1.はじめに
Spotifyは楽曲に対して、どのような曲であるかを示すデータを持っており、誰でも取得することが可能です。今回は、「宇多田ヒカル」の全アルバム、全シングルの曲のメタデータをSpotify APIを使用して取得して、分析していこうと思います。
さて、データを見る前に私はいくつか仮説を立てました。なんとなくですが、音楽業界について、こうであろうと個人的に思ったことです。
- キャリアが長くなるにつれて、曲が長くなる
- キャリアが若いころはエネルギッシュな曲が多く、キャリアが長くなると落ち着いた曲が増える
- 夏に出す曲はアップテンポ、冬に出す曲はバラードが多い
- キャリアが長くなるにつれて、インスト部分が長くなり、よりエクスペリメンタルになる
- 人気度は初期に高く、徐々に下がっていく
- キャリア初期ではマイナー超の寂しげな曲が多いが、キャリアが長くなるにつれて、メジャー調なハッピーな曲が多くなる
この仮説がどれだけ合っているかを今回のデータから何か見いだせればと思います。
2. データの取得までの準備
以下、順番に解説します。
Client IDとClient Secretの取得
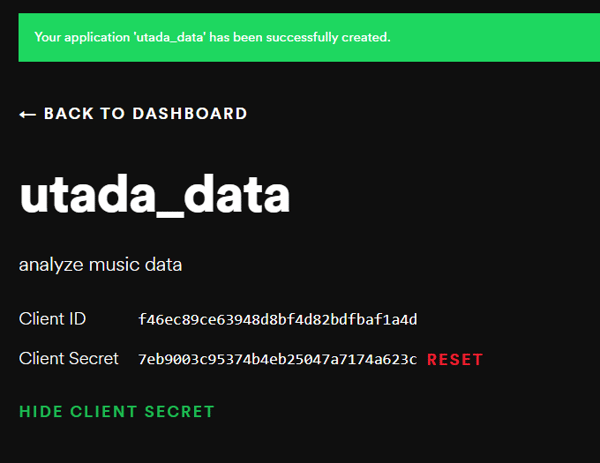
最初のステップとして、Spotify for Developersにて、Spotify APIを使用するために必要なclient IDとsecret keyを取得する必要があります、Spotify DeveloperにSpotifyの(有料)アカウントのクレデンシャルでログインし、ダッシュボード右上の「Create an App」を選択します。

App NameとApp Descriptionを何でもよいので入力して、Createをクリックします。ここでは、App nameを「utada_data」、App descriptionを「analyze music data」としました。
次の画面で、App Nameの下に「Client ID」が確認できます。その下の「SHOW CLIENT SECRET」をクリックすると、「CLIENT SECRET」も確認できます。
この2つが必要になるので、テキストエディターなどにコピーしておきましょう。
Playlistの作成とplaylist IDの取得
次に、SpotifyのPlaylistのIDを取得します。今回の分析対象曲は宇多田ヒカルの全アルバム収録曲、全シングルとして、インストトラックやリミックスは除外します。新しくplaylistを作成し、対象曲全て96曲を入れます。ウェブのSpotifyプレイヤーから、このPlaylistを開き、URLを確認すると、open.spotify.com/playlist/の後に英数字が確認できます。これがplaylist IDになります。この数字をコピーします。
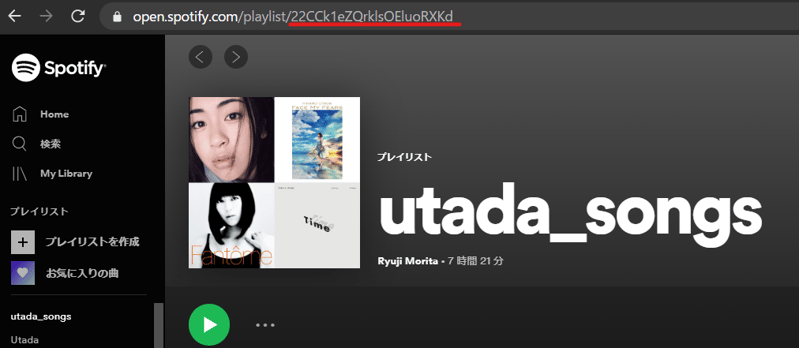
client IDとClient Secret、そして分析対象曲を入れたPlaylistIDの用意がこれでできました。次からPythonを使って曲情報を取得していきます。
3. データの取得
次に、Pythonを使って宇多田ヒカルの曲データを取得します。
Python環境として今回は、便宜上のためGoogle Colabを使いましょう。Google ColabはJupyter Notebookがインストールなしで、無料でChrome上で使える機能です。GPUが無料(TPUも!)で使えて、Pythonやデータサイエンス系のライブラリのインストールなどの環境構築が不要、ノートブックの共有がとても楽チン、ということなしでいいところばかりです。
Google ColabをGoogleドライブ上から起動します。今回はPythonのSpotify API用のプラグイン、Spotipyを使って宇多田ヒカルの曲のメタデータ情報を取得します。以下のコードの通り、spotipyをgoogle colabの環境にインストールして、その他、必要なライブラリもインポートしましょう。
# colabの環境にspotipyをインストール !pip install spotipy
import pandas as pd
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import time
以下のコードを入力しましょう。client_idと、client_secretにはSpotify for Developersで取得した値を入れます。
