本記事は、Snowflake Advent Calendar 2022 の 17 日目の記事になります。
はじめに
こんにちは。新卒入社し今年2年目を迎えました、utaです。
本記事は、Streamが必要になった背景・ユースケースと、Streamを使用したデータパイプライン構築例をシンプルにした形で紹介します。「Streamとは何か」、「Streamを用いたデータパイプラインをつくったことが無い」という方向けの内容になります。
Streamとは
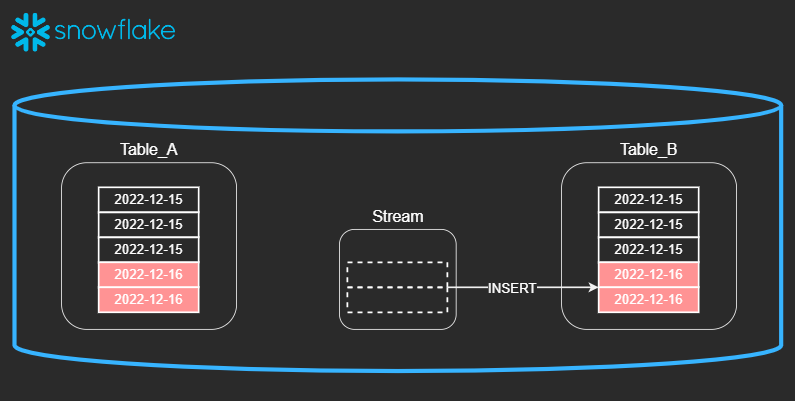
ストリームオブジェクトは、挿入、更新、削除などのテーブルに加えられたデータ操作言語(DML)の変更、および各変更に関するメタデータを記録し、変更されたデータを使用してアクションを実行できるようにします。このプロセスは、変更データキャプチャ(CDC)と呼ばれます。個々のテーブルストリームは、 ソーステーブル の行に加えられた変更を追跡します。テーブルストリーム(単に「ストリーム」とも呼ばれます)は、テーブル内の2つのトランザクションポイント間で行レベルで変更された内容の「変更テーブル」を利用可能にします。これにより、トランザクション形式で一連の変更記録をクエリおよび使用できます。
