


Qlik Senseユーザーの皆様、こんにちは。
Qlik Sense DesktopやTableauなどのBIツールを使っていると、DBサーバーに接続して大量のデータを分析することがありますが、
画面が固まってしまったり、PCのパフォーマンスが悪くなってしまうことがあります。
今回は通常BIツールでは扱えないような大量のデータを、
クラウドDWHのSnowflakeを活用して一瞬で分析できる方法をレポートしていきます。
(Tableauの記事は こちら)
1. Snowflakeの下準備
1-1. Snowflakeのアカウント作成・初期設定
Snowflakeのトライアルでは、1ヶ月で400ドル分のリソースを無料で利用することが出来ます。
トライアルを開始するには Snowflake にアクセスし、氏名、メールアドレス、会社名、国名(JapanでOK)を入力してアカウントを作成します。
数分経つと登録したメールアドレスにアクティベート用リンクが送られてくるので、
リンク先にアクセスします。
ログインを行うとコンソール画面が開かれ、アカウント登録が完了します。
この状態でもQlik Senseから接続を行うことは可能ですが、
その前にSnowflakeの ウェアハウス(クエリ実行などをするサーバー)の初期設定を行います。
コンソール画面上部の「Warehouses」を開き、
ウェアハウスを選択し「Configuration」を選択します。
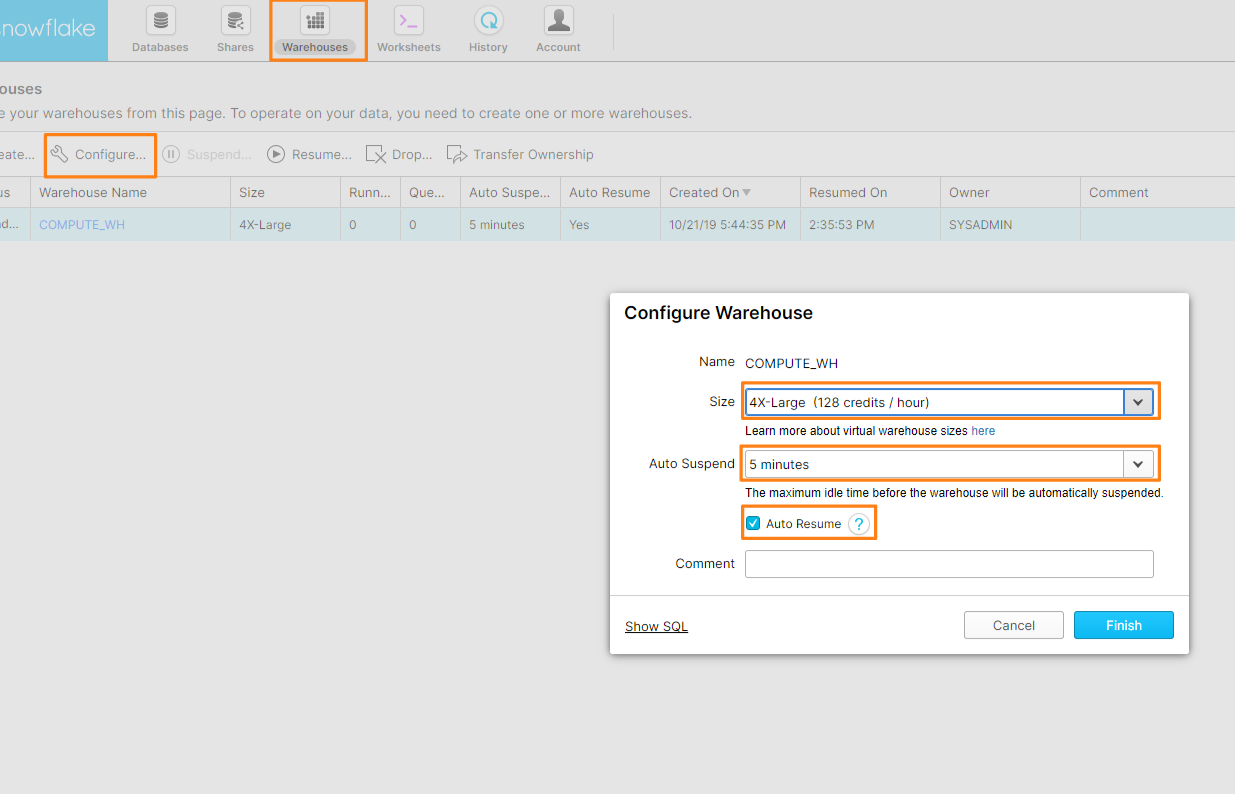
「Configure Warehouse」で以下の項目を設定します。
- Size: ウェアハウスの性能です。性能が高いほど消費コストが高くなります。今回のレポートでは一番性能が良い「4X-Large」を選択しました。
