ログインを行うとコンソール画面が開かれ、アカウント登録が完了します。
今回はODBCで接続します。
(サポートしているOSや詳細情報などは公式ガイドを参照。)
|
Data Source
|
名前。自由に設定可能 |
|
User
|
SnowflakeのログインID
|
|
Password
|
Snowflakeのログインパスワード
|
| Server |
Snowflakeのコンソール画面のURL
|
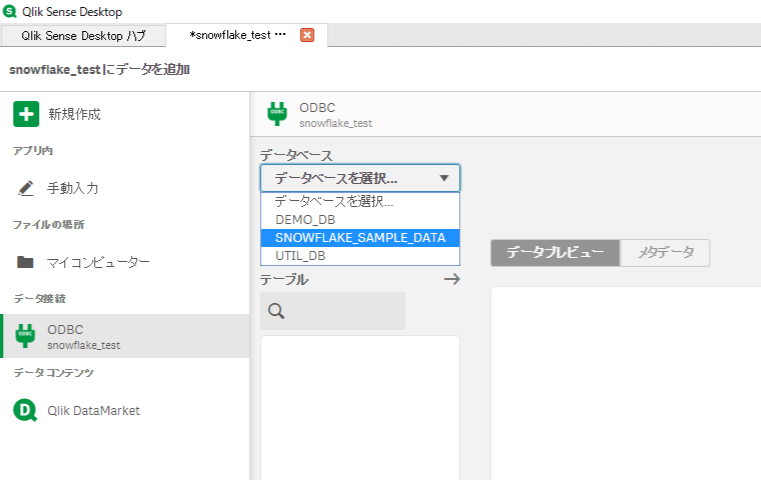
Qlik Senseから作成したデータソースを利用してSnowflakeに接続します。
|
Database
|
SNOWFLAKE_SAMPLE_DATA |
|
Schema
|
TPCH_SF10000
|
|
行数
|
150億件 |
|
サイズ
|
516GB
|
ロードスクリプトエディタを開き、以下のように記入します。
SET ThousandSep=',';
SET DecimalSep='.';
SET MoneyThousandSep=',';
SET ThousandSep=',';
SET DecimalSep='.';
SET MoneyThousandSep=',';
SET MoneyDecimalSep='.';
SET MoneyFormat='¥#,##0;-¥#,##0';
SET TimeFormat='h:mm:ss';
SET DateFormat='YYYY-MM-DD'; // 日付のフォーマットをSnowflakeのものに合わせます
SET TimestampFormat='YYYY-MM-DD h:mm:ss[.fff]';
SET FirstWeekDay=6;
SET BrokenWeeks=1;
SET ReferenceDay=0;
SET FirstMonthOfYear=1;
SET CollationLocale='ja-JP';
SET CreateSearchIndexOnReload=1;
SET MonthNames='1月;2月;3月;4月;5月;6月;7月;8月;9月;10月;11月;12月';
SET LongMonthNames='1月;2月;3月;4月;5月;6月;7月;8月;9月;10月;11月;12月';
SET DayNames='月;火;水;木;金;土;日';
SET LongDayNames='月曜日;火曜日;水曜日;木曜日;金曜日;土曜日;日曜日';
SET NumericalAbbreviation='3:k;6:M;9:G;12:T;15:P;18:E;21:Z;24:Y;-3:m;-6:μ;-9:n;-12:p;-15:f;-18:a;-21:z;-24:y';
SET DirectTableBoxListThreshold = 10000000000; // テーブルチャートの行数が多い時に設定。デフォルトは1000
LIB CONNECT TO 'snowflake_test'; // コネクション名
DIRECT QUERY // Direct Discoveryの宣言や初期化
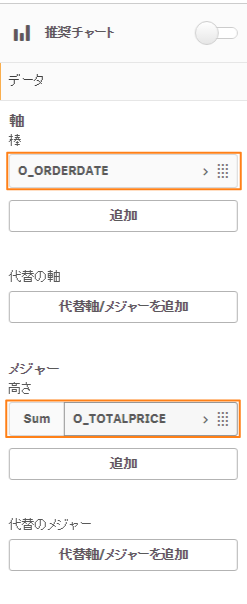
DIMENSION
O_ORDERDATE
MEASURE
O_TOTALPRICE,
O_ORDERKEY,
O_CUSTKEY
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF10000.ORDERS;
|
フィールドタイプ
|
メモリーにロードされるか?
|
関連付け
|
チャートでの利用
|
|
DIMENSION
|
される |
可
|
軸に使用
|
|
MEASURE
|
されない
|
不可
|
メジャーに使用。集約関数が使用可能
|
|
DETAIL
|
されない
|
不可
|
表示は出来るがチャートや集約関数は使用不可 |
| DIMENSION | O_ORDERDATE (注文日付) |
| MEASURE | O_TOTALPRICE (金額) O_ORDERKEY (注文ID) O_CUSTKEY (顧客ID) |
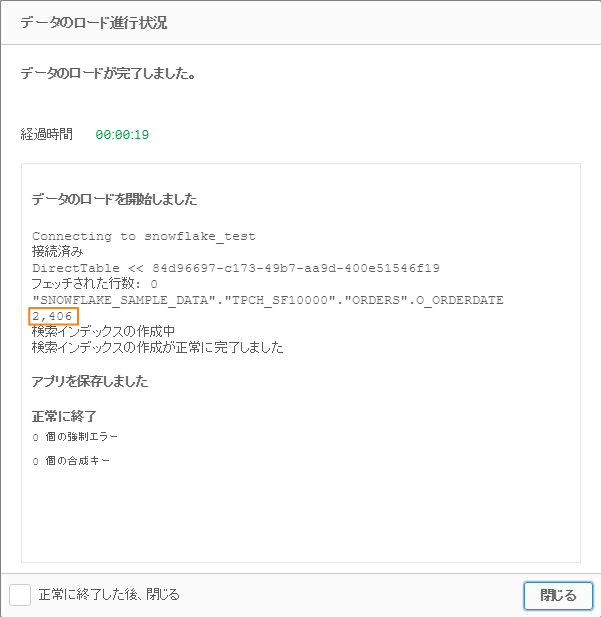
150億件のデータですが、ロードは20秒程で完了しました。
(注: 今回のチャートは分析が目的ではなく、Snowflakeを使用したパフォーマンス検証であるため、見やすいようチャートを拡大表示しています。)
150億件のデータを扱っている実感は全くありませんでした。
なぜ大量のデータをここまで高速に処理できるのでしょうか?
上記スクリーンショットはDirect Discoveryでデータをロードした際のログです。
Direct Discoveryではこのデータを利用してデータソースを参照し、
チャートをリアルタイムに作成します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}