AWS SageMaker Canvas は AWS が提供する AutoMLツールです。本記事では、AWS SageMaker Canvas を使用してモデルを構築する方法に解説します。
AWS SageMaker Canvas とは
AWS SageMaker Canvas は、AWSの機械学習サービスであり、AutoMLツールの一つです。SageMaker Canvasを使用すると、GUI操作で簡単に機械学習モデルを構築できます。
また、AWS SageMaker Canvas は、データの前処理、特徴量エンジニアリング、モデルの設計、学習の実行、モデルの評価などの一連の作業を簡単かつ効果的に行うことができます。
AWS SageMaker Canvas は、ビジネスユーザーやデータサイエンティストが機械学習モデルを作成する際に、手作業で行う必要があった複雑な作業を自動化し、生産性を向上させることができます。
AWS SageMaker Canvas の主な機能
AWS SageMaker Canvas には、以下の主な機能があります。
-
データの視覚化と探索: データセットを視覚的に探索し、データの特徴や傾向を把握することができます。
-
自動特徴量エンジニアリング: データから自動的に特徴量を生成するためのツールを提供します。
-
モデルの構築とトレーニング: 視覚的なインターフェースを使用して機械学習モデルを構築し、トレーニングすることができます。
-
モデルの評価とデプロイ: モデルの性能を評価し、必要に応じてデプロイすることができます。
-
ワークフローオーケストレーション: データの前処理からモデルの学習、評価、デプロイまでの一連の作業をシームレスに実行することができます。
AWS SageMaker Canvas の使い方
AWS SageMaker Canvasを使用するためには、以下の手順を実行します。
-
データセットのアップロード: モデルを構築するためのデータセットをAWS SageMaker Canvas にアップロードします。
-
データの視覚化と探索: アップロードしたデータセットを視覚的に探索し、データの特徴や傾向を把握します。
-
自動特徴量エンジニアリング: データから自動的に特徴量を生成するためのツールを使用します。
-
モデルの構築とトレーニング: 視覚的なインターフェースを使用して機械学習モデルを構築し、トレーニングします。