https://docs.snowflake.com/ja/user-guide/streams.html#change-tracking-using-table-streams
つまり、ソーステーブルに変更があると変更行の記録がStreamに格納され、データが格納されているようにみえます。
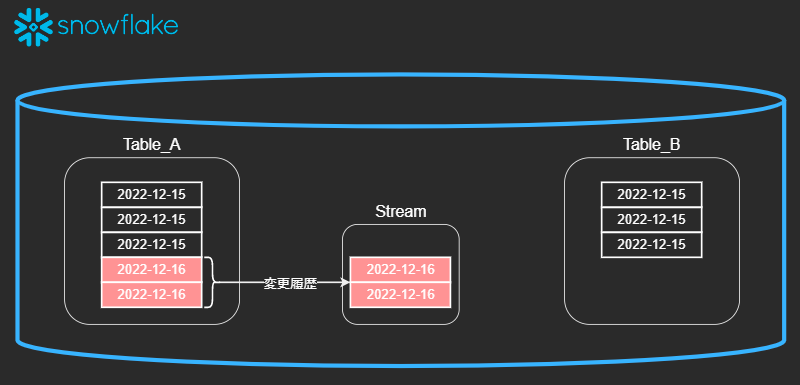
このStreamがINSERTなどで使用されると、消費されるような形でStreamから無くなります。
背景
入社後、未経験ながらデータプレパレーション部に配属され、SQLServerからSnowflakeへのDWH移行プロジェクトにアサインされました。
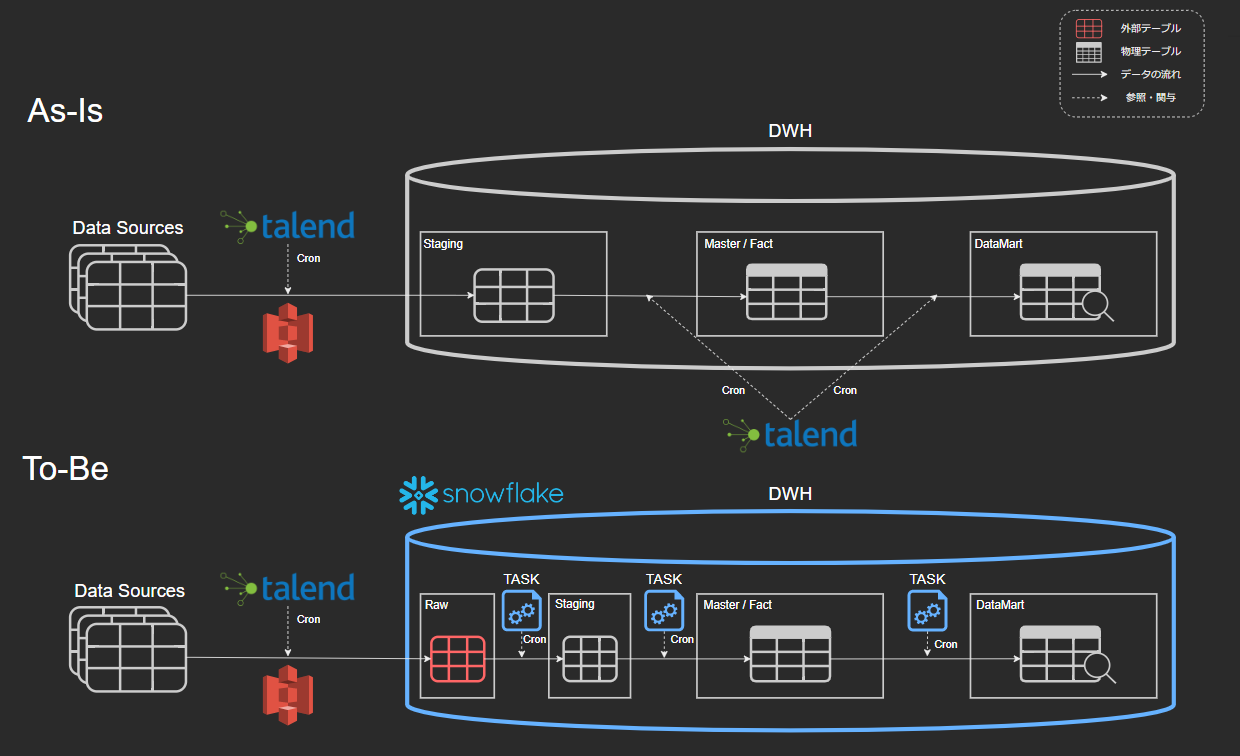
移行の概要としては、TalendによるETL処理を行っていた旧データ分析基盤をSnowflakeにしTalendでEL、SnowflakeのTASKでTを行うELT処理にリプレイスするというものです。
- データ取得(Talend)
- [Raw] 外部テーブル更新
- [Staging] 外部テーブルを実テーブル化(Task)
- [Master/Fact] 生データを構造化(Task)
- [DataMart]分析用の集計(Task)
※見慣れない方もいるかと思うので、外部テーブルについてはこちらを参考にしてください。