- Auto Suspend: クエリ実行が終了してから次のクエリが実行されるまでに自動でウェアハウスがサスペンドされる時間です。今回は5分を選択しました。(設定ファイルでもっと短い時間を選択することもできます。)
- Auto Resume: ウェアハウスがサスペンド状態の時にクエリが実行された時、自動でウェアハウスが起動されるようにするかの項目です。今回はオンにしました。
1-2. Snowflake ODBCドライバーのインストール・設定
Snowflakeの設定が完了したので次は接続のための準備を行います。
Qlik Sense DesktopでSnowflakeに接続する方法はいくつかありますが、
今回はODBCで接続します。
SnowflakeはODBC接続するためのドライバーを以下のページで提供しているので、
そこからドライバーをダウンロード、インストールします。
今回は2019/10/25時点で最新だった「snowflake64_odbc-2.19.16.msi」をインストールしました。
(サポートしているOSや詳細情報などは公式ガイドを参照。)
ドライバーをインストールした後、
「ODBCデータソース」などでデータソースを作成します。
「ドライバー」タブでSnowflakeのドライバーがインストールされていることを確認します。
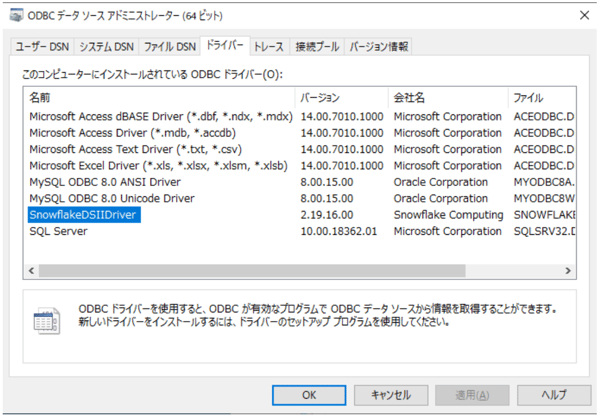
「システムDSN」タブでデータソースを追加します。
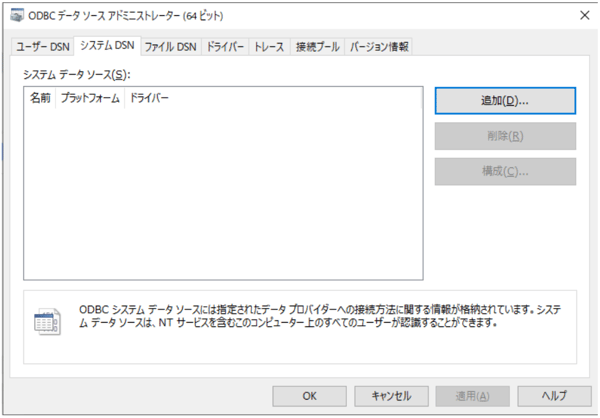
「SnowflakeDSIIDriver」を選択し、設定に必要な項目を入力していきます。
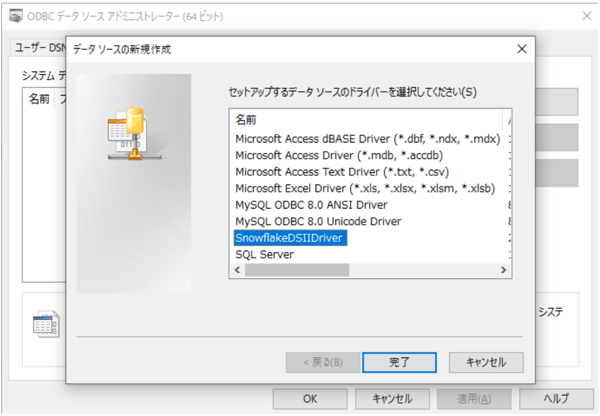
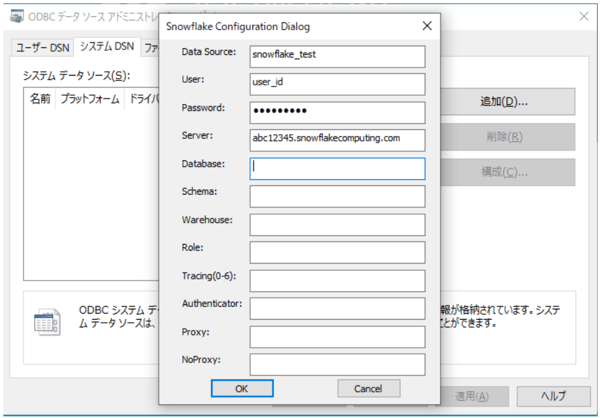
【必要入力項目】
|
Data Source
|
名前。自由に設定可能 |
|
User
