セットアップ
まずはSisenseコミュニティのサイトからWord Cloudのプラグインをダウンロードして、サーバーにインストールします。
https://support.sisense.com/hc/en-us/community/posts/115007701128-Word-Cloud-Plugin
ダウンロードしたファイルを解凍し、下記のパスに置きます。
C:\Program Files\Sisense\app\plugins\
関連サービスをリスタートします。
今回の対象データ
今回のデータは、弊社、INSIGHT LABのSlackの「全メッセージ」を対象としました。詳しい取得方法については今回は割愛しますが、全従業員(累計96名)の全メッセージのメッセージ内容のみ(返信メッセージも含む)を抽出し、テキストファイルとして出力してあります。
- 全従業員 累計96人
- 抽出期間 約3年ほど
- データ件数 45000件
※赤枠のTextカラムが対象です
前処理
SisenseでWord Cloudを作成するためには、頻出単語とそのカウント数をリストで洗い出す必要があります。今回は、Pythonとオープンソースの形態素解析エンジンであるMeCabを使用しました。
MeCabのセットアップ
1)MeCabの関連のファイルをインストール
Windows環境へのセットアップは環境変数にパスを追加したりと、少し面倒です。こちらのブログを参考にさせていただきました。各自、インストールをして頂ければと思います。
https://techacademy.jp/magazine/22052
2) Python環境のセットアップ
Python上からMeCabを使用するために、mecab-python3をインストールする必要があります。これは、シンプルにpip install でOKです。
pip install mecab-python3
Pythonコーデイング
詳細は割愛しますが、処理としては以下の手順で行いました。
- 必要なモジュールのインポート
- テキストファイルを読み込み
- MeCabで形態素解析。名詞のみをリストに格納
- 頻出順に出力
- CSVファイルとして書き出し
最終的なコードがこちらです。
import csv
import MeCab
import sys
import re
from collections import Counter
# テキストファイル読み込み
with open('<ファイルのパス>', encoding='utf-8') as f:
data = f.read()
# パース
mecab = MeCab.Tagger('/usr/local/lib/mecab/dic/mecab-ipadic-neologd/')
parse = mecab.parse(data)
lines = parse.split('\n')
items = (re.split('[\t,]', line) for line in lines)
# 動詞をリストに格納
words = [item[0]
for item in items:
if (item[0] not in ('EOS', '', 't', 'ー') and
item[1] == '名詞' and item[2] == '一般')]
# 頻度順に出力
counter = Counter(words)
header = ['word','count']
# データをCSVに書き出し
with open('sample_slack.csv','w',newline='',encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(header)
for word, count in counter.most_common():
writer.writerow([word,count])
抽出結果がこちらです。
我が社のSlack頻出名詞TOP20です。
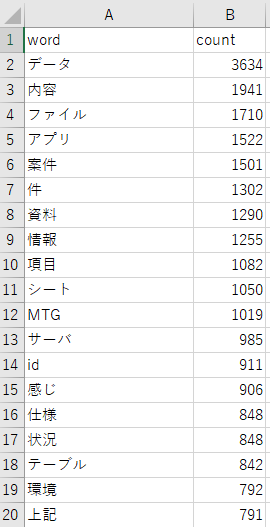
当たり前と言えばそうなのですが、社内のSlackで一番使われている言葉は「データ」でした。15位の「感じ」というカジュアルな言葉が一つだけ入っているのが気になります。
Sisense側の設定
データの取り込み
ElastiCubeで先程書き出したCSVファイルを読み込んで、見てみます。
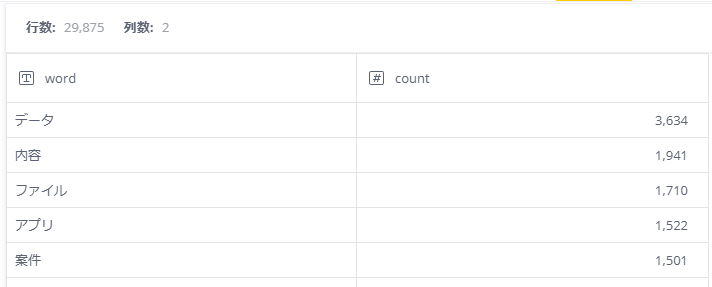
データ件数が29875件と頻出単語のリストとしては多いですね。
Word Cloudでワードの数が多すぎると、表示に時間がかかります。思い切って削りましょう。
カスタムテーブルを作成し、countが100以上のみの行を抽出します。また、wordにはスタンプ関連や意味不明な単語が30個ほど含まれていたので、SQLのWHERE句で除外しました。

結果、29875語 => 430語となりました。
ビルドします。
これでWord Cloudを作るためのデータが準備できました。
次に、分析タブからダッシュボード作成へ移ります。実際にWord Cloudを作成していきましょう。
Word Cloudの設定
ダッシュボード作成画面より新しくウィジェットを作成します。ウィジェット作成の左上のチャート選択画面からWord Cloudが増えているのが確認できます。
ここからWord Cloudを選択します。
カテゴリに「word」を設定し、値に「count」を設定します。
設定した瞬間にすぐにWord Cloudが表示されました!

右ペインから、見た目をカスタマイズします。
以下のように行いました。


完成です!
ところで、カウント数が多いものから表で見てみると、
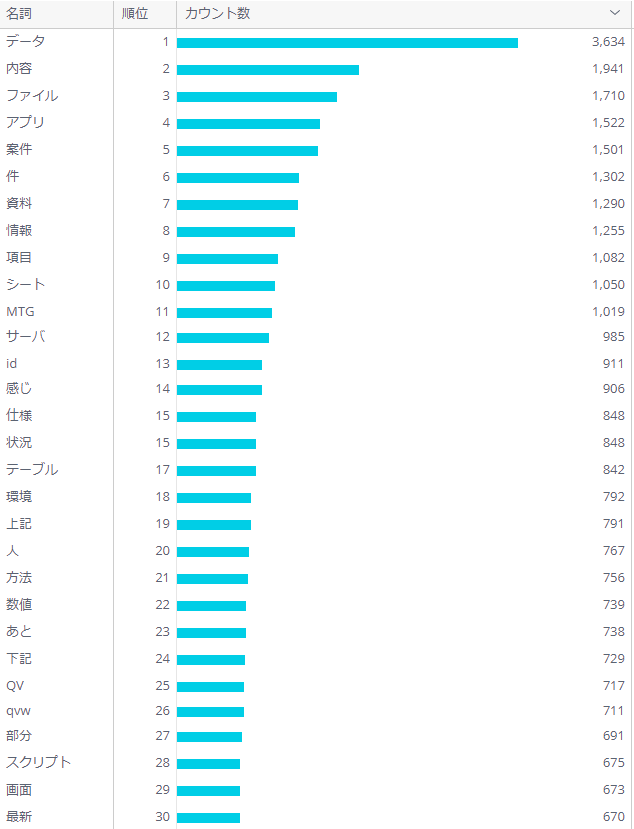
あれ、「Sisense」がまだ見つかりません!
スクロールしていくと・・・

ありました!
450回はなかなか多いので、Sisenseは社内でも話題に上がっていると解釈することにしましょう!
まとめ
今回は、WordCloudを紹介しました。
Pythonを使った前処理が必須となりますが、なかなか綺麗なビジュアルです。
Sisenseを体験してみませんか?
INSIGHT LABではSisense紹介セミナーを定期開催しています。Sisenseの製品紹介や他BI製品との比較だけでなく、デモンストレーションを通してSisenseのシンプルな操作性やプレゼンテーション機能を体感いただけます。