-
モデルの評価とデプロイ: 構築したモデルの性能を評価し、必要に応じてデプロイします。
AWS SageMaker Canvas は直感的なインターフェースを提供しており、初心者でも簡単に機械学習モデルを構築することができます。
モデル構築
セットアップ
初めて SageMaker を使用する際には、ドメインとユーザープロファイルの作成が必要なため、そのための操作を行っていきます。
AWS を開き、SageMaker を検索してページを開き、左のリストから「ドメイン」>「シングルユーザー向けの設定」>「設定」をクリックします。
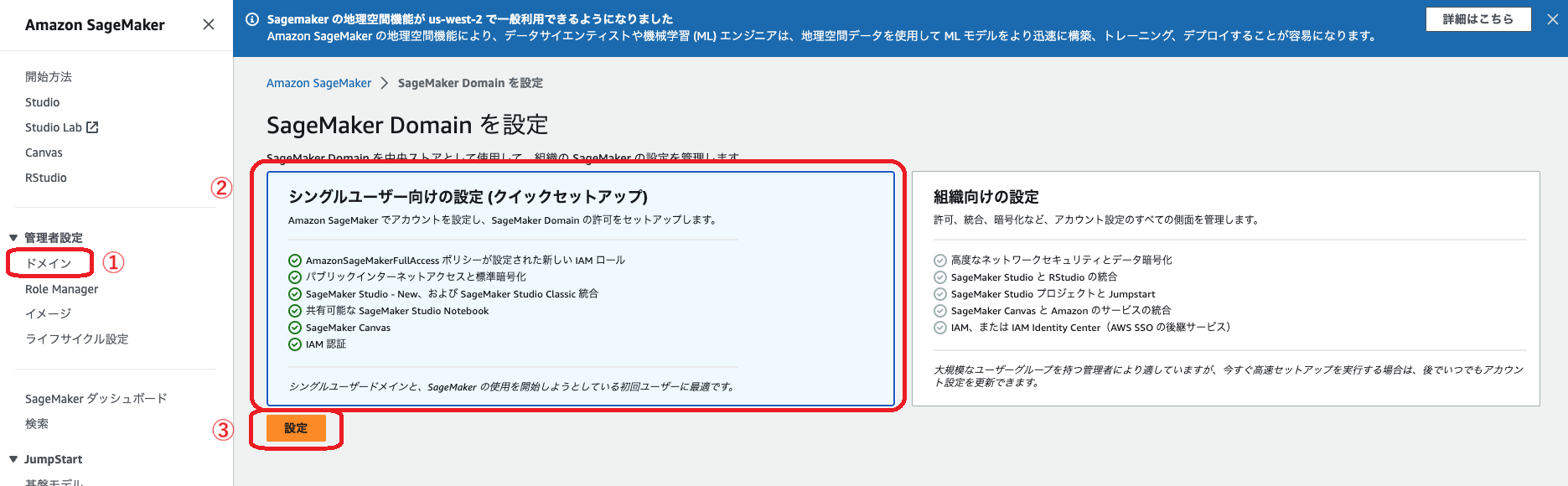
ドメインに必要なリソースの準備が始まるので、しばらく待ちます。
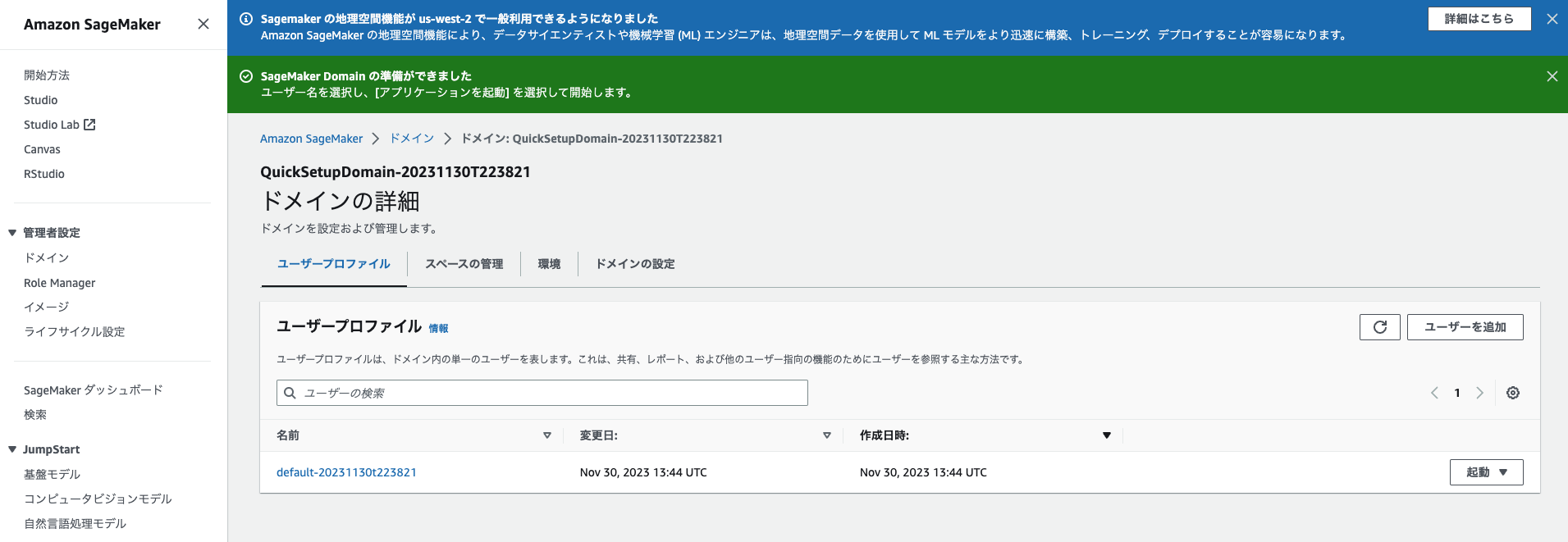
少しかかりますが待っていれば以下のように完了します。
デフォルトのユーザーが追加され、SageMaker を使用する準備が完了しました。今回はこのままデフォルトユーザーを使用していきたいと思います。
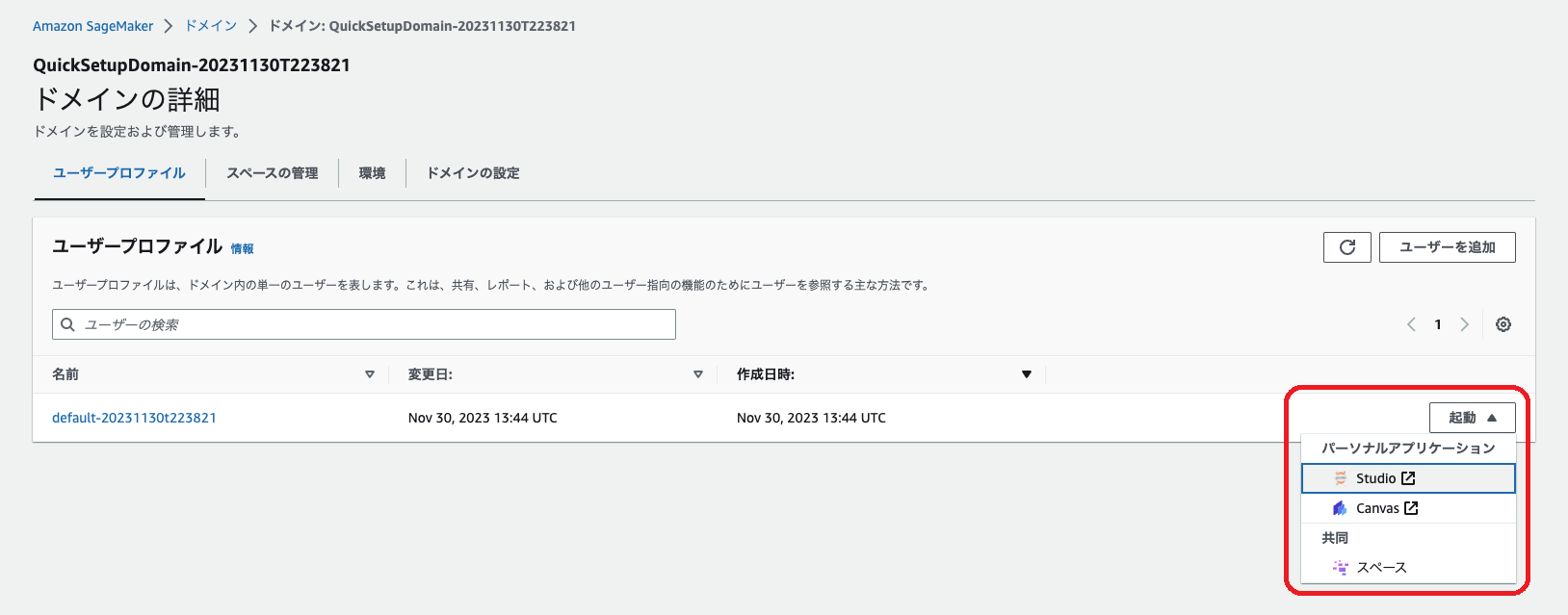
ユーザー名の一番右、「起動」をクリックします。ここで、SagaMaker Studio か Canvas を起動するか選択します。(Canvas は Studio のページからでも起動できます。)
こちらが 「Studio」を選択して起動した画面です。左上に「Canvas」があるのでクリックします。
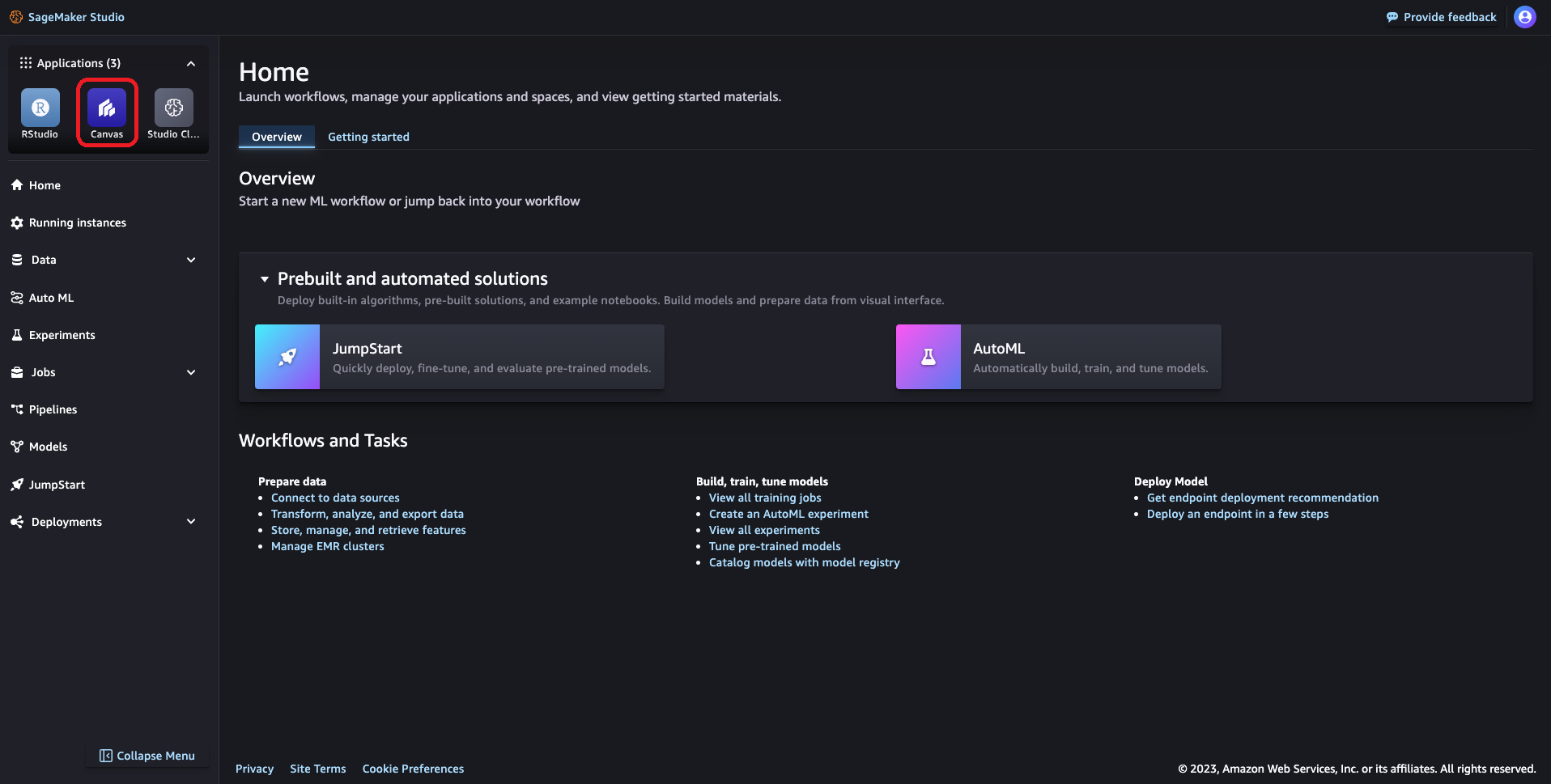
「Run Canvas」をクリックします。(前述の起動の際、Studio ではなく Canvas から起動すればこの操作は必要ありません。)
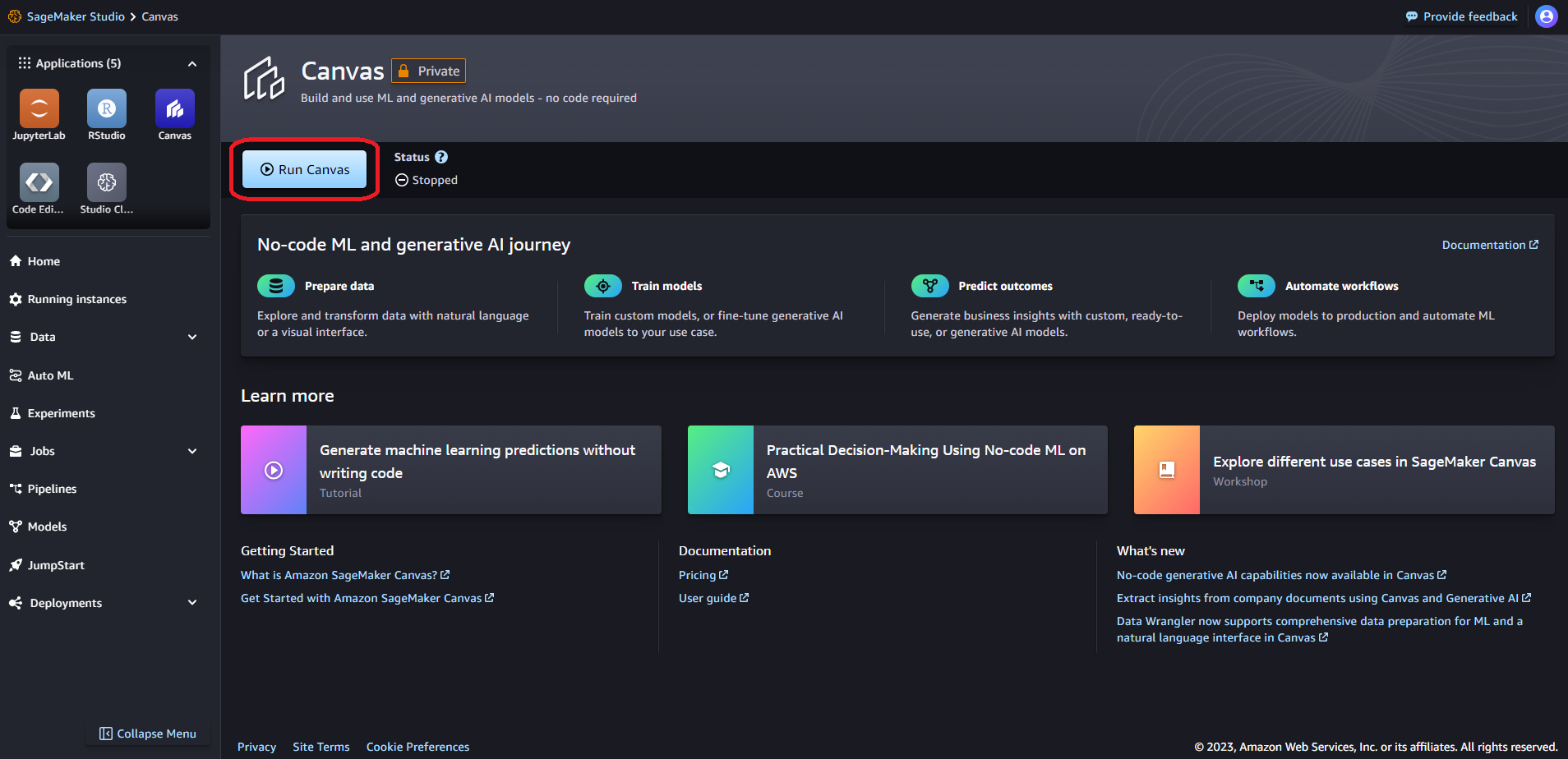
「Open Canvas」がクリックできるようになったら、Canvas を起動できます。「Open Canvas」をクリックします。
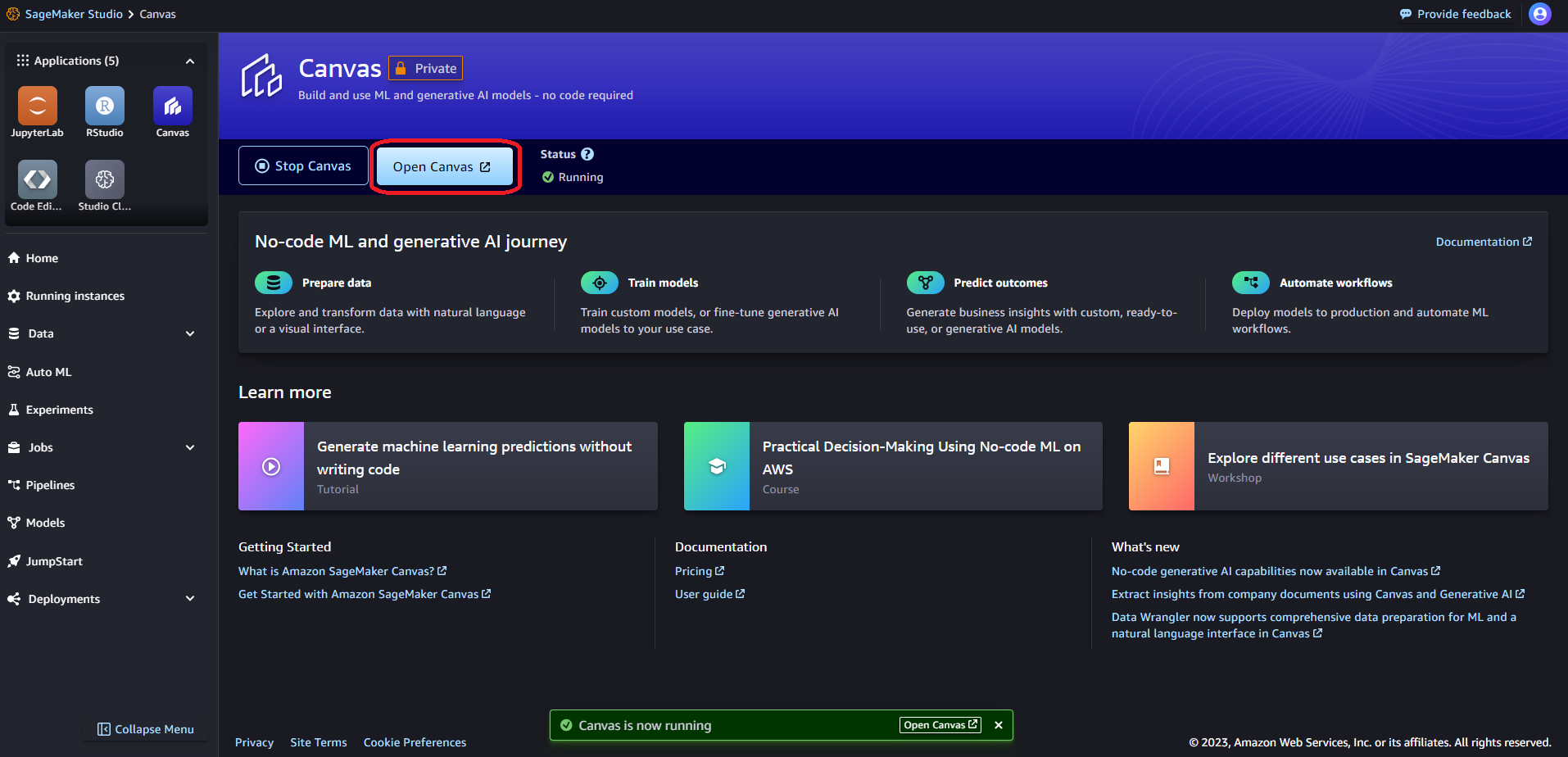
こちらが Canvas の画面になります。
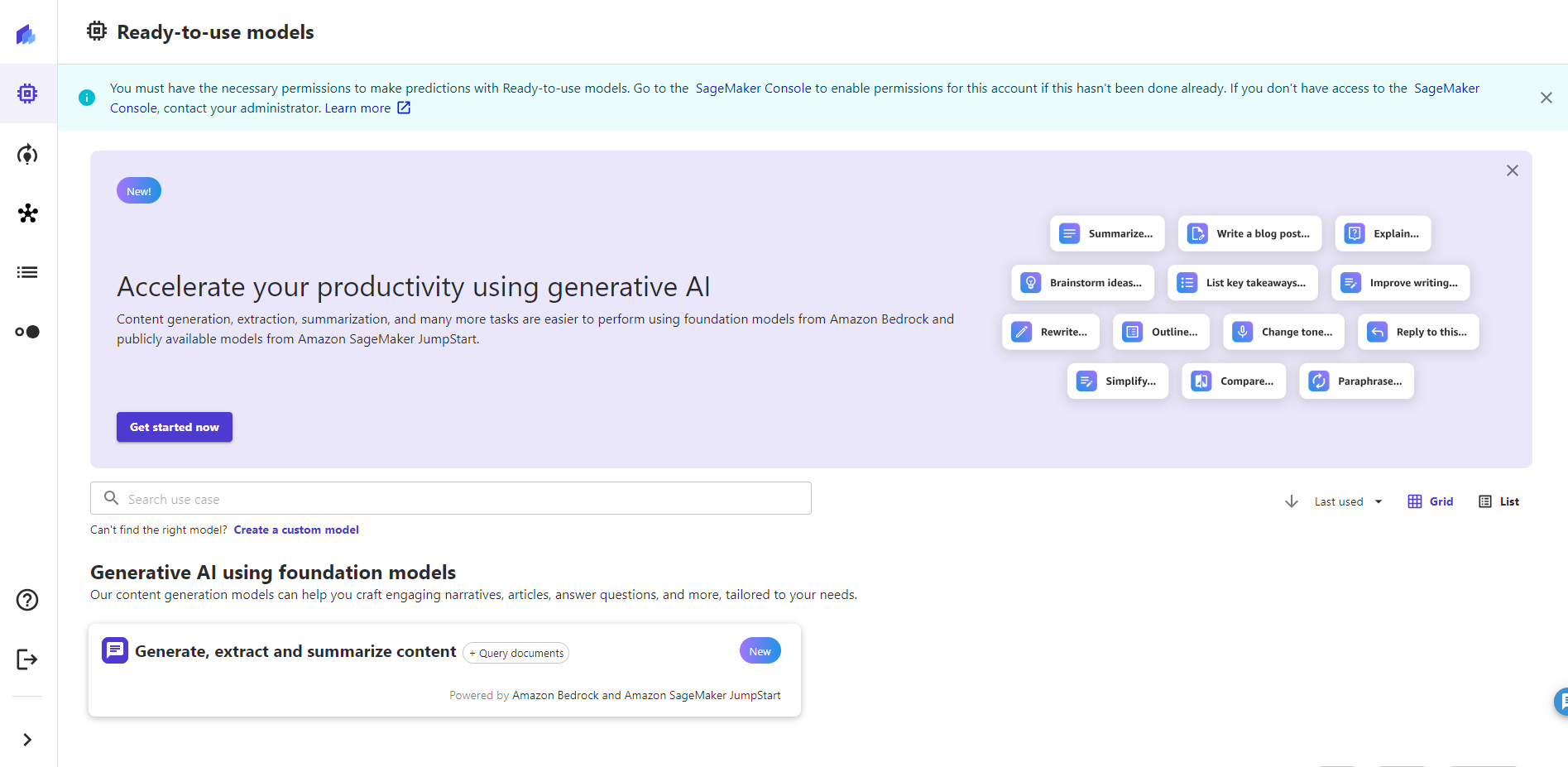
以上で Canvas のセットアップが完了しました。次項からモデルの構築を行っていきます。
