みなさんこんにちは、INSIGHT LAB株式会社のSHOWです。
本記事はApache Kafkaを使ってSnowflakeへリアルタイムストリーミング処理を検証した内容となります。
前提
最初に前提のお話をします。
- Kafkaの詳細な構築方法は割愛させていただきます
- ターゲットとなるSnowflakeは個人のフリーアカウントを利用しました
- Kafkaを起動させるマシンはUbuntu20.04を採用しております
Apache Kafkaとは?
Kafkaは大規模なストリームデータを扱うことができるオープンソースの分散メッセージングシステムです。
Kafkaの特徴は次のとおりです。
- Pub/Subモデルを採用し、複数サーバからのログの受信インターフェースを1か所に集約が可能
- 大量のメッセージを高速処理が可能
- 複数のKafkaサーバを稼働させることで高可用性を実現
- Kafkaクラスタをダウンタイム無しで柔軟に拡張が可能
上記以外にも特徴はありますが、詳細はKafka公式ドキュメントをご確認ください。
Apache kafkaの簡易アーキテクチャ図
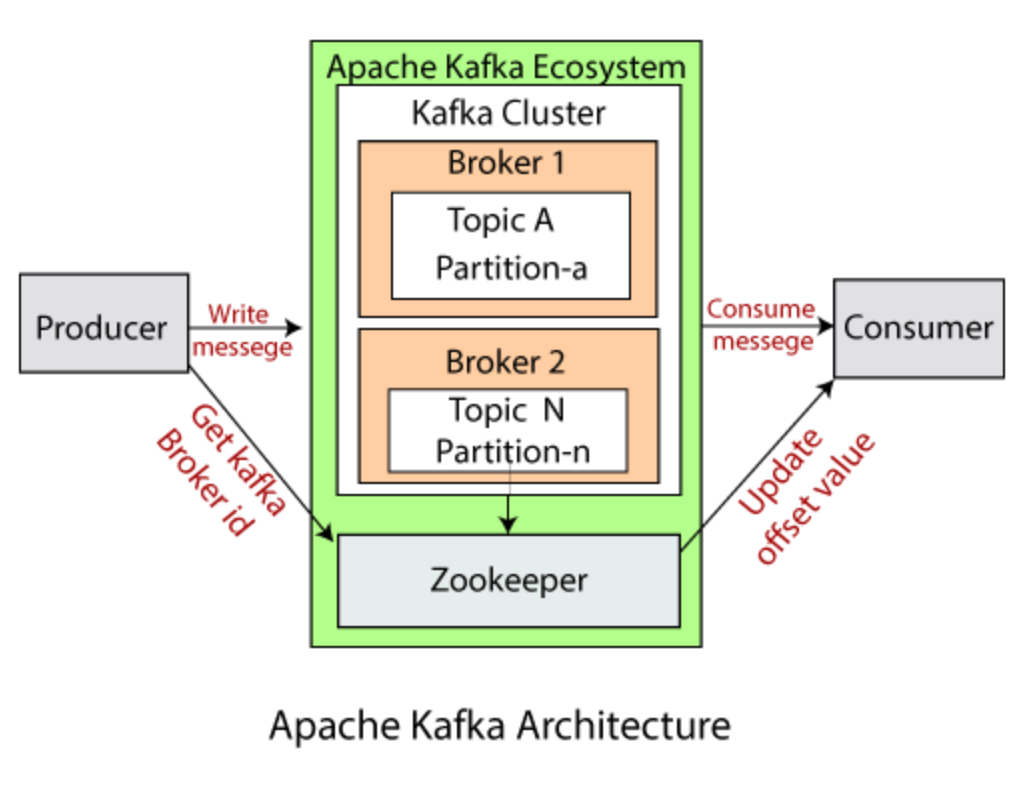
Kafkaの話を始めると大変長くなりますので、さっそくKafkaのストリーミング処理を検証してみたいと思います。
必要なリソースの起動
Kafkaを動かすために必要なリソースを作成起動します。
Brokerの起動
Broker は Publish/Subscribe メッセージングシステムが稼働する 1 台のサーバーです。
よくある構成としては、Pub/Subサーバが複数あり、そのサーバを管理するのがZookeeperとなります。