|
SnowflakeのログインID
|
|
Password
|
Snowflakeのログインパスワード
|
| Server |
Snowflakeのコンソール画面のURL
|
(他は空欄でも作成可能でした。)
1-3. Qlik Sense からSnowflakeへ接続
データソースの追加が完了したら、
Qlik Senseから作成したデータソースを利用してSnowflakeに接続します。
「新規データソースへの接続」でODBCを選択し、

作成したデータソースに接続する為のユーザー名、パスワードを入力して接続を作成します。
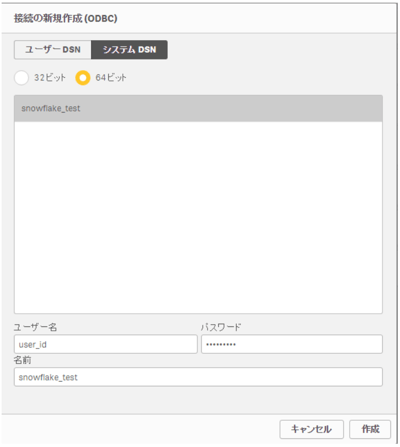
以下の画面でSnowflakeのデータベース等が確認出来たら接続設定完了です。
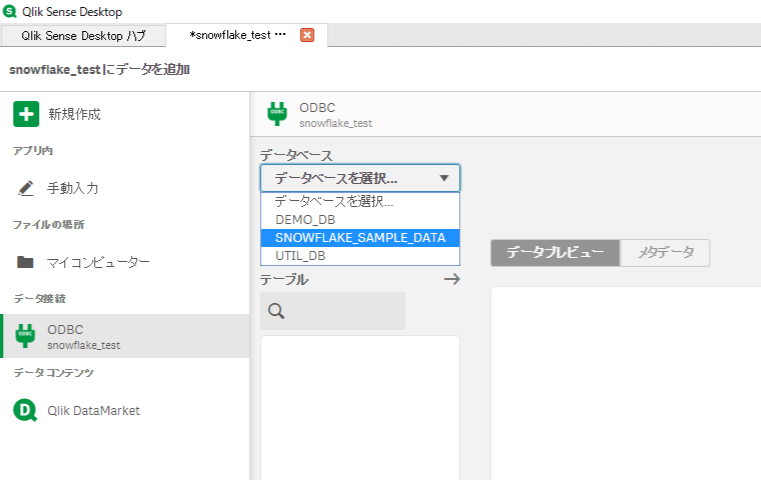
チャート作成
2-1. Direct Discoveryでデータをロード
今回は単純な日次売上グラフを作成してみます。
Snowflakeに最初から入っているサンプルデータの、
購入情報をまとめた「ORDERS」テーブルを使用します。
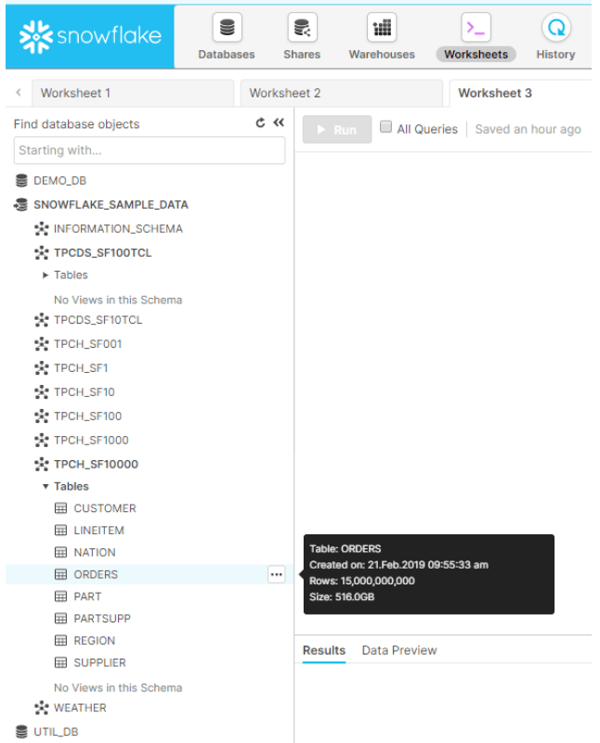
【テーブル概要】
|
Database
|
SNOWFLAKE_SAMPLE_DATA |
|
Schema
|
TPCH_SF10000
|
|
行数
|
150億件 |
|
サイズ
|
516GB
|
ロードスクリプトエディタを開き、以下のように記入します。
SET ThousandSep=',';
SET DecimalSep='.';
SET MoneyThousandSep=',';
SET ThousandSep=',';
SET DecimalSep='.';
SET MoneyThousandSep=',';
