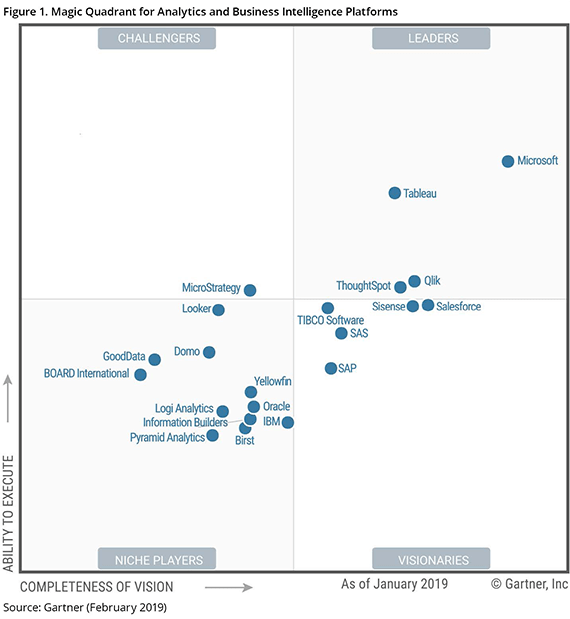
2019年のGartner Magic Quadrant
2019年版のGartner Magic Quadrantの
Business Intelligence and Analytics Platformsにおいて
ちょっとした変化が起きました。
予めお断りしておきますが、
これから書くことはあくまで我々の私見であって、
何ら公正性はありません。
私達の経験と読みかじりの限られた知識の範疇での内容です。
まず、LeadersにはMicrosoft,Tableau,Qlikの3社に加え、
ThoughtSpotが初めて入りました。
これは、SpotIQという独自のインメモリ超並列処理テクノロジーを駆使したインテリジェントな検索型BI製品で、日本市場にも本格参入する模様です。
これまで常連だったLeaderの中で見るとPower BIは不動の地位をキープ、
TableauとQlikはCompleteness of Visionを伸ばすことはできなかった一方で
Ability to Executeのスコアを下げた格好。
Tableauには革新的な技術が生まれなかったし、
QlikはQlikSenseにおいてはAIを利用した技術の取り込みが行われたが、
多くのユーザを抱えるQlikViewが重荷になっているということなのかもしれません。
Tableauはビジュアル面でいうと他のBI製品に対して圧倒的に優位にあると言っていい。アーキテクチャーもシンプルだし、デザインの秀逸さは他社ではそう簡単に真似できそうにない。もはやセルフBIといえばTableauと言ってもいいくらいTableau Desktopはすでに浸透しています。
それは誰が作っても簡単にきれいなダッシュボードになるユーザビリティの良さにあります。
彼らのポリシーは「Tableauを使ってデータ分析しなければビジネスマンではない」というくらいに世の中を変えようとしており、その意気込みを強く感じます。
しかし、見方を変えると彼らはデータ活用するエンドユーザを強く意識しているものの、実際に企業内のデータを統合するには他の力を借りなければいけないというのも事実です。
複雑なデータモデルは元々得手としていない(十分な性能が出ない)し、
ライブ接続でデータベースのデータを直接利用してビッグデータを操るにはハイパフォーマンスなデータベースを必要とします。
また、エンドユーザが利用しやすいようにデータマートをひたすら作り続けるのに疲れたという声も耳にします。
昨年、Tableau Prepも投入され、データ準備に関してやっと競合製品に追いつこうとしています。
あとは複雑なデータに対する性能改善に加え、
Tableau Serverでの開発環境がDesktop並みに良くなってくれればよいのだが、
そのためには何らかの技術革新が必要かもしれません。
セルフBIのスタンダードだが、他社に先行する革新的な技術というのが見当たらない点がCompleteness of Visionの伸び悩みの原因の一つだと思われます。
実用面でいうとEnterpriseとして利用するには、
TCO面での課題が実は多いというのも悩ましいところです。
QlikはQlikView,Qlik Senseという2つのラインナップを持っています。
QlikViewはセンスがない人がアプリを作ると目も当てられないくらいにダサいものになるが、それを熟知している人ならTableauと同じ画面を作成できる(チャートの制限は別として)くらいに作成者のスキルに依存する製品です。
データ準備はETLをSQLライクなスクリプトで実現、数式も「SET分析」を使って素晴らしいパフォーマンスを出す。しかし、スクリプトもSET分析もマニアックな方言で習得に時間がかかるため、Qlik社はQlikViewをセルフBIではなくガイデッドBIとして位置づけています。
Qlik SenseはQlikViewのセルフサービス製品として開発されたもので、最近の製品強化はQlik Senseを中心に行われています。
特にデータモデリングの自動化や拡張知能によるアナリティクス機能の強化など、
私たちはその方向性に共感を持っています。
が、如何せん、デザイン性が見劣りしてしまいます。
センスのいい人が作ったQlikViewアプリくらいのデザインは現段階では無理だし、
Tableau並みのUXを実現する日はいつになるのか。…と悩ましい2つのBIブランドの話。
どっちも頑張ってほしいのだが、Microsoftの絶対王者の時代は当分続きそうな気配です。
そしてVisionariesには、Salesforceのすぐ左に並ぶ形でSisense。
もう少しでLeadersの仲間入りができそうなところまで来ています。
インメモリは今後も主流なのか
現在のLeader製品に共通していえることは全てがインメモリ型BI製品であるということです。
実際、この10年のBI製品の進化はインメモリ技術を中心に行われてきたと言ってよい状態です。
最初にインメモリのBI製品に触れた時はやはり衝撃でした。
数千万件のデータをPC上で自由に扱える時代がやっと来たと実感しました。
その背景にはインメモリにデータを載せるためのデータ圧縮技術やインデックス技術などの技術革新があります。
私たちは、レガシーBIの時代からBIをやっていますが、インメモリ型BIが出てこなかったら、BIはこんなに浸透しなかっただろうと思います。特に日本市場では...