# spotify developerから取得したclient_idとclient_secretを入力 client_id = '〇〇〇' client_secret = '△△△'
client_credentials_manager = SpotifyClientCredentials(client_id, client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
次にユーザー名と、プレイリストのIDを指定して、ids = getTrackIDs('username', 'playlist_id')のusernameとplaylist_idの部分を皆様のIDで置き換えてください。
def getTrackIDs(user, playlist_id): ids = [] playlist = sp.user_playlist(user, playlist_id) for item in playlist['tracks']['items']: track = item['track'] ids.append(track['id']) return ids
# Spotifyのユーザー名と、プレイリストのIDを入力
ids = getTrackIDs('username', 'playlist_id')
取得できているか確認しましょう。
print(len(ids))
print(ids)

96曲分のtrack idが取得できているのが確認できます。
次に、曲のメタデータを取得する関数を以下のように定義します。
def getTrackFeatures(id): meta = sp.track(id) features = sp.audio_features(id)
# meta
name = meta['name']
album = meta['album']['name']
artist = meta['album']['artists'][0]['name']
release_date = meta['album']['release_date']
length = meta['duration_ms']
popularity = meta['popularity'] # features
acousticness = features[0]['acousticness']
danceability = features[0]['danceability']
energy = features[0]['energy']
instrumentalness = features[0]['instrumentalness']
mode = features[0]['mode']
liveness = features[0]['liveness']
loudness = features[0]['loudness']
speechiness = features[0]['speechiness']
tempo = features[0]['tempo']
time_signature = features[0]['time_signature']
valence = features[0]['valence']
track = [name, album, artist, release_date, length, mode, popularity, danceability, acousticness, energy, instrumentalness, liveness, loudness, speechiness, tempo, time_signature, valence]
return track
上の関数を、先ほど取得した個々のtrack idにループさせて、全曲のメタデータを取得します。DataFrame(2次元のデータ構造)に格納して、headメソッドでデータの確認します。
# loop over track ids tracks = [] for i in range(len(ids)): time.sleep(.5) track = getTrackFeatures(ids[i]) tracks.append(track)
# create dataset
df = pd.DataFrame(tracks, columns = ['name', 'album', 'artist', 'release_date', 'length', 'mode', 'popularity', 'danceability', 'acousticness', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'time_signature', 'valence'])
df.head()
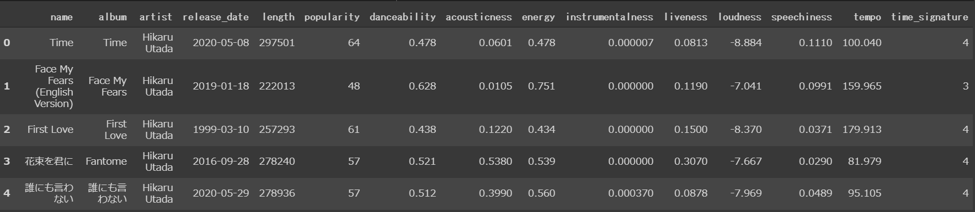
取得できました!
