


こんにちは。Michaelです。
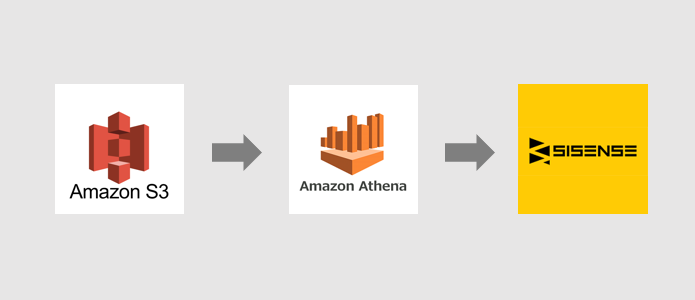
Sisenseの純正コネクタの中には、Athenaドライバーといったものがあります。これを使えばS3からSisenseにデータを持ってくることが可能になります。

AthenaとはS3に格納されたファイルに対してクエリを打つことができるAWSのサービスです。クエリ量に対しての従量課金となります。
今回はS3に置いてあるデータを、Athena経由でSisenseに持ってこようと思います。
S3の設定
まずは、今回のデモで使うデータをS3に入れます。「transaction_1.csv」という、2万件ぐらいのシンプルなトランザクションデータを用意してあります。
AWSマネージメントコンソールでS3に移動し、新しくバケットを作成します。その中に、dataフォルダーと、Athenaのクエリを保存するフィルダーで必要となるresultという2つを作成します。