最初はデータやSQLに慣れるため、ひたすら数値検証に明け暮れていましたが、2年目を迎え、初めて「データ収集からデータマート作成までを行う」というデータパイプライン構築作業を任されました。
しかし、旧データ分析基盤のCronに依存したデータパイプラインをそのまま移行したことと、特殊なデータソースだったことが起因して、従来のCRON管理によるデータパイプラインでは対応することができませんでした。
ユースケース
午前6時~7時の間にSFTPサーバ上に、csvファイルを圧縮したzipファイルが配置され、そのファイルデータを用いてデータマートまで作成するというパイプラインが必要になりました。
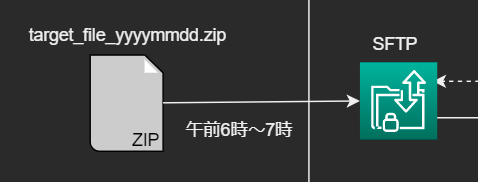
zipファイル自体の大きさが約2~3GBで解凍すると十数GBにもなるcsvファイルなのですが、運用していくと日に日にデータサイズが大きくなるデータだということが分かりました。
最近では午前8時になってもファイル配置が完了せず、S3への配置が遅れるようになり、最も配置が遅かった時刻+バッファでCRONを設定していたことで追い越し事故も頻発しました。
- SFTPサーバへのファイル配置完了前にジョブ実行(ジョブの追い越し)
- S3へのファイル配置前にタスク実行(タスクの追い越し)
