


はじめに
Pythonでは、データフレームの操作にPandasがよく使われていますが、設計に上限のあるメモリ使用量や処理速度が問題になる場合があります。Polarsはこれらの問題を解決するための高速でモダンなデータフレームライブラリです。
今回はそのPolarsについて学習しましたので、Pandasでできるデータフレーム処理を、PolarsとPandasのスクリプトを比較しながら紹介します。
PandasとPolarasの比較
1. CSVデータの読み込み
まずはCSVの読み込みをしてみます。読み込むデータはKaggkeからこちらのオープンデータを使用します。サイズも約1.6GBと大きめとなっています。
また比較のため、実行時間を計ってみます。(あくまで参考)
Pandas例
start_time = time.time()
df_pd = pd.read_csv('archive/dataset/train.csv')
print(df_pd.head())
print(f'Pandas CSV読込時間: {time.time()-start_time:.5f}秒')
結果は以下になります。
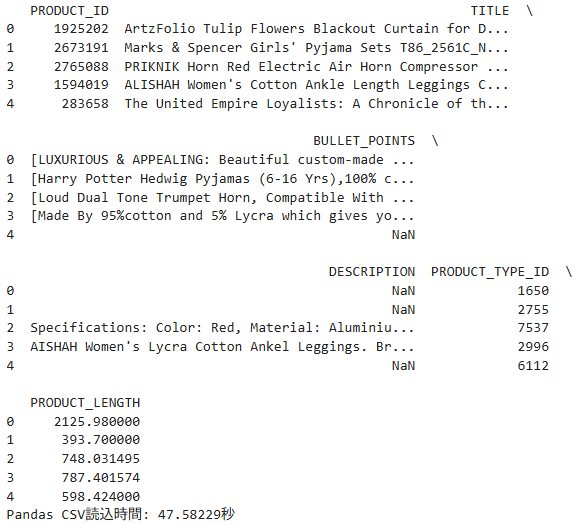
実行時間は約 47 秒となりました。
続いてPolarsでCSVを読み込んでみます。
Polars例
start_time = time.time()
df_pl = pl.read_csv('archive/dataset/train.csv')
print(df_pl.head())
print(f'Polars CSV読込時間: {time.time()-start_time:.5f}秒')
スクリプトはPandasと変わらず read_csv() でCSVファイルを読み込めます。

表示の仕方もPandasとは異なっており、枠線が追加されてます。
時間は約 11 秒と、Pandasより短い時間で読込が完了しました。
PolarsはPandasと同様に、先頭行を表示する head と 末端行を表示する tail は使えるようです。
2. 行選択
次に行選択を比較します。
Pandasでは loc で列名を指定するか、iloc でインデックスを指定することでデータを抽出できます。
Polarsでは、先ほどの出力結果を見た通り、インデックス列がないため、loc や iloc は使えませんが、Python標準のスライスは使うことができます。
Pandas例
start_time = time.time()
# 行選択
sliced_df_pd = df_pd.iloc[1001:2000]
print(sliced_df_pd.head())
print(f"Pandas 行選択時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 行選択
sliced_df_pl = df_pl[1001:2000]
print(sliced_df_pl.head())
print(f"Polars 行選択時間: {time.time() - start_time:.5f}秒")
結果
Pandas フィルタリング時間: 0.24555秒
Pandas フィルタリング時間: 0.04687秒
それぞれ大差なく、行抽出を行うことができました。
3. フィルタリング
次にデータのフィルタリングを比較します。
Pandasでは df[df["column"]==""] のように条件を記述しますが、Polarsでは filter() と pl.col を組み合わせて条件を記述します。
Pandas例
start_time = time.time()
# 条件フィルタリング
filtered_df_pd = df_pd[(df_pd["PRODUCT_ID"] > 200000) & (df_pd["PRODUCT_TYPE_ID"] > 5000)]
print(filtered_df_pd.head())
print(f"Pandas フィルタリング時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 条件フィルタリング
filtered_df_pl = df_pl.filter((pl.col("PRODUCT_ID") > 200000) & (pl.col("PRODUCT_TYPE_ID") > 5000))
print(filtered_df_pl.head())
print(f"Polars フィルタリング時間: {time.time() - start_time:.5f}秒")
結果

Pandas フィルタリング時間: 11.27074秒

Polars フィルタリング時間: 0.27175秒
フィルタリングに関してはPandasの方がやや早い結果となりました。
4. 並べ替え(ソート)
次にデータの並べ替えを比較します。
Pandasでは sort_values を使用し、Polarsでは sort を使った同様の記述で並べ替えが可能です。
Pandas例
start_time = time.time()
# 並べ替え
sorted_df_pd = df_pd.sort_values(by="PRODUCT_ID", ascending=False)
print(sorted_df_pd.head())
print(f"Pandas 並べ替え時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 並べ替え
sorted_df_pl = df_pl.sort("PRODUCT_ID", descending=True)
print(sorted_df_pl.head())
print(f"Polars 並べ替え時間: {time.time() - start_time:.5f}秒")
結果
Pandas 並べ替え時間: 5.08156秒