SET MoneyDecimalSep='.';
SET MoneyFormat='¥#,##0;-¥#,##0';
SET TimeFormat='h:mm:ss';
SET DateFormat='YYYY-MM-DD'; // 日付のフォーマットをSnowflakeのものに合わせます
SET TimestampFormat='YYYY-MM-DD h:mm:ss[.fff]';
SET FirstWeekDay=6;
SET BrokenWeeks=1;
SET ReferenceDay=0;
SET FirstMonthOfYear=1;
SET CollationLocale='ja-JP';
SET CreateSearchIndexOnReload=1;
SET MonthNames='1月;2月;3月;4月;5月;6月;7月;8月;9月;10月;11月;12月';
SET LongMonthNames='1月;2月;3月;4月;5月;6月;7月;8月;9月;10月;11月;12月';
SET DayNames='月;火;水;木;金;土;日';
SET LongDayNames='月曜日;火曜日;水曜日;木曜日;金曜日;土曜日;日曜日';
SET NumericalAbbreviation='3:k;6:M;9:G;12:T;15:P;18:E;21:Z;24:Y;-3:m;-6:μ;-9:n;-12:p;-15:f;-18:a;-21:z;-24:y';
SET DirectTableBoxListThreshold = 10000000000; // テーブルチャートの行数が多い時に設定。デフォルトは1000
LIB CONNECT TO 'snowflake_test'; // コネクション名
DIRECT QUERY // Direct Discoveryの宣言や初期化
DIMENSION
O_ORDERDATE
