


はじめに
この記事では、#30DaysOfStreamlitの内容の紹介を行います。
#30DaysOfStreamlitについてはコチラの記事を参照してください。
コンポーネントについて
コンポーネントとはstreamlitでできることを拡張するサードパーティ製のPythonモジュールです。
利用できるコンポーネント
streamlitのwebサイトには数十のコンポーネントが紹介されています。
Fanilo氏(streamlitの製作者)は、このサイトにてコンポーネントを紹介しています。
使い方
まずは、利用したいコンポーネントをインストールします。
Pythonライブラリとして公開されているため、pipでインストールします。
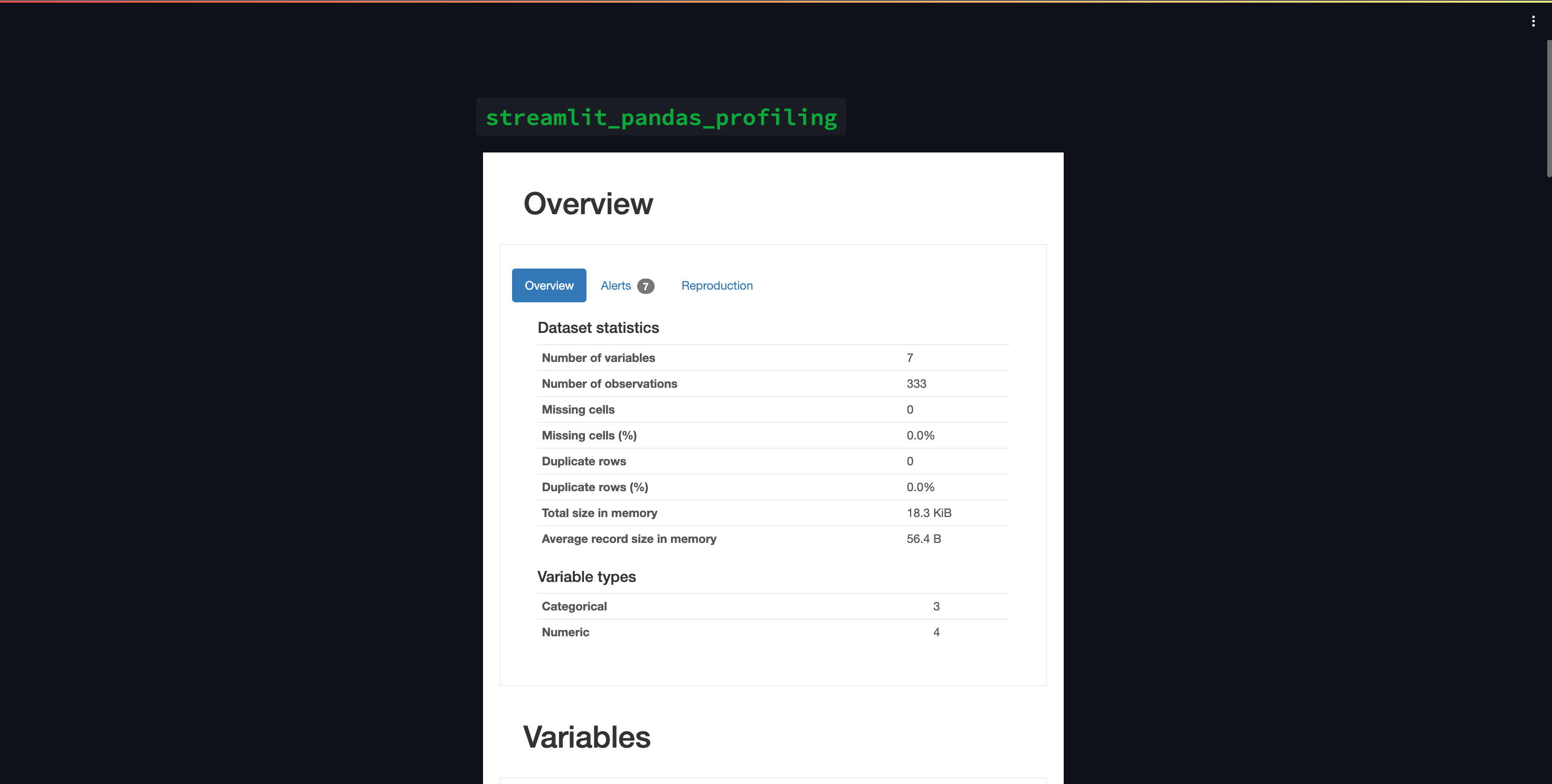
今回は、streamlit_pandas_profilingを利用してみます。
こちらのコンポーネントはPandasデータフレームで読み込まれたテーブルデータのプロファイリングを行い、表示することができるコンポーネントのようです。
また、ライブラリの依存関係上、以下のライブラリもインストールします。
以下のようなアプリケーションを作成します。
コードの解説
まずは、必要なライブラリをインポートします。 依存関係上、ydata_profilingもインポートします。
続いて例の如く、ヘッダーテキストを設定します。
続いてデータをロードします。 今回は、ペンギンデータセットを利用します。(データセットの詳細はリンクを確認してください。)
さらに、以下のコマンドでデータフレームに対するプロファイリングを作成して、st_profile_reportで可視化します。
以下がアプリケーションを実行した時の画面です。
独自のコンポーネント作成
また、コンポーネントは独自で作成することも可能です。 以下のリソースが役に立つかと思います。
また、ビデオ教材としてTim Conkling氏がチュートリアルを公開していますので、そちらも参考になります。