Select:データ準備
データは Kaggle のオープンデータを使います。
https://www.kaggle.com/datasets/mirichoi0218/insurance
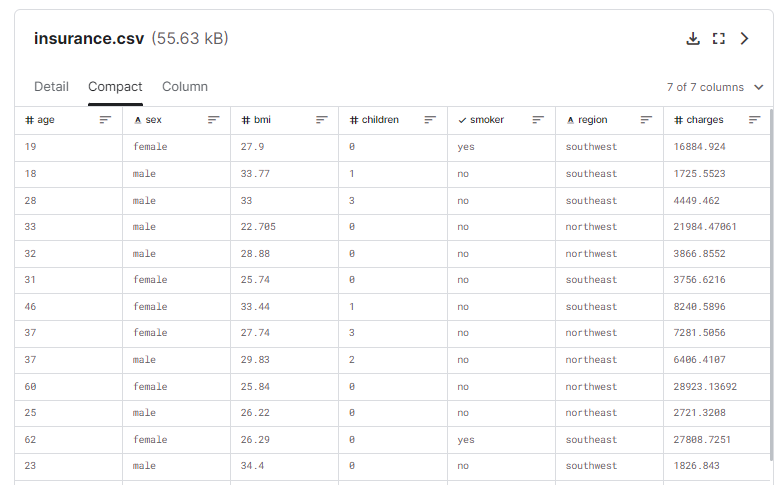
各カラムのそれぞれの意味は以下。
age:主たる受取人の年齢
sex:保険契約者の性別、女性、男性
bmi:Body mass index(体格指数)。身長に対する体重の相対的な高低を示す、
身長と体重の比を用いた体重の客観的な指数(kg / m ^ 2)で、理想的には18.5~24.9である
child: 健康保険に加入している子どもの数/扶養家族の数
smoker:喫煙
region:米国内の受給者の居住地域(北東部、南東部、南西部、北西部)
charges:健康保険から請求された個々の医療費
今回はこのデータをS3に配置しておきます。
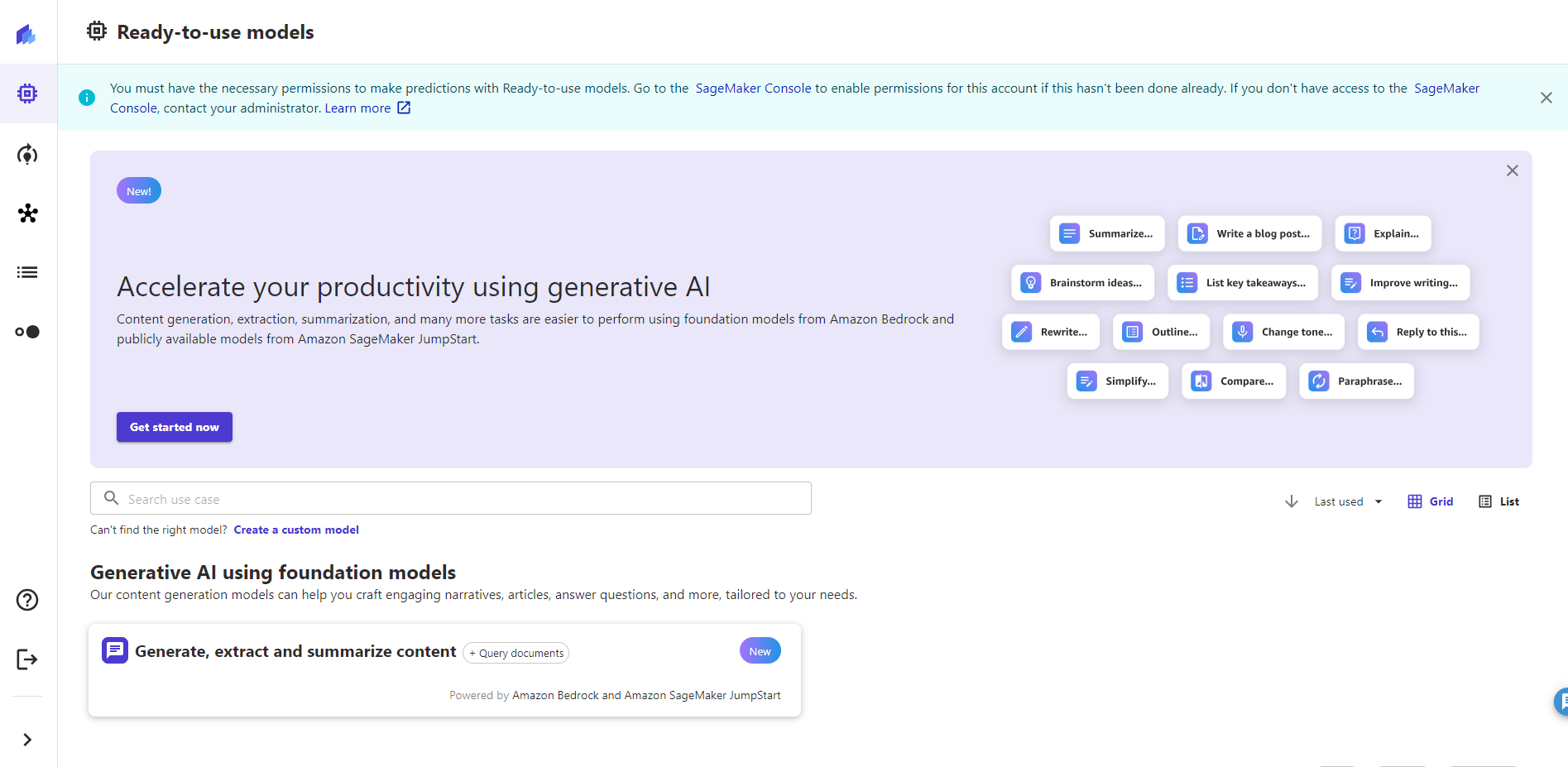
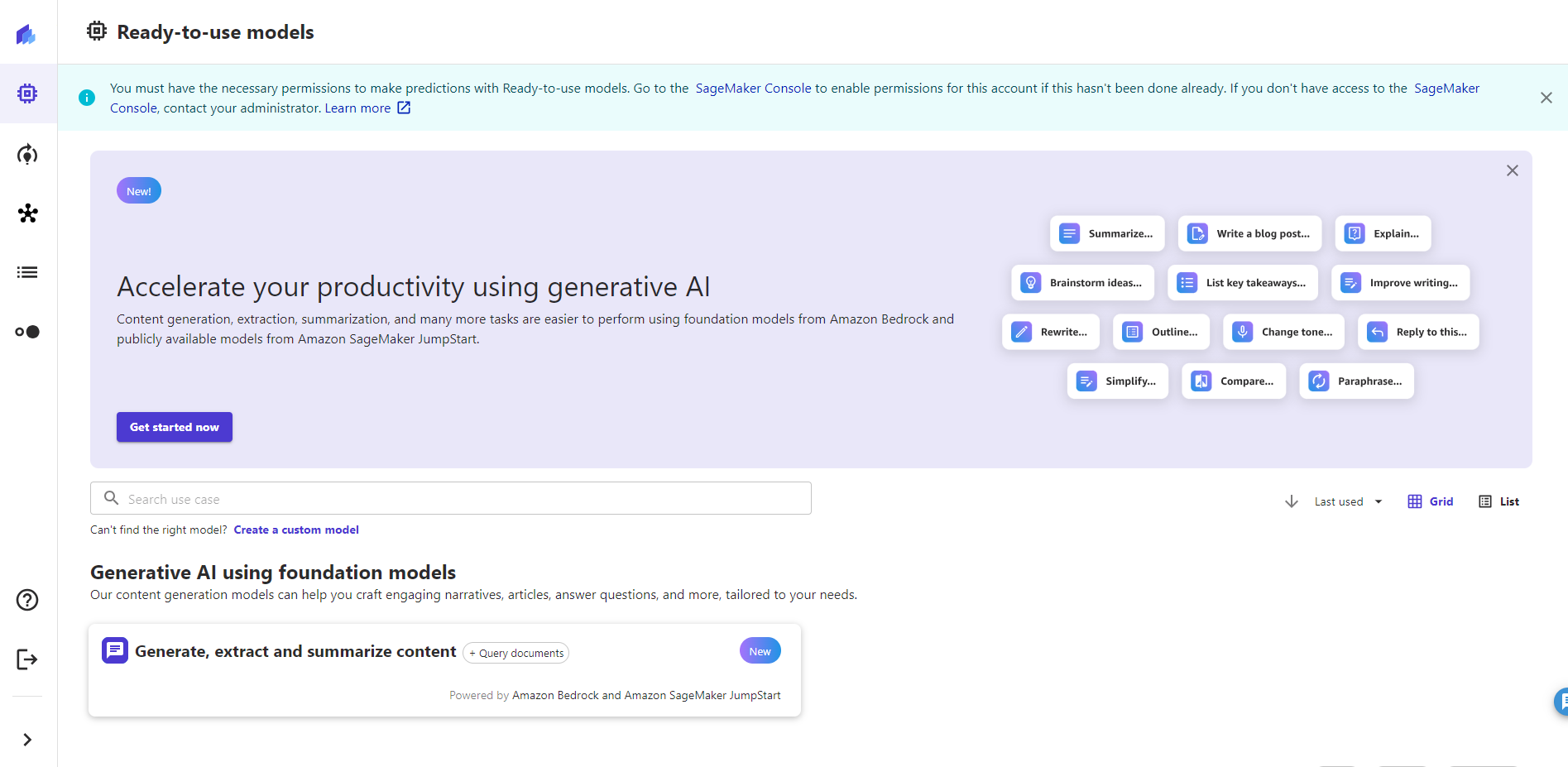
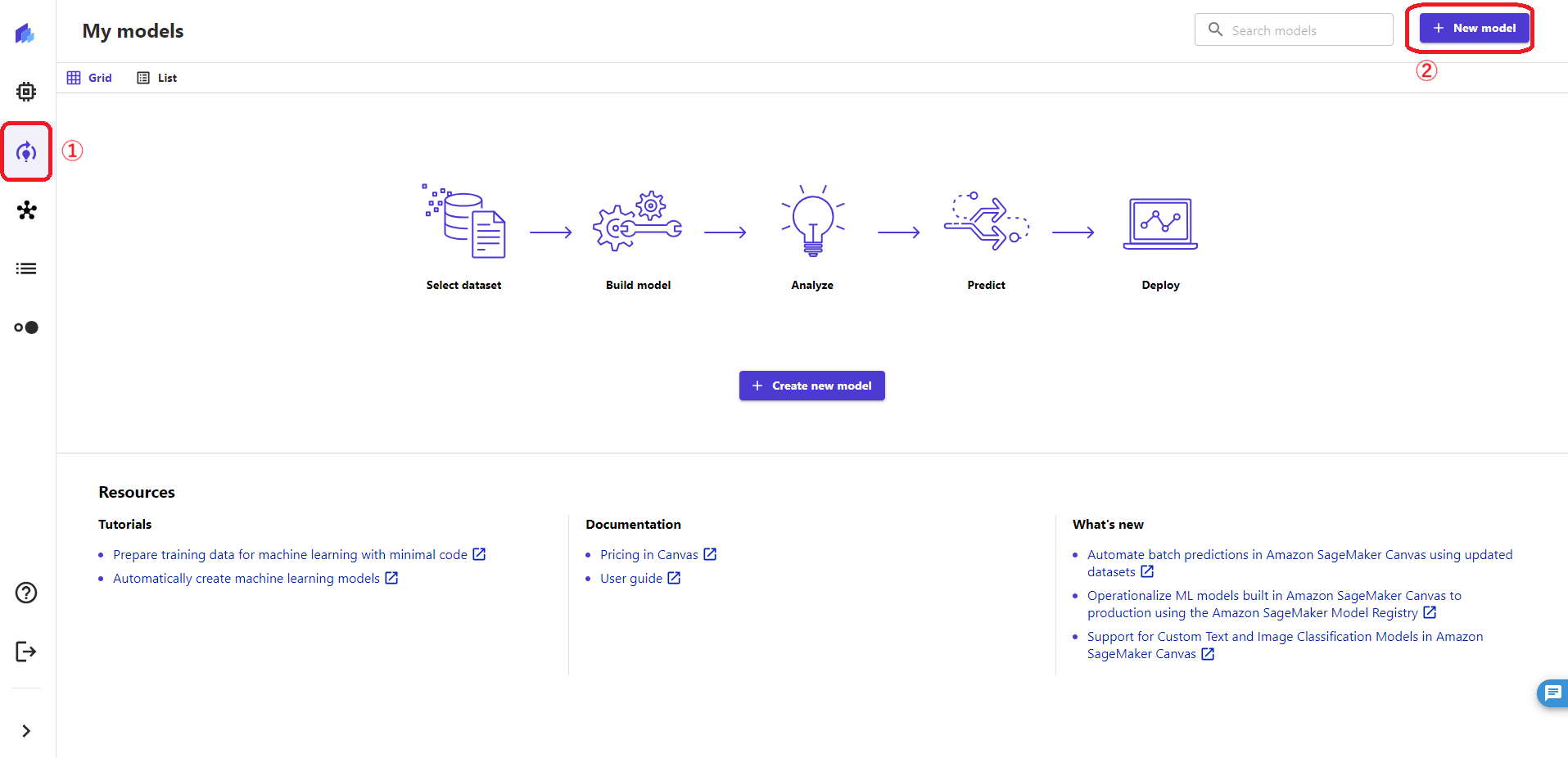
モデルの作成を始めていくので、①左の電球のようなアイコンをクリックし、右上の②「+New model」をクリックします。
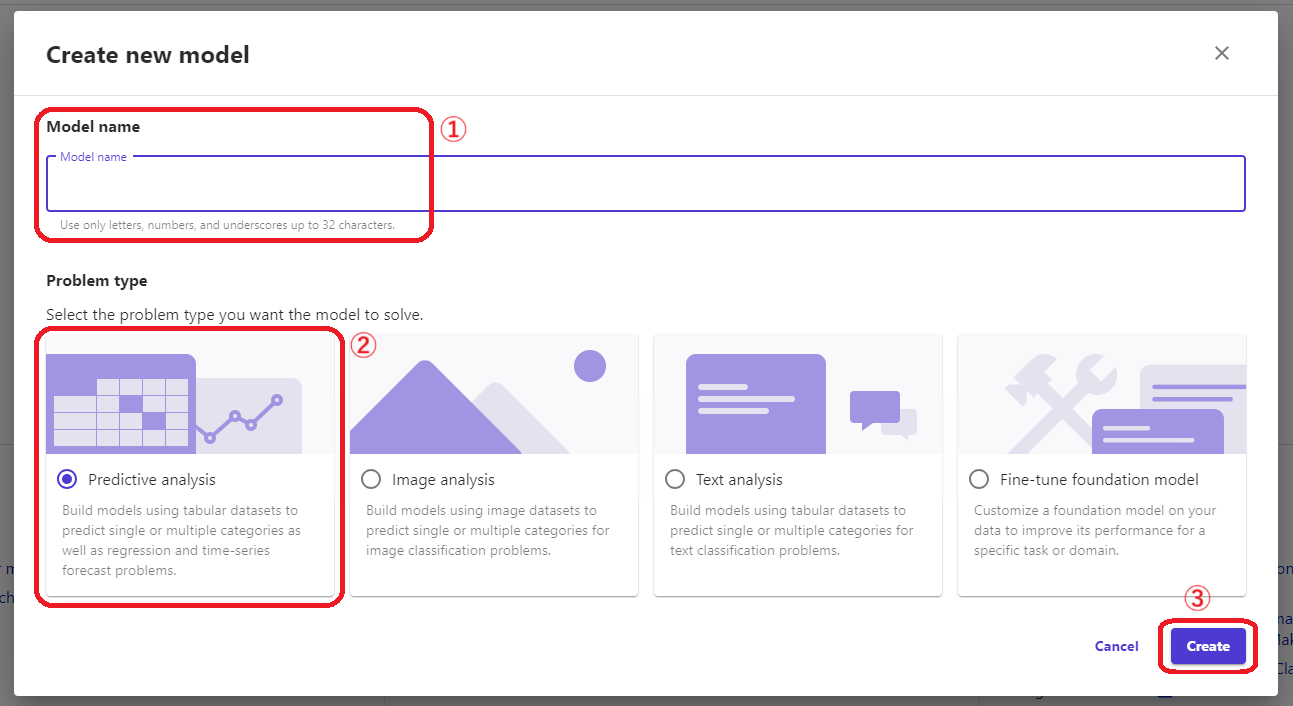
①「Model name」に作成するモデルの名称を設定して、予測する問題のタイプを選択します。
- Predictive analysis:テーブル形式のデータセットを使って、分類、回帰、時系列問題予測に使用します。
- Image analysis:画像データセットを使って、画像分類問題に使用します。
- Text analysis:テーブル形式のデータセットを使って、テキスト分類問題に使用します。
- Fine-tune foundation model:自前のデータ上で基盤モデルをカスタマイズして、特定のタスク、ドメインのパフォーマンスの改善に使用します。
今回は医療費を予測する回帰問題なので、②「Predictive analysis」を選択し、「Create」をクリックします。
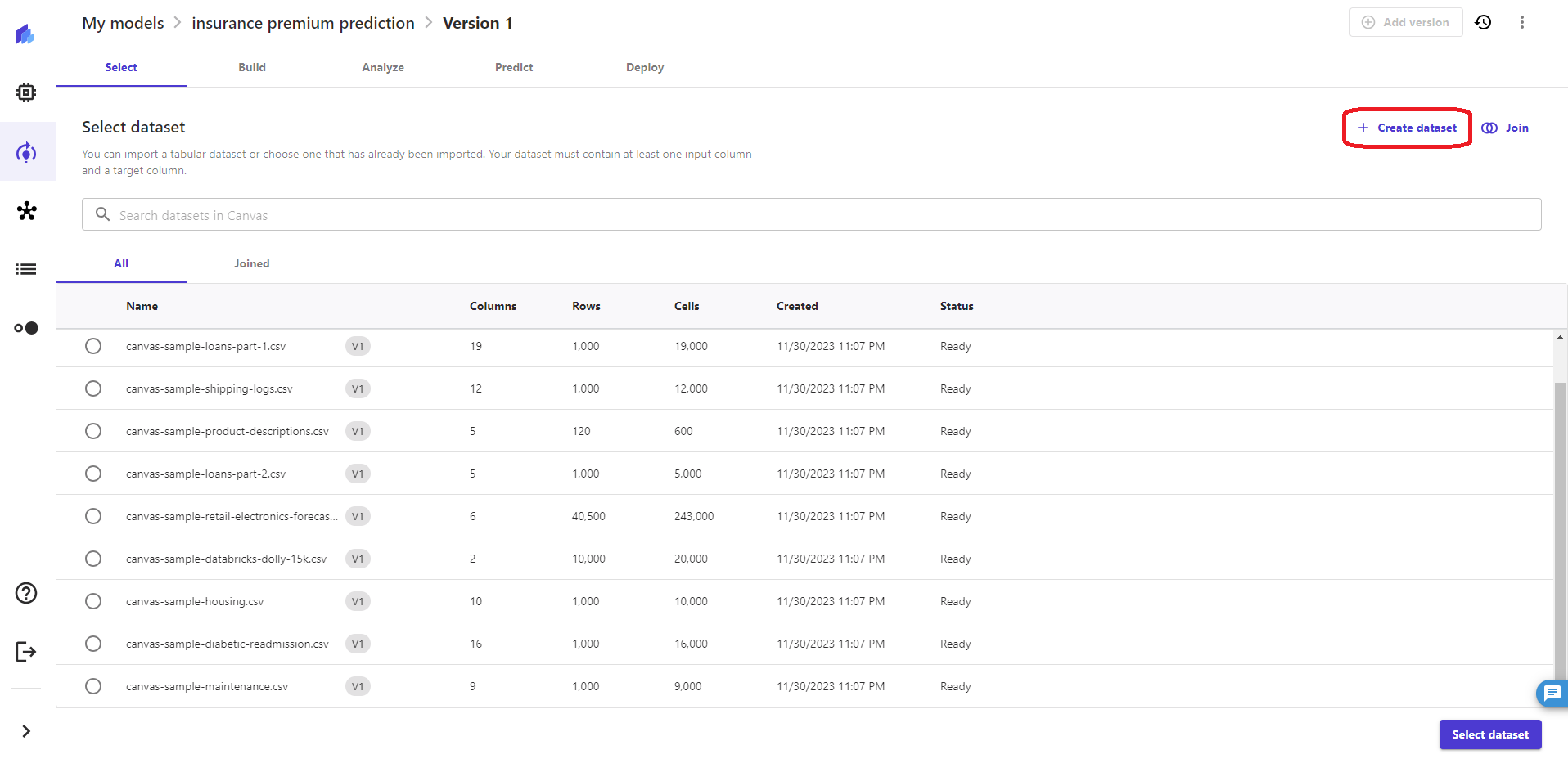