MEASURE
O_TOTALPRICE,
O_ORDERKEY,
O_CUSTKEY
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF10000.ORDERS;
Direct Query以下の行がDirect Discoveryの特徴的なフィールドとなります。
各フィールドは以下のような特性を持っています。
|
フィールドタイプ
|
メモリーにロードされるか?
|
関連付け
|
チャートでの利用
|
|
DIMENSION
|
される |
可
|
軸に使用
|
|
MEASURE
|
されない
|
不可
|
メジャーに使用。集約関数が使用可能
|
|
DETAIL
|
されない
|
不可
|
表示は出来るがチャートや集約関数は使用不可 |
今回は以下のようにフィールドタイプを設定しました。(スクリプト参照)
| DIMENSION | O_ORDERDATE (注文日付) |
| MEASURE | O_TOTALPRICE (金額) O_ORDERKEY (注文ID) O_CUSTKEY (顧客ID) |
スクリプトを編集したらデータをロードします。
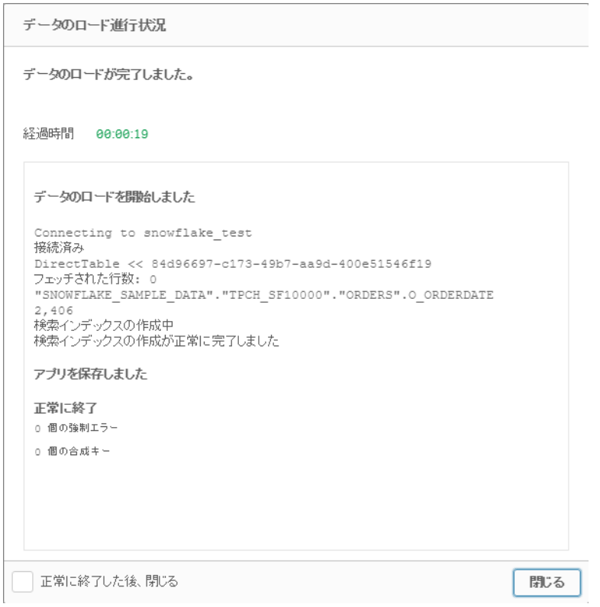
150億件のデータですが、ロードは20秒程で完了しました。
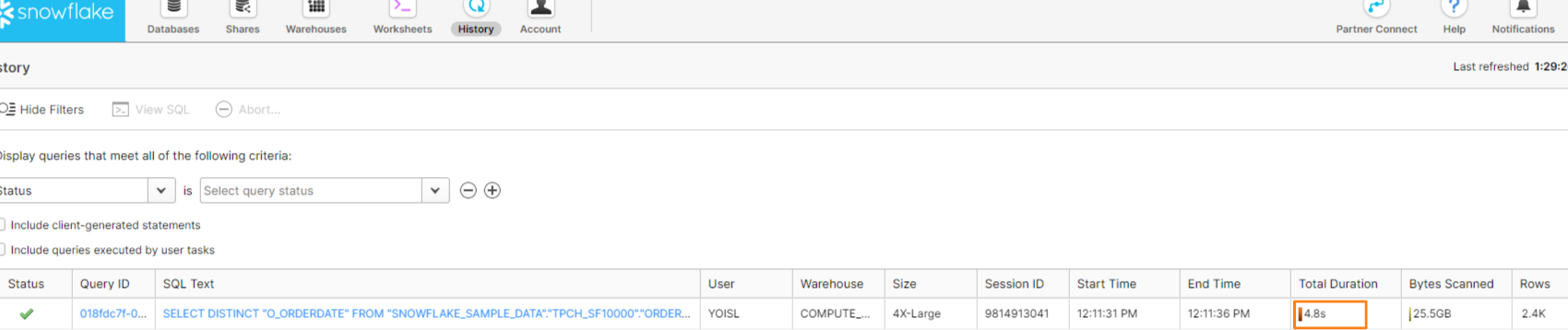
ここでSnowflakeの方の「History」を開くと、
データロードの為のSQLクエリが実行されていることが確認できます。
Snowflake自体の実行時間は 4.8秒程だったことが分かります。
2-2. チャート作成
データのロードが完了したらシートを新規作成し、チャートを作成します。
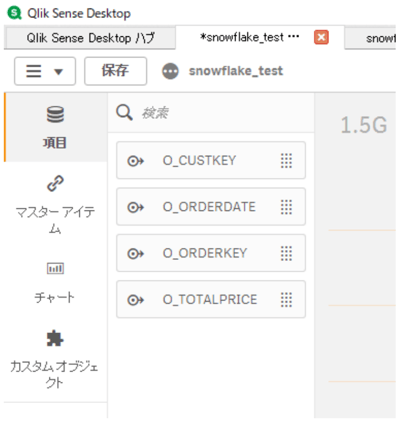
