


1.データ準備(Preparation)
1.1 分析までの遠い道のり
分析の実際を順を追って見ていきます。まずは、データの準備(Preparation)。データの準備には、いくつかの段階があります。
- 分析対象の理解
- 分析内容の決定
- データの収集
- データの変換
- データの格納
まずは分析内容の決定です。これは意思決定者でもある経営者が設定する目標であると言い換えることができます。経営学のピーター・F.ドラッガーは、経営者の意思決定についてこう述べています。
戦略的な意思決定には状況を把握することが必要である。状況を変えることさえ必要である。さらには、いかなる資源が存在するか、いかなる資源が必要かを知ることが必要である。(中略) 戦略的な意思決定では、範囲、複雑さ、重要さがどうあろうとも、初めから答えを得ようとしてはならない。重要なことは、正しい答えを見つけることではない。正しい問いを探すことである。間違った問いに対する正しい答えほど、危険とは言えないまでも役に立たないものはない。 「現代の経営」(上田惇生訳 ダイヤモンド社 2006年 原著は1954年刊)
ここでの「正しい答え」は、そのまま「分析から導きだせる結果」と読み替えることができます。その分析の出発点となるのが、「正しい問い」です。正しい問いとは、ビッグデータを分析する場合、課題発見、問題の理解に他なりません。なぜその分析をするのか、何を解決する必要があるのか。これを常に問い続けなければ分析が徒労に終わることになります。
じつは、出発点を間違えたために、あるいは出発点で手を抜いたために行き詰まる事例は多いのです。何のためにが間違っていたりあいまいなら分析結果も役に立たないことは、ドラッカーが指摘している通りです。加えて、処理段階にも問題が発生します。分析の段階では、ほとんどの場合いくつかのデータをクロス集計して傾向や結果をあきらかにするのですが、クロスするデータは多いときに10項目近くにもなります。無駄な分析まで加えてしまうとデータ量が膨大になって、コンピュータの処理が追いつかなくなるのです。
「何のために分析するのか」は、分析から得られる知見、ひいては経済的効果を大きく左右しますし、「どうやって分析するのか」を固めておけば、分析処理の効率を高める方法を用意できます。ガーベージイン・ガベージアウトという言葉があります。ガベージ、つまりゴミを入力しても、ゴミしか出てこないという意味です。最初の思考の手間を惜しむと良い分析結果が得られないのですが、意外におざなりにされている事例がとても多いことは、強調しておかねばなりません。
1.2 データ利用には洗浄(クレンジング)が不可欠
こうして分析の目標と方法を固めたら、必要なデータを収集します。もっとも重要であり手間がかかるのは、収集の次の段階である洗浄(クレンジング)です。分析作業のかなりの部分は準備段階についやされることが多いのです。これはビッグデータの特徴である非構造化と深く関係しています。
コンピュータで分析する場合、文字や数字のデータは、処理に適した形式なっていなくてはなりません。たとえば、データを表計算ソフトやデータベースに取り込むためには、文字や数字が、それぞれ独立したデータであることをコンピュータが理解できるように変換されている必要があります。たとえば、文書データの中に売上高100万円という記載があったとしても、これは「売上高100万円」という一つのデータの塊でしかなく、コンピュータにはなんの情報も伝わっていないことになります。これを「売上高」「100」「万円」に分解して、特定の記号によって区切られ、「100」(全角文字)は「100」(半角文字)に変換されていなければ、処理に進めないのです。現実的には、アルファベットや数字の全角・半角の混在がクレンジングのかなりの部分を占めます。
これはまだ、データがわかりやすく整っている場合です。ビッグデータは様々なソースを通じて生成されるので、分析のための準備には相当な労力が必要になります。こうした事態がおきてしまうのには、いくつかの背景があります。