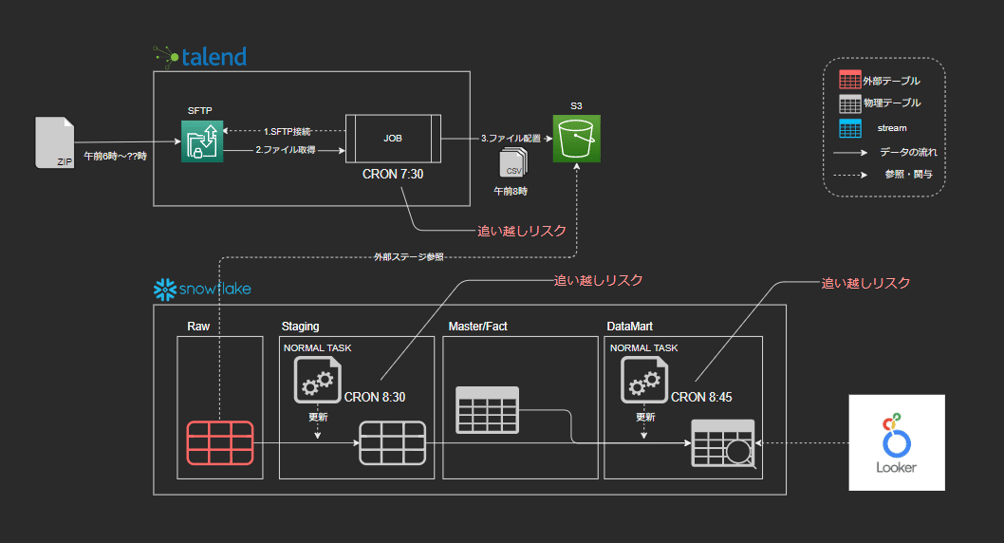
そこで、Talendジョブ側でファイルが配置されていなかったら一定時間待機。再度取得を試みてファイルが見つかったら、ファイルを解凍・分割しS3へ連携するという形に変更しました。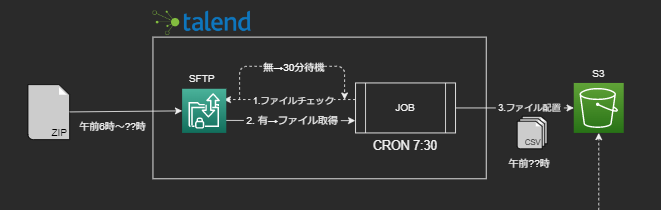
ここまではTalendの強みを活かしてなんとか解決できたのですが、一番頭を悩ませたのはSnowflake内のタスク構成です。
先に話した通りSnowflake内のタスクは、層ごとにCRONで管理されていたため、いつS3に配置されるか分からないデータのパイプラインをCRONで管理することは不可能でした。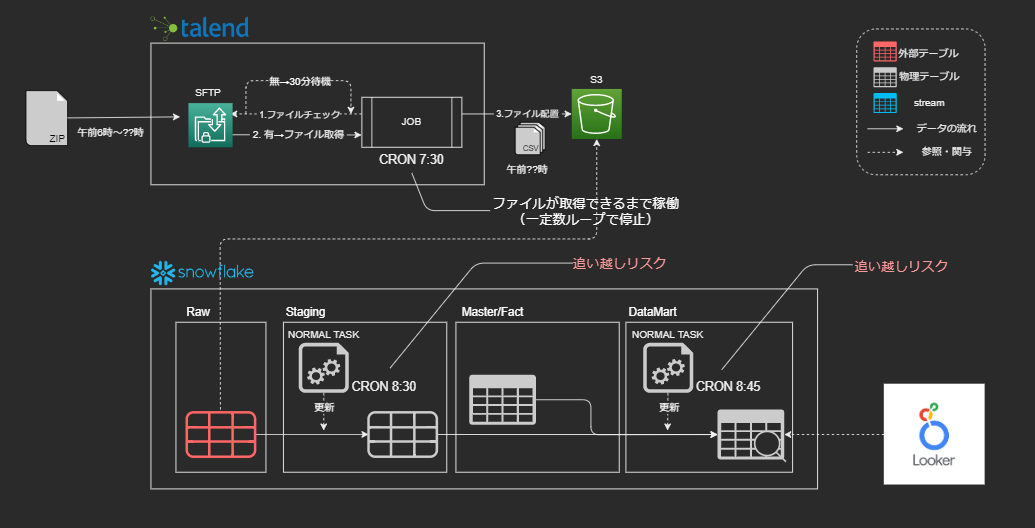
その問題を解決するため辿り着いたのが、SnowflakeのStream機能です。
完成したデータパイプライン
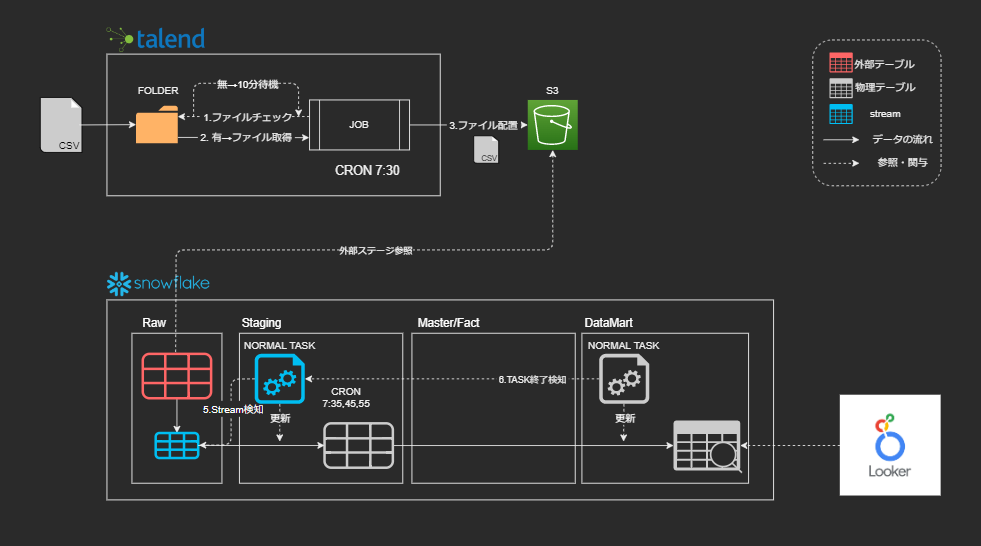
現在、運用しているデータパイプライン構成は以下のようになりました。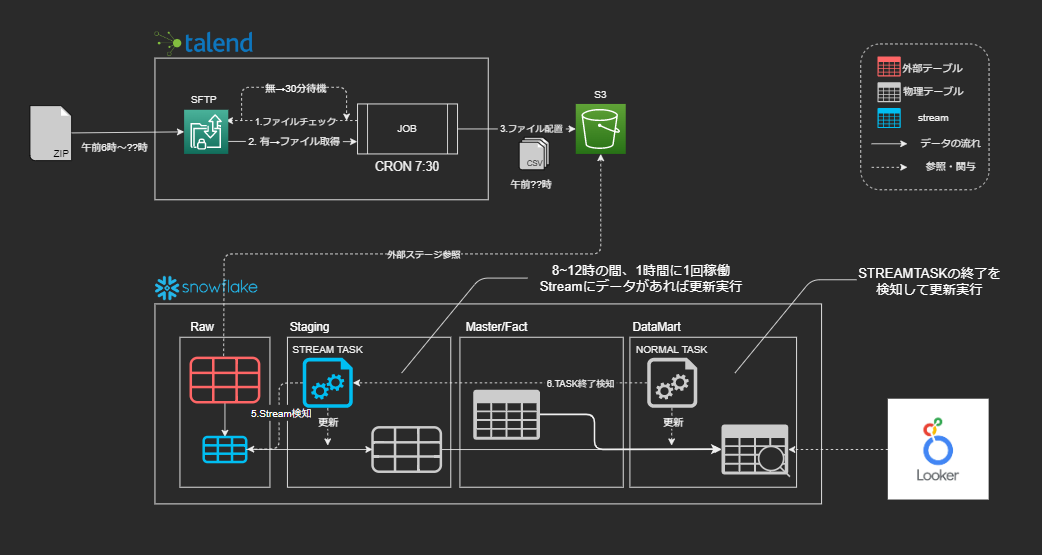
- データ取得(Talend)
- 外部テーブル更新 + Streamが更新レコードをキャプチャ
