


今回の記事はAWS RedshiftのPIVOTとUNPIVOTについてになります。
最近テーブルをUNPIVOTしたいと思い、RedshiftのUNPIVOTについてググったところ
PIVOT and UNPIVOT examples
というAWSドキュメントの英語記事が出てきて驚きました!
何故驚いたのか、詳しく記載します!
RedshiftのPIVOTとUNPIVOTについて
他のクラウドDWHであるBigQueryやSnowflakeではPIVOT・UNPIVOT機能はありましたが
元々Redshiftにはありませんでした。
- BigQuery(2021年にPreviewとなり追加されました)
https://cloud.google.com/blog/ja/topics/developers-practitioners/cool-summer-with-bigquery-user-friendly-sql - Snowflake
PIVOT:https://docs.snowflake.com/ja/sql-reference/constructs/pivot.html
UNPIVOT:https://docs.snowflake.com/ja/sql-reference/constructs/unpivot.html
これまでのRedshiftでのPIVOT・UNPIVOTは一般的に知られているように
- PIVOT
CASE式を利用して対象を各カラムに抽出した後に重複をなくす - UNPIVOT
UNION ALLを利用し各カラムを1カラムに連結させる
もしくは対象カラム数分のレコード数を持ったテーブルを作成しCROSS JOINで結合しCASE式で各カラムを指定し抽出
といったやり方でした。
ただこれが結構手間でもあったので他のDWHを触るとRedshiftではこの機能が無いんだよな~便利だな~と嘆いていました。
AWS公式ドキュメントが…
執筆している2022/01/27時点でRedshiftのFROM句についての日本語版ドキュメントでは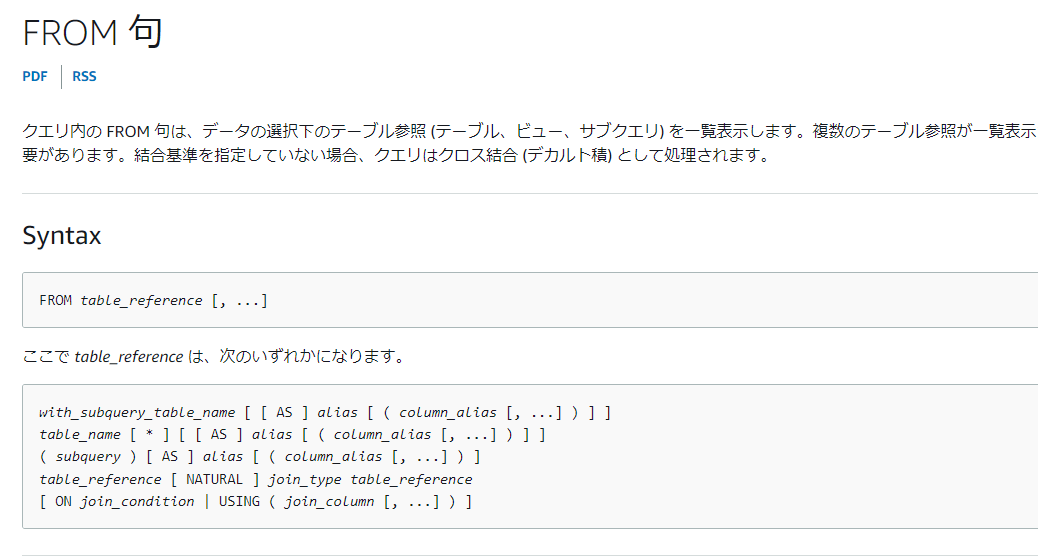
特にPIVOTについての記載はないのですが英語版ドキュメントに切り替えると…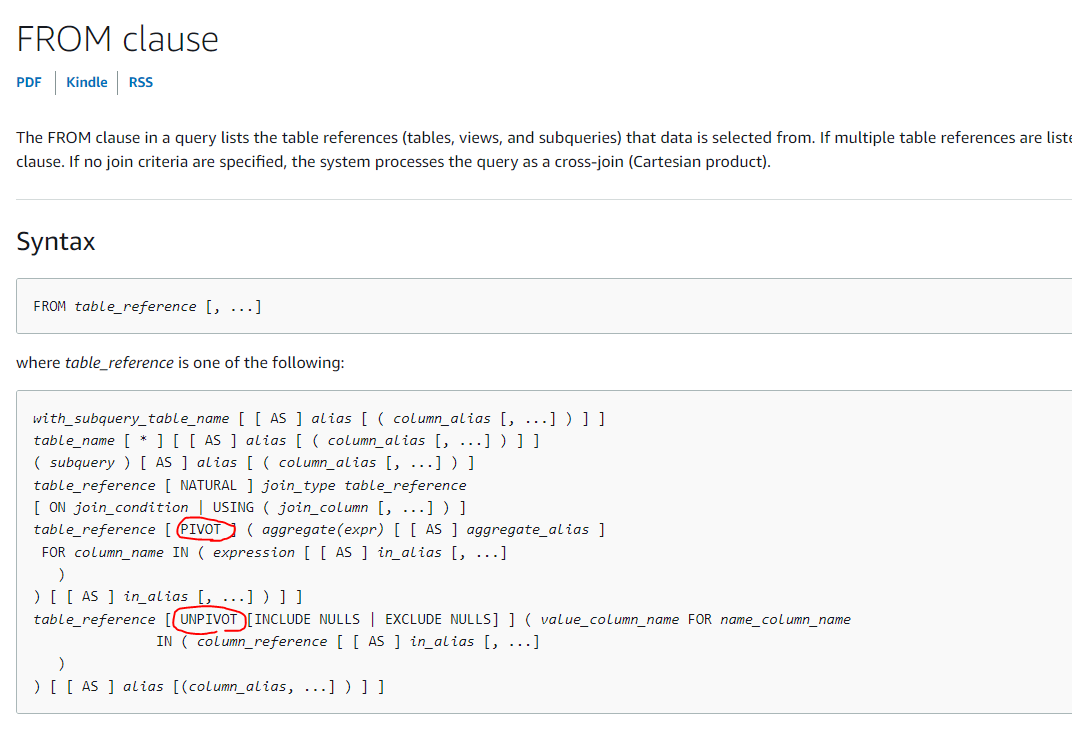
PIVOTとUNPIVOTがあります!おそらくそのうち日本語版でも更新されると思います。
※2022/02/28 追記
2022/02/23にPIVOT・UNPIVOTについてのアナウンスがあったようです。
日本語ドキュメントも対応したようなのでご確認ください!
