


事前準備
今回は、Serverless Frameworkを利用することやAWS CLIを利用してイメージ登録を行う為、事前に検証用のIAMユーザーを作成しております。
作成したユーザープロファイルは登録済みの状態です。
Serverless Frameworkプロジェクト作成・設定
まずは、Serverless Frameworkを使い、テンプレートからプロジェクトを作成します。
以下のコマンドで作成できます。
sls create -t aws-python3 -n [your-project-name] -p [your-project-name]
指定したディレクトリに「.gitignore」「handler.py」「serverless.yml」が生成されていれば成功です。
プロジェクト設定ファイルを修正します。
プロジェクト作成後、「serverless.yml」は以下のような記述がなされています。
service: [your-project-name]
frameworkVersion: '2'
provider:
name: aws
runtime: python3.8
lambdaHashingVersion: 20201221
functions:
hello:
handler: handler.hello
lambdaでDockerを利用する為に上記のような設定ファイルを下記の様に書き換えます。
service: [your-project-name]
frameworkVersion: '2'
custom:
env:
accountID: 0000000
region: ap-northeast-1
repository: [your-repo]
digest:
provider:
name: aws
runtime: python3.8
stage: dev
region: ${self:custom.env.region}
timeout: 30
memorySize: 512
functions:
parse:
image: "${self:custom.env.accountID}.dkr.ecr.${self:custom.env.region}.amazonaws.com/pyspacy-for-lambda-repo@${self:custom.env.digest}"
events:
- http:
path: spacy/parse
method: post
lambdaデプロイ時のメモリに関しては「provider」項目の「memorySize」で設定できます。
設定しなかった場合、デフォルトでは「1024MB」となるので注意が必要です。
また、ECRとの連携関連の設定値を「custom.env」にまとめています。
各項目の説明は下記の通りです。
- accountID : AWSで利用するユーザーのアカウントID(12桁)
- region : AWSで利用するリージョンコード
-
repository : ECRで作成したリポジトリの名前
- digest : ECRリポジトリに登録したDockerイメージのハッシュ値(固有値)
これでServerless Frameworkの設定ファイル準備は完了です。
言語判定機能・形態素解析機能実装
まずは、Pythonで利用するライブラリインストール用の「requirements.txt」を作成します。
記述内容としては、下記の通りです。
spacy
ginza
ja-ginza
langdetect今回は形態素解析にSpaCyというライブラリを使います。
また、今回は日本語と英語での形態素解析ができるツールを目指したいので言語判定用にlangdetectを導入しています。
SpaCyの公式の日本語モデルがありますが今回はGinZaを利用したいと思います。
プロジェクトのカレントディレクトリに「app.py」を作成します。
「app.py」は下記のような記述をします。
import re
import json
import spacy
from langdetect import detect_langs
jp_model = spacy.load('ja_ginza')
en_model = spacy.load('en_core_web_sm')
# Detects hiragana and katakana in sentence
def is_japanese_for_regex(text):
comp_1 = re.compile('[\u3041-\u309F]+')
comp_2 = re.compile('[\u30A1-\u30FF]+')
if len(comp_1.findall(text)) != 0:
return True
elif len(comp_2.findall(text)) != 0:
return True
else:
return False
# Check hiragana only
def check_hiragana_only(word):
compiled_hiragana = re.compile(r'^[あ-ん]+$')
status_hiragana = compiled_hiragana.fullmatch(word)
if status_hiragana == None:
return False
elif len(status_hiragana.group()) == len(word):
return True
else:
return False
# language detection (en, ja, etc...)
def lang_detector(text):
if is_japanese_for_regex(text):
return 'ja'
else:
try:
detect_resulter = detect_langs(text)
except:
return 'other'
else:
detect_result = detect_resulter[0]
return detect_result.lang
# Morphological Analyzer
def morphological_analyzer(sentence):
lang_code = lang_detector(sentence)
if lang_code in ['ja', 'en']:
if lang_code == 'ja':
model = jp_model
elif lang_code == 'en':
model = en_model
analyzed_result = []
for w in model(sentence):
analyzed_result.append(
{
'word': w.text,
'word_length': len(w.text),
'pos_code': w.pos_,
'pos_tag': w.tag_,
'lemma': w.lemma_,
'is_hiragana_only': check_hiragana_only(w.text),
'lang_code': lang_code
}
)
else:
analyzed_result = [{
'word': sentence,
'word_length': len(sentence),
'pos_code': '',
'pos_tag': '',
'lemma': sentence,
'is_hiragana_only': check_hiragana_only(sentence),
'lang_code': lang_code,
'dummy': 'test'
}]
return analyzed_result
# lambda handler
def lambda_handler(event, context):
target_text = event['body']
try:
parsed_result = morphological_analyzer(target_text)
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*"
},
"body": json.dumps(parsed_result),
"isBase64Encoded": False
}
except Exception as err:
return {
"statusCode": 500,
"body": "Application Error Message: {}".format(err),
"isBase64Encoded": False
}
入力された文に対し、日本語か英語かその他の言語か判定し、日本語もしくは英語であれば形態素解析を実行する関数を実装しました。
これで、言語判定機能・形態素解析機能実装が完了しました。
Dockerfile作成・イメージビルド
今回利用するDockerfileを作成します。
プロジェクトのカレントディレクトリに「Dockerfile」を作成し以下のような記述をします。
FROM public.ecr.aws/lambda/python:3.8
RUN yum update
# install build libs
RUN yum groupinstall -y "Development Tools" \
&& cat /etc/yum/vars/awsregion \
&& cat /etc/yum/vars/awsdomain \
&& yum install -y which openssl
# setup python
COPY ./requirements.txt /opt/
RUN pip install --upgrade pip && pip install -r /opt/requirements.txt
# setup spacy
RUN python -m spacy download en_core_web_sm
# set function code
WORKDIR /var/task
COPY app.py .