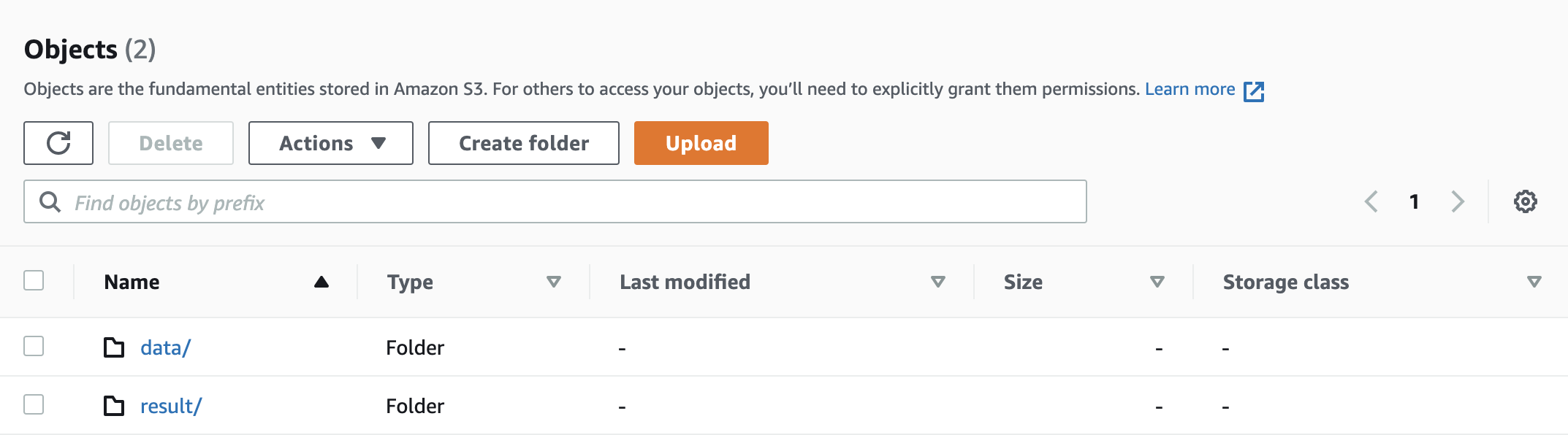
※バケットのルートにおいて
サンプルデータの「transaction_1.csv」をdataフォルダーに入れます。
resultフォルダーは空のままにしておきます。ここでパスを作っておかないと、Sisense側で接続した際に、エラーとなるので注意です。
s3://<任意のバケット名>/data/
Athenaで読み込むデータを格納する場所。ロードしたいデータを格納。
s3://<任意のバケット名>/result/
Athenaで投げたクエリの結果を格納する場所。ここでは空でOK。
では次に、Athenaの設定にいきましょう。
Athenaの設定
AWSマネージメントコンソールでAthenaに移ります。
テーブルを作成し、S3バケットデータからテーブルの作成を選択します。
