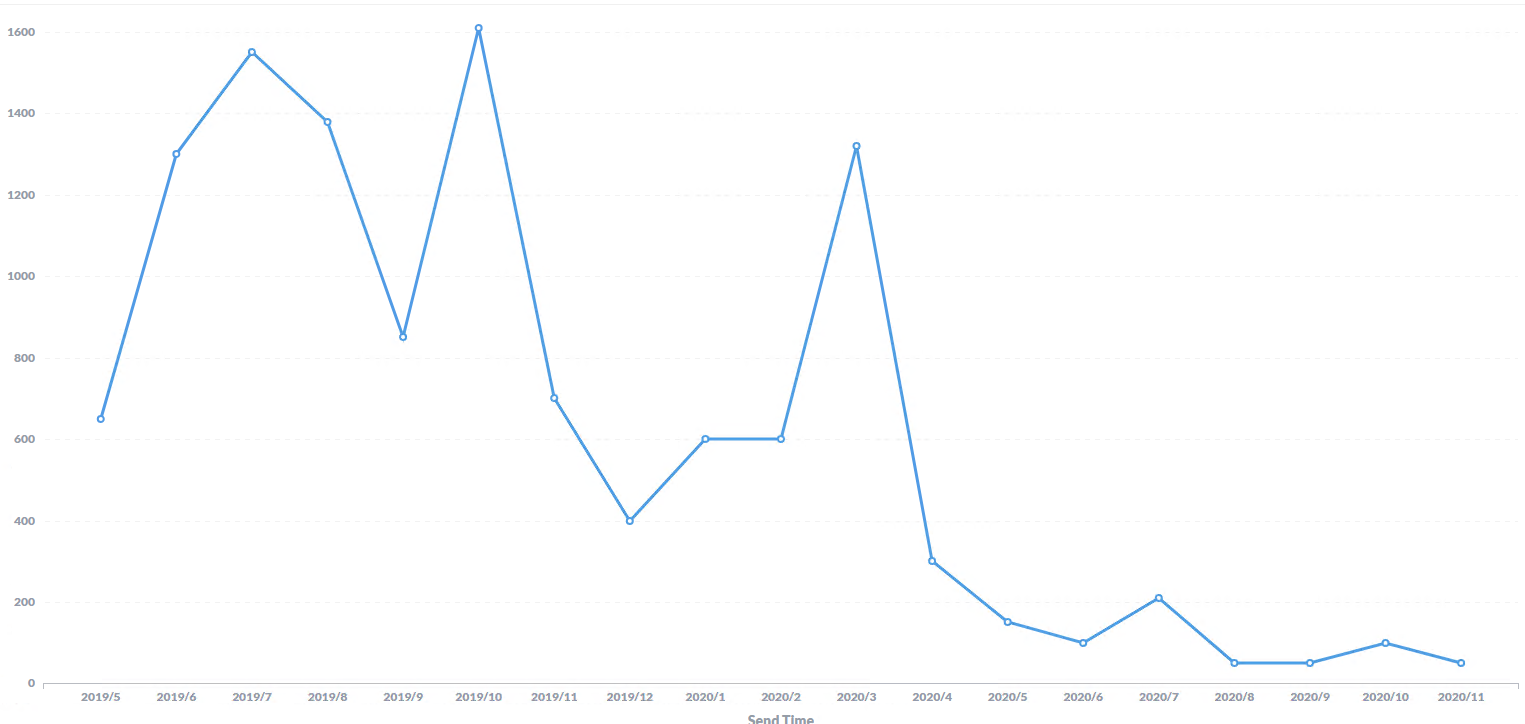
ここ最近「SnowflakeとTreasure Dataの違いを教えてほしい」
といった質問を頂くことが増えています。
どちらもクラウドDWH(データウェアハウス)や、
クラウドデータプラットフォームと呼ばれるように、競合するプロダクトですね。
クラウドのスケールメリットを活かしている点、
ユーザビリティの高いGUIが用意されている点など、共通点が多いです。
2011年に米国で日本人が創業し、
2013年から今日に至るまで日本国内での普及を着実に進めていったTreasure Data。
2012年に米国で元Oracle出身者が創業し、
グローバルでの評価を確固たるものとし、
満を持して2019年に日本法人を設立したSnowflake。
グローバルでの知名度は圧倒的にSnowflakeの方が高いのですが
日本国内での歴史はまだ浅く、
国内においてはTreasure Dataの方が知名度が高く、
導入企業も多いです。
ただし、
日本法人が設立されてから
Snowflakeの国内導入企業が一気に増えているため、
それに伴って両プロダクトの違いを気にする人が増えているのでしょう。
しかし、
SnowflakeとTreasure Dataを比較した記事って
調べても殆ど出てきません…。
比較したらヤバい人にヤバいことをされてしまうのでしょうか?
