はじめに
Qlik Senseで、階層的なデータ構造をテーブル形式に変換することができるプレフィックス(データロードの前処理)である、「Hierarchy」プレフィックスと「HierarchyBelongsTo」プレフィックスについて紹介します。
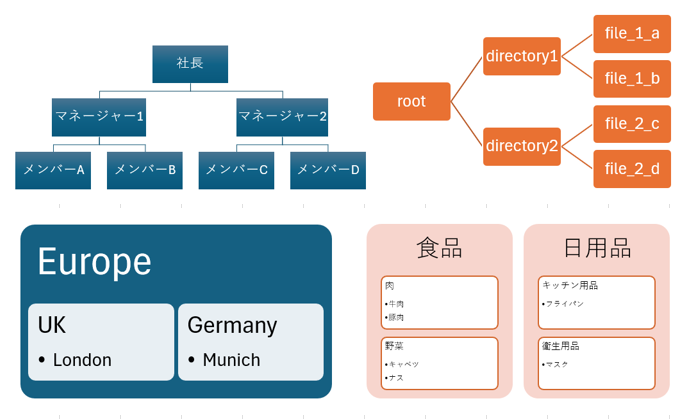
階層的なデータ構造の例としては、以下のようなものがあります。
- 組織図
- PCファイルのディレクトリ構造
- 地理的情報
- 製品管理情報


Hierarchyプレフィックス
概要
Hierarchyプレフィックスを使用することにより、読み込むデータごとに階層関係において親にあたるデータが列挙されたテーブルを、最上層までの親子関係が列挙されたテーブルに変換することができます。
ここで、読み込むデータには以下の3つを含む必要があります。
※以下、この読み込むデータの各行のことを「ノード」と呼ぶことにします。
- ①ノードのID
- ②ノードの親にあたるノードのID
- ③ノードのIDに対応する名称
構文は以下のようになります。(Qlik Senseの公式ドキュメントより引用)
Hierarchy (NodeID, ParentID, NodeName, [ParentName, [PathSource,
[PathName, [PathDelimiter, Depth]]]])(loadstatement | selectstatement)
| 引数 | 必須 | 説明 |
| NodeID | Yes | 上記①が入っている列名 |
| ParentID | Yes | 上記②が入っている列名 |
| NodeName | Yes | 上記③が入っている列名 |
| ParentName | No | 新たに作成される、ParentIDに対応するNodeNameが入る列名 省略した場合、この項目は作成されません |
| ParentSource | No | 新たに作成される、NodeIDを起点とした最上層までの親関係を記述する際に使用する項目名 省略した場合、NodeName が使用されます(読み込むデータの中にある列であればどれでもよい) |
| PathName | No | 新たに作成される、NodeIDを起点とした最上層までの親関係を記述したデータが入る列名 ParentSourceを省略した場合、この項目は作成されません |
| PathDelimiter | No | PathNameで区切り記号として使用する文字列 省略した場合、「/」が使用されます |
| Depth | No | 新たに作成される、NodeIDを起点とした最上層までの階層数が入る列名 省略した場合、この項目は作成されません |
Hierarchyプレフィックスは、LOAD文または SELECT文の前に置いて使用し、通常、Hierarchyプレフィックスを使用して作成されたテーブルのレコード数は、元々のノード数と同じになります。
また、NodeIDを起点とした最上層までの親がそれぞれ入る列が新たに作成されます。
具体例を見てみます。
具体例
今回使用するのは、以下のような組織図のデータです。

このようなデータに対して、以下のロードスクリプトでデータを読み込みます。
Hierarchy(社員No, 上長No, 社員名, 上長名, 社員名, 関係性, '>', 深さ)
社員情報:
LOAD * inline [
社員No, 上長No, 社員名
1, , '社長'
2, 1, 'マネージャーA'
3, 1, 'マネージャーB'
4, 2, 'メンバー1'
5, 2, 'メンバー2'
6, 3, 'メンバー3'
7, 3, 'メンバー4'
]
すると、次のようなテーブルが得られます。

HierarchyBelongsToプレフィックス
概要
HierarchyBelongsToプレフィックスを使用することにより、読み込むデータごとに階層関係において親にあたるデータが列挙されたテーブルを、最上層までの親子関係が列挙されたテーブルに変換することができます。
ここで、読み込むデータには以下の3つを含む必要があります。
※以下、この読み込むデータの各行のことを「ノード」と呼ぶことにします。
- ①ノードのID
- ②ノードの親にあたるノードのID
- ③ノードのIDに対応する名称
構文は以下のようになります。(Qlik Senseの公式ドキュメントより引用)
HierarchyBelongsTo (NodeID, ParentID, NodeName, AncestorID, AncestorName,
[DepthDiff])(loadstatement | selectstatement)
| 引数 | 必須 | 説明 |
| NodeID | Yes | 上記①が入っている列名 |
| ParentID | Yes | 上記②が入っている列名 |
| NodeName | Yes | 上記③が入っている列名 |
| AncestorID | Yes | 新たに作成される、NodeIDに対応する親から先祖までのNodeIDが入る列名 |
| AncestorName | Yes | 新たに作成される、AncestorIDに対応するNodeNameが入る列名 |
| DepthDiff | No | 新たに作成される、NodeIDを起点としたAncestorIDまでの[階層数-1]が入る列名 省略した場合、この項目は作成されません |
Hierarchyプレフィックスは、LOAD文または SELECT文の前に置いて使用し、通常、Hierarchyプレフィックスを使用して作成されたテーブルのレコード数は、元々のノード数より増加します。
Hierarchyプレフィックスとの相違点
本質的な違いとしては、Hierarchyプレフィックスは最上層までの隣接する親子関係を横方向に(ノードに対して列を増やして)列挙するのに対し、
HierarchyBelongsToプレフィックスは最上層までの隣接する親子関係を縦方向に(ノードに対して行を増やして)列挙します。
Hierarchyプレフィックスは、組織図やPCファイルのディレクトリ構造のような、ノードの親子関係が明確であるようなデータへの使用に適しており、
HierarchyBelongsToプレフィックスは地理的情報や製品管理情報など、複数の上位ノードに属するような(ある種の包含関係を持つような)データへの使用に適しています。
具体例を見てみます。
具体例
今回使用するのは、以下のような組織図のデータです。

このようなデータに対して、以下のロードスクリプトでデータを読み込みます。
HierarchyBelongsTo (地名ID, 所属地名ID, 地名, 所属地名ID, 所属地名, 深さ)
地名情報:
LOAD * inline [
地名ID, 所属地名ID, 地名
1, 4, 'London'
2, 3, 'Munich'
3, 5, 'Germany'
4, 5, 'UK'
5, , 'Europe'
];
すると、次のようなテーブルが得られます。

以上になります。ご覧いただきありがとうございました。
Qlik Senseを体験してみませんか?
INSIGHT LABではQlik紹介セミナーを定期開催しています。Qlik SenseとQlikViewの簡単な製品概要から、Qlikの特性である「連想技術」のご紹介、デモを通してQlik SenseとQlikViewの操作感や美しいインターフェースをご覧いただきます。企業の大切な資産である膨大なデータからビジネスを発見する 「Business Discovery」を是非ご体験ください。