最後に取得したデータをCSVファイルで出力して、google colab上でダウンロードできるように以下の通り記述します。
df.to_csv("spotify_utada_songdata.csv", sep = ',')
from google.colab import files
files.download('spotify_utada_songdata.csv')
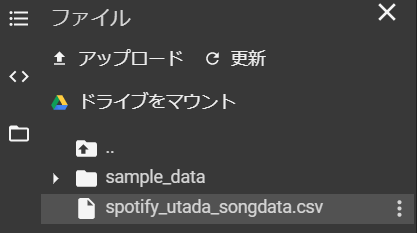
これで準備は完了です!このCSVファイルをダウンロードして、Sisenseにデータを取り込んでいきましょう。
4.データの取り込み
Sisense上から、先ほどのダウンロードしたCSVファイルを読み込みます。
テーブル名を「song_data」に変更し、ビルドしてからPreviewでデータを見てみましょう。
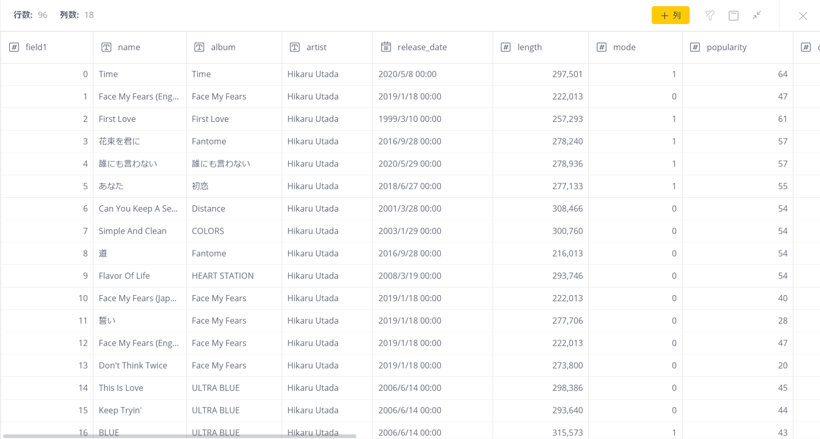
「field1」という一番左のカラムはPythonのDataFrame化した際にインデックス番号を振るのに作成されたので、必要ありません。ドロップします。
楽曲データの定義
Previewを見ると、カラムがずいぶん沢山あることに気づくと思います。
楽曲の各メタデータの説明は以下の通りです。
name 曲名
album
アルバム名
artist
アーティスト名
release_date
リリース日
length
曲の長さ
millsecondsで入る
popularity
人気度
danceability
ダンス度(テンポ、リズムの一定感、ビートの強さなどから算出)
0.0-1.0
1.0がダンス度が高いことを示す
acousticness
アコースティック度
0.0-1.0
1.0がアコースティック度高いことを示す
energy
エネルギー
fast, loud, noisyであれば1に近づく
0.0-1.0
instrumentalness
インスト感
0.0-1.0
0.5以上でインスト
mode
曲調を示す。
メジャーが1,
マイナーが0
liveness
ライブさ
0.0-1.0
レコーディングにオーディエンスが含まれているかで判断されている
0.8以上でライブトラックの可能性大
loudness
音の大きさ
-60 〜 0 db
speechiness
スピーチ度
トークショー、オーディオブック、ポエムなどは1に近くなる
0.33以下で音楽
valence
曲のポジティブ度
0.0-1.0
1がポジティブ(happy, cheerful, euphoric)