さて、インメモリが当たり前になってくると、もっと大量データを扱えるようにできるんじゃないかと欲は深まるばかりで、メモリが安くなったとはいえ、ユーザの欲求は留まるところを知りません。
数十億件ものデータでも10秒以内のレスポンスで返ってこないと「遅いね」と言われる。
そういう企業はバリバリにチューニングしたOracleのExadataでも買うか、クエリを間違えると1回で数十万ぶっ飛ぶかもしれないBigQueryでも使って下さいーと言いたい。
良いエンジニアが見つかれば全く問題ないんだから。
実際、現行のインメモリ型BIは現時点でいうと数億件レベルならそこそこのパフォーマンスが出せる製品があるというのが正確なところじゃないかと私たちは感じています。
そして、「そこそこのパフォーマンスを出す」ためには、製品によりやり方が違うため、チューニングに製品固有の特殊な知識やスキルが要求されるから、社内でやってみようなんて考えないほうが良いです。
具体的には、Tableauでは複雑なデータモデルは避けるべきだし、QlikだとUIの作り方や数式の書き方でパフォーマンスを改善できたりします。
とはいえ、私たちはこの3年くらい、ユーザの欲求の高まりに応えるために実に涙ぐましい努力をしてきたつもりですが、ブレークスルーできないもどかしい時間を費やしてきたのも事実です。
キャッシュ最適化という選択肢
「Tableau,QlikViewとQlik Senseの3つの違いをデモで見せてほしい」
と頼まれて、8000万件ほどのシンプルなデータを使ってデモをしたことがあります。
因みに作成したダッシュボードにはシンプルな3種類のグラフを配置することとし、3つの製品に実装した上で、1台のPC上で同時に3つの製品を起動した状態でデモをしました。
作成したアプリを開くのにTableauとQlikで大きな違いがあったのが興味深かったので、
共有しておくと、
- データの取り込みはTableauはQlikの3倍時間がかかった。
- 初回の表示はTableauがかなり時間がかかった。
- 2回め以降の表示はTabeauが最も早かった。
- ②と③は意外な結果だった。
こういうことらしい。
Tableauは初期状態でメモリにロードされておらず、
呼び出された時に初めてメモリにロードされるから初回表示は遅い。
Tableau、Qlikともキャッシュを使っており、
一度読み込んだ結果はキャッシュに保持している。
TableauはDesktopの場合、
キャッシュはハードディスク(Tableau Serverではメモリ)を使うが、
Qlikはメモリを使用しているようです。
今回の場合は、PCのメモリが限界の状態でデモしていたのが原因で、Qlikはメモリが不足している状態だとハードディスクの仮想メモリを使用するため、スワップが発生し遅くなってしまいましたが、Tableauはそもそもがハードディスクにキャッシュファイルをおいておく仕様だからQlikより早かった。
実際、物理メモリが不足した状態のQlikのスローダウンというのは、
固まっちゃったんじゃないのかというくらいに遅いからうなずける結果でもあります。
まあ、キャッシュが一番速いというはわかる。しかし、ここで疑問点が発生します。
・インメモリ型BIはメモリにデータをロードしている(Qlikの場合は全データ、つまり全部のせ状態)
・そこにさらにキャッシュデータを載せる=二重載せの状態
じゃあ、CPUが頻繁に使うキャッシュデータを優先してガンガン載せておけば効率がよいのではないか?何も2階建てにしなくてもいいんじゃね?
