Qlik Senseでの「分析しやすい」データ構造とは、ズバリ次の2つの条件を満たすものと言えます。
1については言うまでもありませんね。
データ構造がQlik Senseで扱うことができないと分析が立ちいかなくなってしまいます。
そして2も重要です。
データの集計自体を行うのはQlik Senseの役目とはいえ、その仕組みを作るのは人間です。
その両方のバランスをとってこそ「分析しやすい」データ構造を作ることができます。
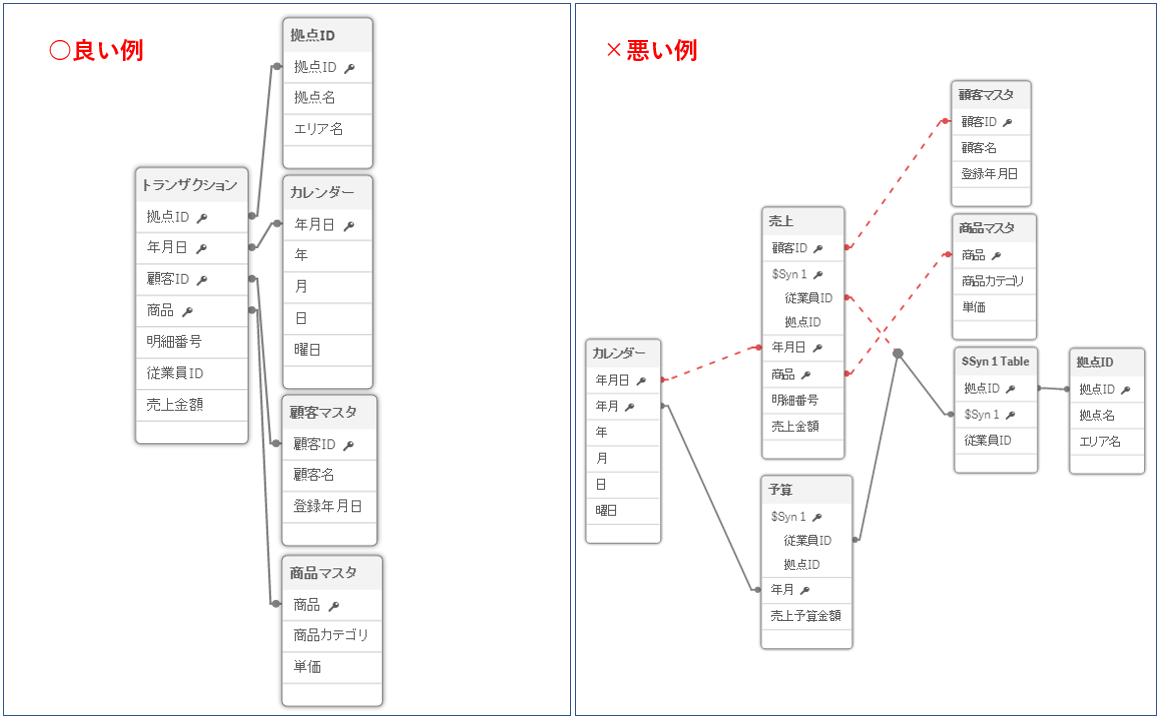
「分析しやすい」データ構造と「分析しにくい」データ構造の例を挙げると、例えばこうなります。
上はちょっと極端な例ですが、「分析しやすい」データ構造のほうがよりスッキリしていることがわかると思います。
良い例であるデータ構造は次のようなルールに従って作られています。
それぞれについて、改善点を図で説明しながら解説します。
データ構造の中心と言えるファクトテーブルはトランザクションテーブルとも呼ばれ、売上明細や販売計画など「何が起こったか」「何をする予定か」、いわゆる時系列に従ったデータを表します。
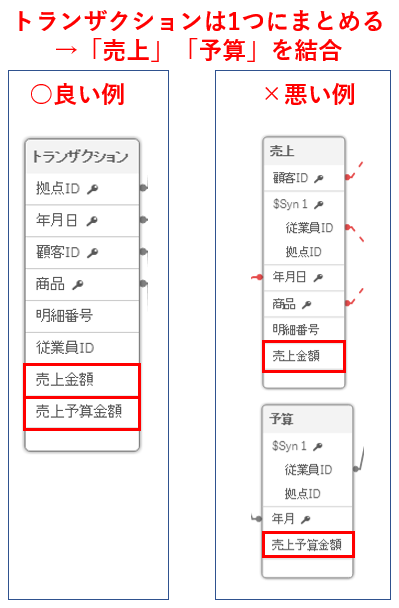
ファクトテーブルを複数取り込むことになった場合、それらは連結によって1つにまとめることが望ましいです。
マスターテーブルはファクトテーブルから参照するためのテーブルです。
「年月日から曜日を取り出す」、「複数の商品をカテゴリにまとめる」など用途に沿ったテーブルを用意しましょう。