0がネガティブ (sad, depressed, angry)
tempo
曲のテンポ
BPMの数字が入る
time_signature
拍子
次に、分析のためのカラムを追加していきます。
カスタム列の追加
データを見ると、「album」のところにはシングル名とアルバム名が混在していますね。
これを区別できるようなカテゴリーをカスタム列で追加しましょう。
宇多田ヒカルさんのアルバムは2020年6月の時点では、以下の7枚です。
②DISTANCE
③DEEP RIVER
④ULTRA BLUE
⑤HEART STATION
⑥Fantome
⑦初恋
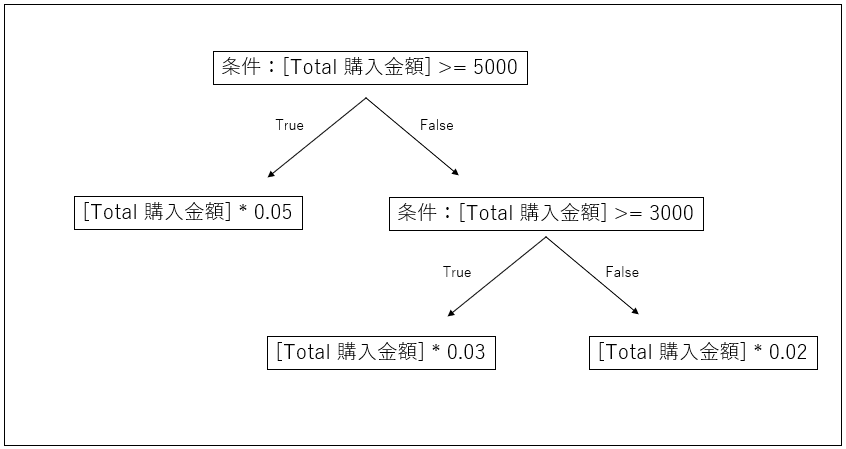
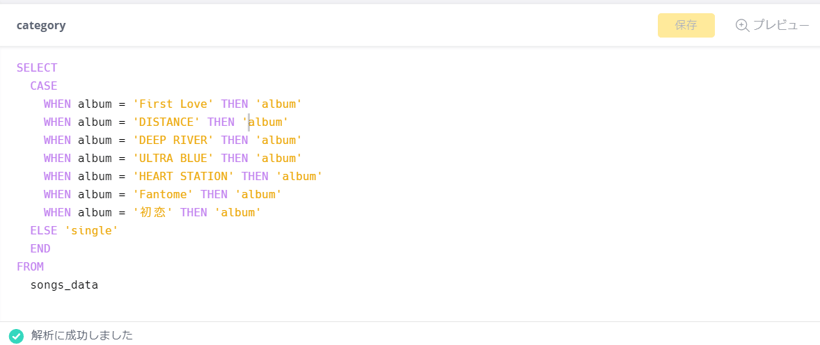
CASE文を使い、albumが上記の場合は「album」、それ以外を「single」とします。列名は「category」としておきます。
SELECT
CASE
WHEN album = 'First Love' THEN 'album'
WHEN album = 'DISTANCE' THEN 'album'
WHEN album = 'DEEP RIVER' THEN 'album'
WHEN album = 'ULTRA BLUE' THEN 'album'
WHEN album = 'HEART STATION' THEN 'album'
WHEN album = 'Fantome' THEN 'album'
WHEN album = '初恋' THEN 'album'
ELSE 'single'
END
FROM
songs_data
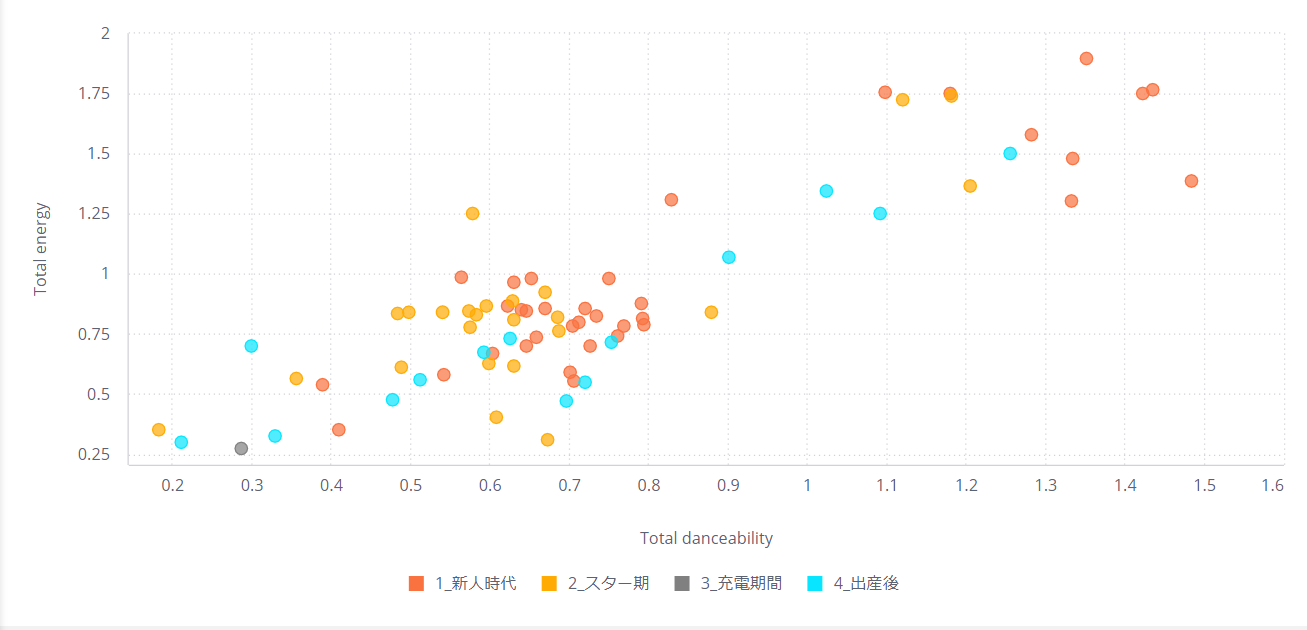
次に、キャリアごとにどう楽曲が変わっていったかを見るために彼女のキャリアを4つのステージに分けることとします。再度ディスコグラフィを見てみましょう。
② DISTANCE 2001年
③ DEEP RIVER 2002年
④ ULTRA BLUE 2006年
⑤ HEART STATION 2008年
⑥ Fantome 2016年
⑦ 初恋 2018年
「HEART STATION」と「Fantime」、この間に数年のギャップがあることが見て取れると思います。この間に、母の死、結婚、出産など、様々なライフイベントを経験されています。この期間を「充電期」としましょう。その他も、キャリア時期により以下のようにグルーピングしました。
スター期 2006 - 2008