- Streamデータで実テーブルをMerge更新(STREAM TASK)
- StreamにデータがあればEXECUTE
- StreamにデータがなければSKIPPED
- 分析用の集計テーブルを更新(AFTER TASK)
- 3がEXECUTEされたらEXECUTE
- 3がSKIPPEDされたらスルー
これで、データソースがいつ更新されても、データマート作成までの一連の流れが止まることはなくなりました。Streamを使用したタスクで改善されたことは以下の点です。
- 先行処理のCRONを考慮する必要がなくなった
- 仮にファイル配置が午後になった場合もSTREAMTASKを手動実行するだけでよくなった
実装例
お見せできないデータがあることと、少し複雑に見えてしまう部分があるため、サンプルデータを用いてシンプルな形で再現した例をもとに紹介します。
■ データソース
前日の売上データファイルが任意のタイミングでフォルダに配置。
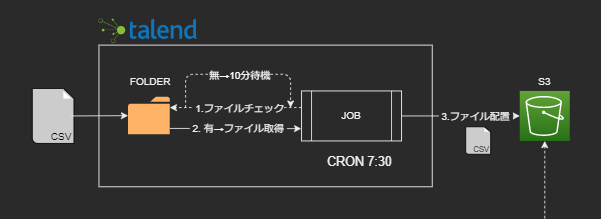
■ データパイプライン
■ 処理の流れ
1. データ取得(Talend)
フォルダ内にターゲットとなる日付(2022-11-25)のファイルが見つかるまでループし、S3配置まで行う。
(実際は無限ループを避けるため、一定数ループしたらエラー終了しています)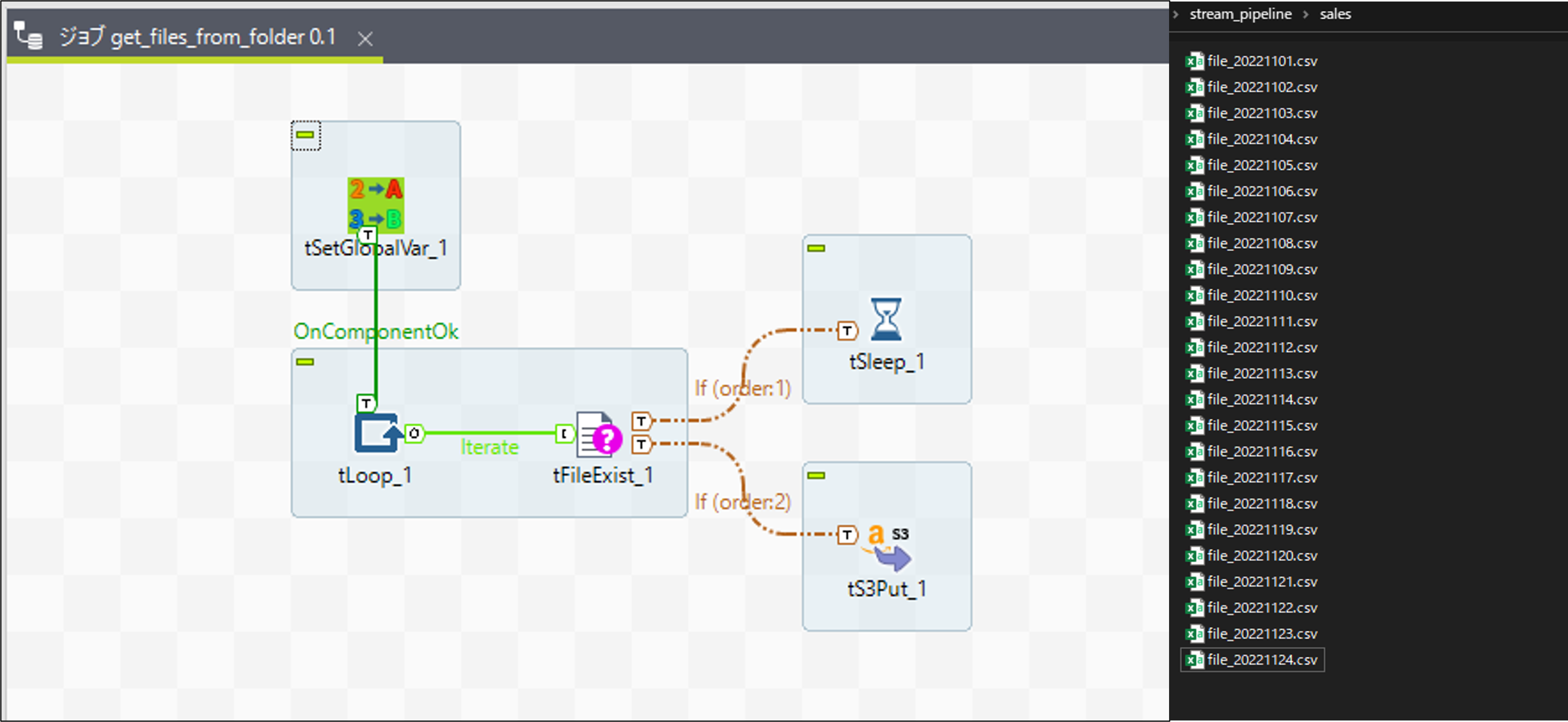
