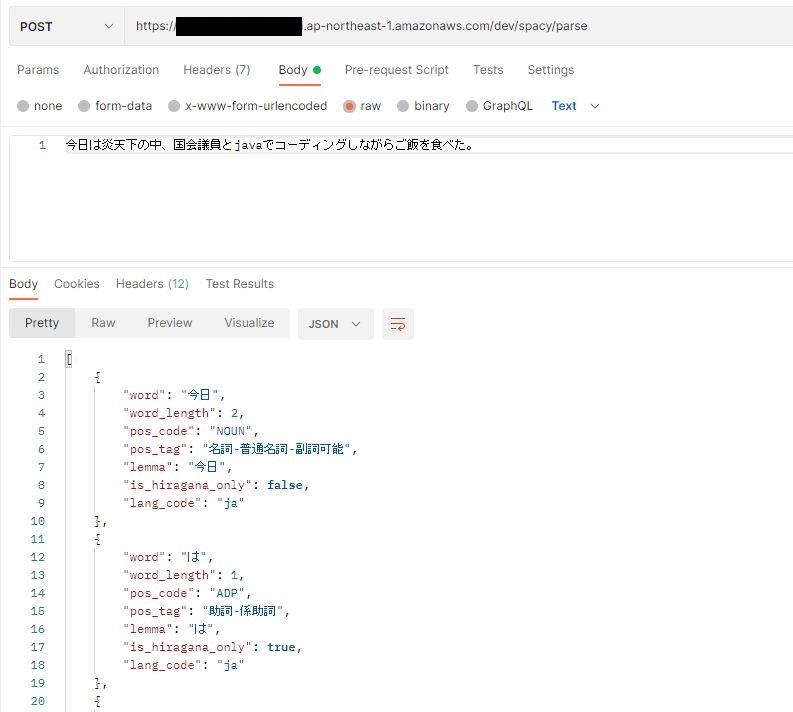
-3.png)
SnowVillageで実演したNLP詳細解説
本記事は、2021/08/04(水)に登壇させていただいたSnowVillage生放送でのNLPパートの詳細解説記事になります。
生放送内では尺の都合上、紹介できなかった前処理やTF-IDFの解説を中心に紹介します。
SnowVillageとは...?
隔週水曜日にSnowflakeに関する情報発信を行っているアツいYoutubeチャンネルです。
Snowflakeはアメリカ・シリコンバレー 生まれのクラウド専用のデータコラボレーション基盤(Data Cloud)。日本では2020年から本格的に展開が進み、クラウドデータウェアハウス(DWH)やクラウドデータ基盤としての活用が始まっています。
以下、登壇時の動画を記載しますので、是非とも視聴していただけると幸いです。
NLPにおける前処理について
NLPにおける前処理の基本方針としては以下の通りです。
-
- 文章の意味に関係のない表現(URL, アドレス, タグ等)の除去
- 表現の正規化(「テレビ」、「テレビ」等の統一化)
- 単語単位での分割、レマタイズ(単語の基本形に統一)
- ストップワード除去(語句指定、品詞指定等)
- ベクトル表現の獲得(One-hot, TF-IDF, Word2Vec, Doc2Vec等)
これらの考え方はどの言語でも共通で使える方針です。
これらを踏まえた上で、動画内で紹介していたNotebook上での処理を並べてみると
-
- ツイート上のURLとメンション表現(@xxxxのような表現)を正規表現で除去
- 改行やタブなどの不要な表現を除去
- 英数字記号を半角に変換(mojimojiというライブラリを利用)
- カタカナを全角に変換(mojimojiというライブラリを利用)
- MeCabでの形態素解析
- 品詞情報等による語彙限定
- MeCabで単語を原形に変換
- TF-IDFによる分散表現の獲得
という処理になります。
今回の発表の流れとしてAWS comprehendでは品詞情報を無視したキーフレーズ取得がされていることが問題だったので6の語彙限定に対し、名詞、動詞、副詞、形容詞等に限定しています。
また、純粋なMeCabの品詞情報のみだとこれらの判定が難しいことから他にも「ひらがなのみの構成単語か?」「一文字で完結する単語か?」も含めて品詞判定を行っています。
形態素解析について
今回は、MeCabと呼ばれる形態素解析器を利用して単語の分かち分け、品詞判定、レマタイズを行っています。
また、Google ColaboratoryではデフォルトでMeCabが導入されていない為、環境設定用のコードを書いてこちらで導入しています。
この際に、MeCabのデフォルト辞書では新語対応ができていないパターンもあるので利用する辞書を「mecab-ipadic-NEologd」という新語対応済みの辞書に変更しています。
実際のMeCabの出力紹介も兼ねてGoogle ColaboratoryでのMeCab導入⇒NEologd辞書導入までを紹介してみましょう。
MeCabのインストール
まずは、MeCabの導入 ※今回は、Windows環境を利用します。
# MeCabのインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!pip install mecab-python3 > /dev/null !ln -s /etc/mecabrc /usr/local/etc/mecabrc
PythonでMeCabの動作確認
続いて、Pythonで試しに動かしてみましょう。
import MeCab
import os
# NEologed辞書の有無を確認
# なければデフォルト辞書でtaggerインスタンス生成
neologd_path = '/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd'
if os.path.exists(neologd_path):
print('Mode: neologed')