Canvas にはあらかじめ様々なデータセットが用意されているようですが、今回は Kaggle からダウンロードした「insurance.csv」データを使用します。
右上の「+Create dataset」をクリックします。
ウィンドウが現れるので、作成するデータセットの名前を設定し、「Create」をクリックします。
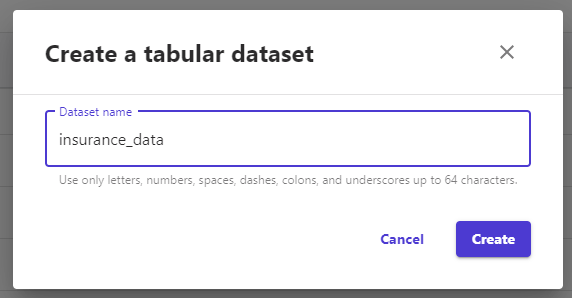
データセットの名前を設定した後は、使用するデータをアップロードします。左上の「Data Source」からデータの取り込み元を設定します。
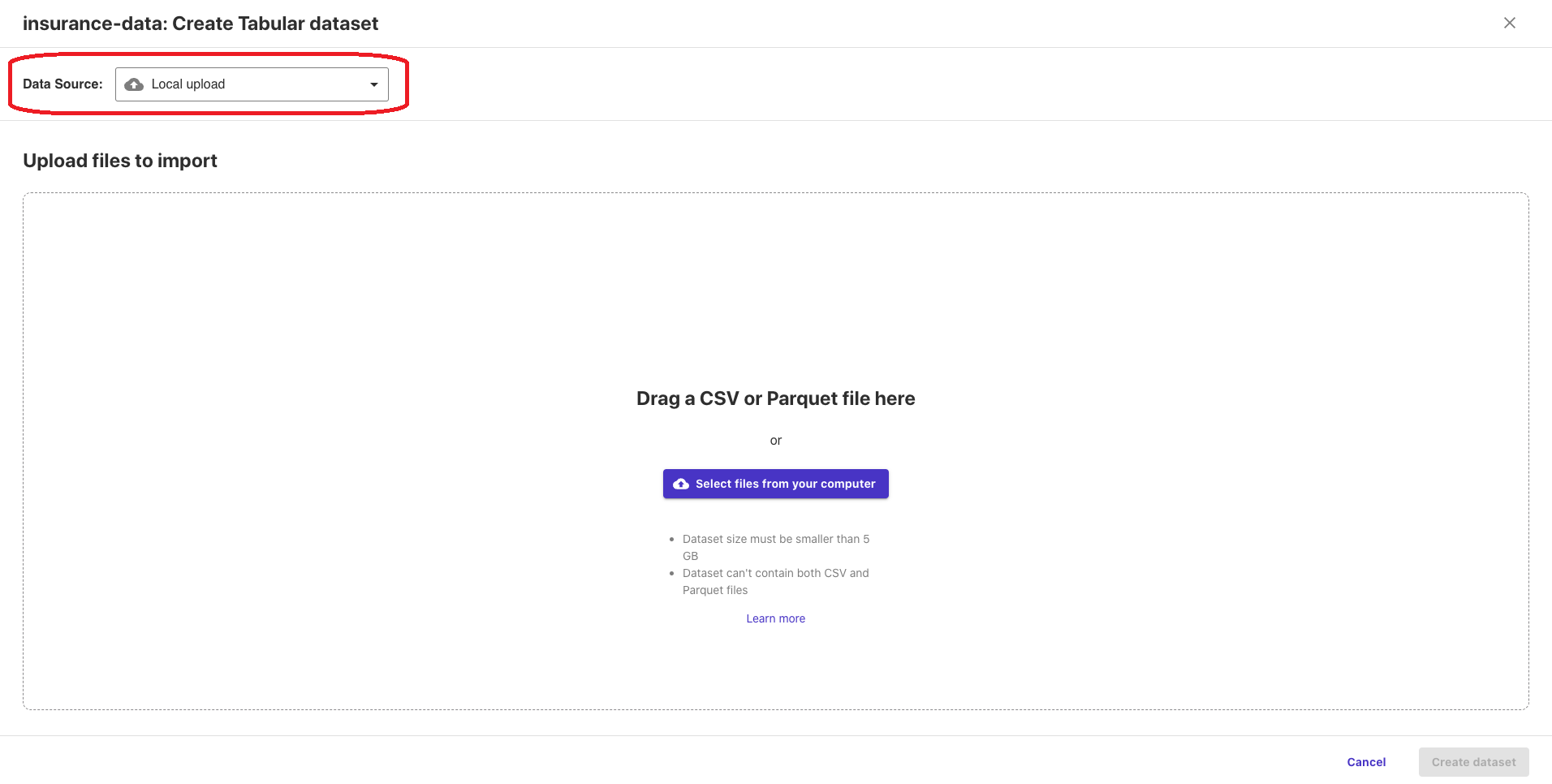
ファイルソースはたくさんあり、Snowflake、Redshift、S3 など主要な DB、DWH、クラウドストレージなど押さえられています。
今回はあらかじめS3に配置したデータからインポートしたいと思いますので、「Amazon S3」をクリックします。
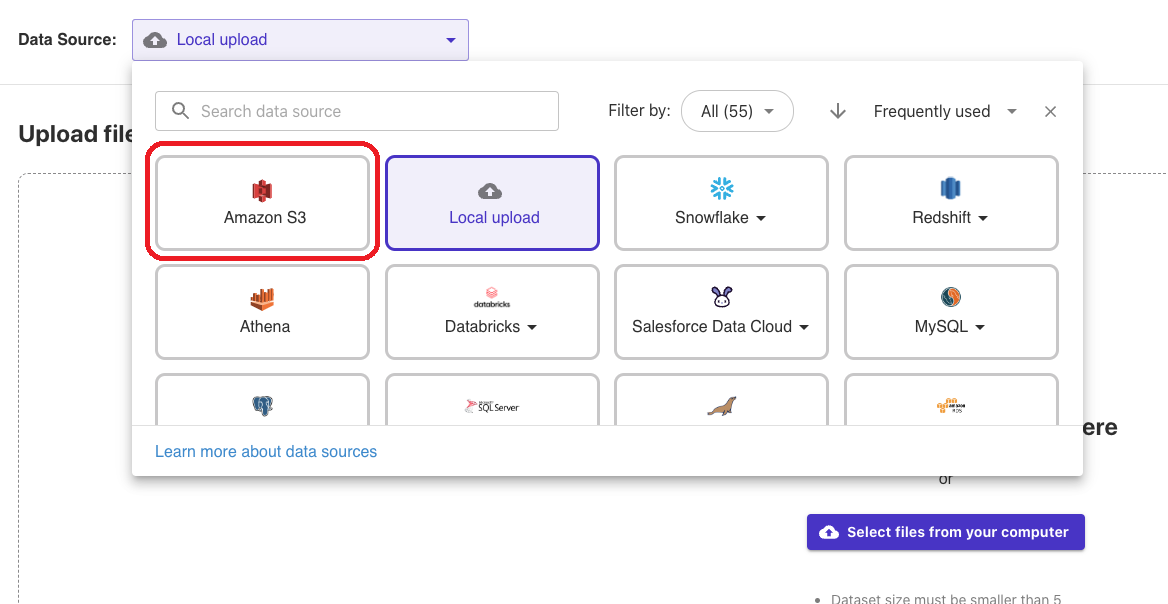
バケット選択画面になるので、インポートするデータがあるバケットを選択します。
ここでは「personal-medical-cost-prediction」>「insurance.csv」と選択します。
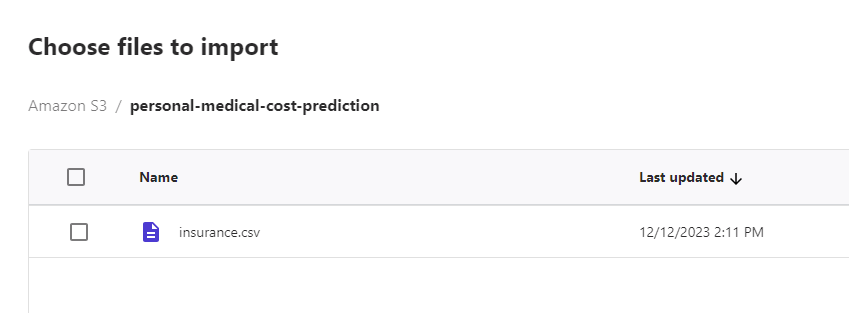
ファイルをクリックすると、データのプレビュー画面になるので、軽く確認して右下の「Select dataset」をクリックします。
またプレビューが出るので、「Create dataset」をクリックします。
無事データセットが作成されました。作成したデータセットを選択した状態で、右下「Select dataset」をクリックすればデータ準備は完了です。
Build:モデル生成
ここではデータの確認、可視化、目的変数の設定など行うことができます。
今見えているカラムビューでは、データセットの各カラムがどのようなデータタイプか、ユニークな変数の種類、平均値などが分かります。
次にグリッドビューを確認してみます。「|||」をクリックします。
グリッドビューではデータの分布を視覚的に確認することができます。さらに別のグラフを確認したい場合は、右にある「Data visualizer」をクリックします。