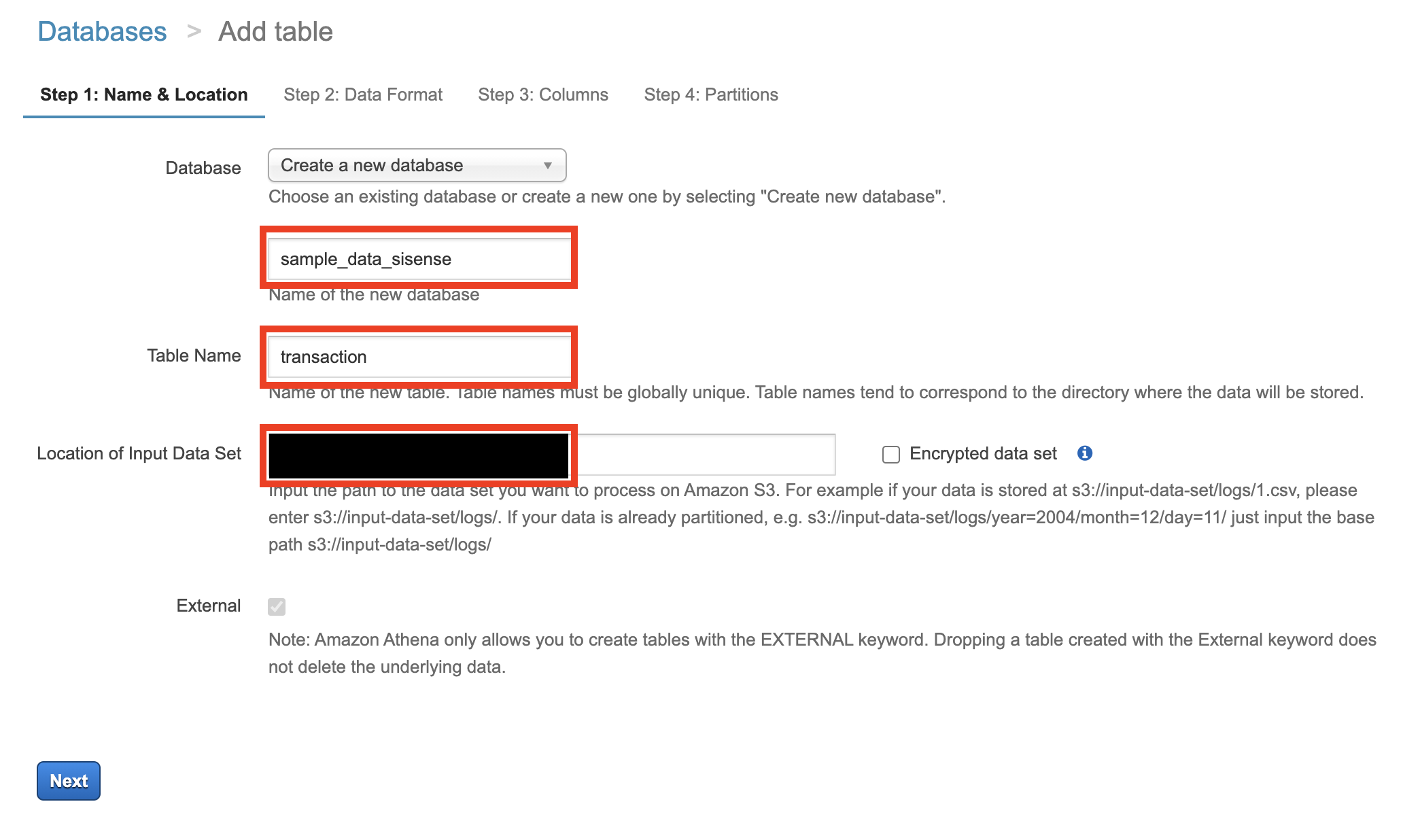
データベース名、テーブル名を任意で設定し、インプットデータセットの場所は、先ほどのDataフォルダーのS3のパスを指定します。
S3://<任意のバケット名>/<データが格納されているフォルダ>
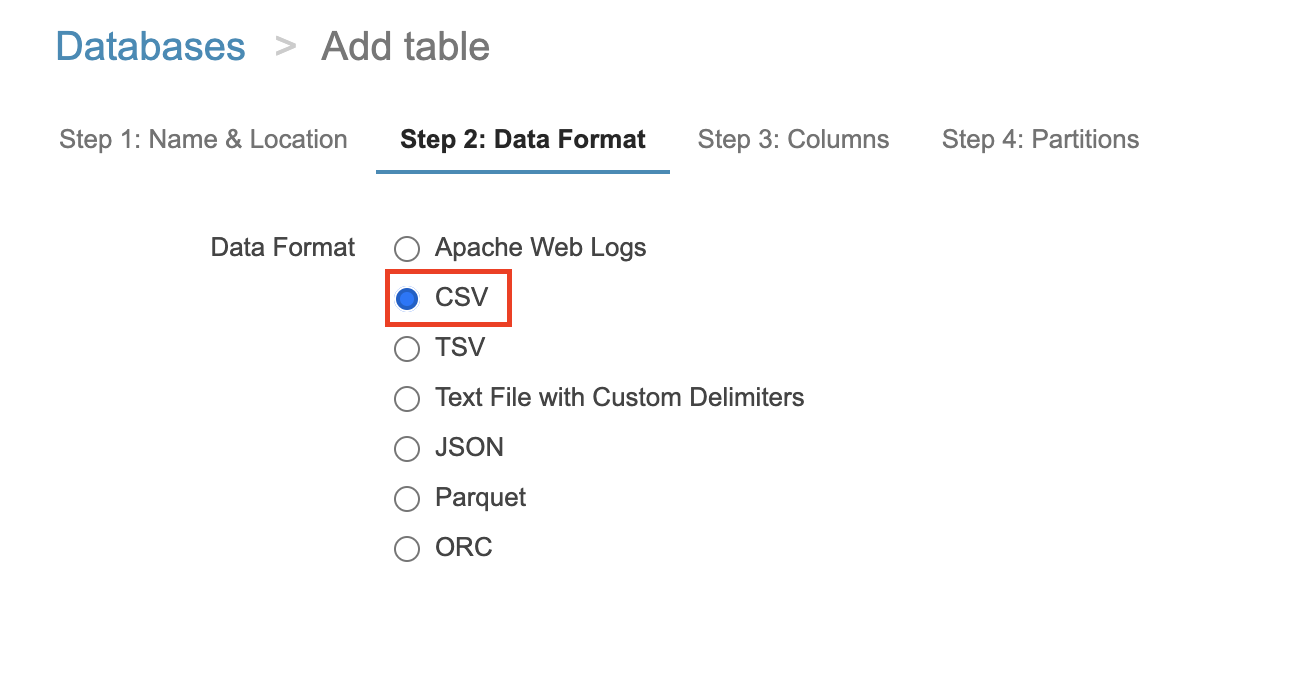
データフォーマットの指定をします。今回はCSVファイルです。
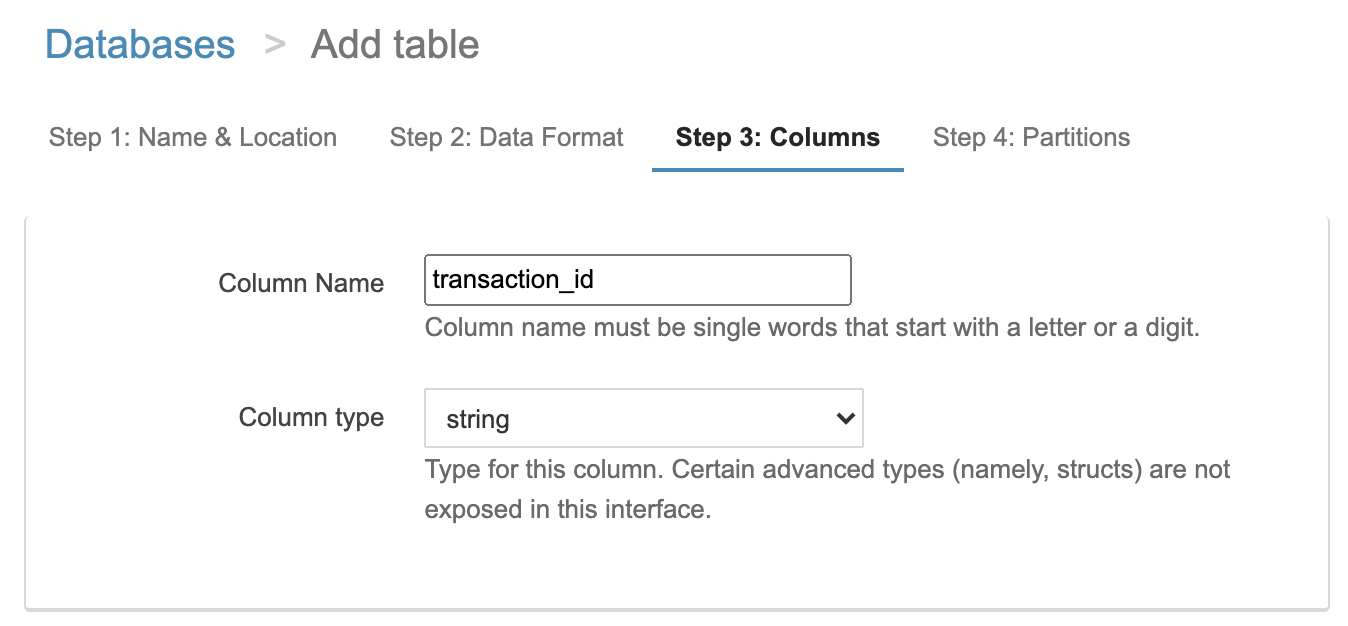
取り込みデータと同じカラムを用意してあげます。全行程は割愛しますが、今回は4カラムあります。下記のように他のカラムも同じように設定します。
パーティション設定の画面が次に出ます。今回はデータサイズが1MB以下と小さいのでとくに設定をせずに進めます。実際にサイズの大きなデータに対してAthenaを多用する場合には、コスト最適化の面でパーティションは必須となります。