Polars 並べ替え時間: 23.94773秒
並べ替えはデータ量によってかなり時間が増減すると思いますが、全量のソートとなると、PandasとPolarsでは処理時間に大きな差が生じるようです。
5. グループ化と集計
次にグループ化・集計を比較します。
Pandasでは、groupby でグループ化、agg で集計方法を記述します。
Polarsでは、Pandas同様に group_by (アンダースコア有・・・)と agg でグループ化と集計を行い、集計するカラムを col 、集計方法を sum() や mean() で指定して記述します。alias で新しいカラム名を指定します。
Pandas例
start_time = time.time()
# グループ化と集計
agg_df_pd = df_pd.groupby("PRODUCT_TYPE_ID").agg({
"PRODUCT_LENGTH": ["mean", "max"]
})
print(agg_df_pd.head())
print(f"Pandas グループ化と集計時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# グループ化と集計
agg_df_pl = df_pl.group_by("PRODUCT_TYPE_ID").agg([
pl.col("PRODUCT_LENGTH").mean().alias("AVG_PRODUCT_LENGTH"),
pl.col("PRODUCT_LENGTH").max().alias("MAX_PRODUCT_LENGTH")
])
print(agg_df_pl.head())
print(f"Polars グループ化と集計時間: {time.time() - start_time:.5f}秒")
結果

Pandas グループ化と集計時間: 1.48616秒

Polars グループ化と集計時間: 19.65873秒
Pandasの方が早いようです。
6. 列の追加
次に列の追加を比較します。
Pandasでは直接列名を指定して計算結果を格納し、Polarsでは with_columns を使い、新しい列を追加します。
Polarsでは列名の変更に alias や、元の列名の前後に文字を追加する prefix や suffix を使用します。
Pandas例
start_time = time.time()
# 新しい列の追加
df_pd["UPDATED_PRODUCT_LENGTH"] = df_pd["PRODUCT_LENGTH"] * 1.1
print(df_pd)
print(f"Pandas 列追加時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 新しい列の追加
df_pl = df_pl.with_columns((pl.col("PRODUCT_LENGTH") * 1.1).alias("UPDATED_PRODUCT_LENGTH"))
# df_pl = df_pl.with_columns((pl.col("PRODUCT_LENGTH") * 1.1).name.prefix("UPDATED_"))
# df_pl = df_pl.with_columns((pl.col("PRODUCT_LENGTH") * 1.1).name.prefix("_UPDATED"))
print(updated_df_pl.head())
print(f"Polars 列追加時間: {time.time() - start_time:.5f}秒")
結果
Pandas 列追加時間: 0.46741秒
Polars 列追加時間: 0.21647秒
ほぼ同じ早さのようです。
7. 列の削除
次に列の削除を比較します。
PandasもPolarsも drop を使用します。
Pandasでは引数に columns= でカラム名を指定しますが、Polarsではそのままカラム名を記述すればよいです。
Pandas例
start_time = time.time()
# 列の削除
df_pd = df_pd.drop(columns=["UPDATED_PRODUCT_LENGTH"])
print(df_pd.head())
print(f"Pandas 列削除時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 列の削除
df_pl = df_pl.drop("UPDATED_PRODUCT_LENGTH")
print(df_pl.head())
print(f"Pandas 列削除時間: {time.time() - start_time:.5f}秒")
結果
Pandas 列削除時間: 20.98425秒

Polars 列削除時間: 0.02419秒
8. 結合(列方向)
次にデータの結合を比較します。
Pandasでは merge を使い、2種のデータフレーム、結合キー、結合方法を指定して結合します。
Polarsでは、一方のデータフレームに join を使って、結合する他方のデータフレームと結合キー、結合方法を指定して結合します。
⇒Pandasの merge のもう一つの書き方、df1.merge(df2) に似ています。
結合方法は、Pandasと同じく、inner, left, right, outer (Polarsでは full), cross の他に、キーがマッチしない行を残す anti というものがあります。
Pandas例
# df_pd_2 = df_pd.head(300)
start_time = time.time()
# データフレームの結合
joined_df_pd = pd.merge(df_pd, df_pd_2, on="PRODUCT_ID", how="inner")
print(joined_df_pd.head())
print(f"Pandas 結合時間: {time.time() - start_time:.5f}秒")
Polars例
# df_pl_2 = df_pl.head(300)
start_time = time.time()
# データフレームの結合
joined_df_pl = df_pl.join(df_pl_2, on="PRODUCT_ID", how="inner")
print(joined_df_pl.head())
print(f"Polars 結合時間: {time.time() - start_time:.5f}秒")
結果