また、シート編集画面で「項目」を見ると先程指定したフィールドが確認できます。
項目名の左にあるアイコンにマウスオーバーすると、
その項目のフィールドタイプを確認できます。
今回は日次の売上チャートを作成します。
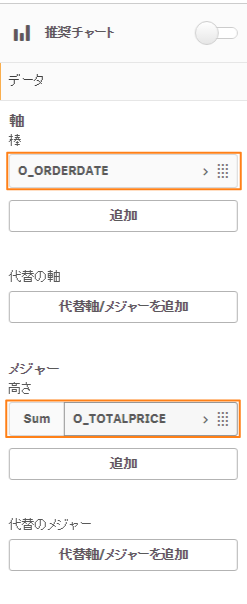
「棒チャート」を選択し、
「データ」で軸に「O_ORDERDATE」、メジャーに「O_TOTALPRICE」を選択します。
(DIMENSIONは軸に、MEASUREはメジャーに利用します。)
ソートを「O_ORDERDATE」順で表示されるようにし、
Y軸の表示範囲を調整します。
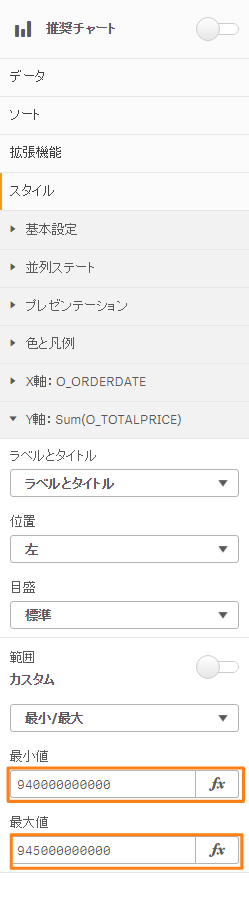
(注: 今回のチャートは分析が目的ではなく、Snowflakeを使用したパフォーマンス検証であるため、見やすいようチャートを拡大表示しています。)
フィルターチャートを追加し、
その軸を「O_ORDERDATE」に設定すると、
このようになりました。
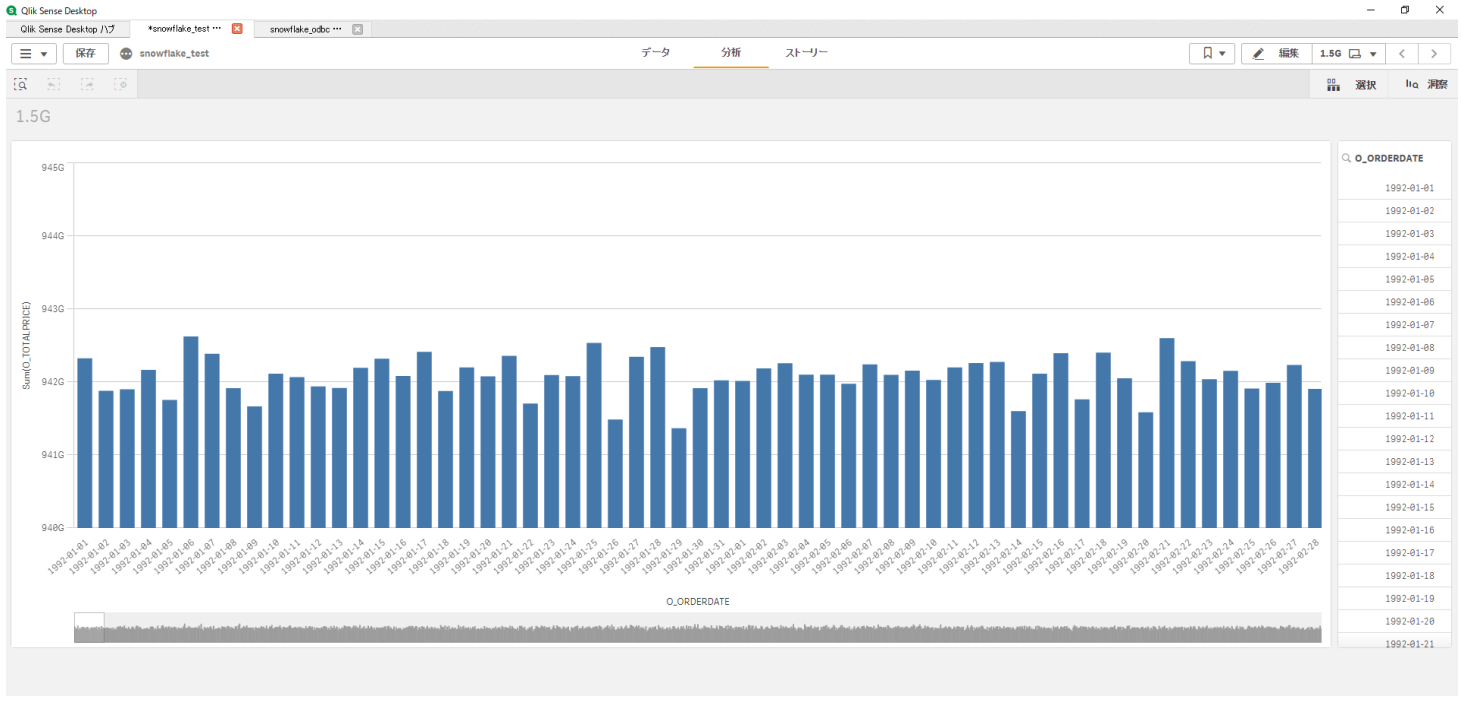
チャートの項目を設定し、表示されるまでに 10秒程かかりましたが、
Qlik Senseの アプリの動作は軽いままで、
150億件のデータを扱っている実感は全くありませんでした。
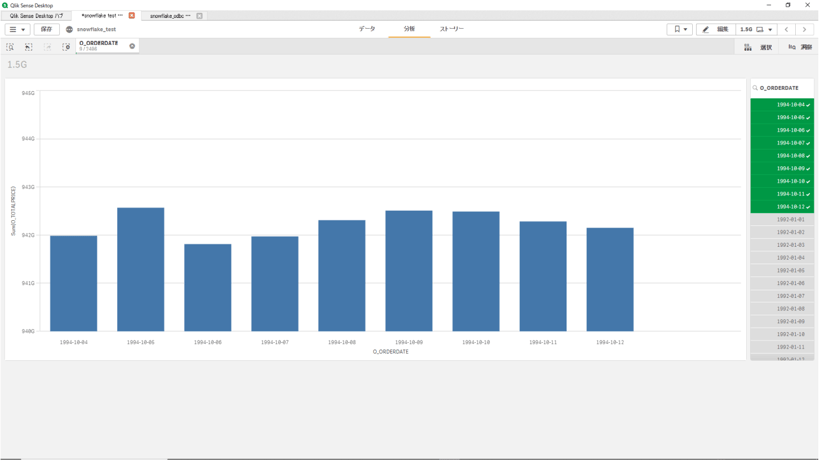
フィルターを有効にすると以下のようにチャートが更新され、
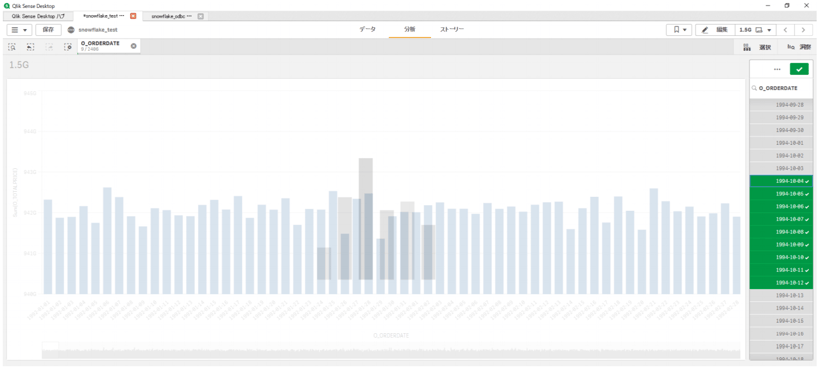
5秒程でフィルターされたチャートが表示されます。
SnowflakeのHistoryを見てみると、
数秒でクエリを実行し結果をQlik Senseに返していることが確認できます。
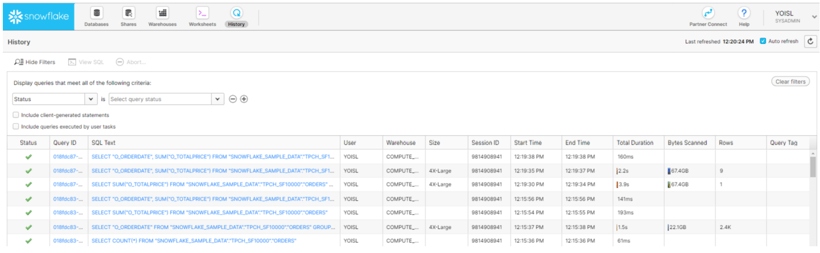
