



DataRobotとは
DataRobotとは機械学習モデル作成を自動化するAIプラットフォームです。
データの分析・モデル構築・システムへのデプロイまでを素早く行え、機械学習ソリューションにありがちな問題であるモデルの判定結果における要因解釈について、わかりやすく可視化も行えることが特徴です。
ここからは、実際の予測モデルを作成する流れを通して、各機能を紹介いたします。
データ導入
今回は、Kaggleの登竜門ともいえるタイタニックの生存者予測データセットを使い二値分類モデルを作成していきたいと思います。
何はともあれ、まずはデータを導入していきます。
今回はローカルファイルからCSVファイルを直接アップロードしましたが、Paxataを介したJDBCコネクタからのインポートも可能のようです。
また、データがなくともDataRobot側で幾つかのユースケースに合わせたデータセットも用意されていました。
モデル構築設定・モデル作成
次に学習モデルを構築していく際の設定を行います。
データをロードすると以下のような表が出現します。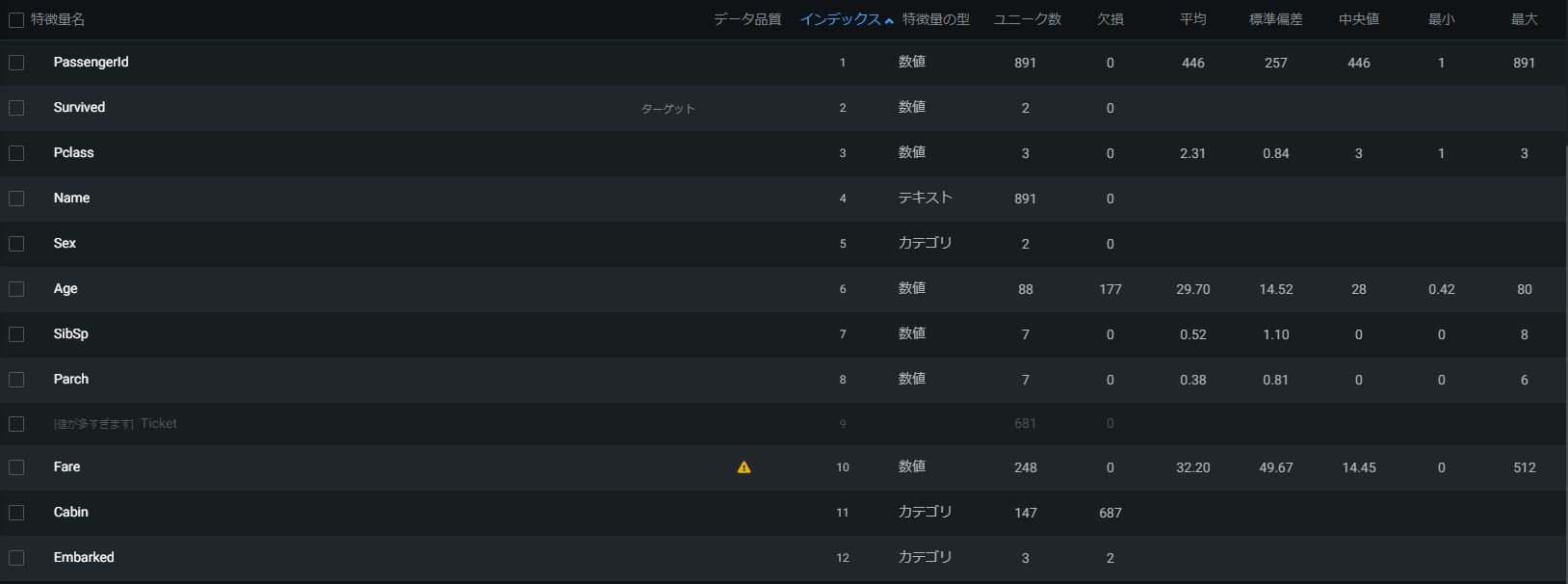
アップしたデータ内の各特徴量の基本的な統計量と型、欠損値の数等の情報が表示されています。
ここで、目的変数となるカラムを指定します。
また、ここで各カラムをクリックするとそのカラムのヒストグラムが表示され、外れ値等の問題がある場合は以下の様に表示され自動で警告されます。
通常であれば、データクレンジングに戻り外れ値に対する対策が行えます。(今回はこのまま続行しました。。。)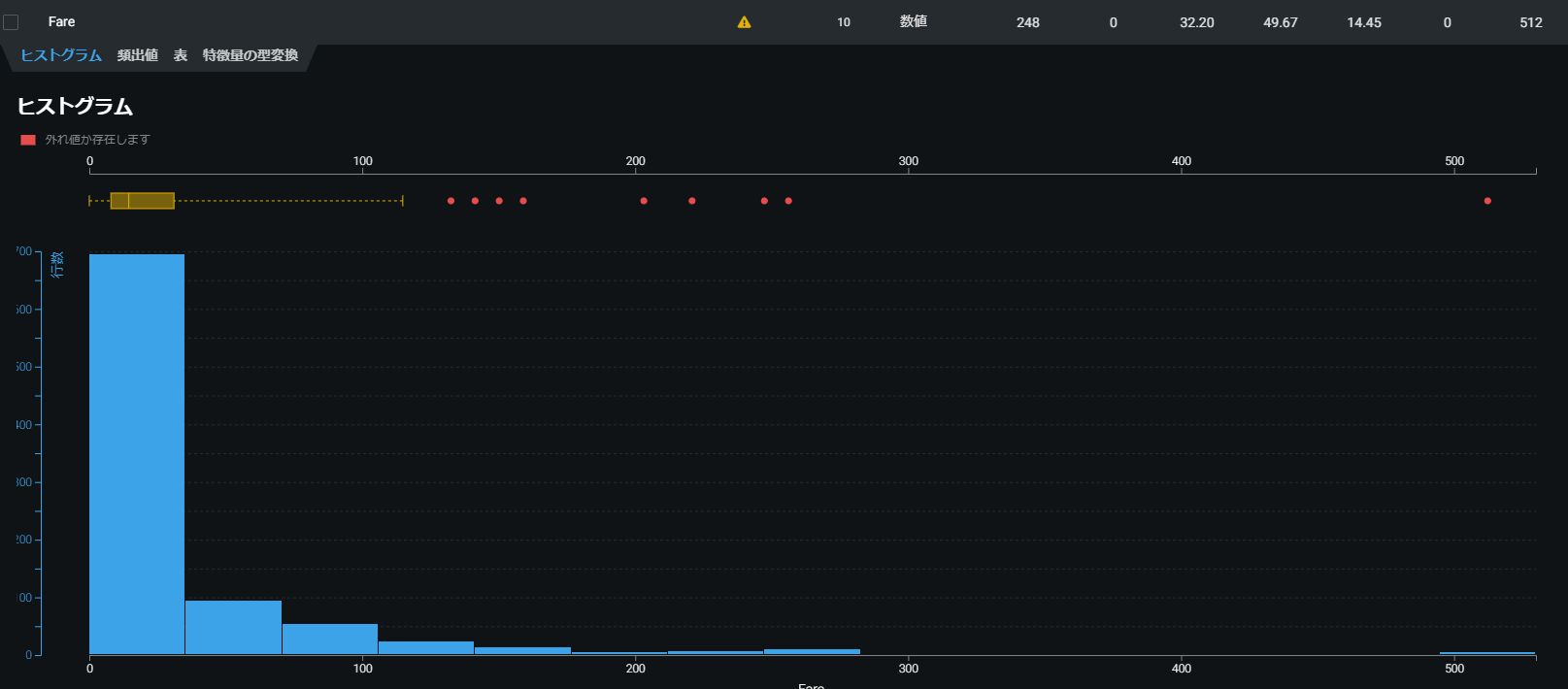
加えて、「高度なオプション」を押下すると以下の画像の様にモデル構築時の評価方法の細かい設定(データパーティション方法)等が設定可能です。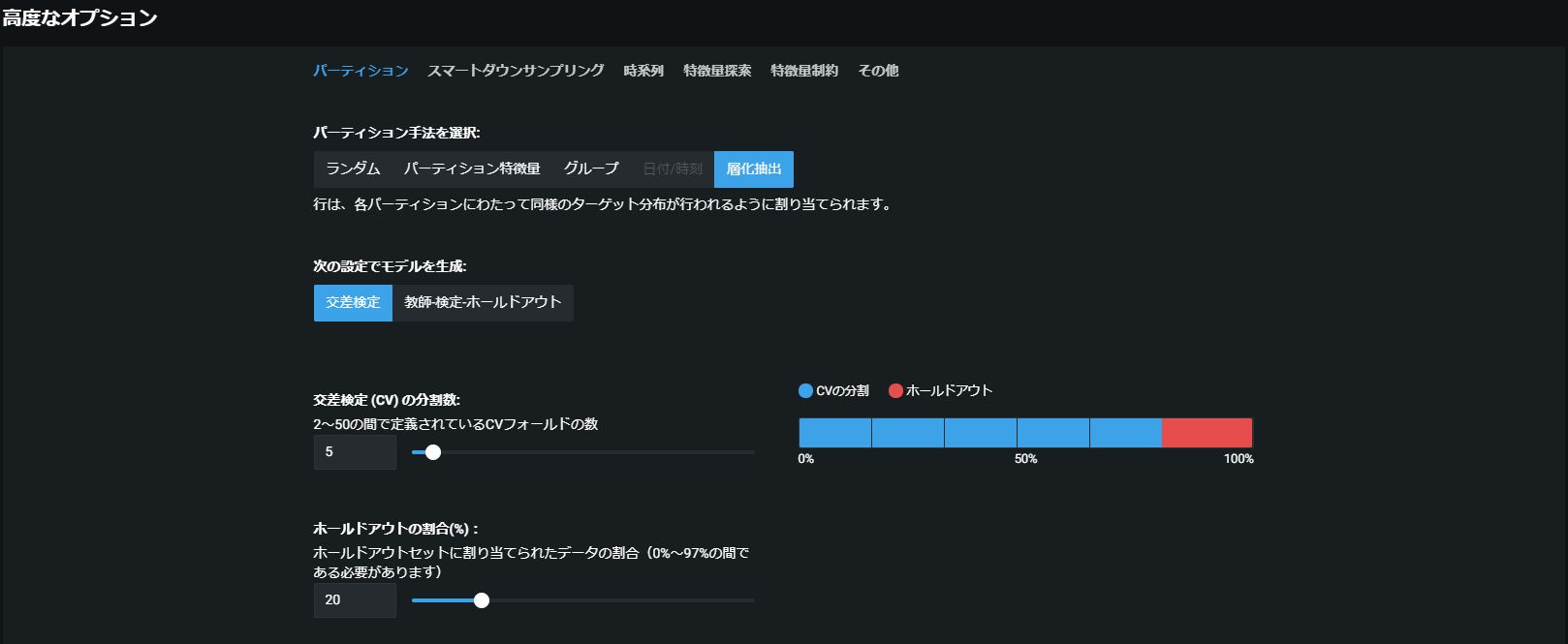
最後に「開始」ボタンを押下するとモデル構築が開始されます。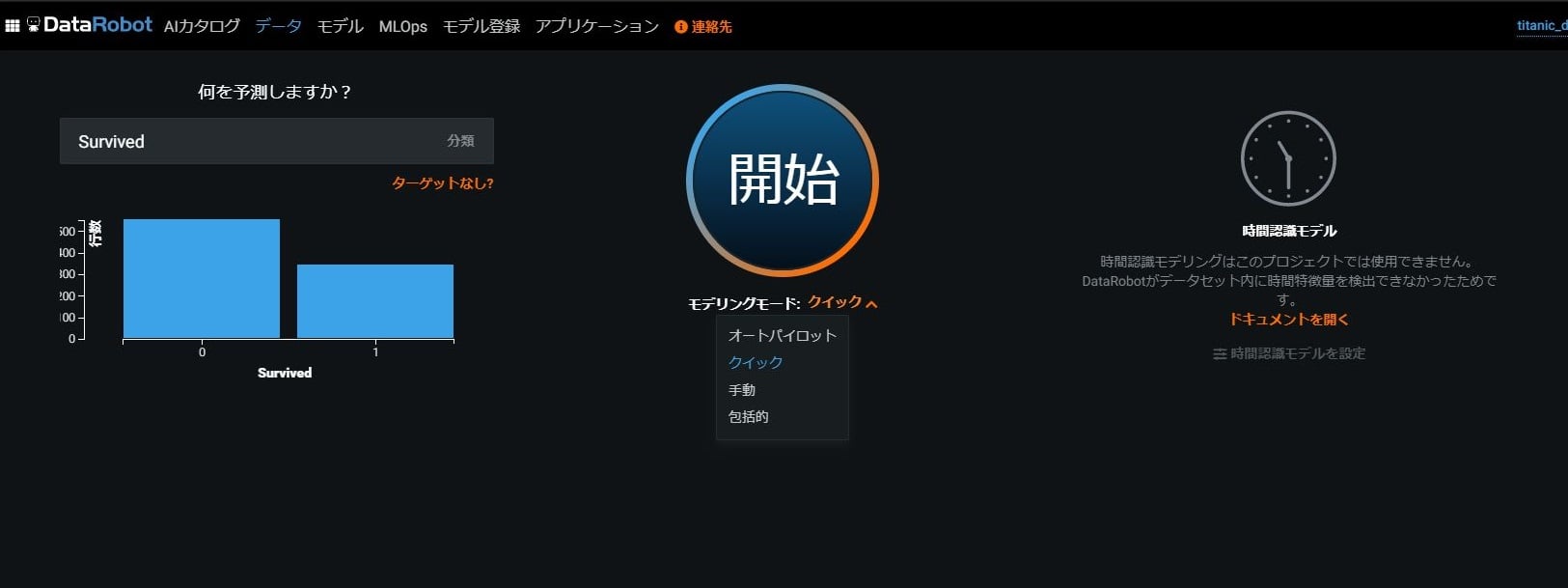