CMD ["app.lambda_handler"]次にDockerのベースイメージをプルします。
今回使っているベースイメージは、AWSが配布しているlambda環境のイメージです。
docker pull public.ecr.aws/lambda/python:3.8そして、作成したDockerfileを元にイメージをビルドします。
以下のコマンドで実行します。
docker build -t [your-image-name] ./特段エラー等が出なければOKです。
以下のコマンドで、作成できたか確認できます。
docker images出力は以下の通りです。
REPOSITORY TAG IMAGE ID CREATED SIZE
[your-image-name] latest XXXXXXXXXX 9 minutes ago 4.96GB
public.ecr.aws/lambda/python 3.8 1cf68d18911b 9 minutes ago 603MB上記の様に確認できれば、イメージビルドは完了です。
AWS ECR接続設定
ECRの接続設定を行います。
以下のコマンドを実行します。
aws ecr get-login-password --region [region]
docker login --username AWS --password-stdin [accountID].dkr.ecr.[region].amazonaws.com
ここで[]で囲っているワードに関しては、Serverless Framework設定で書いたものを参考にしてください。
AWS ECRリポジトリ作成・イメージ登録
ECRのリポジトリを作成します。
以下のコマンドで実行します。
aws ecr create-repository --repository-name [your-repo] --image-scanning-configuration scanOnPush=true作成に成功しますと、JSON形式のリポジトリ情報が返ってきます。
次に、先ほど作成したDockerイメージをリポジトリに登録します。
ECR用にタグ付けを行い、作成したリポジトリに対しPUSHを行います。
docker tag [your-image-name]:latest [accountID].dkr.ecr.[region].amazonaws.com/[your-image-name]:latest
docker push [accountID].dkr.ecr.[region].amazonaws.com/[your-image-name]:latest処理に成功しますと、digest情報が返ってきます。
その情報をメモして、Serverless Frameworkの設定ファイル「digest」の項目に追記します。
digest情報は、「sha256:xxxxxxxxxx」のような形式です。
AWS lambdaへのデプロイ・動作確認
いよいよ、サービスをデプロイします。
以下のデプロイコマンドをプロジェクトのカレントディレクトリで実行します。
sls deployデプロイが成功すると以下のような情報が返ってきます。
記述されているエンドポイントにPOSTすれば形態素解析結果が返ってきます。
Serverless: Packaging service...
Serverless: Uploading CloudFormation file to S3...
Serverless: Uploading artifacts...
Serverless: Validating template...
Serverless: Updating Stack...
Serverless: Checking Stack update progress...
..............
Serverless: Stack update finished...