SisenseのIn Chip TechnologyとElastiCubeとは
人間は眼の前で起きていることを一旦、短期記憶に保存しています。
その短期記憶から必要なものを長期記憶に格納し、必要に応じて長期記憶から取り出しています。
これはコンピュータも同じで、
短期記憶はメモリであり、長期記憶がディスク。
しかし、人間の記憶には重要度が関係している。例えばこんなふうに...
(本人がファイターズのファンであることを仮定して)
ジャイアンツの背番号6番は坂本である。今TVでやっているオープン戦を見て知ったのだが、僕はジャイアンツのファンではなく余り興味がないから、忘れてしまうかもしれない。しかし対戦相手のファイターズの背番号6番は中田であることは覚えている。
こんなふうに人間は自分にとって重要なものを思い出しやすい記憶の領域に配置しています。
Sisenseのデータ管理は、より人間に近く、
データの重要度に応じて、データの配置をコントロールしています。
これは従来のBI製品にはない全く新しい技術であり、
しかも、使い込むとさらに学習されて高速化していくというインテリジェントな機能です。
1.In Chip Technology
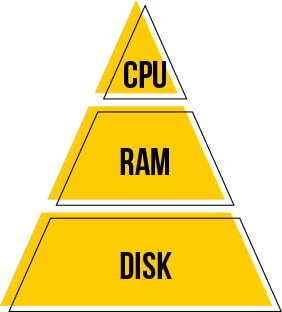
Sisenseの特長の1つしてキャッシュ最適化があります。
この機能はIn Chip Technologyと呼ばれています。
CPUはまず、L1キャッシュに確認する、あればL1キャッシュから取得する。
なければL2キャッシュ、さらにメモリ(RAM)、メモリになければDISKに取りに行く。
だから応答時間はL1<L2<メモリ<DISKと遅くなるわけだが、
Sisenseはキャッシュデータをどこに配置すべきかを機械学習によって制御している。
この技術はサーバで共有される場合、ユーザ単位にも最適化されており、
どのユーザがアクセスしてきているかによってもキャッシュされる内容は異なる。
先程の野球の例でいうと、僕がSisenseにアクセスすると、背番号6="中田"というデータがメモリにロードされる(ファイターズファンじゃない人がアクセスしても呼び出されない)。
野球の放送が始まると、そのデータはL2キャッシュに移動し、さらに中田がバッターボックスに立つとL1キャッシュに移動する。Sisenseは僕の過去の行動から学習して、僕の動きに応じて、必要なデータを最適な場所に配置している。
簡単にいうとIn Chip Technologyはそんな技術です。
言うは易し...であるが、これを実現しちゃったというのがSisenseです。
これまでのBI製品のインメモリ技術と違い、限られたリソースの範囲で最大限のパフォーマンスを出せるよう考えられています。
2.ElastiCube
In Chip Technologyに対応して最適化されたデータベースがElastiCubeです。
ElastiCubeは他のBI製品にも見られるカラムナー(列指向)データベースで、In Chip Technologyに呼応して、カラム単位でスライスして抽出することができるようになっています。
例えば10個のテーブルに合わせて500カラムがあるとします。
よくあるインメモリBI製品ではテーブル全てがメモリにロードされているわけですが、ElastiCubeでは製品毎の売上と顧客毎の売上を集計する場合は、「製品」「顧客」「売上」のカラムのみディスクから抽出され、メモリに展開されます。
これらの使用頻度が高い状況ではIn Chip Technologyによってメモリ、キャッシュにロードされた状態となり、常に高速に処理されます。
インメモリといっても万能ではなく、大量のメモリを搭載し、大量のデータをメモリに展開していれば、当然多くの処理時間を要します。
メモリを過信して限界に悩み続けてきた者としては、Sisenseの登場はまさに朗報でした。