まずは、多くの企業に共通している社内システムの複雑さです。システムはそれが導入されている現場のそれぞれの目的に特化しており、高いところから俯瞰して見ると継ぎはぎになっています。たとえばカネの流れをつかむためお経理データは、業務用ソフトや基幹システム、マーケティング部門なら市場調査や売れ行きなどが表計算ソフトで管理されています。顧客管理にはデータベースソフトが使われているでしょう。営業日報などはワープロ文書、ウェブサイトから取り込んだ情報はテキストデータ、プレゼンソフトになっている企画書や報告書もあります。さまざまなセンサーから生成されたデータは、英数字の羅列です。
これらをざっくり一つのデータととらえるのがビッグデータです。各データがそのまま集められている場所をデータレイク(湖)、データ分析のニーズに応じてクレンジングして分類、格納されている場所をデータウェアハウス(倉庫)と言います。さらにレイクやウェアハウスから分析に必要なデータを持ち出して目的別にまとめておく場所をデータマート(市場)と呼びますが、レイクやウェアハウスからマートに移すだけでかなりの労力をついやすことになります。この作業をしない限り、別種のデータを突き合わせる分析はほぼ不可能です。社内のデータであれば、データ作成時点での処理基準の統一によって改善ができないわけではありません。しかし、分析のためのデータを収集する場合は、外部の組織が作成したデータ、政府の統計調査や公的文書、他社のデータなども利用せざるを得ず、事前に統一しようにも、手の届かないものがたくさんあります。
1.3 表記の揺れと固有名詞の不統一
仮にデータの整理ができたとしても、データ上で並んでいる数値(や文字データ)が何であるのか、間違いなく定義されていなくてはなりませんが、この点も意外に手間がかかります。「表記の揺れ」の修正と「固有名詞のコード化」が主な作業です。たとえば、古くから株式投資のために厳密な管理の下で作成・公表されてきた「有価証券報告書」など上場企業の財務データがあります。現在はXBRLという規格によって、どの数値が売上高なのか、どの数値が税引き後利益なのかが自動的に認識できるようになっていますが、こうなったのは十数年前の話。それ以前も財務データはデジタル化されていましたが、データを整理する段階で決算書類を読んだ人間が「これは売上高」「これは税引き後利益」と判断して、キーボードから入力することでできあがったものでした。
というのも、企業から公表される財務データの書類は、データの掲載位置、掲載順が統一されていない(そのために固有名詞のコード化、つまり統一された英数字コードへの置き換えが必要となる)ばかりか、データ項目の表現もばらばら(表記の揺れの修正が必要になる)だったのです。
当時、XBRL制定に関わった関係者によると、売上高という概念の数値だけでも20以上のバリエーションがあったといいます。売上高、業務純益、受注残高といった業態による違いだけでなく、入力された売上高という文字列自体も、「売上高」「売 上高」(文字の間に空白が入れられている)「売り上げ高」など、実に「創造的」に作られていたのです。位取りも「円」「千円」「百万円」「十億円」とさまざまで、たとえば売上高100という数字を取り込めたとしても、それを分析に使えるようにするためには人間の目による判断とデータの転換を必要としたのです。
政府が発表する各種の統計も同じです。いまでは多くの統計データがネットを通じて入手できるようになっています。しかし、各自治体の数値を利用する際にも、本来であれば都道府県コード、市町村コードを使って自治体名を数値化しておくべきなのですが、県名だけ、市町村名だけの表記になっているものがいまだに多いのです。最低限、都道府県の掲載順が決まっていれば、ある程度処理は楽になるのですが、これも担当官庁によって掲載順が異なります。それだけでなく「奈良県」「奈 良 県」(全角の空白が入っている)「奈 良 県」(半角の空白が入っている)「奈良」など、表記の揺れがあるのです。
そのため、自治体名に全国地方公共団体コードを振り、表記の揺れを統一する作業が不可欠になります。統一的に作られているはずの上場企業の財務諸表や政府の統計ですら、このように一筋縄ではいきません。
