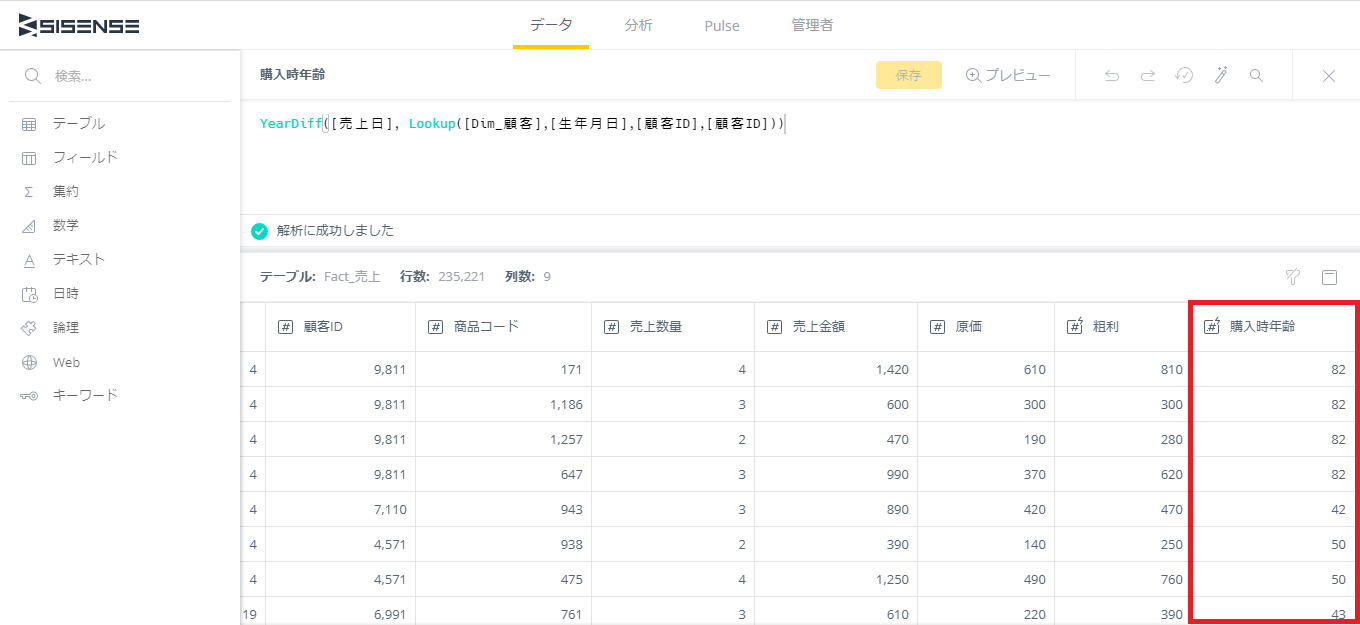
数式の結果は下記のようにプレビューされる。
最後に「ビルド」を行い、以下のように完成すればOK。
第2回、第3回と簡単なデータモデリングをご紹介してきた。ここで使用したデータは非常に扱いやすいデータにしてあるので、実際の場面ではこう簡単にはいかない。もっと数式を使用してカスタムフィールドを作成したり、SQLを使用してカスタムテーブルを作成する必要も出てくるだろう。ただ、Sisenseは複雑なデータモデルでも比較的簡単に構成できることは、ご覧いただいた通りだ。
次回は、いよいよダッシュボードの作成をご紹介したいと思っているので、乞うご期待。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}