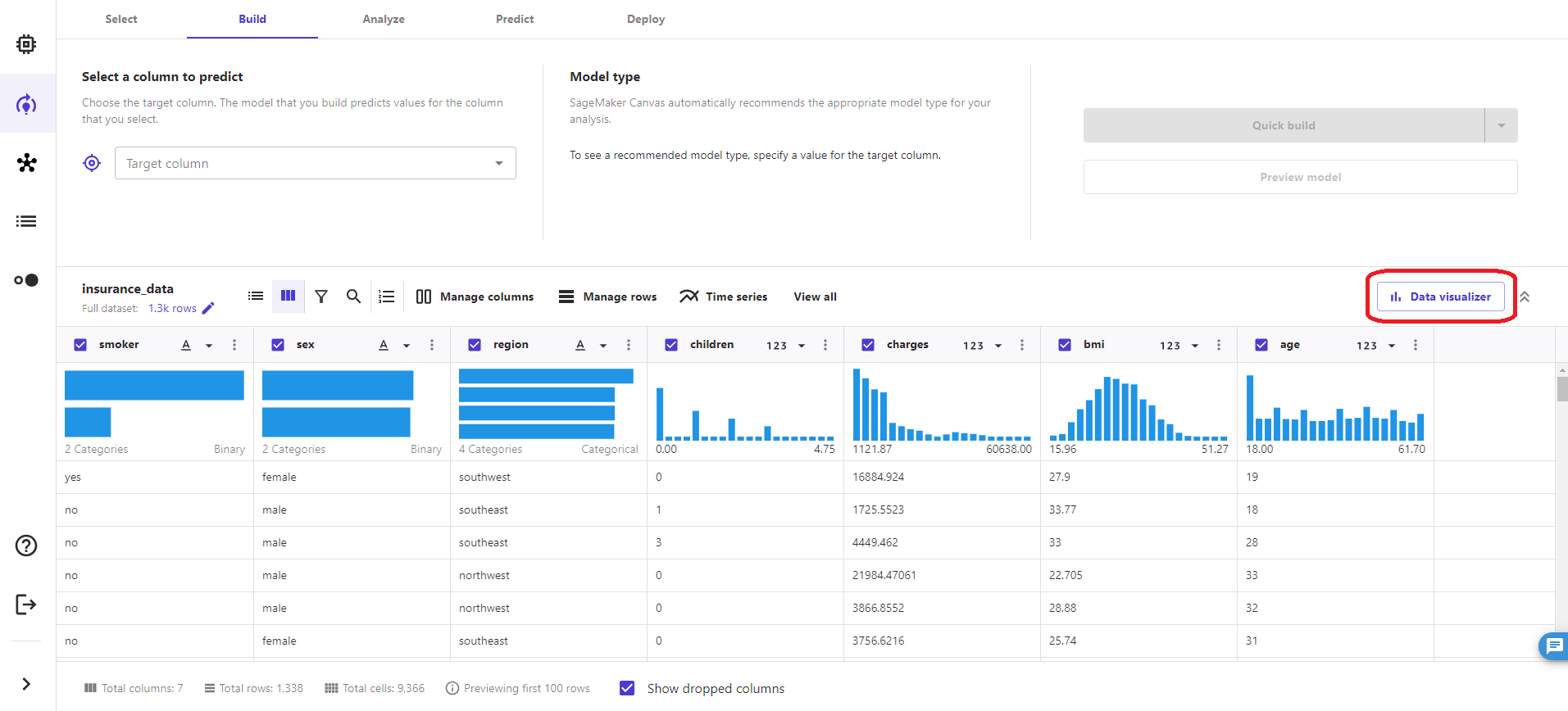
Data visualizer では、データセットの各カラムを組み合わせて散布図、棒グラフ、箱ヒゲ図でデータを比較することができます。
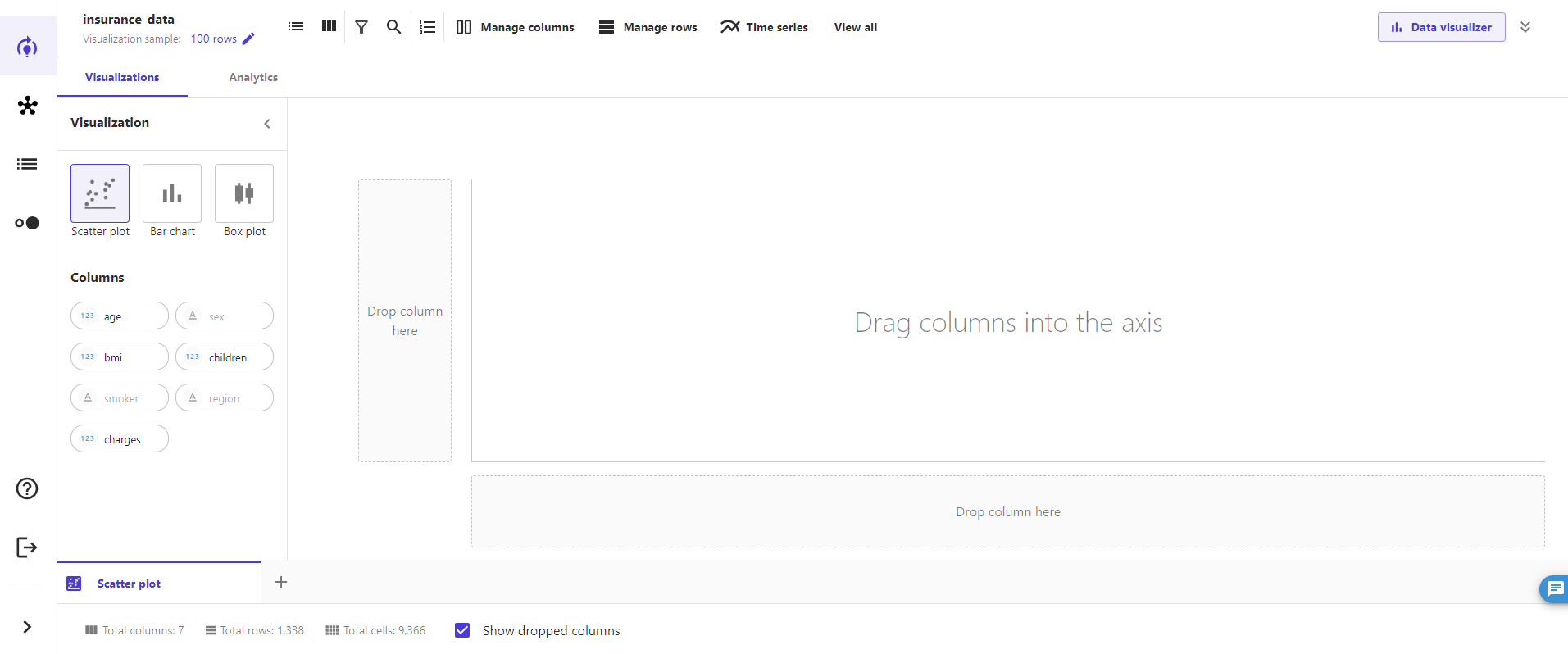
散布図で、横軸に「age」、縦軸に「charges」を選んでみたのが下のキャプチャになります。グラフの種類は3種類ですが簡単に視覚化することができました。
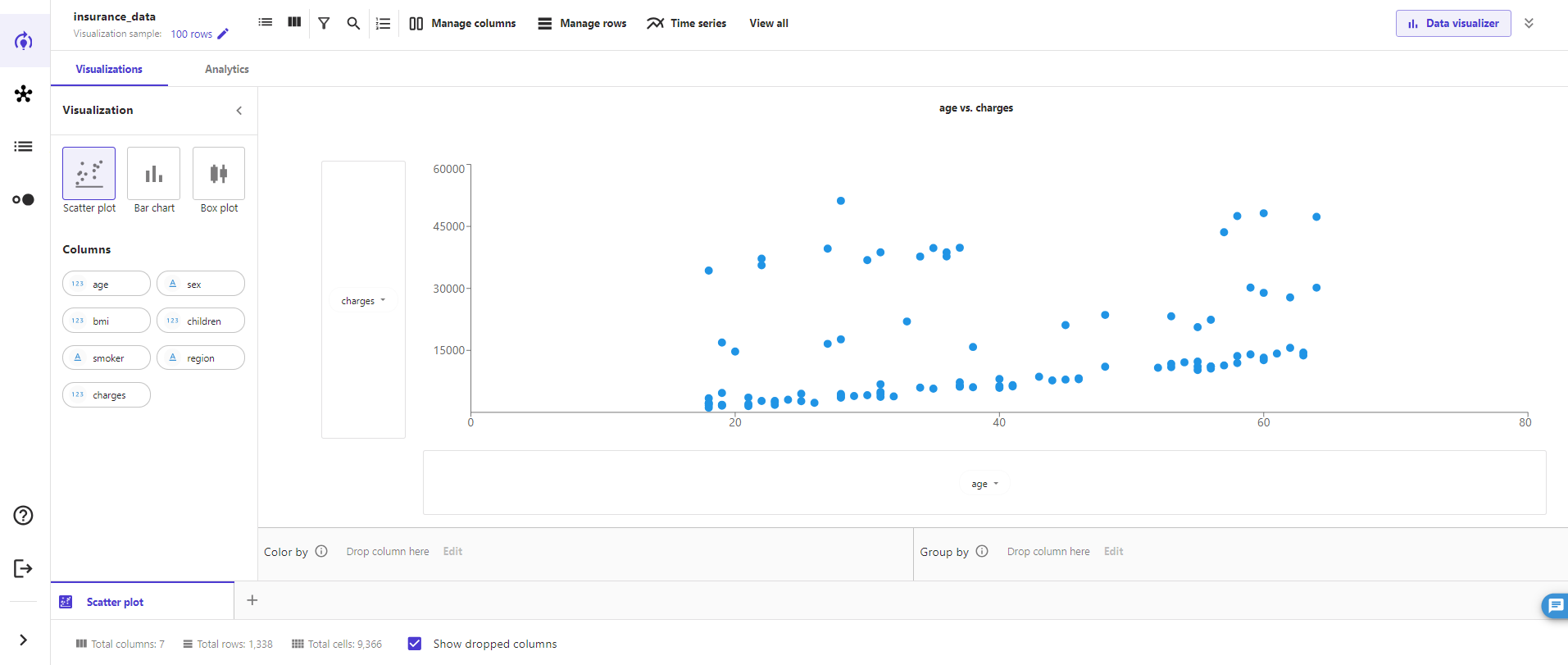
次に「Analytics」を確認してみます。ここでは相関行列が確認でき、各カラムごとの相関係数を簡単に確認できます。
データを確認できたところで、モデルの作成に移りたいと思います。
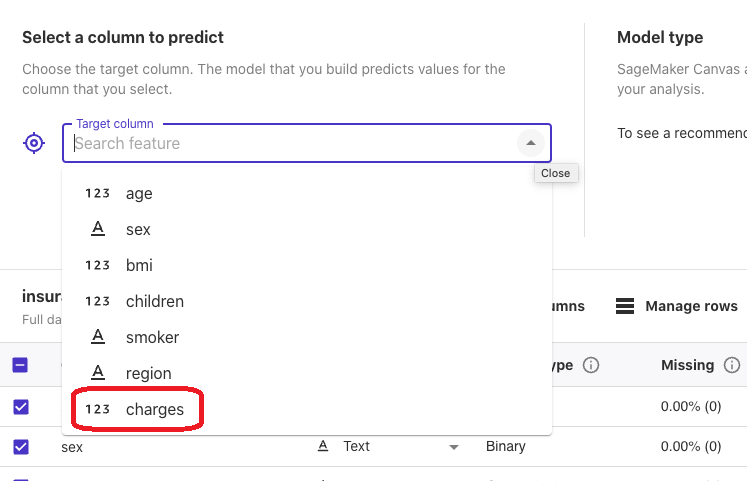
データが整ったものなので、「Select a column to predict」で推定したい変数(目的変数)を設定するだけでモデル生成できます。
今回のプロジェクトでは「健康保険料」を推定するモデルを生成したいので、目的変数は「charges」を選択します。
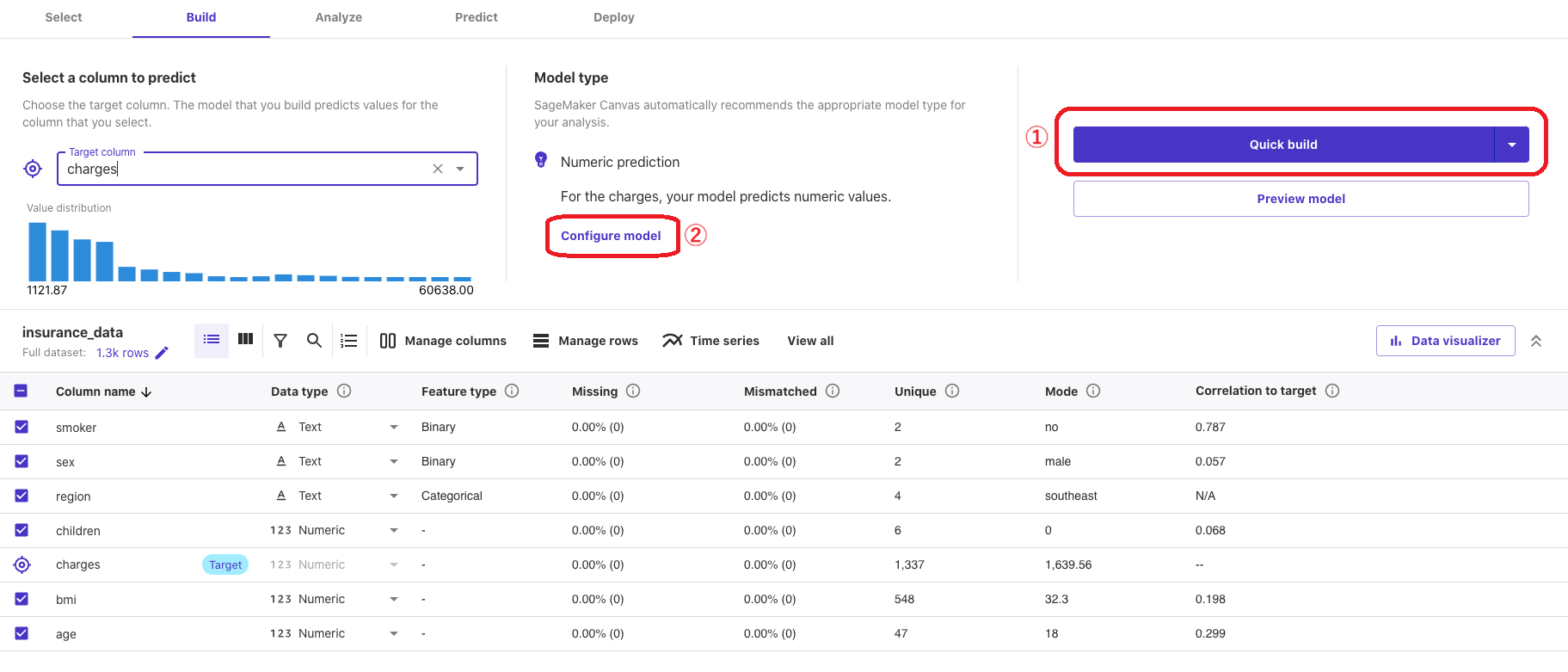
目的変数を設定したら、①「Quick build」をクリックすることでモデル生成を行ってくれます。
モデルの設定に関しては真ん中の「Model type」の下、②「Configure model」をクリックすればモデルの設定を行うことができます。(自動で推奨の設定が選択されているので、確認するだけでいいかもしれません。)
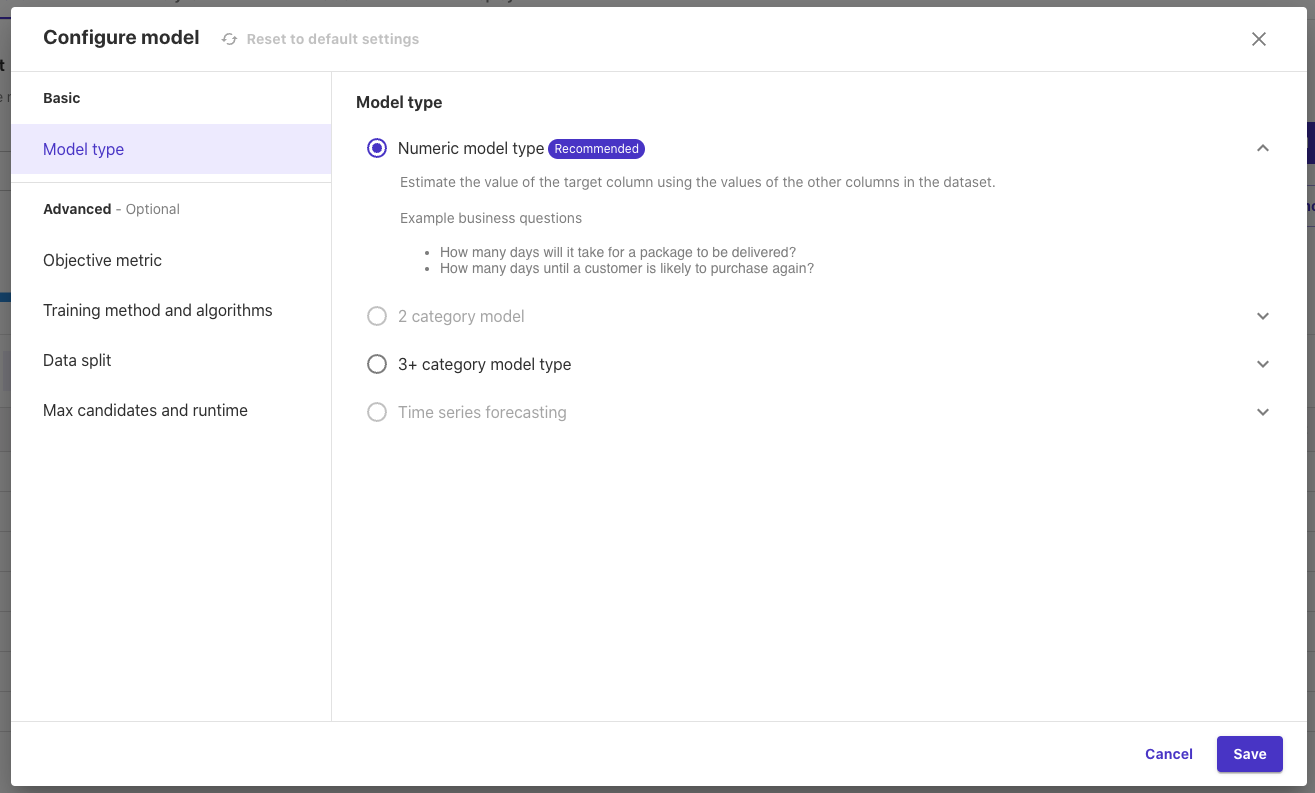
今回は数値を予測する、回帰モデルになるのでそのまま「Numeric model type」になっています。
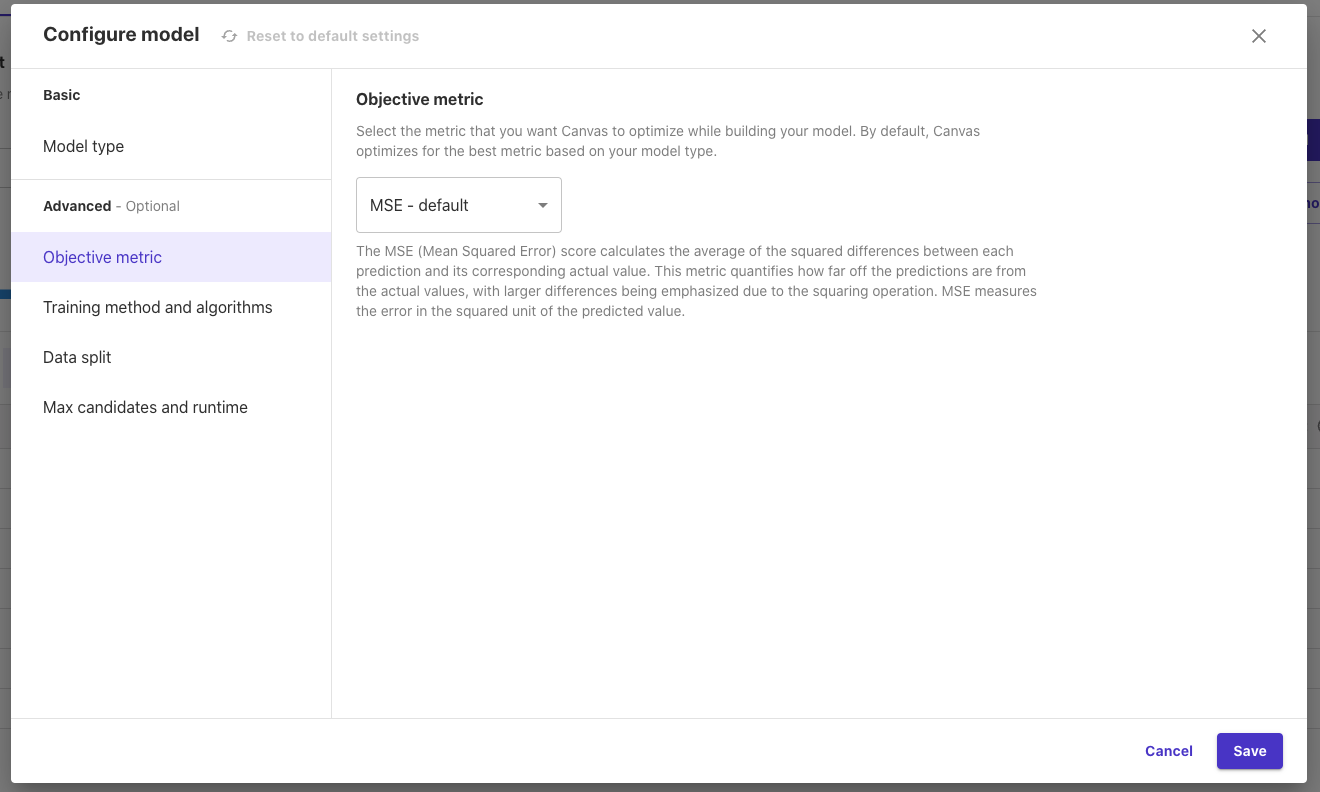
「Advanced」では、以下のようにもう少し細かくモデルの設定を変更できます。
「Objective matrix」:モデルの最適化に使用する評価関数を以下の2種類から選択できます。
- MSE:平均二乗誤差(Mean Squared Error)。MSE は、予測値と実際の値の差の二乗の平均を表す指標。二畳操作により大きな差が強調されます。