2. 外部テーブル更新(自動)
SQSを使用することでSnowpipeのようにS3イベントを検知して外部テーブルを自動リフレッシュすることができます。
https://docs.snowflake.com/ja/user-guide/tables-external-s3.html
3. Stream生成
外部テーブルをターゲットとしたStreamを作成します。
※外部テーブルの場合、INSERT_ONLY = TRUE が必須
4. 外部テーブルから実テーブルにINSERT(Task)
SYSTEM$STREAM_HAS_DATAをWHENで指定することで、ストリームにレコードが含まれているときのみ実行するよう制御することができます。
https://docs.snowflake.com/ja/sql-reference/functions/system_stream_has_data.html
5. 分析用の集計(Task)
SHOPIDを3分割して、AREAごとの日別売上を集計するテーブルを作成します。
データパイプライン実行
7:30 TALENDジョブによる1回目の取得
実行日(2022-11-25)のファイルが未配置のため、tSleepで10分待機します。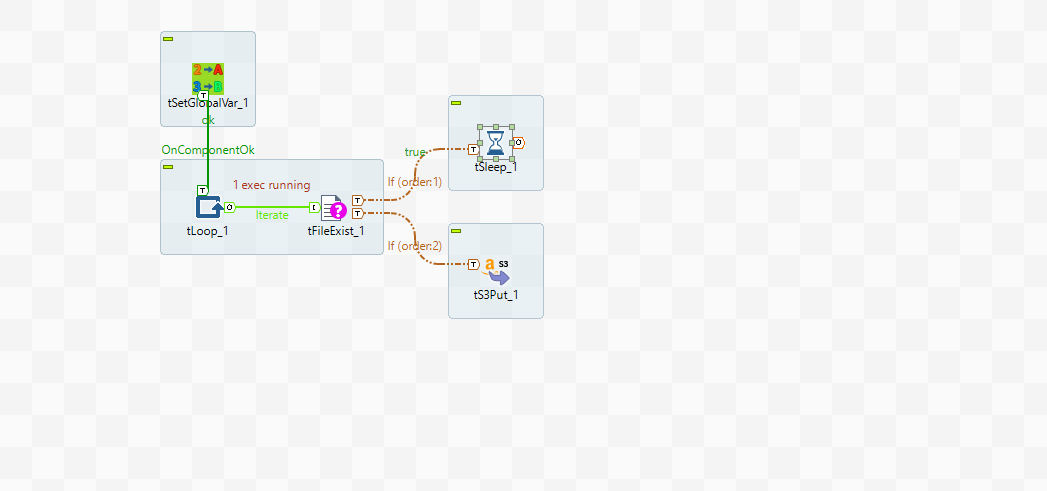