これでテーブルを作成できました。テーブル横の点をクリックし、プレビューして確認します。
1行目でheaderが読み込まれてしまっています。
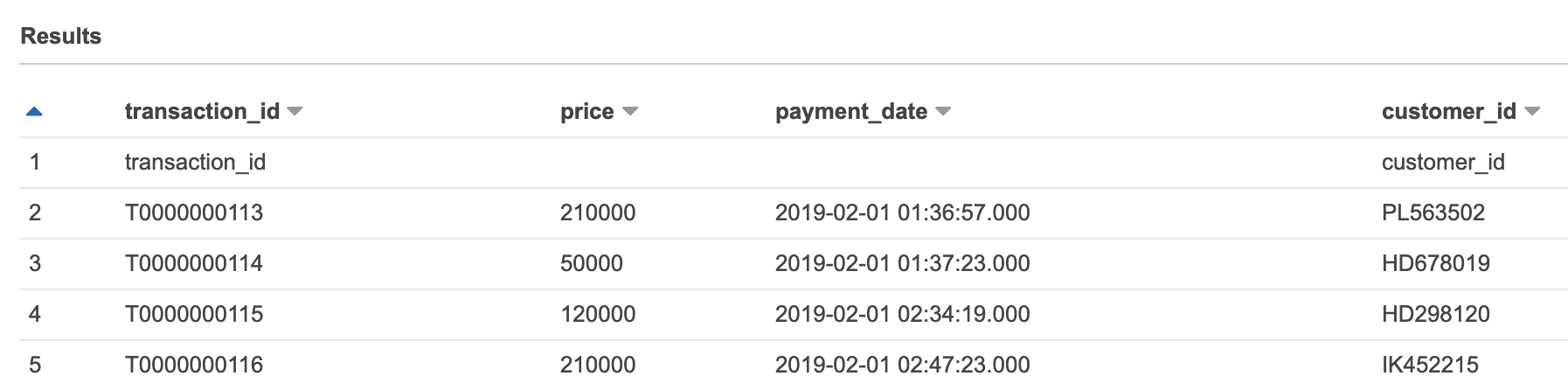
これを直すには、DDLでテーブルを作成し、1行目を無視するということを明示してあげる必要があります。DDLは、先ほどテーブル作成した際に、クエリエディタに自動生成されているので、一度作成したテーブルを削除し、TELEPROPERTIESの中に以下の一文を書き加えて再度作成します。
'skip.header.line.count' = '1'
このクエリを実行します。テーブルが作成され、プレビューすると。。
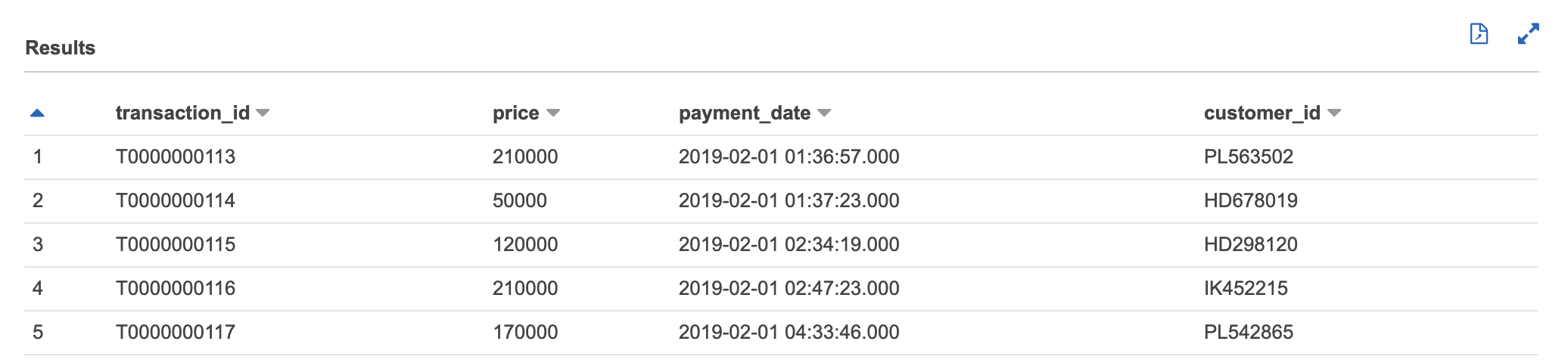
今度は問題なさそうです。
試しにSELECT文を打ってみます。