- RMSE:平方平均二乗誤差(Root Mean Squared Error)。RMSE は、予測値と実際の値の差の二乗の平均を表す指標である MSE の平方根で、MSE で二乗した単位が元に戻るので、MSE よりも人間が理解しやすい指標と言えます。
- MAE:平均絶対誤差(Mean Absolute Error)。MAE はモデルの予測値が実際の値にどれだけ近いかを測定する方法である。MAEは、データセット中の外れ値に対してより頑健です。
- R2:R2スコアは、予測モデルが実際のデータにどの程度フィットするかを示します。この指標は、モデルの予測値がどれだけ真の値に近いかを測定します。
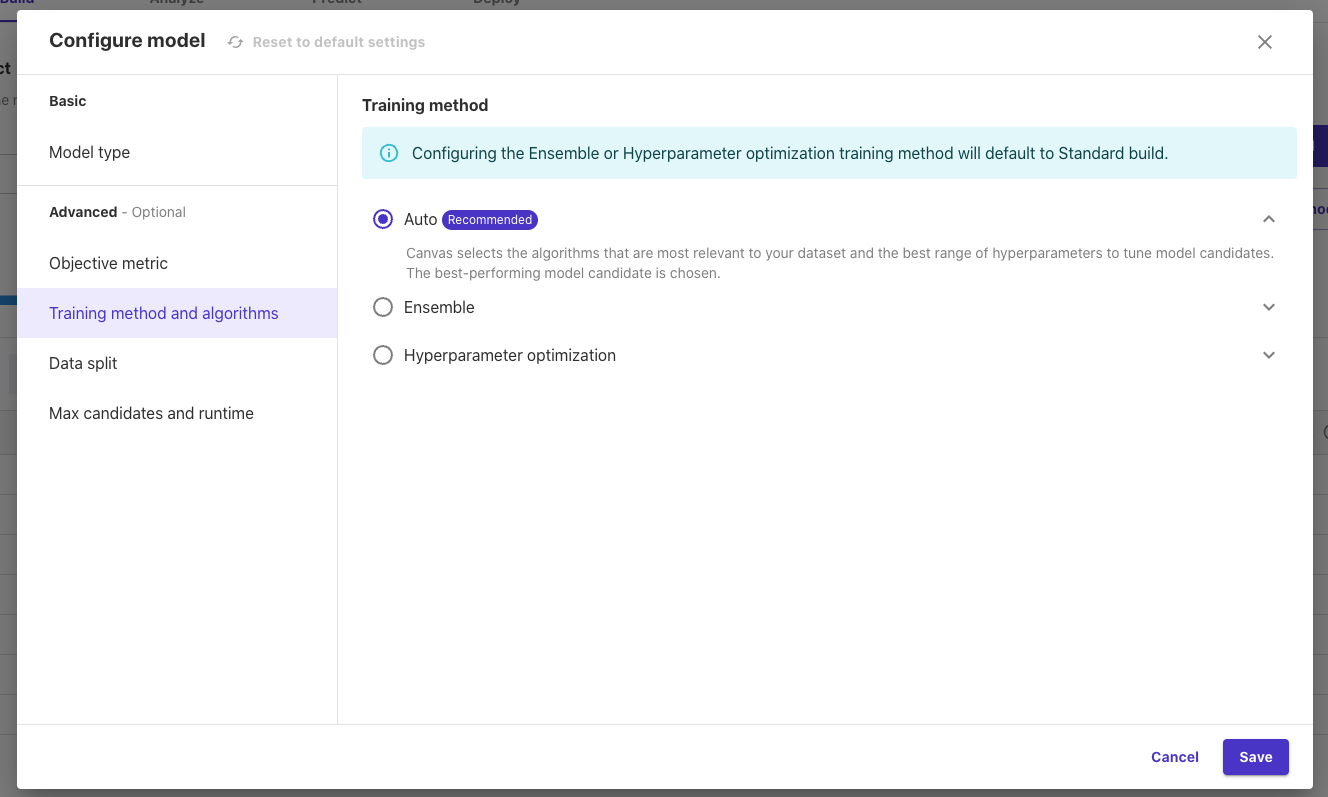
「Training method」:学習方法を以下3種類から選択できます。
- Auto:データセットに最も関連するアルゴリズムと、モデル候補を調整するための最適なハイパーパラメータの範囲を選択します。最もパフォーマンスの高いモデル候補が選択されます。
- Ensemble:データに基づいてAutoMLアルゴリズムを選択し、多層スタック・アンサンブル・モデルを訓練して、回帰および分類問題の予測を行います。
- Hyperparameter optimization:データセットに対して複数の学習ジョブを実行し、ハイパーパラメータをチューニングして最適なモデルを見つけます。
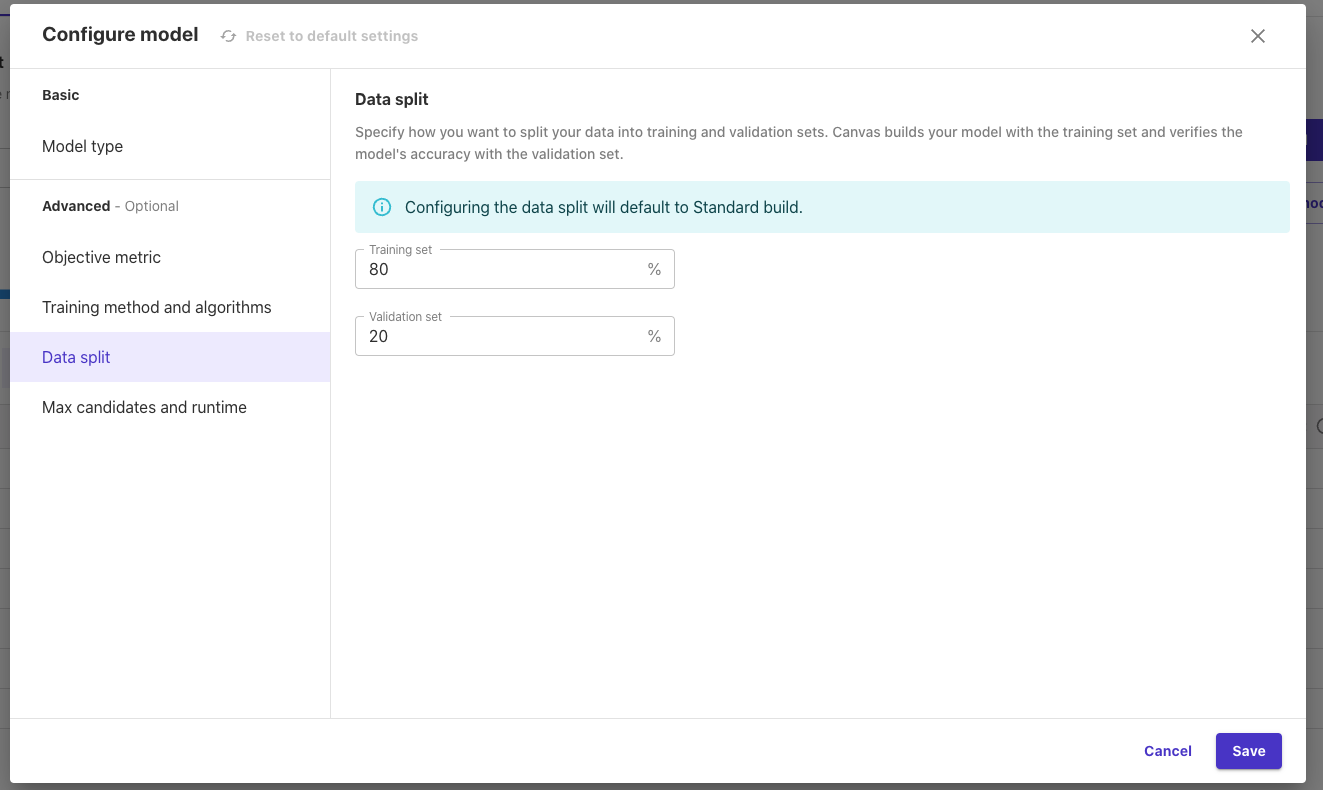
「Data split」:データをトレーニングセットと検証セットに分割する方法を指定します。Canvasはトレーニングセットでモデルを構築し、検証セットでモデルの精度を検証します。
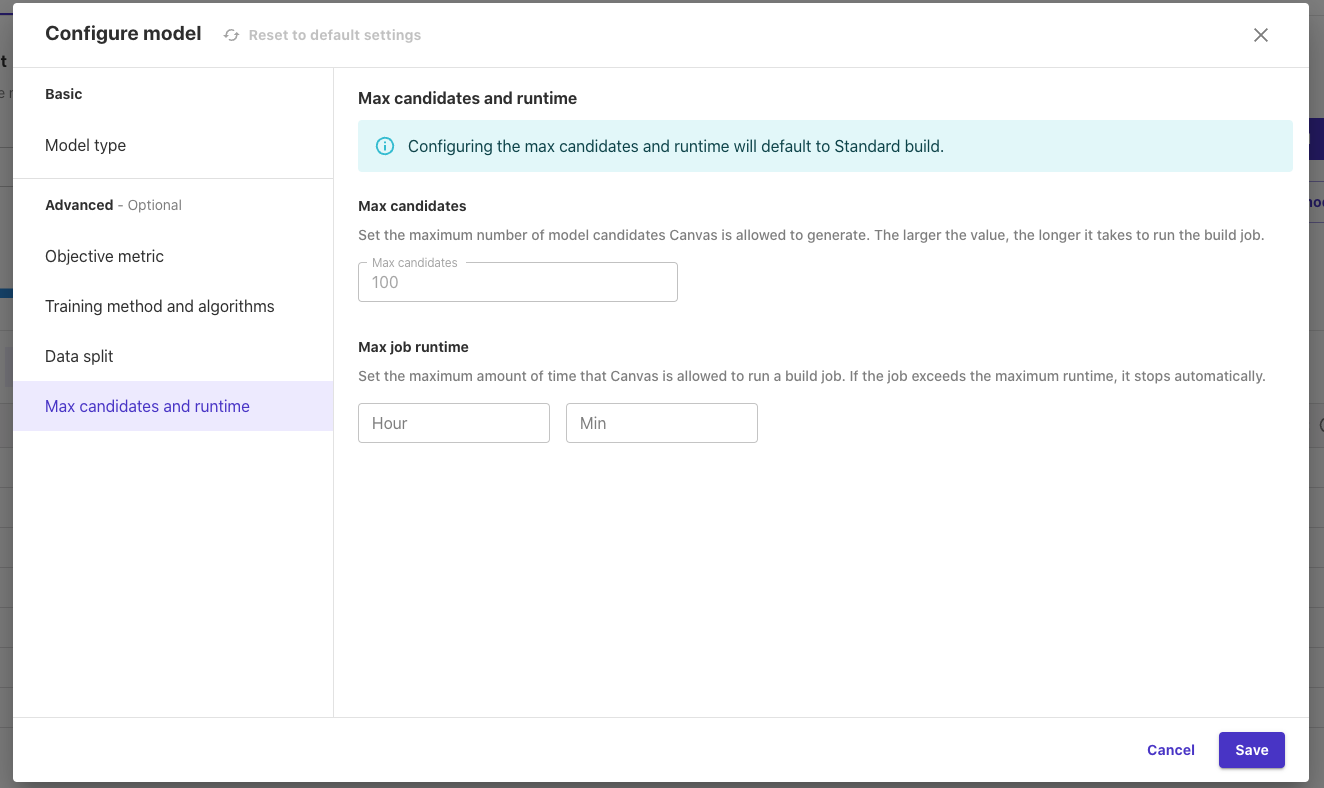
「Max candidates and runtime」:最大候補とランタイムを設定できます。
- 最大候補数
- Canvas が生成できるモデル候補の最大数を設定します。値が大きいほど、ビルドジョブの実行時間が長くなります。
- 最大ジョブ実行時間
- Canvas がビルドジョブの実行を許可する最大時間を設定します。ジョブが最大実行時間を超えると、自動的に停止します。
以上がモデルの設定でした。
では「Quick build」からモデル生成を開始してみます。