この時、モデル構築のモードとして「クイック」「オートパイロット」「手動」「包括的」が存在しており各モードの説明は以下の通りです。
| オートパイロット | 全データの16%を使用してモデルを構築、スコアリンで上位16のモデルに対し、さらにデータの32%を使用してモデル構築を再実行。その実行から上位8つのモデルが、データの64%を使用して実行。というように段階的に評価してモデルの最適化をおこなうモード。 |
| クイック | オートパイロットを短縮化、最適化したモード。実行速度は速い。 |
| 手動 | ユーザー側で探索するアルゴリズムの指定等が行えるモード。 |
| 包括的 | DataRobotで利用できるアルゴリズムを使い精度重視で探索するモード。実行時間は遅くなる。 |
モデル評価
今回は、「包括的」モードでモデル構築を行いました。
実行時間としては、1時間半程度でした。
そして作成されたモデル一覧が以下の通りです。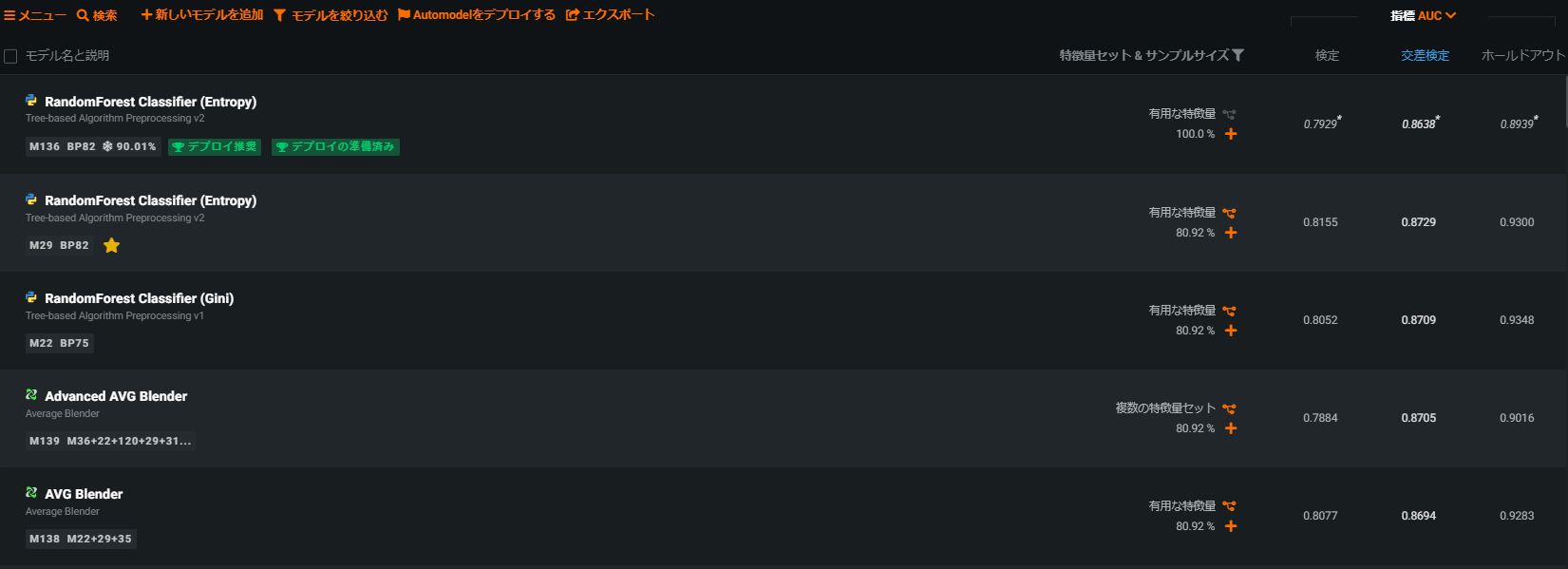