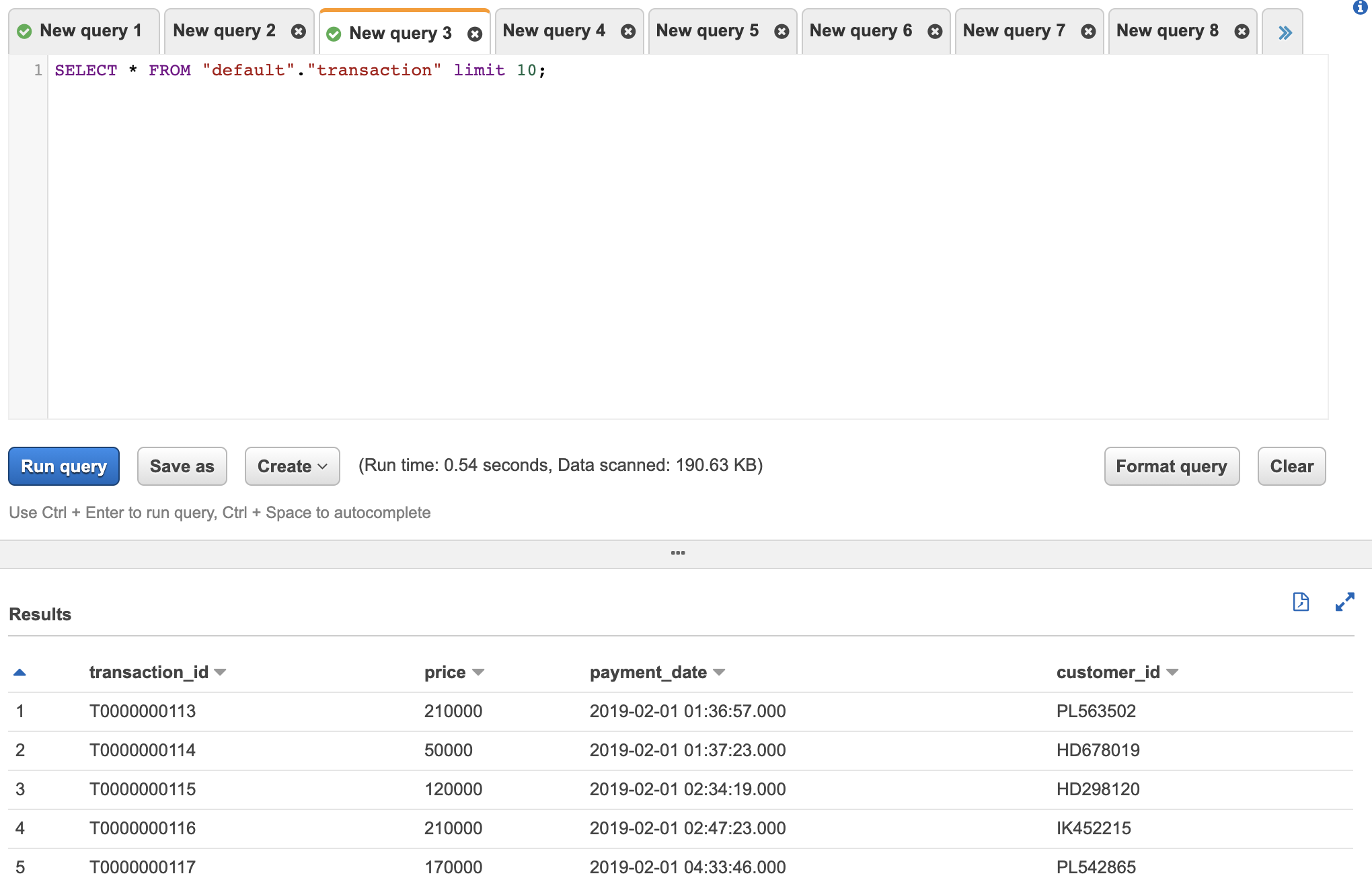
ヘッダーが消えて、問題なさそうです。
これで、準備が整いました。次はIAMの設定に行います。
IAMの設定
IAMの画面に移ります。
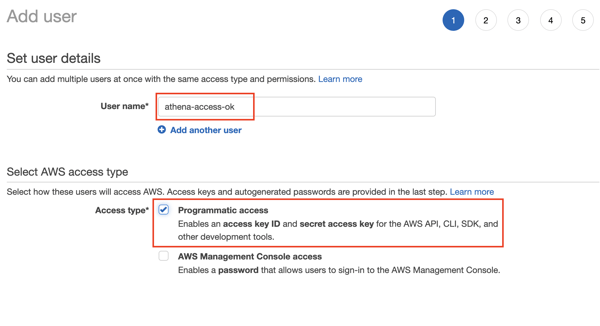
今回は新しくIAMユーザーを作成します。
Name: athena-sisense-ok
アクセスタイプで「プログラムでのアクセス」にチェックを入れておきましょう。
この新しく作ったユーザーに、AthenaへのフルアクセスとS3へのフルアクセスの2つの権限を与えます。
「既存のポリシーをアタッチ」して、「Athenaへのフルアクセス」を許可します。
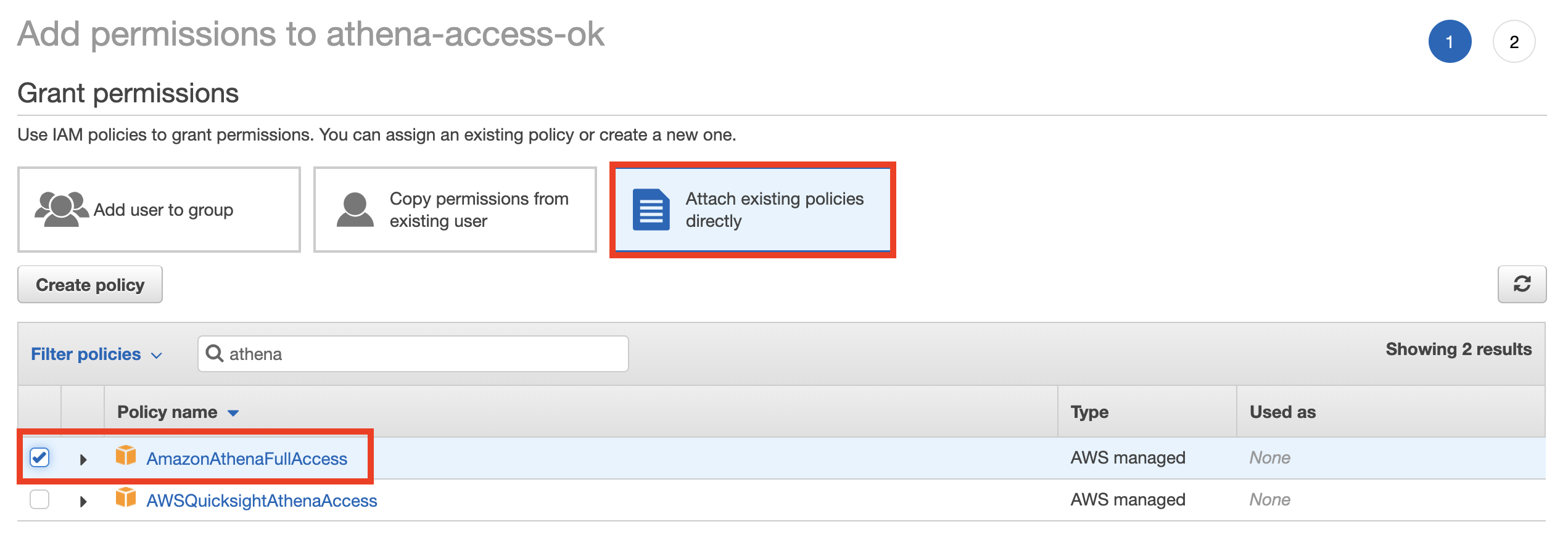
同様に、S3もフルアクセスを許可します。
下記の2つのポリシーがアタッチされました。