tagger = MeCab.Tagger('-d {}'.format(neologd_path))
else:
tagger = MeCab.Tagger()
print('Mode: vanilla')
# 以下はテストコード
sentence = '彼女は恋ダンスとペンパイナッポーアッポーペンを踊った。'
parsed_text = tagger.parse(sentence)
print(parsed_text)
print(type(parsed_text))
出力は以下の通りになりました。
Mode: vanilla
彼女 名詞,代名詞,一般,*,*,*,彼女,カノジョ,カノジョ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
恋 名詞,一般,*,*,*,*,恋,コイ,コイ
ダンス 名詞,サ変接続,*,*,*,*,ダンス,ダンス,ダンス
と 助詞,並立助詞,*,*,*,*,と,ト,ト
ペンパイナッポーアッポーペン 名詞,一般,*,*,*,*,*
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
踊っ 動詞,自立,*,*,五段・ラ行,連用タ接続,踊る,オドッ,オドッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
。 記号,句点,*,*,*,*,。,。,。
EOS
<class 'str'>
このようにPythonラッパーを使ってMeCabを使うと文字列として上記のような情報が獲得できます。
各行に対し分かち分けされた単語が表れており、それに続いて以下のような情報になっています。
表層形\t品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音
ここでいう表層形というのは入力された状態の単語です。
これらの品詞情報を使い今回は語彙限定を行いました。
また、ここで注目してほしいのは、「恋ダンス」という単語は「恋」と「ダンス」に分かれているところです。
「恋ダンス」自体は比較的新しい単語なのでデフォルト辞書だと認識ができないようです。
NEologd辞書を追加導入して再実行
ここで、NEologd辞書を導入して同様のことを行うと以下のような出力になります。
NEologd辞書導入用スクリプト
# mecab-ipadic-neologd辞書導入
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
!echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
Pythonスクリプト実行後の出力
Mode: neologed
彼女 名詞,代名詞,一般,*,*,*,彼女,カノジョ,カノジョ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
恋ダンス 名詞,固有名詞,一般,*,*,*,恋ダンス,コイダンス,コイダンス
と 助詞,並立助詞,*,*,*,*,と,ト,ト
ペンパイナッポーアッポーペン 名詞,固有名詞,一般,*,*,*,Pen-Pineapple-Apple-Pen,ペンパイナッポーアッポーペン,ペンパイナッポーアッポーペン
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
踊っ 動詞,自立,*,*,五段・ラ行,連用タ接続,踊る,オドッ,オドッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
。 記号,句点,*,*,*,*,。,。,。
EOS
<class 'str'>
「恋ダンス」が固有名詞として無事認識されました。
このように新語に対応している辞書なので、積極的に利用したほうが良いと思います。
MeCabのユーザー辞書について
今回の事例ではツイッターの文章を利用しているということもあり「#」から始まるハッシュタグ表現が多用されています。
これをノイズとして捨て置く考え方もできますが、実際の文章を見ると単語としての使われ方(特に名詞句として)が多く見受けられたのでハッシュタグを単語(固有名詞)として処理しました。