SisenseのIn Chip TechnologyとElastiCubeの組み合わせはビッグデータをスモールデータとして扱うことを可能にし、少ないリソースで最大の性能を発揮する現段階でのベストソリューションと言えると思います。
データモデルの観点でいえば、かなり複雑なデータモデルでもそこそこの性能を発揮できる点も注目されるべき点です。
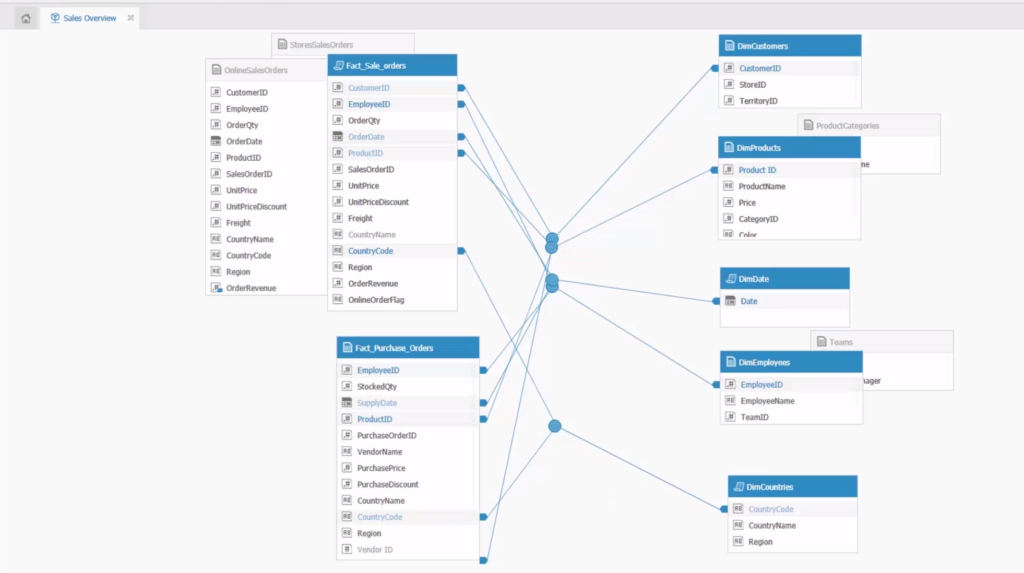
上記のようなデータモデルをデータモデラーを使用して作成できます。
複雑なデータモデルには向かないTableau、連想技術であるがゆえに複数のファクトテーブルで循環参照に悩まされるQlikとは一線を画します。
但し、構築は伝統的なBIの作法に則っており、ファクトテーブルやディメンションテーブル等のスタンダードなBIに関する知識を習得しておく必要があります。
またETLに関していうとSQLベースであり、高度なデータモデルを作りたければSQLで組むことになります。
慣れの問題かもしれませんが、ElastiCubeのデータモデル自体をエンドユーザが作るのはやや難があり、専門のエンジニアに任せたほうがベターな印象です。
データの取り込みは「ビルド」という処理で行われます。
よって常にリアルタイムな状態ではないですが、ビルドのスケジューリングも当然可能なので一定の間隔でデータを更新するように設定できます。
リアルタイムなデータがお望みなら、他のBIと同じように「ライブ接続」も行えますし、データソースコネクタも十分すぎるくらいに揃っているので問題はないです。
Sisenseのダッシュボードデザイン
Sisenseを起動するとブラウザからSisenseサーバに接続し、ブラウザ上で開発します。
下記はSisense社のMaster Courseを通して開発した簡単なダッシュボードです。
もちろん、日本語で開発できます。
但し、ドキュメントは英語なので、弊社のこのサイト(Sisenseナレッジ)を通じて様々なテクニックを紹介させていただければと考えています。
操作感はブラウザベースとは思えない快適さで、Qlik Senseのような固さがないのはSisenseの開発者の技術の高さ、センスを感じます。
デザイン面ではTableauには敵わないが、Qlik よりは断然良い印象です。
標準で実装可能なグラフも主要なものは揃えており(Sisenseではこれらのオブジェクトをウィジェットと呼びます)、エクステンション(add-on)も以下のサイトから入手可能です。
・オフィシャルサポートされているadd-on:Sisense Marketplace
・Community内で共有されているadd-on:Sisense Community Plugins List
Sisenseで新たなビジュアライゼーションの旅に出よう
データに変化があるとアラートしてくれるPulseとか、R連携とか、色々書きたいことはまだまだありますが、この記事はここまでにして、全体をまとめます。
BI、特にビジュアライゼーション分野での重要課題というのは、こういうことかと思っています。
- エンドユーザが直感的に使えなきゃいけない
- アウトプットがきれいで、自分が思い描いたように表現できなきゃいけない
- 今の時代、数億件くらいはラクラクと集計できる環境にしておきたい
- 分析するのは自分
=エンドユーザであって、要件に応じてデータベース担当者にデータマート作ってもらうのはいやだ(やっていいなら自分でやるが、大抵の場合はやらせてもらえない) - データ分析のためのデータモデルは、分析をよく知っているパワーユーザが作り、エンドユーザはそれを利用するだけにしたい
Sisenseを体験してみませんか?
INSIGHT LABではSisense紹介セミナーを定期開催しています。Sisenseの製品紹介や他BI製品との比較だけでなく、デモンストレーションを通してSisenseのシンプルな操作性やプレゼンテーション機能を体感いただけます。

-3.png)