また色々確認しましたがこの機能についてアナウンスがなさそうでしてサイレント追加的なものでしょうか…?
実は昨年10月頃にエイリアスにUNPIVOTという名称を使っていたクエリが突然使えなくなり、12月ごろにはPIVOTという名称が使えなくなっていたことがあり、もしかすると使えるようになったのではと思っても調べても何も出てこない…ということがあったんですがやはり追加されていたんだなと確信を得ることができました。
兎にも角にもとりあえず実際に触ってみましょう!
実際に触って確認してみる
今回はPIVOT and UNPIVOT examplesのテーブルサンプルを使って確認してみます。
PIVOT
まずはテーブルを作成します。
CREATE TABLE part (
partname varchar
, manufacturer varchar
, quality int
, price decimal(12, 2)
);
INSERT INTO part VALUES ('P1', 'M1', 2, 10.00);
INSERT INTO part VALUES ('P1', 'M2', NULL, 9.00);
INSERT INTO part VALUES ('P1', 'M3', 1, 12.00);
INSERT INTO part VALUES ('P2', 'M1', 1, 2.50);
INSERT INTO part VALUES ('P2', 'M2', 2, 3.75);
INSERT INTO part VALUES ('P2', 'M3', NULL, 1.90);
INSERT INTO part VALUES ('P3', 'M1', NULL, 7.50);
INSERT INTO part VALUES ('P3', 'M2', 1, 15.20);
INSERT INTO part VALUES ('P3', 'M3', NULL, 11.80);テーブルの中身は以下になります。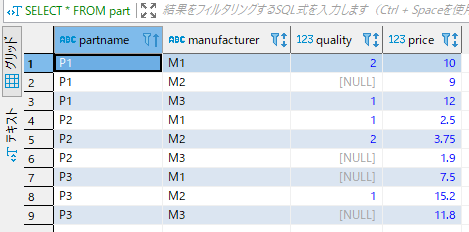
試しにpartnameをカラムにpriceを値としてPIVOTしてみます。
FROM句の後にPIVOTパラメーターを使う形になります。
SELECT * FROM
(SELECT partname, manufacturer, price FROM part)
PIVOT ( sum(price) FOR partname IN ('P1', 'P2', 'P3') );結果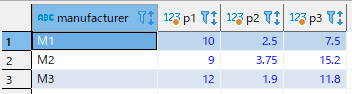
簡単ですね!いちいちCASE式を書かないでいいのは助かります!