Pandas 結合時間: 0.74357秒
Polars 結合時間: 10.05689秒
Pandasの方が早いみたいですね。
9. 結合(行方向)
先ほどは列方向の結合だったので、次に行方向の結合を比較します。
Pandas、Polarsともに concat を使用しますが、Pandasでは引数で行列の方向を設定しますが、Polarsでは自動的に行方向の結合になります。
Pandas例
# df_pd_2 = df_pd.head(300)
start_time = time.time()
# データフレームの結合
concat_df_pd = pd.concat([df_pd, df_pd_2], axis=0)
print(concat_df_pd.head())
print(f"Pandas 結合時間: {time.time() - start_time:.5f}秒")
Polars例
# df_pl_2 = df_pl.head(300)
start_time = time.time()
# データフレームの結合
concat_df_pl = pl.concat([df_pl, df_pl_2])
print(concat_df_pl.head())
print(f"Polars 結合時間: {time.time() - start_time:.5f}秒")
結果
Pandas 結合時間: 31.96616秒
Polars 結合時間: 0.24839秒
行方向の結合においては、先ほどと違いPolarsの方が早いようです。
10. CSVファイル出力
次にファイル出力を比較します。
Pandasでは to_csv を使用し、Polarsでは write_csv を使用しますが、PolarsのCSV出力はUTF-8固定です。。。
Pandas例
start_time = time.time()
# CSVファイルの出力
df_pd.to_csv("archive/dataset/train_pd.csv")
print(f"Pandas 結合時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# CSVファイルの出力
df_pl.write_csv("archive/dataset/train_pl.csv")
print(f"Pandas 結合時間: {time.time() - start_time:.5f}秒")
結果
Pandas 結合時間: 82.69538秒
Polars 結合時間: 13.22587秒
Polarsでは読み込みと同様にPandasより早く出力できるようです。
Polarsの便利機能
遅延実行
Polarsでは、ファイル読み込みに read_csv ではなく scan_csv を使うことで LazyFrame と呼ばれる遅延実行を行えます。これにより並列処理とクエリの最適化を行うことで、最も高いパフォーマンスでデータ操作を行うことができます。Polarsにとっても推奨されているようです。
以下に、上記で実行したデータ処理をいくつか実行して、処理時間を確認したいと思います。
- 処理内容
- ファイル読み込み
- フィルタリング
- グループ化と集計
- ソート
最後の collect を読むことで計算され、LazyFrame からデータフレームとして出力されます。
スクリプト
# 遅延実行を開始
start_time = time.time()
# LazyFrameでCSVファイルを読み込む
lazy_df = pl.scan_csv('archive/dataset/train.csv')
# 遅延実行のパイプラインを定義
result = (
lazy_df.filter(pl.col("PRODUCT_ID") > 200000) # フィルタリング
.group_by("PRODUCT_TYPE_ID") # グループ化
.agg([
pl.col("PRODUCT_LENGTH").mean().alias("AVG_PRODUCT_LENGTH"),
pl.col("PRODUCT_LENGTH").max().alias("MAX_PRODUCT_LENGTH")
]) # 集計
.sort("AVG_PRODUCT_LENGTH", descending=True) # 並べ替え
.collect() # 実行
)
# 処理結果を表示
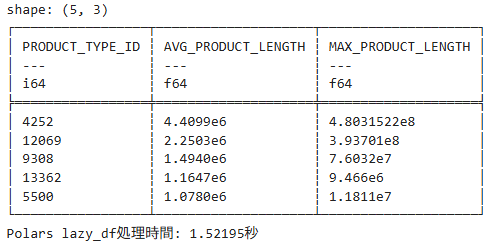
print(result.head())
print(f"Polars lazy_df処理時間: {time.time() - start_time:.5f}秒")結果
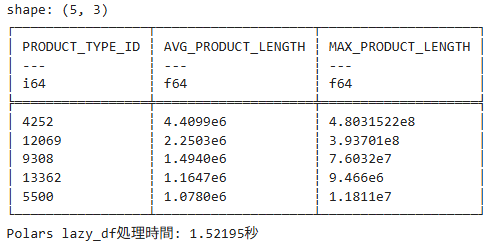
処理時間は約 1.5 秒で、データフレームとして読み込んで処理するより圧倒的に早く処理できているようです。
まとめ
今回はPolarsとPandasを比較してみました。
Polarsは早い印象ですが、処理によってはPandasの方が早かったりと得手不得手があるのかもしれません。ローカルでの実行なので、バックグラウンドソフトの影響もあるかと思います。
ただ最後の LazyFrame の処理時間はかなり早いようで、ファイルサイズが大きすぎて読み込めないといったときでも、すべて読み込む前に計算してメモリの節約になりそうです。