任意でタグを設定し、ユーザーを作成します。
アクセスキー、シークレットキーが表示されます。Sisense側でAthenaに接続する際に使用するので、csvでダウンロードするか、メモ帳にコピペしておきましょう。
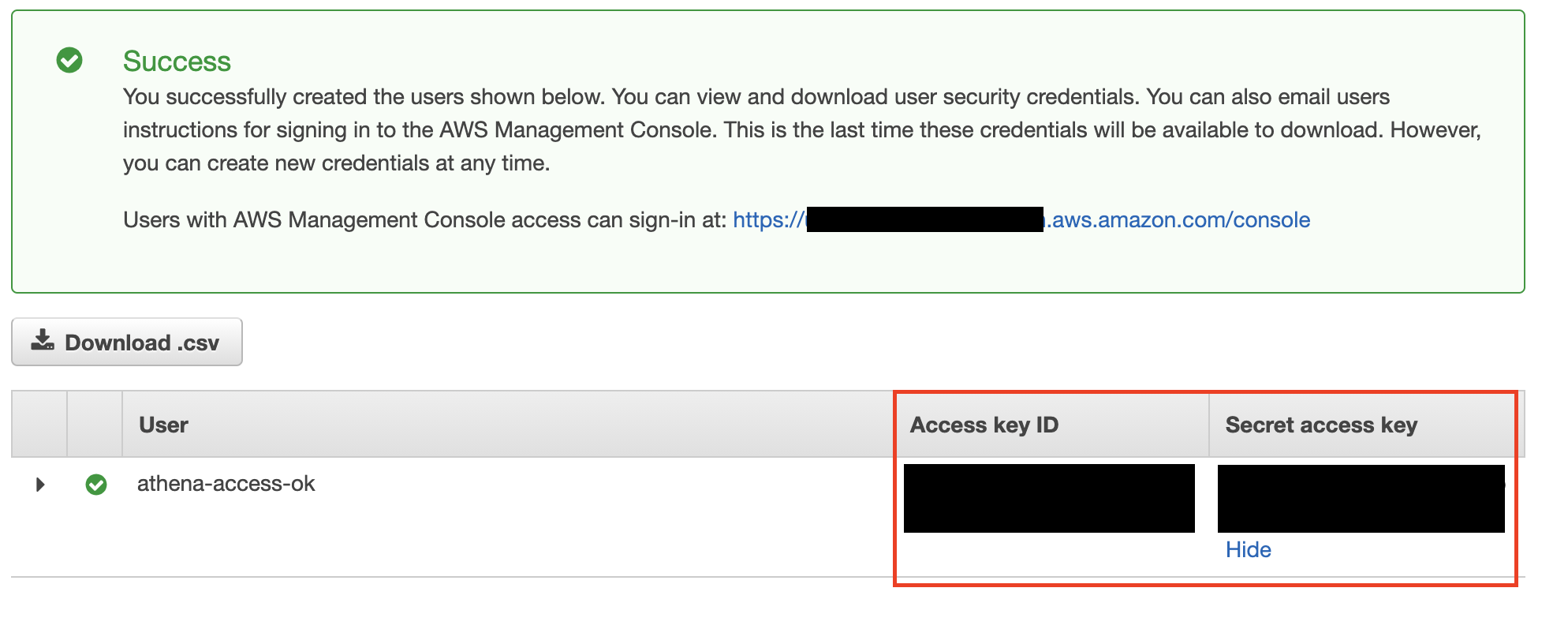
AWS側の準備が整いました。Sisenseに移ります。
Sisenseからの接続
elasticCubeで、「+データ」ボタンを押します。コネクタの中からAmazon Athenaを選びましょう。

今回Basic, Advancedと2種類の入力方法がありますが、今回はBasicのままで入力していきます。
Region: Athenaのリージョンを指定。今回は東京リージョンなので、ap-northeast-1を入力。
S3 Output Location: S3内でAthenaのクエリの結果が格納されているパス。今回は、S3://<作成したバケット名>/result を入力。