Service Information
service: pymecab-lambda-container
stage: dev
region: {region}
stack: pymecab-lambda-container-dev
resources: 12
api keys:
None
endpoints:
POST - https://[api-id].execute-api.[region].amazonaws.com/dev/spacy/parse
functions:
parse: [your-project-name]-parse
layers:
None
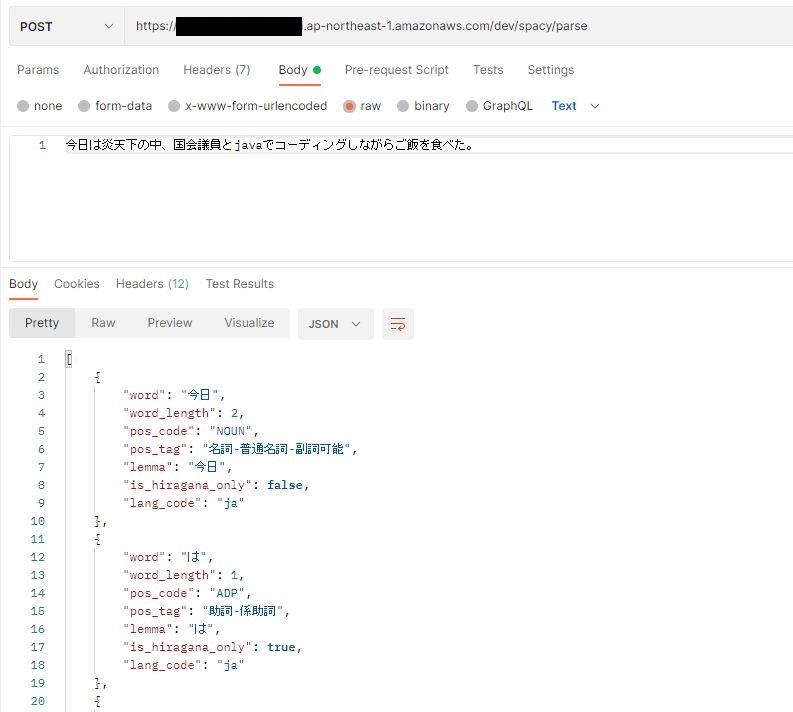
Serverless: Removing old service artifacts from S3...POSTMANでテストしてみましょう。
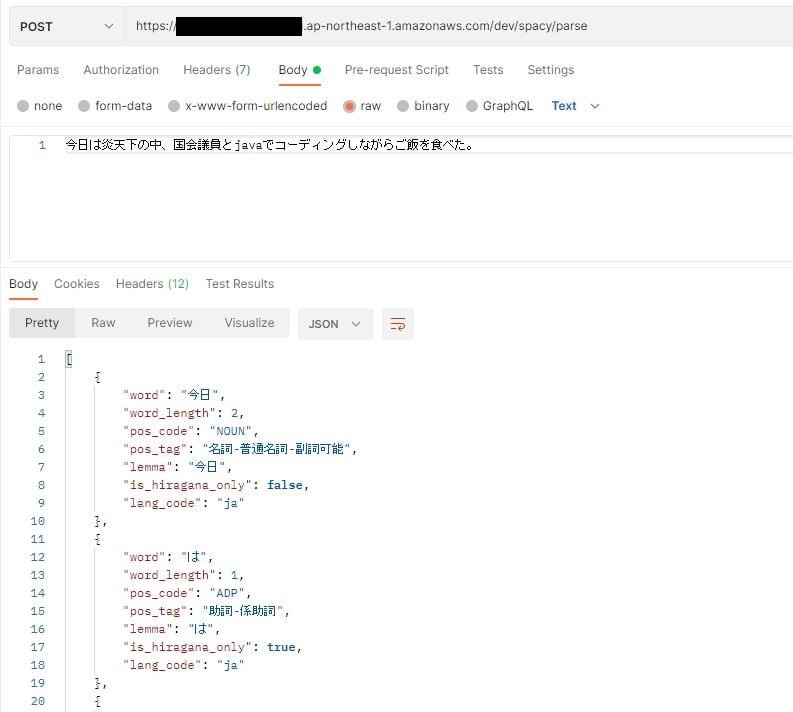
日本語は問題ない様です。
次に英語を実施してみます。
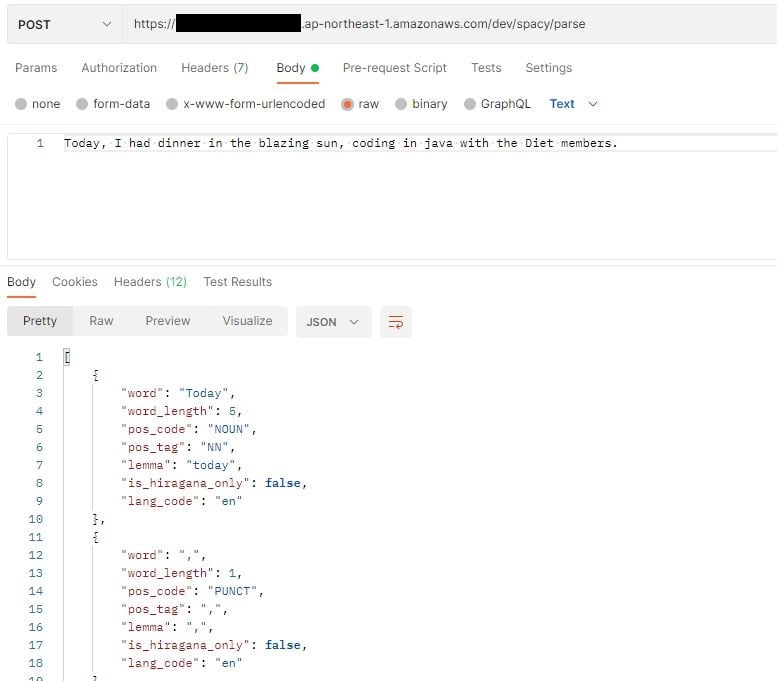
英語も無事、形態素解析できました。
まとめ
今回は、形態素解析ツールをAWS lambdaとAWS ECRを使い実装してみました。
ECRを介してlambdaでDockerが利用できることにより、サーバーレスの可能性が広がった気がします。
また、今回はユニバーサルデザインなSpaCyを利用することで必要に応じて多言語への拡張も可能です。

-3.png)