sum(price)と集計している形になっていますがmanufacturerを軸にしているので実際は集計していない形になります。
集計関数を使うのでもちろん集計してPIVOTをすることができるようです。
試しにmanufacturer毎のpriceの平均を出してみます。
SELECT *FROM
(SELECT manufacturer, price FROM part)
PIVOT (avg(price) FOR manufacturer IN ('M1', 'M2', 'M3') );結果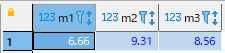
またドキュメントによると以下のような暗黙列の集計やINでNULLを指定することも可能だそうです。
SELECT * FROM
(SELECT quality, manufacturer FROM part)
PIVOT ( count(*) FOR quality IN (1, 2, NULL) );結果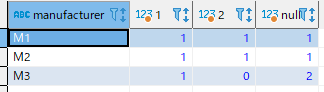
普通の集計ではM3の「2」という値は存在しないのでNULLになるものですが
この集計の特性としてレコードがない場合は0を返すようです。
またPIVOTされるカラム名はエイリアスとして別名を付けることができるようです。
SELECT * FROM(SELECT quality, manufacturer FROM part)
PIVOT ( count(*) AS count FOR quality IN (1 AS high, 2 AS low, NULL AS na));
結果
UNPIVOT
続いてUNPIVOTを見ていきます。
データサンプルは以下になります。
CREATE TABLE count_by_color (
quality varchar
, red int
, green int
, blue int
);
INSERT INTO count_by_color VALUES ('high', 15, 20, 7);
INSERT INTO count_by_color VALUES ('normal', 35, NULL, 40);
INSERT INTO count_by_color VALUES ('low', 10, 23, NULL);テーブルの中身は以下になります。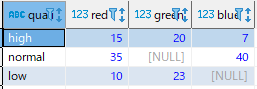
早速、UNPIVOTを確認しましょう。
SELECT *
FROM count_by_color
UNPIVOT (cnt FOR color IN (red, green, blue));結果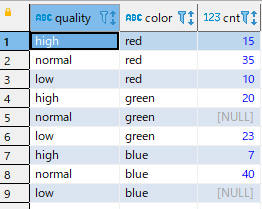
シンプルなクエリでいいですね~!
カラーだけをUNPIVOTする場合は以下になります。
SELECT * FROM
(SELECT red, green, blue FROM count_by_color)
UNPIVOT ( cnt FOR color IN (red, green, blue));結果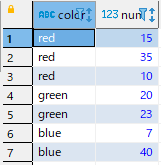
NULL以外の値が縦持ちになりました。
NULLも含めて縦持ちにする場合はINCLUDE NULLSを使います。
SELECT * FROM
( SELECT red, green, blue FROM count_by_color )
UNPIVOT INCLUDE NULLS ( cnt FOR color IN (red, green, blue));結果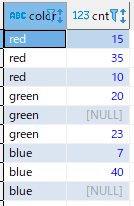
またINで指定する名称を別名に変更することもできるようです。
SELECT * FROM count_by_color
UNPIVOT ( cnt FOR color IN (red AS r, green AS g, blue AS b) );結果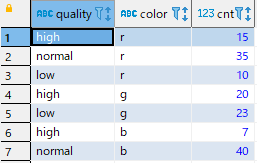
終わりに
Redshiftに新規追加?されていたPIVOT・UNPIVOTについて触ってみました。
この機能の追加でRedshiftでもテーブルの縦持ち・横持変換が扱いやすくなったのではないでしょうか?
これまでRedshiftでPIVOT・UNPIVOTを触っていた方、これから触ってみる方はぜひ触ってみてください!
BIツールを体験してみませんか?
INSIGHT LABでは、BIツールの無料紹介セミナー(動画)を配信しています。初めてBIツールをご利用される方を対象に、BIツールの概要や、複数あるBIツールの違いについて分かりやすくご説明いたします。

-3.png)