上の例で問題になっているのはファクトテーブルが「売上」「予算」の2つに分かれたまま取り込んでいることです。
テーブル同士の関連付けは1つ項目のみで紐づくことが望ましいです。
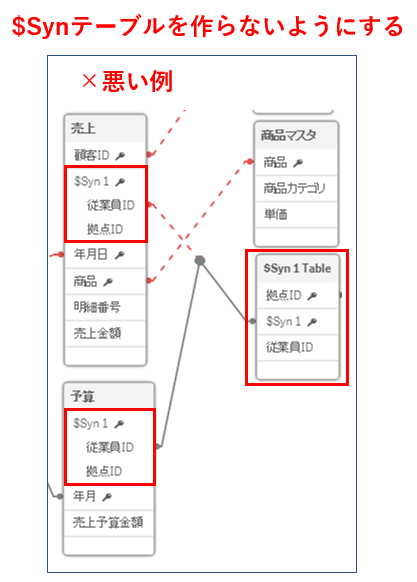
Qlik Senseではテーブルの関連付けが多対多で紐づくことはできませんが、このような場合は自動的に「$Syn」テーブルによって多対多の関連付けを解消してくれます。
ただし、本来ならば不必要な「$Syn」テーブルがあることで構造がややこしくなりますし、あまり多くの「$Syn」テーブルがあるとパフォーマンスにも悪影響があります。
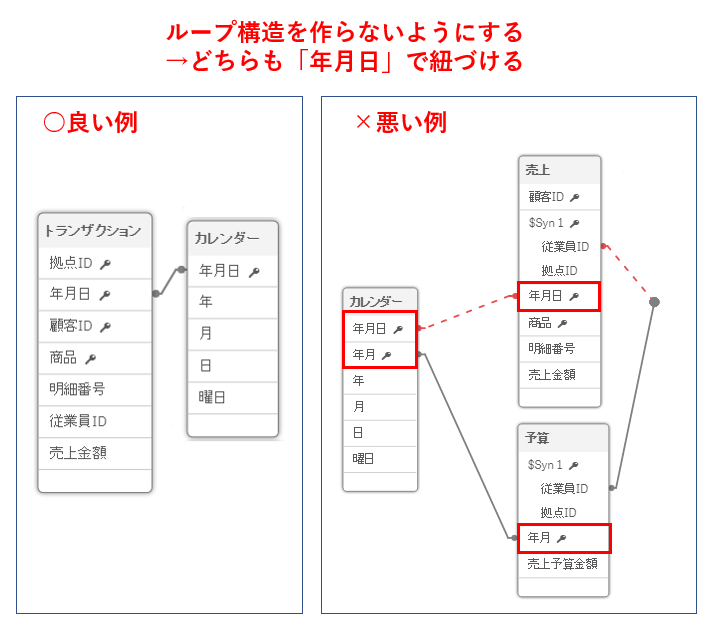
このように関連付けがループするとテーブルを跨いだ集計時にルートが定まらないため関連付けが切られてしまいます。
図の赤い点線の部分は疎結合と呼ばれ、関連付けを利用することができません。
ループのあるデータ構造では集計時に予想外の結果が生じる可能性もあります。データ構造にループを発生させないように心がけましょう。
上に書いたポイントに従ってデータ構造を構築すれば、テーブル数が増えたとしてもモデルが破綻することはないでしょう。
次回からの記事では、
を解説します。
「分析しやすいデータ構造を作るテクニック【テーブルの関連付け】」はこちら
{kind=link}
{kind=link}
{kind=link}
{kind=link}