ここからSQL Textをクリックすると、実行されたSQLクエリを確認できます。
下のクエリはフィルターを有効にした際に実行されたものです。
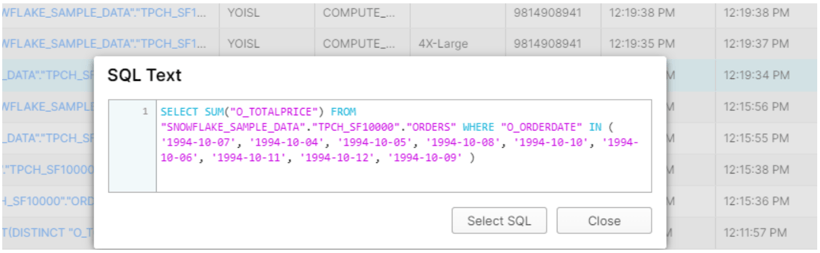
まとめ
3-1. 150億行のデータを快適に扱える理由
なぜ大量のデータをここまで高速に処理できるのでしょうか?
150億件500GBのデータを可視化しようとしたら通常はもっと時間がかかりますし、アプリの動作も重くなります。
今回高速に大量のデータを可視化出来た要因は以下の2つです。
-
Snowflakeの性能
-
Qlik SenseのDirect Discovery
1.Snowflakeの性能
ビッグデータを処理するプラットフォームとして、Snowflakeは非常に高い評価を得ています。
一部の調査では、Amazon RedshiftやBigQueryよりもコストパフォーマンスが優れているという結果が出ています。 ( https://fivetran.com/blog/warehouse-benchmark)
クエリの内容にもよりますが、単純な集約関数のクエリであれば、以下のように2880億件10TBのデータも十数秒で完了することが出来ます。
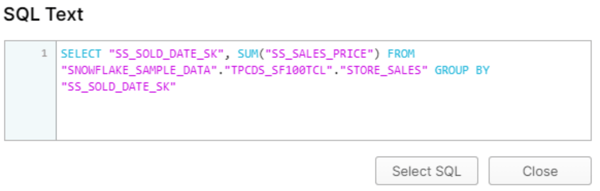
他にも、同じデータを利用して同じクエリを実行すると、
クエリを実行せずに過去の結果だけをミリ秒で返してくれる リザルトキャッシュ機能や
データウェアハウス自体のキャッシュによるクエリの高速化機能があり、
大量のデータ処理高速化の大きな要因となっています。
2.Qlik SenseのDirect Discovery
しかし、たとえSnowflakeでデータを高速に処理をしたとしても、
可視化ツール側(今回だとQlik Sense)も渡されたデータを高速に処理できなくては意味がありません。