ダウンロード:政府データ(オープンデータ)を使って、データ分析の流れをまとめています。

なかば冗談のような状況がいまも厳然と横たわっている理由は、これまで様々なデータが「人間が見やすい」ということだけを念頭において作られてきたからです。要するにコンピュータを文書作成機としてしか使っていないのです。データは人間のためか、コンピュータのためか、この違いは想像以上に大きな障壁となっています。データのクレンジングは、人間世界の言葉をコンピュータ世界の言葉へ翻訳する作業ともいえます。
夢の技術と期待を集めるビッグデータというゆるやかな概念と、データ処理の複雑さという現場の認識。このギャップは非常に地味にみえるのですが、ビッグデータの利用にたちはだかる大問題なのです。
2.データの可視化(Visualization)とデータの分析(analyzation)
2.1 表計算ソフトの限界
19世紀中盤に起きたクリミア戦争に従軍し、献身的な活動で「天使」と呼ばれたフローレンス・ナイチンゲールは、後に統計学の先駆者として評価されてイギリス王立統計学会のエンバーに女性として初めて選ばれたということをご存知でしょうか。
ナイチンゲールは洗浄における衛生管理の重要さに気がつき、死者数のデータを原因別にとりまとめておきました。データは戦闘に起因するものよりも、不衛生な環境から発生した病気によるものがはるかに多いことを示していたのです。
帰国後に取得したデータを可視化して政府や軍関係者に現状改善を説得してまわり、その後の兵士の士気向上に寄与したとされます。このときに使われたグラフを紹介しますが、このグラフは後に「鶏のとさか」と名付けられ有名なものです。
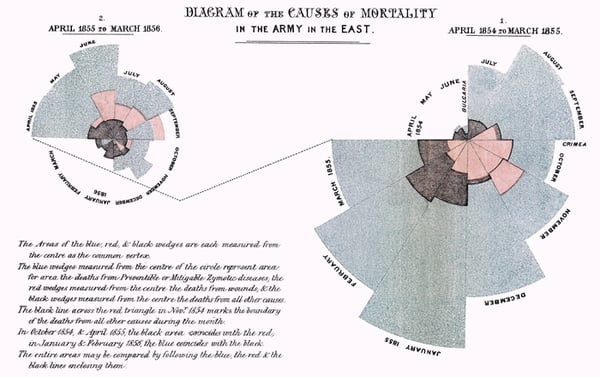
ナイチンゲールは、この取り組みをもって統計学の「先駆者」の評価を得ました。可視化の努力が多くの関係者の説得に効果を発揮したことから、可視化はきわめて重要な作業であることがわかります。
PVAOのうちVの可視化とAの分析を個人のレベルで手がける場合には、表計算ソフトが使われていることでしょう。代表的なソフトはマイクロソフトのEXCELです。特にマーケターや企画部門の担当者のなかには、極めて高度に使いこなしている人も多いはずです。
しかし、表計算ソフトは、データベースやグラフ化の機能が弱く、リアルタイムの分析や可視化には向きません。あくまで計算するためのソフトであり、データを管理したり可視化する機能はあとから付加された機能にすぎないからです。分析作業においては、表計算ソフトの限界を理解しておく必要があります。
主な表計算ソフトの限界を以下にまとめます。
- 一般的なパソコンではデータが一定規模を超えるとスピードが遅くなる
- 可視化、特にグラフ作成に限界がある
- データベースとして使うことが想定されていないので、複雑な集計ができない
- データを集計、変換しながら取り込むことができない
- 気になったデータをさらに細かく集計しようとすると、さかのぼった段階から処理をし直さなければならない
- 分析はシート単位でしかできず、探索型の分析ができない。
こうした限界の何が問題になるのかを考えてみましょう。データ分析、可視化は何のためにやるのかというと、最終的な目的は経営者の意思決定支援です。チーム内での情報共有と理解のためにも役に立ちます。そうなると、データ量の限界がまず問題になります。一般的に表計算ソフトではデータが10万件近くになると目に見えてスピードが遅くなりますが、ビッグデータにおける10万件はむしろ小さな部類に属します。量の面ではまったく相性が悪いと言わざるを得ません。
ビッグデータのもうひとつの特徴であるデータが生成されるスピード、ここでも表計算ソフトとの相性の悪さがあります。時々刻々と生み出されるデータを自動で取り込むことができないのです。