表の左側が各モデルがマークしたスコア(今回はAUC)になります。
右側には各モデルのアルゴリズムが表示されており、~~Blenderと表記のあるアルゴリズムは、DataRobotが複数のアルゴリズムを掛け合わせたアンサンブルモデルとなります。
各モデルの行をクリックするとそのモデル詳細、評価結果等を見ることができます。
以下の画像は、上記の表で最もAUCが高いRandomForest Classifier(Entropy)の評価詳細です。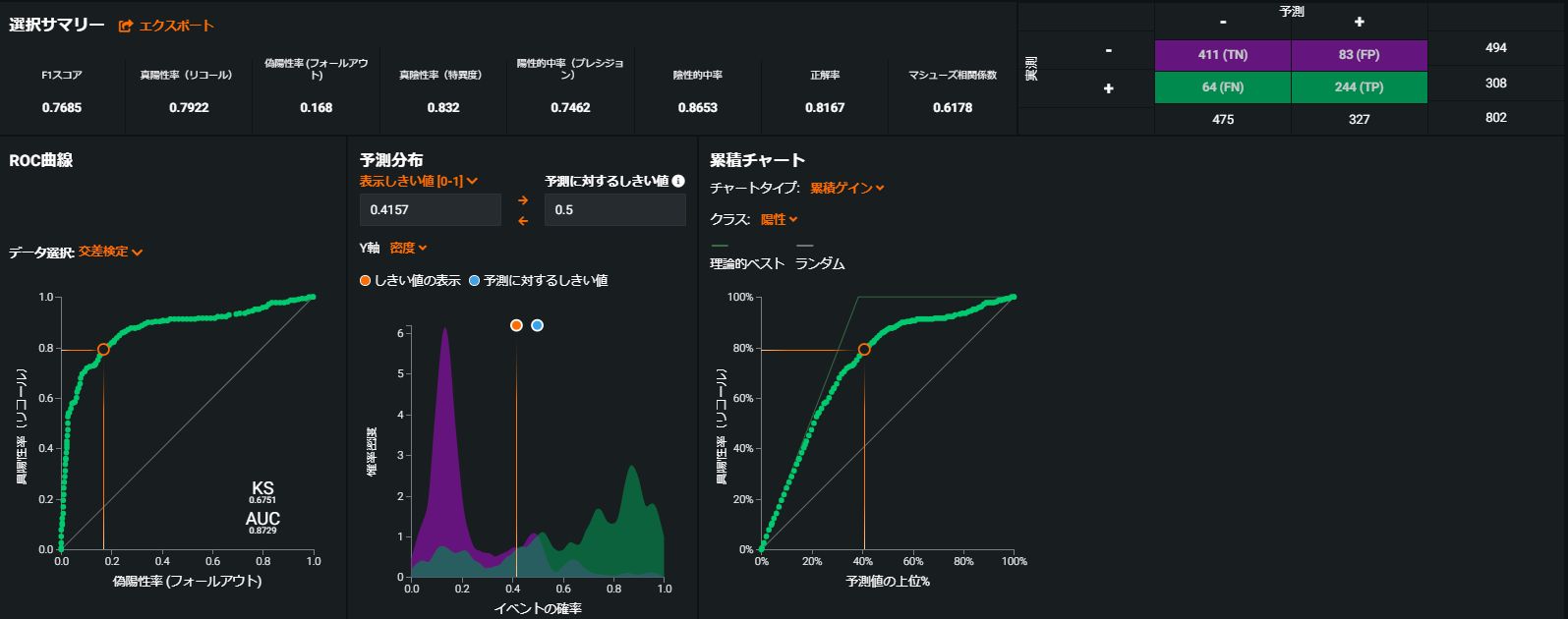
二値分類の評価方法としては、おなじみのROC曲線や混合行列、さらにF1スコアからマシューズ係数等の評価値が算出されており、これらの値を利用して評価可能です。
また、分類実行時の確率値に対する閾値も編集可能なので、業務利用目標に応じた閾値の設定も可能です。(例:Recall 80%設定時のPrecissionで評価等)