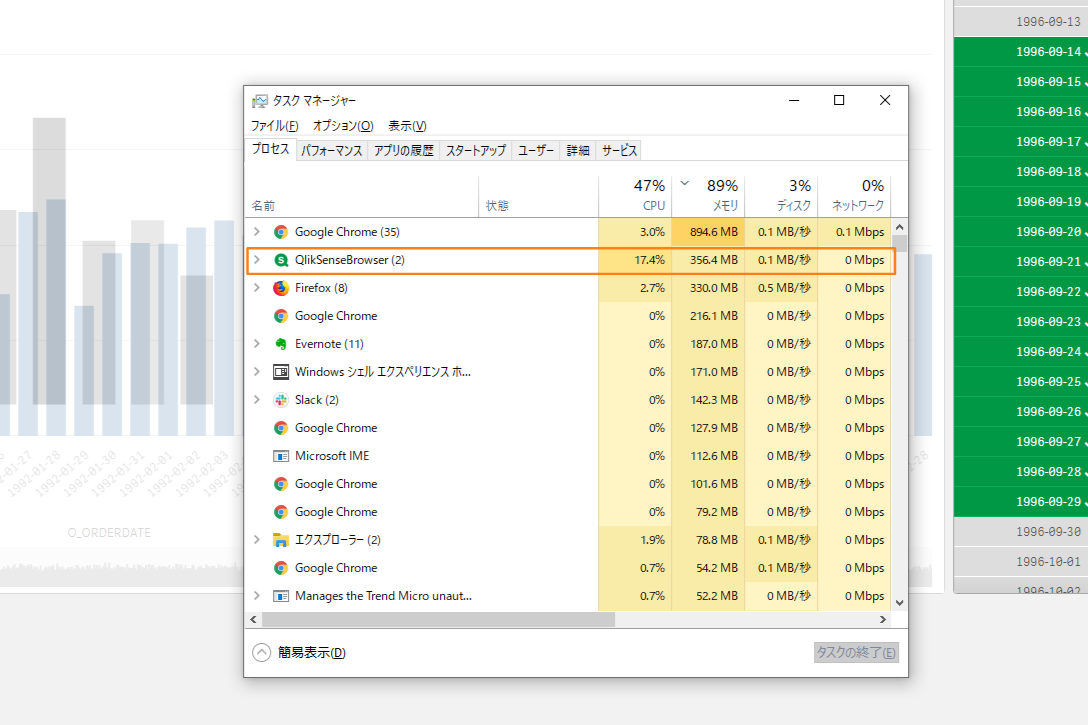
そもそも、500GBのデータは一般のノートパソコン(下記スクリーンショット参照)ではロードすら出来ません。
それが出来たのは、Direct Discoveryのデータロード処理の仕方によります。
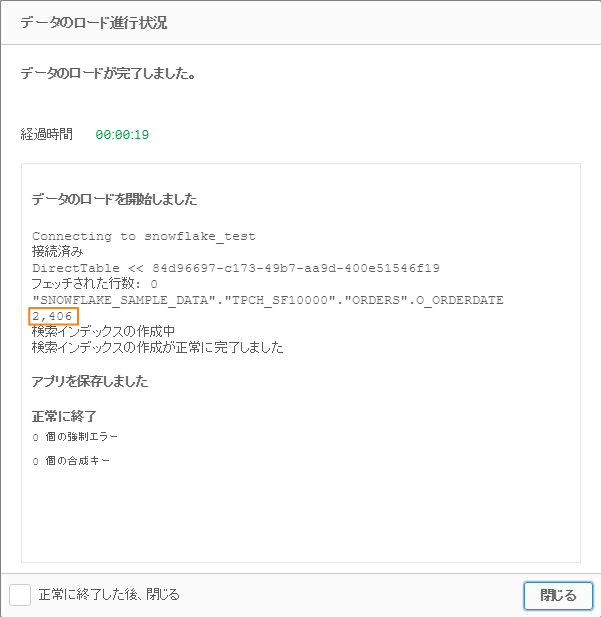
上記スクリーンショットはDirect Discoveryでデータをロードした際のログです。
「2406」という数字が表示されていますが、これはメモリにロードされたデータの数となります。
今回だと、元データにO_ORDERDATEが2406種類あり、
500GBの元データの内、それらだけがメモリーにロードされたことを表しています。
Direct Discoveryではこのデータを利用してデータソースを参照し、
チャートをリアルタイムに作成します。
なので、150億件のデータをQlik Senseで扱っているように見えて、
実はたったの 2406件(1列のみ)のデータとSnowflakeから帰ってくる クエリ結果しか扱っていなかったため、極めて快適に可視化することが出来たのです。
(下の画像を見ると、チャートフィルターを有効にした時のQlik Senseのメモリ使用量が低いことが分かります。)
 以上、【Qlik Sense DesktopとSnowflakeで150億件のデータを可視化してみた】でした。
以上、【Qlik Sense DesktopとSnowflakeで150億件のデータを可視化してみた】でした。INSIGHT LABでは、Snowflake(スノーフレイク)についてもナレッジ情報を発信しております。
Snowflakeにもご興味ございましたら、ぜひ、以下のサイトも覗いてみて下さい。
-3.png)