ということで今回は、
どちらも1~2年ほど使用経験のある私が、
経験を元に様々な観点から比較してみました!
アーキテクチャ
|
Snowflake |
|
|
Treasure Data |
|
Snowflake
特許取得済のマルチクラスタ共有データアーキテクチャを採用しており、
コンピュートリソースとストレージリソースが分離しています。
※コンピュートリソース = CPU、ストレージ リソース = HDD/SSDでイメージして下さい!
これによって複数のワークロードを完全に競合なく同時実行することができ、
コンピュートリソースの増強(スケールアップ/スケールアウト)も
ダウンタイムなしに行うことができます。
また、独自のマイクロパーティション技術によって、
パフォーマンス・チューニング(Treasure Dataにおけるtime列の指定、Redshiftにおけるソートキー/分散キーの指定など)をしなくとも高速な処理を実現できます。
クラスタリングキーを設定してパフォーマンス・チューニングすることも可能ですが、未設定状態でも速度的な問題は生じにくいです。
Treasure Data
Hadoopをベースに改良したMPPアーキテクチャを採用しており、
コンピュートリソースとストレージリソースが結合しています。
独自のカラムナーインデックス&タイムインデックス技術によって
素のHadoopよりは処理性能が高いです。
ただ、処理速度を上げるには
タイムインデックスを考慮したDB設計をする必要があり、
他のDBのように設計すると、パフォーマンスを発揮することが出来ません。
★タイムインデックスとは?
Treasure Dataにはインデックスが効くtimeカラム(unixtimeが格納されるカラム)が全テーブルに自動的に作られます。
→データを検索する際、このtime列を指定しないと全件検索になってしまい、処理速度低下に繋がります。
Treasure DataのバックエンドはAWS(EC2/S3/RDS等)で動いており、
これを活かしてダウンタイムなしにスケールアウトは可能なのですが、
Snowflakeのアーキテクチャと比較するとどうしても同時実行性能が劣ってしまいます。

【図の引用元】Hadoop-Vs-Snowflake
クエリ
|
Snowflake |
|
|
Treasure Data |
|
Snowflake
ANSI(米国規格協会)準拠の標準SQLを使用できるため、
SQL経験者であれば何不自由なくクエリを発行することができます。
さらに他のDBと互換性の高い関数を豊富にサポートしています。
よって、
他のDBから移行がしやすく、
再設計のコストを抑えることができるでしょう。
Treasure Data
クエリ発行時に2つのエンジンを選択することができ、
Prestoを選択したらPrestoSQL、
Hiveを選択したらHiveQL
と言われるSQLの派生言語を使用することになります。
ちなみにPrestoSQLはANSIに準拠しているため、
「じゃあ全部PrestoSQLで書けばいいじゃん」と思いがちですが、
そうはいきません。
各エンジンには向き不向きがあり、
アドホック処理ならPresto/バッチ処理ならHive…
といったように使い分ける必要があります。
また、
関数はTreasure Data独自のものが大半を占めるため、
他のDBからの移行は時間がかかるでしょう。
ちなみに、PrestoはSELECT句での相関サブクエリをサポートしており、
Snowflakeはサポートしていません。
他にもRedshift等、サポートしているDBは多いです。
よって、
SELECT句での相関サブクエリを含んだ処理を移行する必要がある場合は
SnowflakeよりもTreasure Data(Presto)の方が
再設計のコストを抑えることができるでしょう。
とはいっても実務上、SELECT句での相関サブクエリは頻繁に使われないため、あまり気にしないでも良いとは思いますが。
データ連携
|
Snowflake |
|
|