Analyze:モデル評価
「Quick build」をクリックすると以下の画面に遷移します。
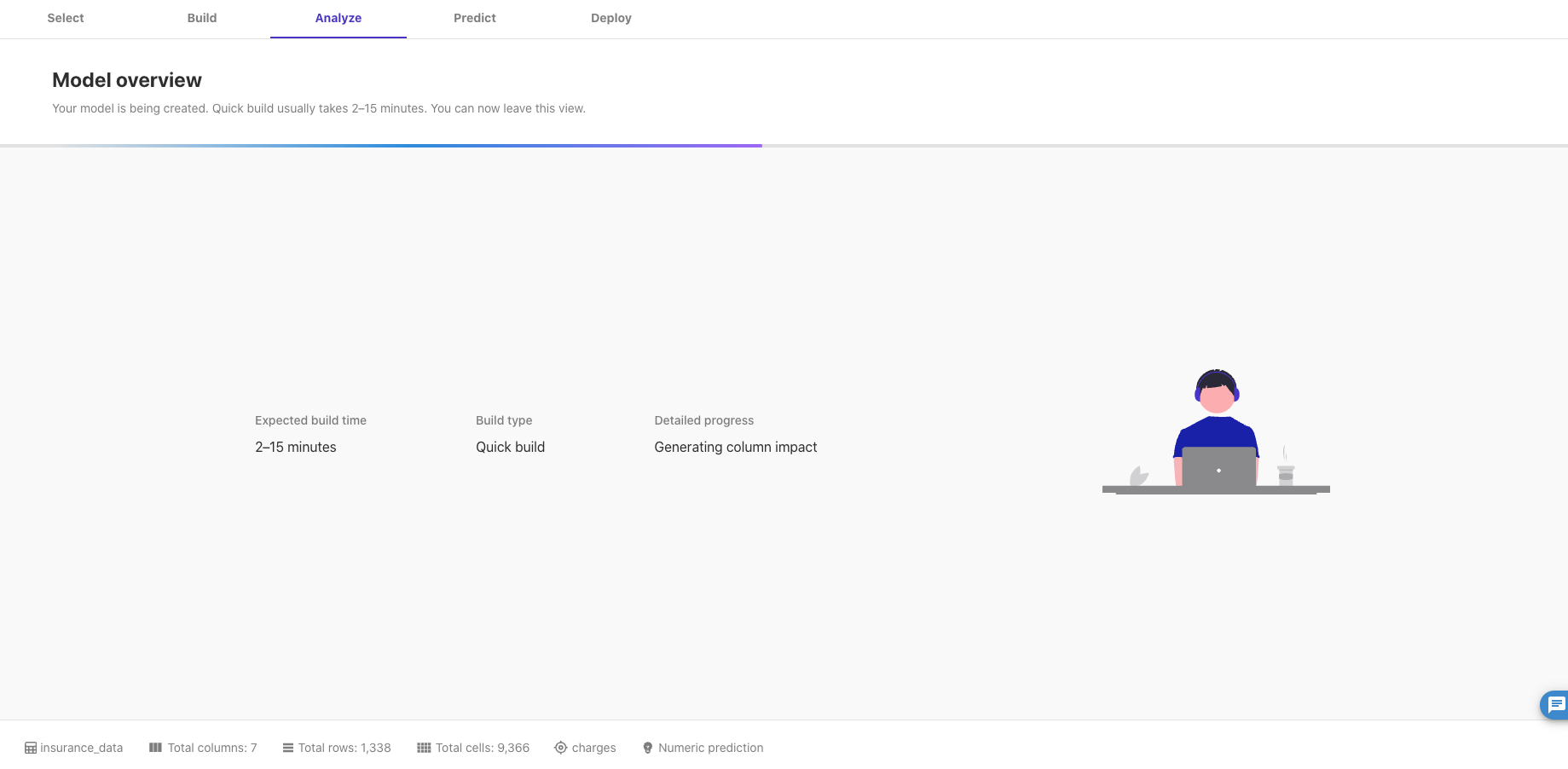
しばらく経つと完了し、結果と評価指標(RMSE、MSE)のスコアが表示されます。
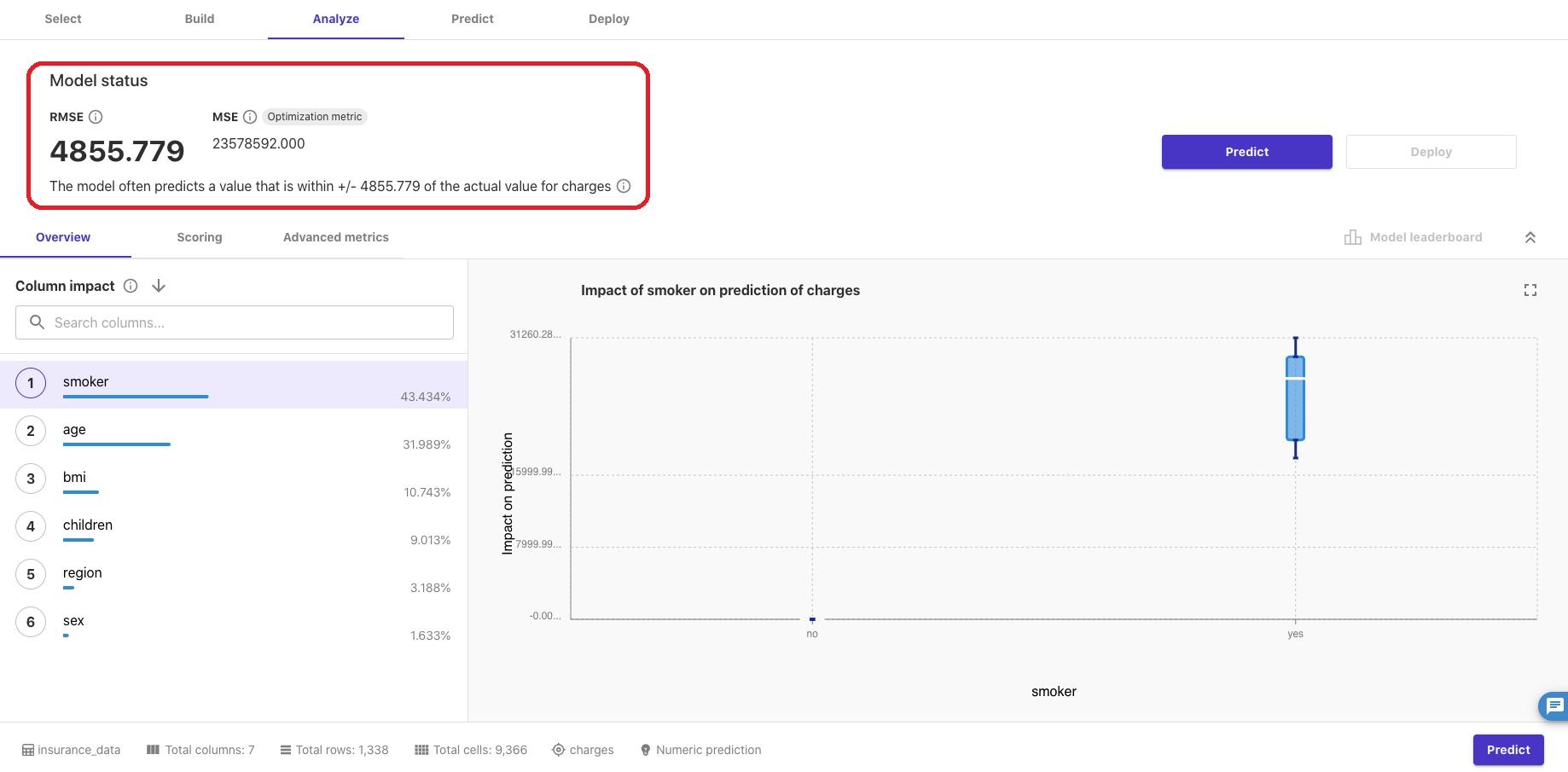
画面下半分(Overview)にはそれぞれのカラム(特徴量)が「charges」の予測にどれくらいインパクトを与えているかが表示されています。(最も健康保険料に影響しているのは喫煙の有無みたいです。)
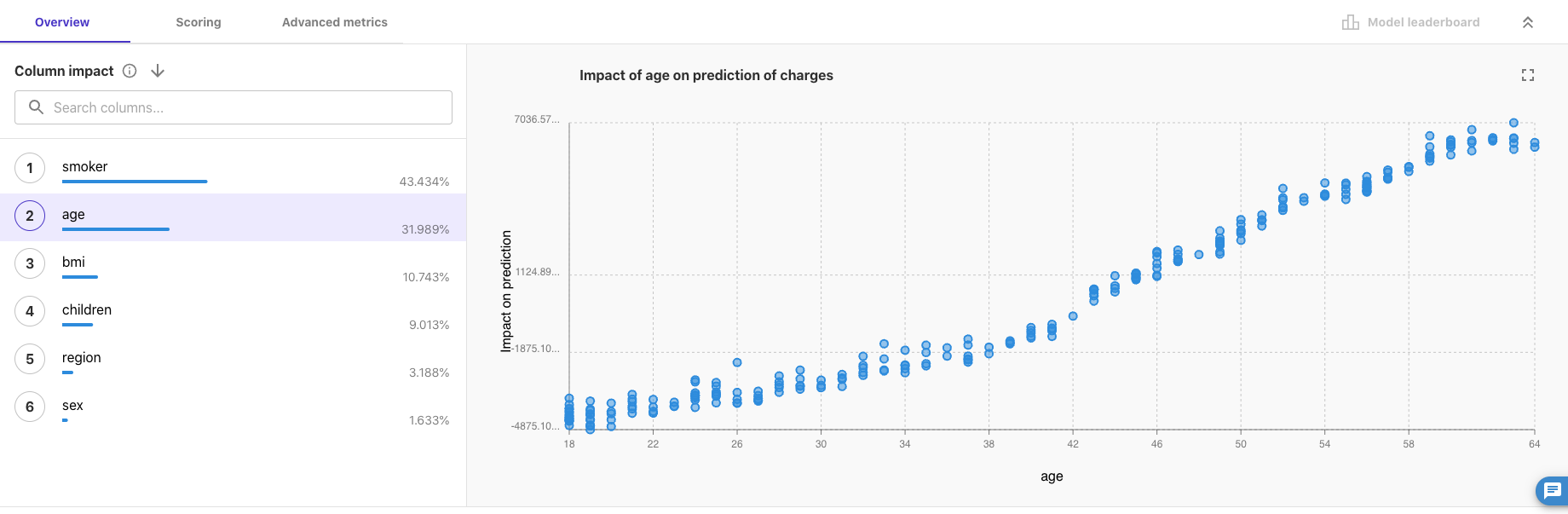
「age」
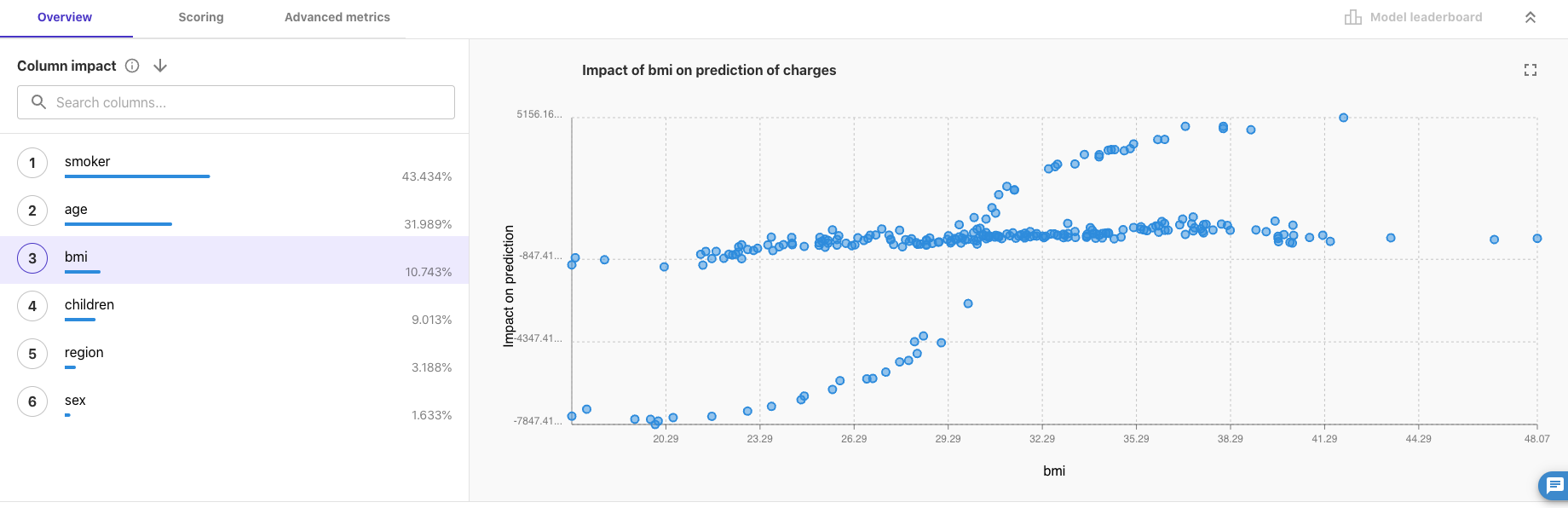
「bmi」
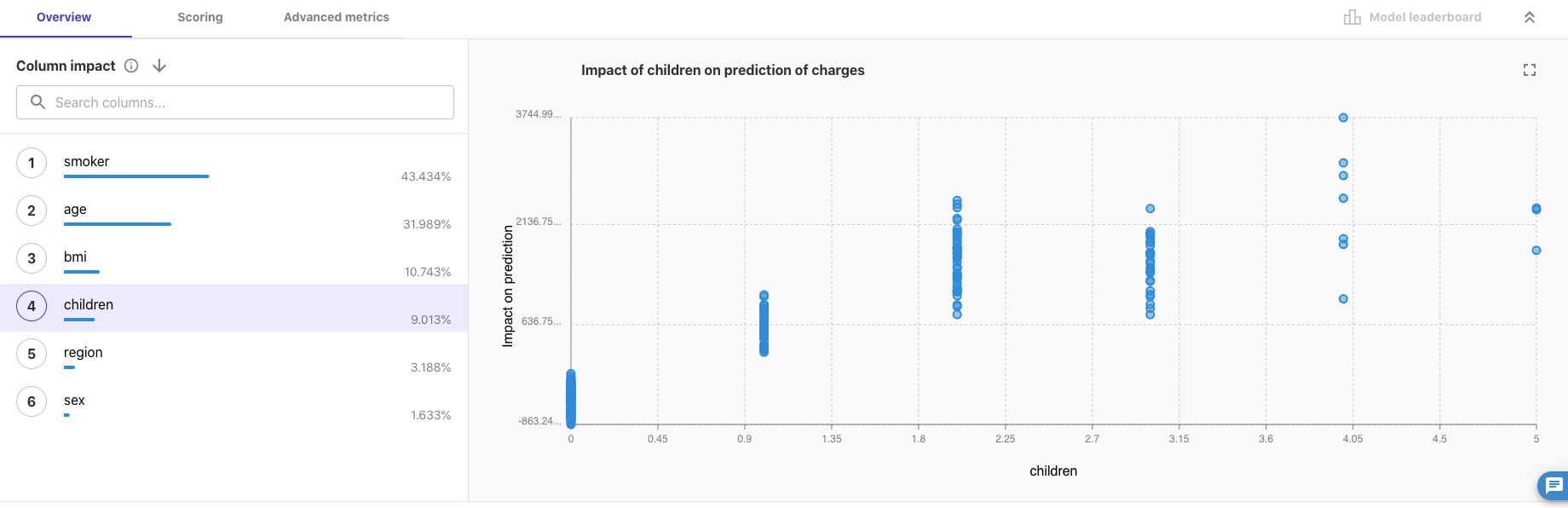
「children」
「Scoring」をクリックすると、予測値と正解値の比較をグラフで見ることができます。
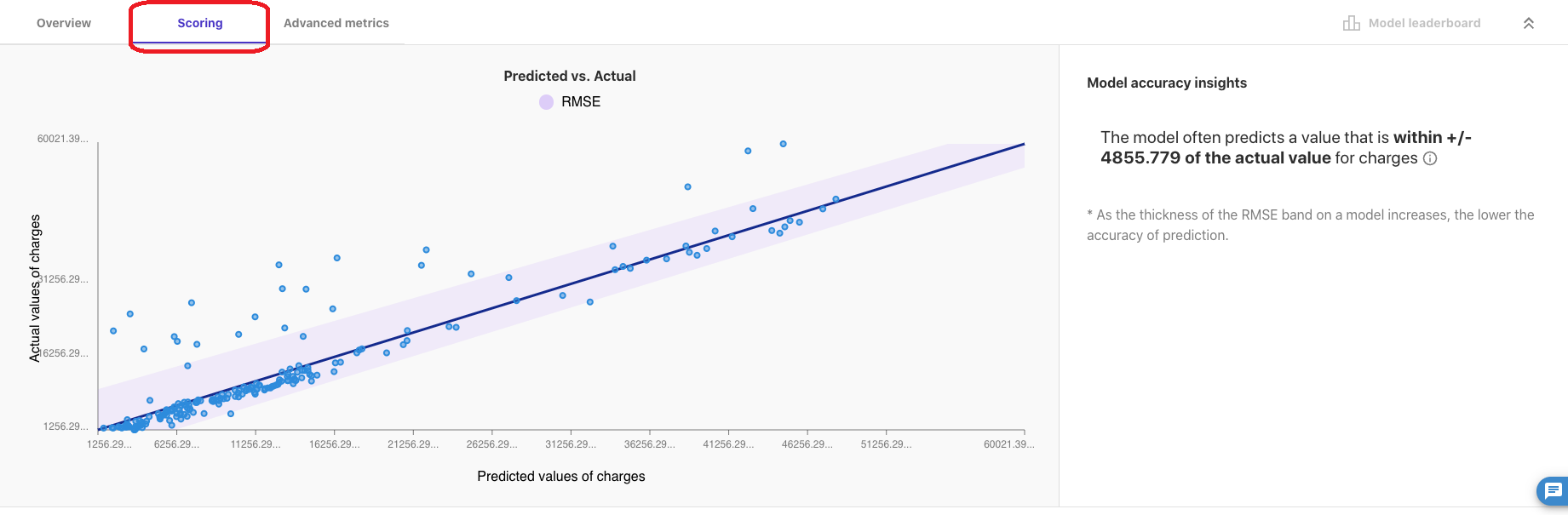
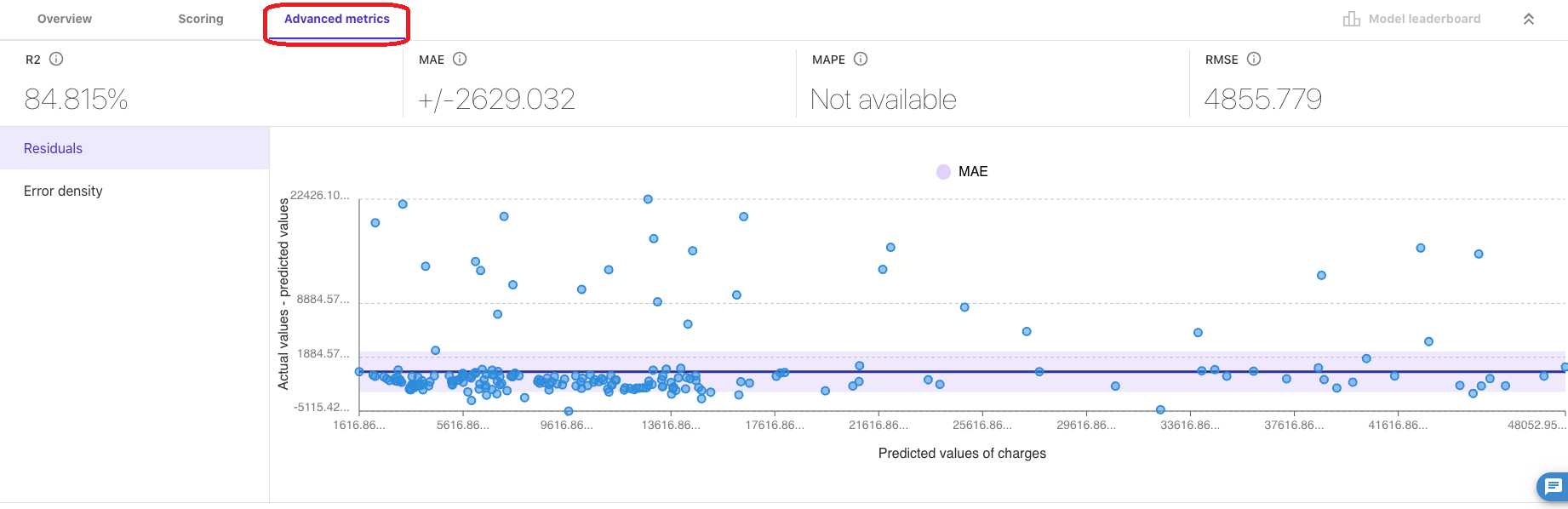
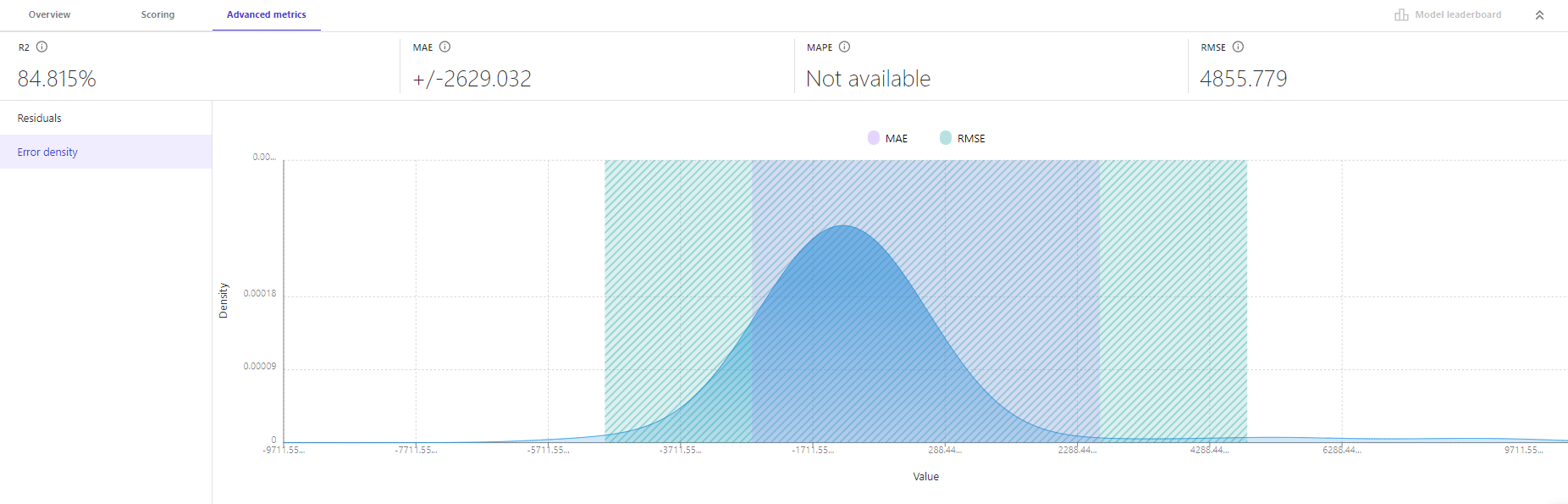
「Advanced metrics」では、RMSE、MSE 以外の評価関数のスコア、「Residuals」、「Error Density」を確認できます。
「Residuals」:モデルの予測値と実際の値との差異を視覚化した、残差プロットです。
このグラフから、モデルの予測精度を評価し、特に予測が実際の値から大きく逸脱している点がないかを確認することができます。また、残差がランダムに分布しているかどうかを検証することで、モデルが持つ可能性のある系統的な誤差を特定する手がかりにもなります。
「Error Density」:エラーの密度を示しています。これは残差(予測値と実際の値の差)の分布を視覚化したもので、モデルの予測誤差がどのように分布しているかを示しています。
Predict:推論
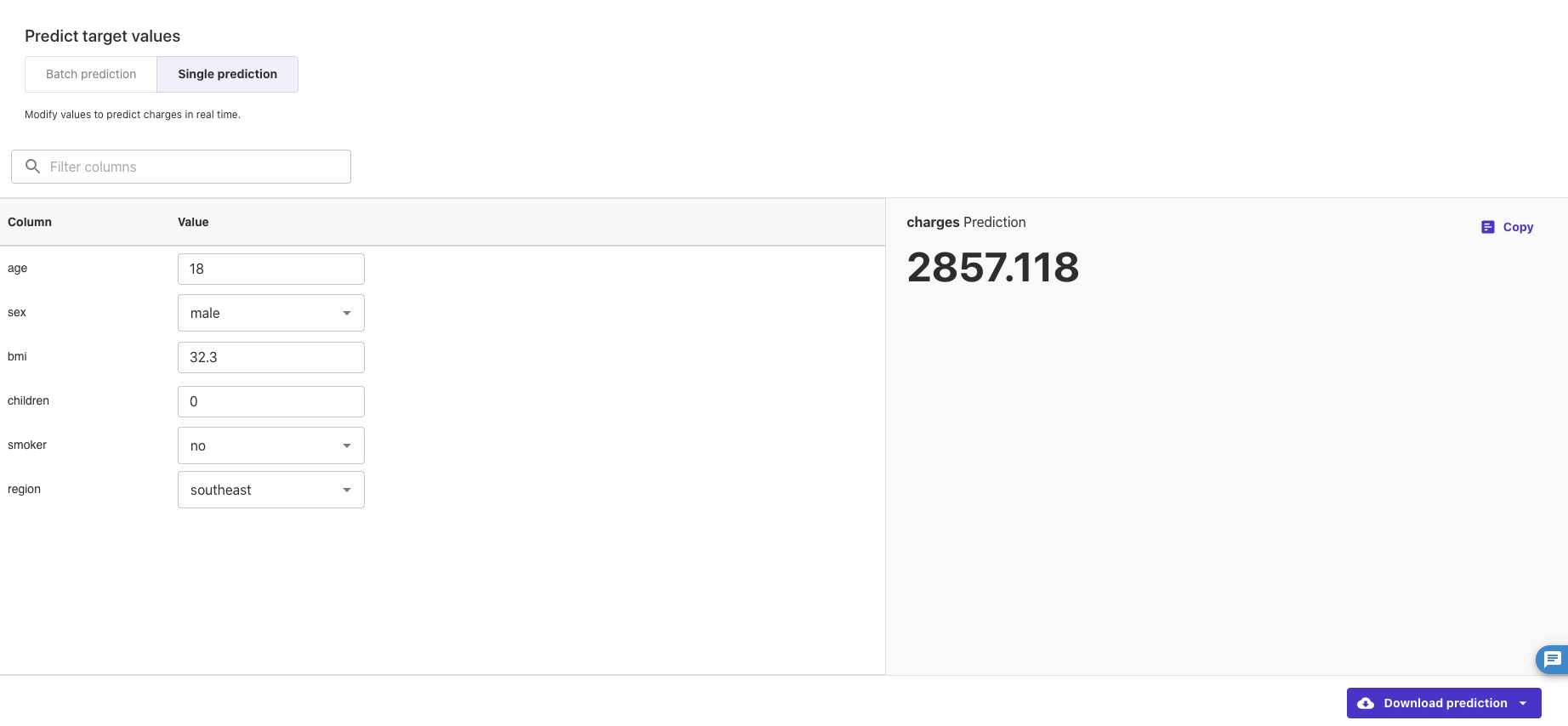