現在はZookeeperでの管理から離れBroker自身で管理するアーキテクチャへ移行しています。
詳しくはKIP-500で調べてみてください。
以下のコマンドを実行し、Zookeeperを起動させます。
$ ./bin/zookeeper-server-start.sh ./config/zookeeper.properties
Kafka
Kafkaが実行されているサーバ(Broker)をグループ化したものです。
以下コマンドを実行し、Kafkaサーバを起動させます。
$ ./bin/kafka-server-start.sh ./config/server.properties
Topic
メッセージを整理するためのカテゴリです。
今回はpersonal-dataと言うカテゴリを作成します。
以下コマンドを実行し、トピックの作成を行います。
$ ./bin/kafka-topics.sh --create --topic personal-data --bootstrap-server localhost:9092
PythonのFakerを使って取り込みフェイクデータの生成
Pythonのプログラム内でTopicのカテゴリ「personal-data」を設定し、kafkaのproducerへフェイクデータを送信するようにしています。
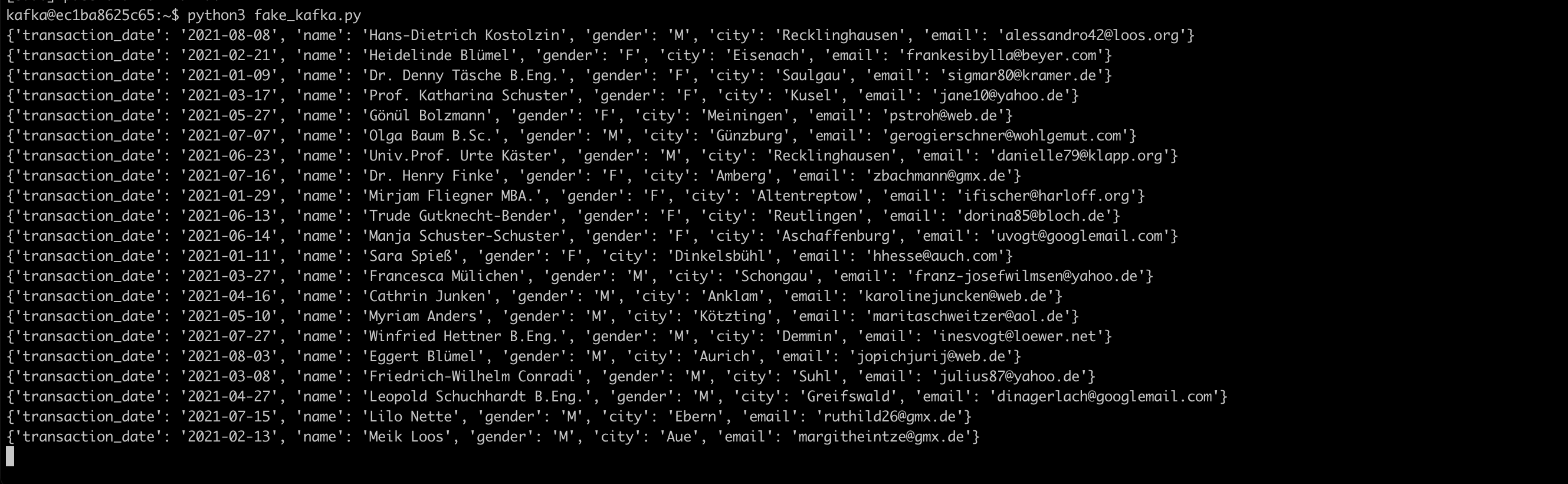
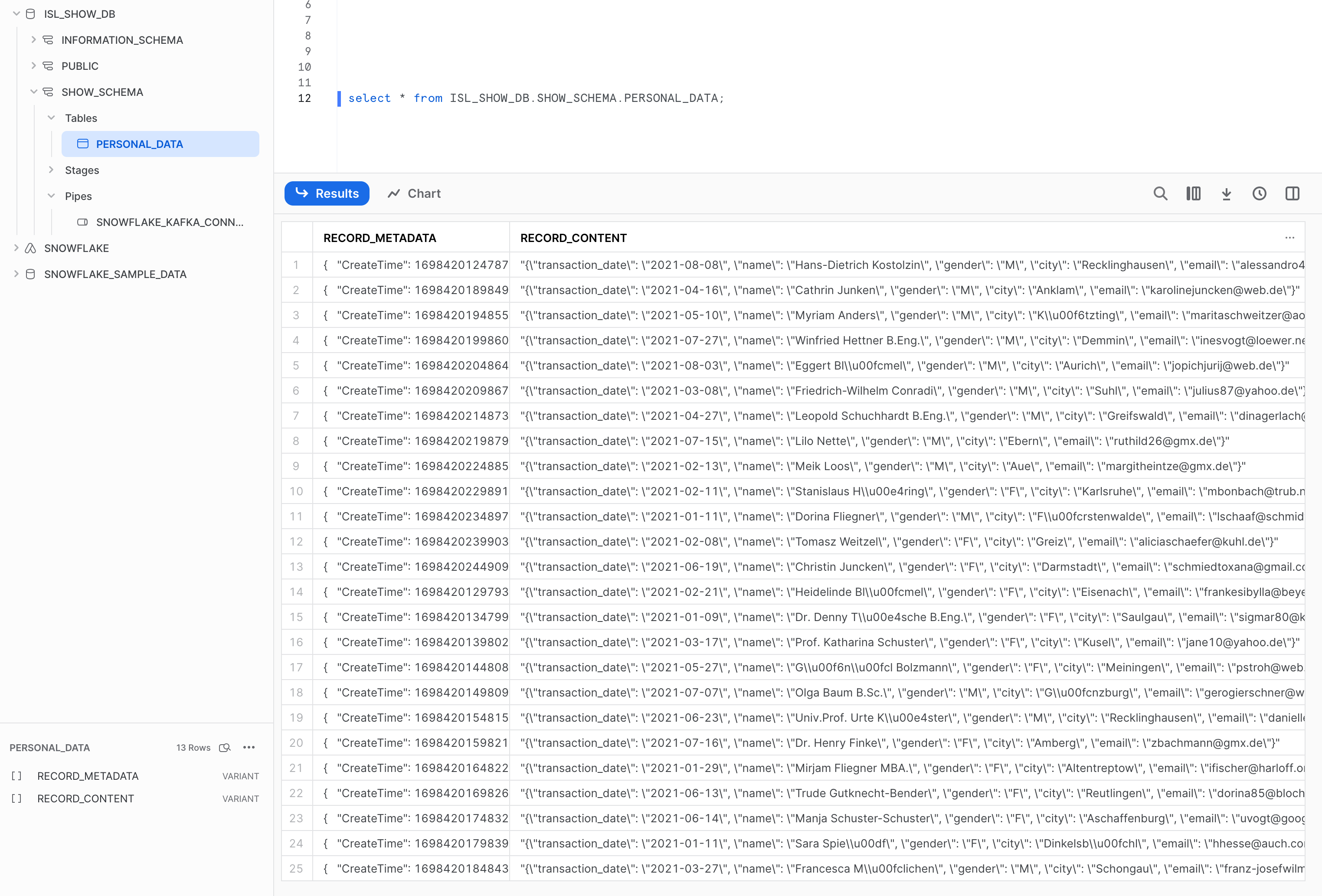
Snowflakeにデータが取り込まれることを確認
以下のとおり、Snowflake側でデータが取り込まれていることを確認できました。
最後に
Kafkaの嬉しいところ
kafkaの嬉しいポイントとしては、Pub/Subモデルを採用しているため、ストリーム処理が非同期で行われるところです。