Treasure Data |
|
Snowflake
ストレージ統合を設定することで、
Amazon S3やGoogle Cloud Storageといった
オブジェクトストレージとシームレスに連携することができます。



オブジェクトストレージ以外のデータソース…
例えば他社製DWH(Redshift, BigQuery等)やSaaS(Salesforce, Google Analytics, Adobe Analytics等)のデータを直接連携することはできないため、
別途データ連携ツール(trocco, Talend, Matillion等)を用意する必要があります。
ちなみに、
Snowflake にはData Marketplaceというオープンデータ共有サービスが用意されているため、
オープンデータ(最近だとCovid-19の統計データ等)については
データ連携ツールの用意は不要でカジュアルに分析することができます。
Treasure Data
GUI上で設定できる豊富なデータ連携用コネクタが用意されています。
別途データ連携ツールを用意しないでも、
直接様々なデータソースに接続し、
データを取得することができます。
そのため、
自身が用意したデータをデータ連携ツール(ETLツール)を
使用しないで直接接続したい場合はTreasure Dataの方が向いています。

ワークフロー(データ処理の自動化)の定義
|
Snowflake |
|
| Treasure Data |
|
Snowflake
TASKを使用します。
SQLで記述するので習得難易度は低いですが、
GUIの管理画面が存在しない(※2021年5月現在)ため、
TASK数が増大すると運用が難しくなりがちです。
また、エラー通知機能がないため、
TASKのエラーを監視するには何らかの通知サービスと
連携する仕組みを実装する必要があります。
(例:Snowflakeのタスク失敗通知をAWSで実装してみた)
…正直、
SnowflakeはあまりTASKに頼らずにdbt等の外部ツールで
ワークフローを定義した方が
ハッピーワークフローライフを送ることができるでしょう。
あとDatadogがSnowflakeに対応しているので、
監視用に導入するのも良いかもしれません。
Treasure Data
DigDag(有名なOSSのワークフローエンジン)ベースのTreasure Workflowを使用します。
そのため、
DigDag経験者は経験を活かせるでしょう。
未経験者は若干覚えることが多いですが、
その分細かい設定が可能です。
また、Treasure WorkflowはGUIの管理画面が存在し、
エラー通知機能もあるため、
SnowflakeのTASKよりも運用面で優れていると言えるでしょう。
最後に
いかがでしたでしょうか。
「で、どっちがいいの?」と聞かれたら…弊社はSnowflakeのパートナーなので察して下さい^^
新規導入をご検討されている場合は、
長期的に見てコストを抑えられるSnowflakeがお勧めですが、
外部ツール(データ連携ツールや監視ツール等)も含めて最適な構成をご検討頂きたいと思います。
どうしても1つのプロダクトで完結させたい場合は、
Treasure Dataがお勧めです。
ワークフロー管理やエラー通知、
データ連携はもちろん、
Hivemallを使うと機械学習までTreasure Data内で完結することができるので。
他のDWHからの移行をご検討されている場合は、
SQLの互換性能が高い&費用対効果が高い(コスパが良い)Snowflakeをお勧めします!
Fivetran社のベンチマーク結果から見ても、
Amazon RedshiftやGoogle BigQueryと比較してももコスパが良いのは間違いないでしょう。
以上、「【禁断の比較?】SnowflakeとTreasure Dataを比べてみました」でした!
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。

-3.png)