続いて生成したモデルを使ってみようと思います。①「Predict」では、生成したモデルを使って別のデータから予測することができ、②「Prediction target values」から「Batch prediction(バッチ予測)」か、「Single prediction(シングル予測)」かを選択できます。
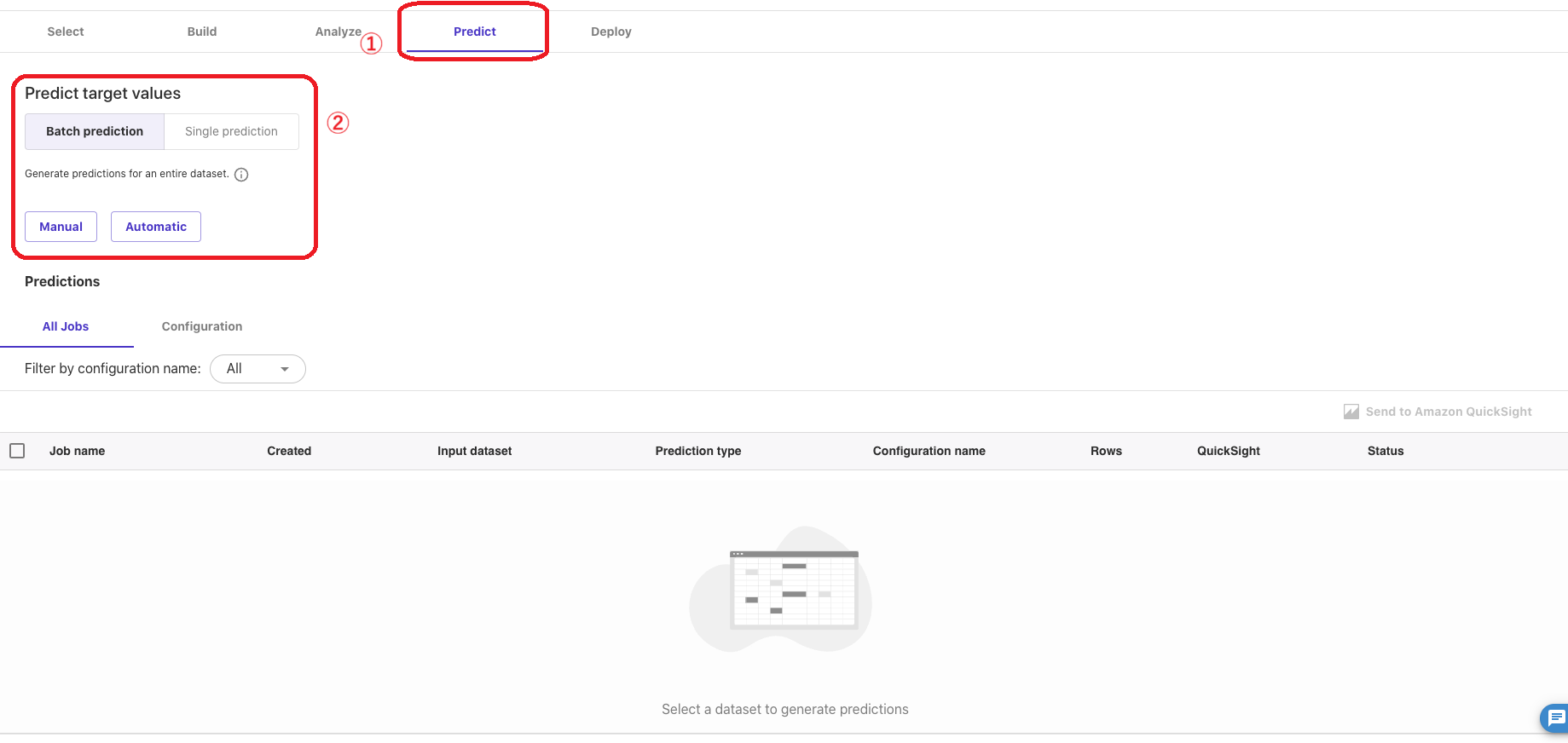
今回テスト用のデータを用意してなかったので「Single prediction」で予測してみようと思います。
ここでは各カラム、特徴量に自由な値を入力して、それに対する予測値を出力させることができます。キャプチャのように各値を設定(18歳、男性、BMI32.2、子供なし、喫煙なし、居住地南東)すれば、画面右に「2857.118」という健康保険料の予測値が得られます。
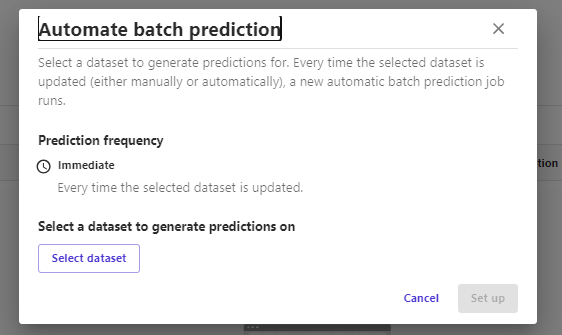
「Batch prediction」の「Manual」では、予測に使用するデータセットを選択し、それで予測を生成できます。また「Automatic」では、予測に使用するデータセットと頻度を設定して、自動で予測ジョブを実行させることができるようです。↓
SageMaker 上での処理
今回実行した処理は、Amazon SageMaker のページの「トレーニング」から確認できます。
画面左の「トレーニング」>「トレーニングジョブ」とクリックします。
ジョブの一覧が表示されるので、任意のジョブをクリックして内容を確認できます。(これは以前実行したものです。)

まとめ
AWS SageMaker Canvas を使用してモデルを構築する方法について概説しました。
AWS SageMaker Canvas は、ビジネスユーザーやデータサイエンティストが機械学習モデルを作成する際に役立つツールです。
データの視覚化や探索、モデルの構築やトレーニング、評価など、様々な機能を備えています。
また、AWS SageMaker Canvas は直感的なインターフェースを提供しており、初心者でも簡単に機械学習モデルを構築することができます。
ユーザーフレンドリーな設計の反面、モデルのカスタマイズ性には限界があることも認識しました。
高度なデータサイエンスのプロジェクトや、より特定のニーズに合わせた微調整を求める場合には、AWS SageMaker Studioのようなツールの利用が求められるかもしれません。
また機会があればそちらも使用してみたいと思います。