Access Key: IAMユーザーのアクセスキー。今回は、athena-access-okのものを入力。
Secret Key: IAMユーザーのシークレットキー。今回ははathena-access-okのものを入力。
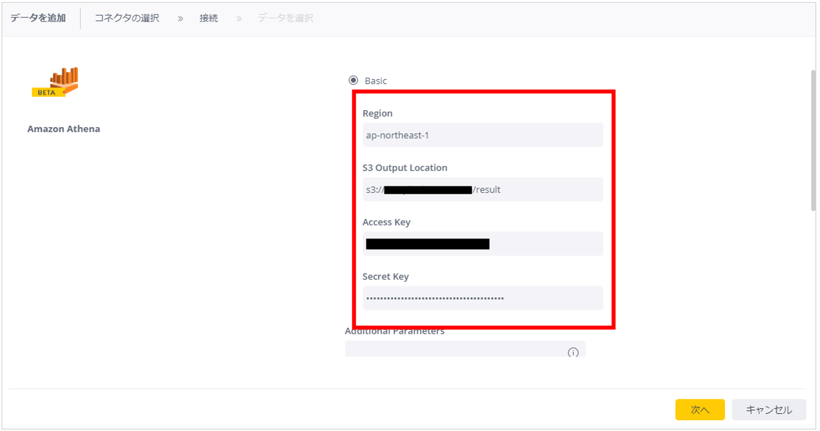
上記の4つの情報を入力して、「次へ」を押すと、
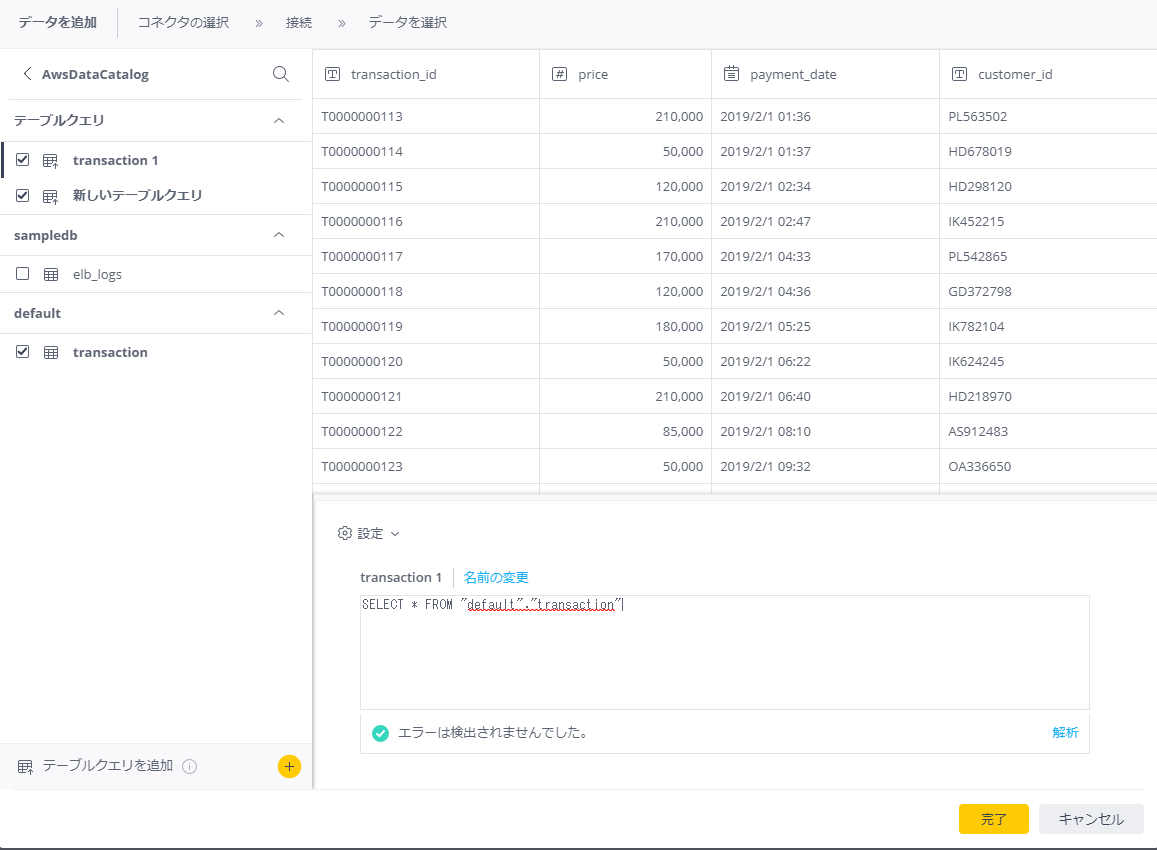
接続が完了しました!プレビューも問題なしです。
これで、S3に格納されたファイルに対して、SQLを叩いて、Sisenseに取り込むことができます。
まとめ
今回は、S3のデータをAthena経由でSisenseに持ってきました。実は以前、S3をそのままSisenseにロードしようと、cDataのコネクタでトライしたことがあったのですが失敗した苦い思い出があります。Athenaドライバーを使えば簡単にロードできてしまうので、びっくりしてしまいました。
留意点としては、クエリ毎に課金されるので、データサイズが大きい場合には、Athenaの設定でパーティションを有効にするなど、コスト最適化をしながら使っていくことになります。
「S3に置いてあるJSONのような半構造化データをGlueでテーブル化して、Sisenseで分析する」なんてことも実現できてしまうのでしょうか。Athena、とっても便利です。
それではまた!Viva, Sisense!!
Sisenseを体験してみませんか?
INSIGHT LABではSisense紹介セミナーを定期開催しています。Sisenseの製品紹介や他BI製品との比較だけでなく、デモンストレーションを通してSisenseのシンプルな操作性やプレゼンテーション機能を体感いただけます。



.png)