もし表計算ソフトで時々刻々のデータを扱おうとすると、一定時間内に生まれたデータを整えて、表計算ソフトに取り込んで、計算式などを再設定する手順が必要になります。ここは自動化できませんから、人の手を動かさなければなりません。時間と手間がかかるだけでなく、こうした過程で設定のミスが起こりえます。また、経営判断の現場、事業を手がける責任者にとっては、さまざまなデータの傾向を、数字を読む素養のあるなしにかかわらず正しく判断する必要があります。直感的に数字を読み取るためには効果的なグラフ化、チャート化による表現が有効ですが、特に表計算ソフトを使い込んだことがある人なら苦労をした経験を持っているでしょう。表計算ソフトは、意外に可視化の機能が弱いのです。説得力のために手書きをしたり、別の描画ソフトを使うのであれば、本末転倒です。さらにビジネスの現場ではすばやい決定が求められます。たとえば、ある顧客層にセグメントした数値に顕著な傾向が出ていた場合、当然のように「このセグメントで再集計したらどうなるか?」と知りたくなります。
表計算ソフトを使う場合を考えてみます。指示を受けた担当者はデータマートからデータを切り出し直して、再集計、グラフ化の手順をふまねばなりません。仮にそれが10分でできあがったとしても、会議の現場なら、すでに話題は別のところに移っているでしょう。
特に量とスピード、可視化に対応するには、別ジャンルのソフトが適しています。それがデータベースとかしかツールを統合したBIツールです。※準備中//BIツールを使った分析手法と実例
また、当然のことながら、データを正しく分析するにはコンピュータの知識ばかりではいけません。統計学の基礎的な知識を持っていないと、データを見誤ることになります。ここでもビッグデータならではの考え方があります。
統計には2つの側面があります。記述統計と推測統計です。記述統計とは集められたデータを分析することで、データから真の姿を読み解くための技術です。推測統計はサンプリングや将来予測のことで、サンプリングとは全数調査の代わりに、全数調査に近い結果を得るようにデータをいかに抜き取るかという技術です。
ビッグデータの良さは、すべてのデータを扱うことが前提となるため、サンプリングを意識する必要は、あまりないことです。一方でビッグデータには「従来の方法では対応できないデータ」も混在しています。全数の分析が可能であるということは、その中に不必要な特異値、ノイズが混じってくることを想定しなくてはなりません。サンプリングではなく統計的なノイズの除去といった、統計の手法にも新しい発想が求められるのです。
3.データの運用(Operation)
そして最終的には分析結果が運用されなければなりません。ここでもまた、現場の理解とツールの使いやすさがカギを握ります。経営判断や現場での業務遂行に使うという運用においては、誰が見ても理解できて、マウスをクリックするだけで、必要な処理ができる簡便性がカギを握ります。
データ分析によって知見を得られたからといって、それをビジネスの実践に移せるとは限りません。人間心理には「理解」と「納得」の間に溝があるのです。行動を起こすためには「理解」させるだけでは不十分で「納得」のレベルに持っていく必要があります。そこで可視化の機能が威力を発揮します。ナイチンゲールの「鶏のとさか」は、まさしくその好例といえます。
「ビッグデータ・ベースボール」(トラヴィス・ソーチック著 桑田 健訳 KADOKAWA 2016年)では、元メジャーリーガーのハードル監督が、ビッグデータ分析をなかなか実戦で活用できなかったことが描かれています。ハードルは現役引退後の解説者時代にセイバーメトリクスについて学び、打撃コーチ時代には統計分析をゲームプランに取り入れるなど、ビッグデータ分析への理解力が高いことを買われてパイレーツの監督に就任しましたが、いざ、実戦となると、なかなか思い切りがつかなかったといいます。
そのためにジェネラルマネージャーのハンティントンが整備したのが「マウスを数回クリックするだけで」様々なデータを画面に呼び出せるシステムでした。データの分析をするだけでなく、結果のわかりやすさ、誰でも利用できる操作性もまたシステムの重要な要件なのです。
BIツールを体験してみませんか?
INSIGHT LABでは、BIツールの無料紹介セミナー(動画)を配信しています。初めてBIツールをご利用される方を対象に、BIツールの概要や、複数あるBIツールの違いについて分かりやすくご説明いたします。