充電期 2009 - 2015
出産後 2016 -
カスタム例を追加し、名前を「stage」とし、CASE分で以下のように書いていきます。
SELECT
CASE
WHEN getYear(release_date) BETWEEN 1998 AND 2003 THEN '1_新人時代'
WHEN getYear(release_date) BETWEEN 2004 AND 2008 THEN '2_スター期'
WHEN getYear(release_date) BETWEEN 2009 AND 2015 THEN '3_充電期間'
WHEN getYear(release_date) BETWEEN 2016 AND 2020 THEN '4_出産後'
END
FROM
songs_data

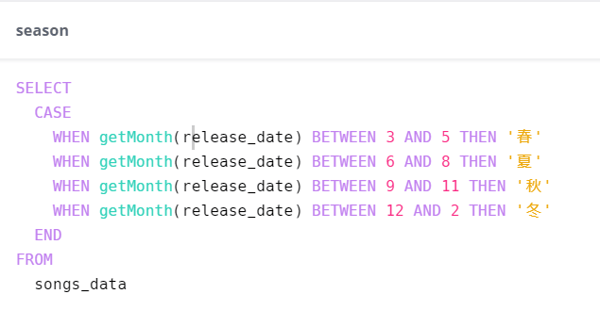
最後に、リリース時期と曲メタデータの相関を見るために、4つの季節にグルーピングします。release_date以下のように、春夏秋冬と分別します。
夏 6-8月
秋 9-11月
冬 12-2月
カスタム列を追加し、名前を「season」とし、CASE文を以下のように書いていきます。
SELECT
CASE
WHEN getMonth(release_date) BETWEEN 3 AND 5 THEN '春'
WHEN getMonth(release_date) BETWEEN 6 AND 8 THEN '夏'
WHEN getMonth(release_date) BETWEEN 9 AND 11 THEN '秋'
ELSE '冬'
END
FROM
songs_data
以下の合計3つのカスタム列が追加されました!
再度ビルドしておきます。
さて、いよいよダッシュボード側でデータを細かく見ていきましょう!
すいません・・・ブログがずいぶん長くなってしまったので、これはまた次回にします。
3.まとめ
Spotify APIを用いて、宇多田ヒカルの全アルバム、シングルの曲情報を取得して、Sisenseに取り組むところまでを紹介しました。
次回から曲のメタデータを用いて今回取得したデータを可視化していこうと思います。
続きは次回のブログにて!
Sisenseを体験してみませんか?
INSIGHT LABではSisense紹介セミナーを定期開催しています。Sisenseの製品紹介や他BI製品との比較だけでなく、デモンストレーションを通してSisenseのシンプルな操作性やプレゼンテーション機能を体感いただけます。

-3.png)