方法としては、MeCabのユーザー辞書登録機能を使い任意の文字列を単語として認識させました。
MeCabのユーザー辞書の作成手順としては、以下の通りです。
-
- csvでの単語一覧を決められたフォーマットで作成
- 作成したcsvファイルを辞書ファイルにビルド
- MeCab設定ファイルでユーザー辞書を登録
1の決められたフォーマットというのは以下のようなフォーマットです。
表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音
基本的には、MeCabの解析結果出力に似ていますが「左文脈ID」「右文脈ID」「コスト」という謎の項目が出てきました。
「左文脈ID」「右文脈ID」は各方向から見た時の内部状態IDですので、ユーザー辞書作成時は空にしておくとMeCab側で自動に割り当てられます。
「コスト」は簡単に言えば単語の出現のしやすさです。
低ければ低いほど単語として優先的に分けられます。(実際には連接コスト等もあるので絶対ではないですが、、、)
なので、意味合い的に類似している単語を参考にスコアを決めるのがベターかと思います。
また、MeCabにはスコア自動推定機能もある為、その機能を利用しても良さそうです。
今回の事例では、絶対に分けてほしかったので「1」に設定しています。
以下辞書ビルド用のスクリプトを載せておきます。
# Mecab版のユーザー辞書ビルド
!/usr/lib/mecab/mecab-dict-index -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd -u user_dic.dic -f utf-8 -t utf-8 user_dic.csv
# ユーザー辞書を追加設定
!echo "userdic = /content/user_dic.dic" >> /etc/mecabrc
!cat /etc/mecabrc
TF-IDFとは【分散表現の獲得】
分散表現を得る為に今回はTF-IDFを利用しました。
TF-IDFとは、TFとIDFという二つの値を掛け合わせた指標です。
以下の式で定義できます。

上記の式でのTF(Term Frequency)はとある文書内に出現した単語wの割合であり、これは文書内での単語の出現頻度を表しており[文書数]×[単語数]だけTFが算出されます。
IDF(Inverse Document Frequency)は文書単位で見た時の単語wの出現頻度の逆数の対数をとっており、これは各文書で共通して出現する単語はこの値が低くなります。またこの値は単語の数だけIDFが出現されます。
今回の例では、文書=ツイートとしてTF-IDFを算出し、各単語毎に加算する事で単語毎のスコアを算出しています。
以下にTF-IDFの計算イメージと今回利用したスコア(Score1)の式を記しておきます。
| Word 1 | Word 2 | ... | Word N | |
| Tweet 1 | TF11 ×IDF1 | TF12 ×IDF2 | ... | TF1N ×IDFN |
| Tweet 2 | TF21 ×IDF1 | TF22 ×IDF2 | TF2N ×IDFN | |
| : | : | : | : | : |
| Tweet M | TFM1 ×IDF1 | TFM2 ×IDF2 | ... | TFMN ×IDFN |
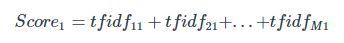
まとめ
今回はSnowVillageで紹介したNLPの詳細解説を行いました。
2週間弱での構築とツイートデータが1カ月程度ということもあり、テキストクレンジング⇒TF-IDFでの可視化という方法をとりました。
ツイートデータ自体がもっと多ければW2VやFastTextを利用した分散表現の獲得も出来たかもしれません。
また、今回はAWS Comprehendも利用していたのでクレンジングしたテキストをAWS Comprehendに通して品詞情報でフィルタリングして可視化してもよかったかもしれません。(その場合、AWS LambdaでのMeCab実装⇒Snowflakeの外部関数連携が必要ですが。。。)