


始めに
最近、M2 Macbook Airを入手したBudoこと荻本です。
この記事では、教師なし学習であるK-meansやその発展形のアルゴリズムについて調査を行ったので、いくつかの手法を紹介したいと思います。
K-meansとは
教師なし学習の手法の一つです。
非階層クラスタリング手法であり、以下のような工程となります。
- 各点に対しランダムにクラスタリングを行う
- 各クラスタに割り当てられた点について重心を計算する
- 各点について上記で計算された重心からの距離を計算し、距離が一番近いクラスタに割り当て直す
- 2.と3.の工程を、割り当てられるクラスタが変化しなくなるまで行う
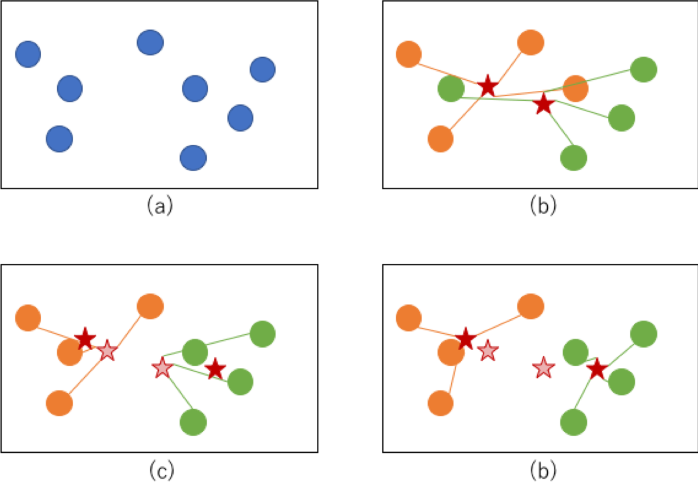
図で表現すると下記のように(a)→(b)→(c)→(d)のような順序を辿ってクラスタが収束していくイメージです。
(b)の段階でまず各点に適当にクラスタが割り振られ、その重心が計算されます(重心は赤星で図示)。
(c)ではその重心との距離のもとに再度クラスタが割り当てられます(新しい重心を赤星で図示、古い重心を薄い赤星で図示)。
この工程を繰り返し(d)のようにクラスタが変化しないように収束すれば完了です。
X-meansとは
K-meansにはクラスタ数を最初に決めなければならないという制約があります。
X-meansはそのクラスタ数を自動推定する発展形のアルゴリズムです。
推定方法としては、k-meansの逐次繰り返しとBICによる分割停止基準を用いて最適なクラスター数を決定することにあります。
つまり、複数のクラスタ数パターンでBICが最大となるクラスタ数を求めていくイメージです。
なので、試行するクラスタ数の最大値は決める必要があります。
G-meansとは
X-means同様、クラスタ数を自動推定する発展形のアルゴリズムです。
アルゴリズムの順序としては以下のステップになります。
- 各点に対しランダムにクラスタリングを行う
- 1で決めた中心点を初期値として使ってK-meansによるクラスタリングを行う
- 2でできた各クラスタ内のサンプルに対してガウス分布に従うかの統計検定(Anderson–Darling検定)を行う
- 帰無仮説が棄却された場合はクラスタを2つに分割し帰無仮説が棄却されない場合はそのクラスタを確定する
- クラスタが分割されなくなるまで2から4を繰り返す
コチラのアルゴリズムに関しては、計算コストの関係上クラスタ数の最大値を決める必要があります。
比較検証
今回は各アルゴリズムの比較を行うため、利用するデータセットはscikit-learnにあるmake_blobsを使って二次元のダミーを作成します。
まずはクラスタ数4での各クラスの標準偏差を0.5としてダミーを生成、このデータに対してX-meansとG-meansの結果を比較します。
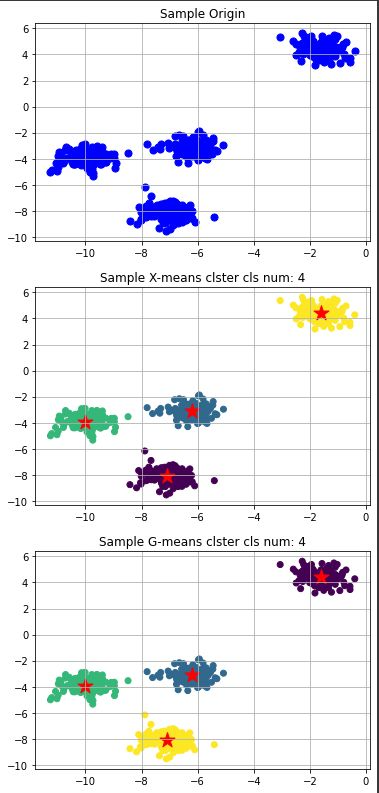
この程度であればどちらのアルゴリズムでも問題ない様です。
次にクラスタ数5での各クラスの標準偏差を0.8としてダミーを生成、このデータに対してX-meansとG-meansの結果を比較します。(上記のコードのパラメータを弄って再生成)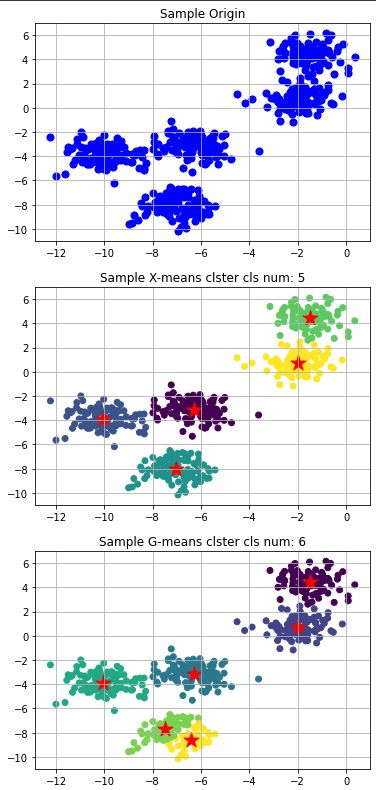
ここで違いが出ました。
感覚的な正しさとしては、X-meansの方が正しいと感じます。
次はかなり極端なダミーを生成します。
クラスタ数200での各クラスの標準偏差を1.5としてダミーを生成、このデータに対してX-meansとG-meansの結果を比較します。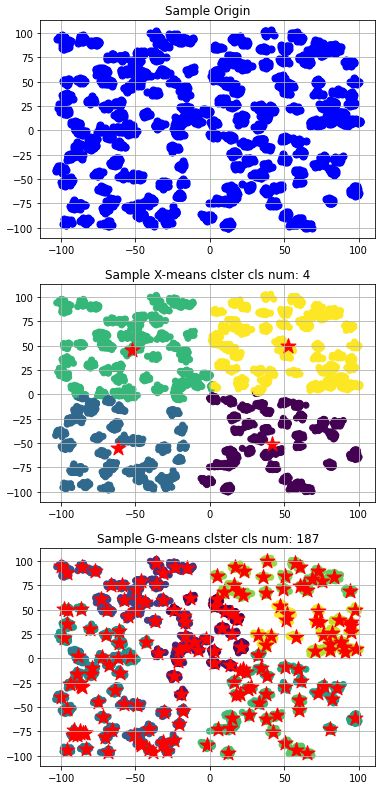
コチラの検証では、G-meansの方が近くなりました。
この検証より、クラスタ数が多い場合はG-meansの方が良く、クラスタ数が少ない場合はX-meansの方が良い結論になりました。
具体的にどちらが良いか言えない状況ですが、状況に応じて利用していく必要があると思います。