さらに、モデルの分類判断に於いてどの説明変数が重要視されているかの分析も「特徴量のインパクト」を見ることで行うことができます。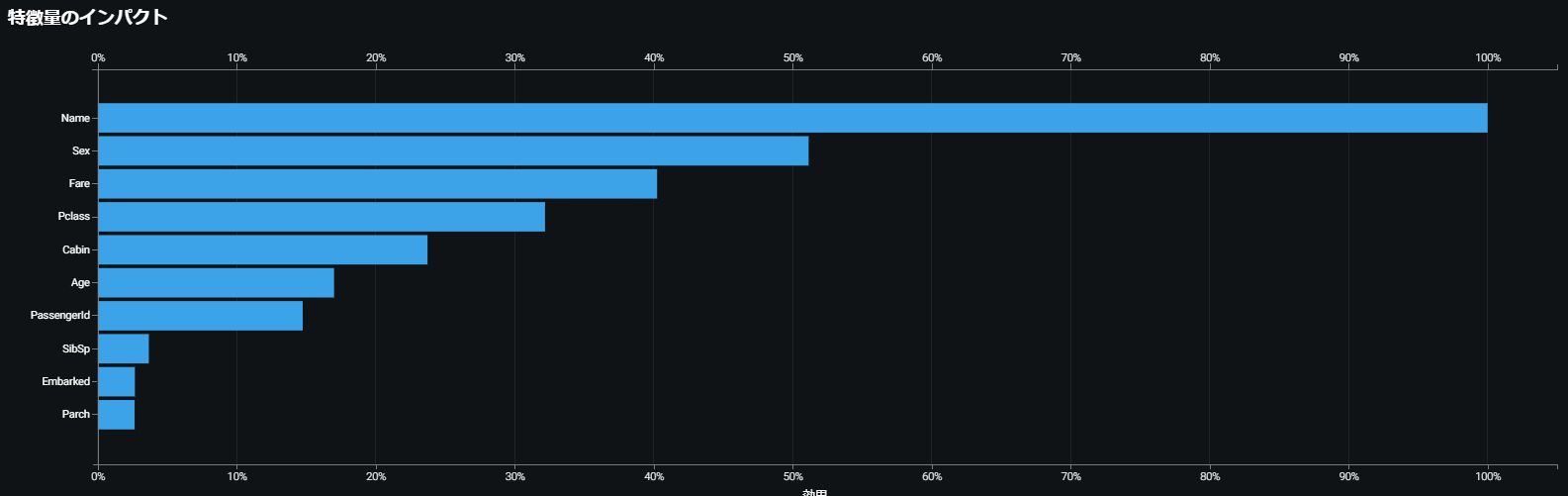
今回の場合ですと、最も分類判断に寄与している変数は「Name」となります。
では、「Name」が目的変数に対し、どのように作用しているのかを見ていきましょう。
こちらは、「インサイト」と呼ばれる機能を使うことでテキストに対する分析も可能です。
以下の画像は、目的変数に対する「Name」でのテキストマイニングの結果をワードクラウドで表示しています。
文字が大きいほど出現数が高く、色が青に近ければ目的変数にネガティブに作用し、赤に近ければ目的変数にポジティブに作用します。
注目していただきたいのは、中央にある「mr」と「mrs」、「miss」、「master」です。
「mr」はネガティブに作用していることから男性は生存しずらかったことが分かります。
また、「mrs」「miss」については女性が生存しやすいことを示し、特に[mrs」つまり既婚女性は生存確率が高いことが分かります。
加えて、「master」は少年に付けられる敬称であり、少年もまた生存しやすかったことが分かります。
以上のことから、タイタニック沈没時は男性は女性や子供を逃がすため犠牲になったと推論できます。
このように、各変数を深堀した分析も行うことができます。
まとめ
今回は、実際にDataRobotを触りながら機能の一部を紹介させていただきました。
実際に利用した所感としては、お手軽にモデル構築ができて驚きました。
Pythonで機械学習モデルを作成するときに必要な各変数に対する特徴量化やアルゴリズムに対するパラメータチューニング等、手間がかかる作業が自動化されたことにより高速化ができていると思います。
個人的には、テキストに対する処理が一般的な文章であれば問題ないレベルで特徴量化・分析可能なのが驚きました。
また、今回は紹介しきれませんでしたが画像に対する分類も最近実装されたようなので試してみたいと思います。


-3.png)