サブスクライバー(データの送信側)はパブリッシャー(データの取得側)に直接接続する必要はありません。パブリッシャーはKafkaでメッセージをキューに入れて、サブスクライバーが後で受信できるようにします。このため一時的にサーバの負荷が高まったとしても、負荷が落ち着いた後にキューからデータを読み取ることが可能であり、データの取りこぼしが無いような設計とされています。
さらに23年7月のsnowflakeアップデートでSnowpipe Streaming + Kafka Connectorの連携が可能となりました。
これにより、Snowpipe Streamingを使用することでデフォルトで配信保証(データの重複や損失を防止)が設定されます。
kafkaのユースケース
- 複雑なシステムをサービス単位で分割運用し、さらに迅速な機能追加や不良修正が必要といった要件の場合にはkafkaがおすすめです。
kafkaはTopic単位でサービスを疎結合に管理することが可能なため、サービスの増減にも柔軟に対応が可能です。 - リアルタイムのストリーミング処理を行いたい場合はkafkaがおすすめです。
例えば、大規模なIoTサービスからの大量のログデータをストリーム処理させたい時などです。
Pub/Subモデルであるため、ログデータはキューで管理され、突発的な高負荷が発生してもログデータの取りこぼしが無いよう設計されています。
AWSのS3とSQSを組み合わせたストリーム処理も有名ですが、ぜひ一度Kafkaのストリーミング処理もお試しください。新たな扉が開かれることでしょう。
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。