7:35 1回目のSTREAM_TASKが起動
外部テーブルの更新(S3の状態に変化)がなく、StreamにデータがないためSTREAM_TASKはスキップされます。
TASK_Aがスキップされた場合、AFTER_TASKは実行されません。
その後、フォルダに実行日のファイルを配置します。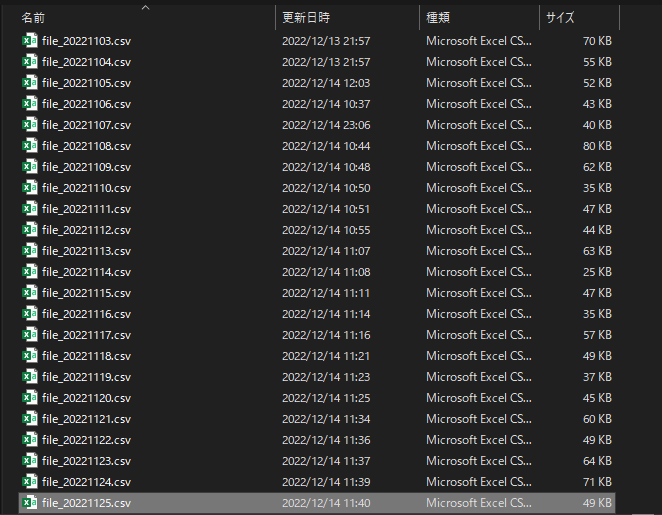
7:40 TALENDジョブによる2回目の取得
実行日のファイルが見つかったため、S3PutでファイルがS3に配置され、ジョブは終了します。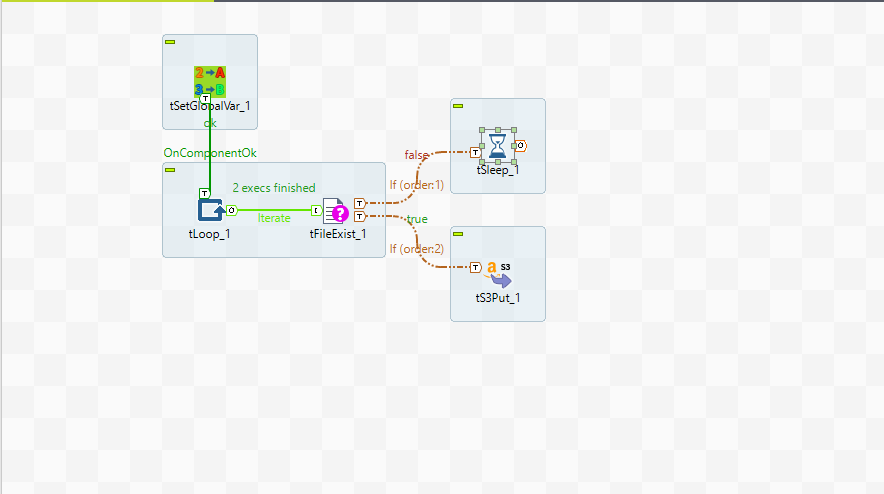
すると、SQSを通じて外部テーブルがS3の更新を検知し、自動リフレッシュされます。
Streamが外部テーブルの更新を検知し、Streamでは変更分のデータが格納されます。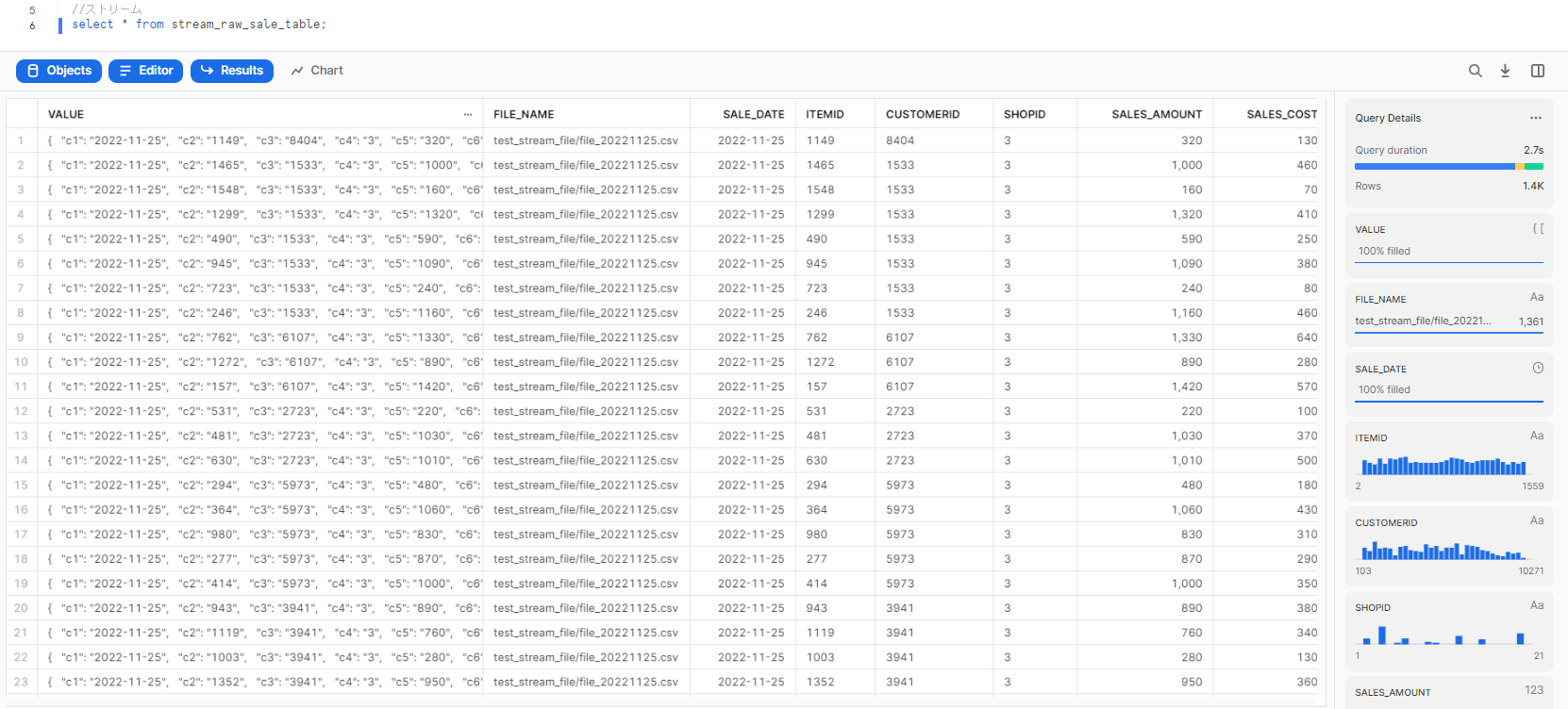
7:45 2回目のSTREAM_TASKが起動・実行
Streamがデータを所持しているため、STREAM_TASKが実行されます。
外部テーブルの更新データが実テーブルにINSERTされます。
7:46 AFTER_TASKが実行
2回目のSTREAM_TASKの実行完了をトリガーとしてAFTER_TASKが実行されます。
※分かりやすさのため+1分しています。
分析用テーブルが更新されています。
7:50
ジョブは終了しているため、次のCronまで何も起こりません。
7:55 3回目のSTREAM_TASKが起動
2回目のSTREAM_TASKのINSERTでStreamは消費されたため、変更記録は消えています。

外部テーブルの更新(S3の状態に変化)がなく、StreamにデータがないためSTREAM_TASKはスキップされます。

まとめ
当初のCron依存のデータパイプラインは、追い越しや追い抜きのリスクを抱えていましたが、Streamを使用したパイプラインでは、それらのリスクは限りなく0に近くなりました。
Cron管理によるデータパイプラインに限界を感じている方は、一度Streamを試してみてはいかかでしょうか。
今後について
データパイプラインを一から構築してみて、データソース側のデータライフサイクルを確実に理解し、それに寄せたパイプライン構成を考えることが非常に重要だと痛感しました。
また、障害発生時にリランしやすいデータパイプライン設計など、まだまだ考えることはたくさんあるので、どんどん経験を積んでデータエンジニアリング力を高めていきたいです。
おまけ
Dynamic Tablesとは
Dynamic Tablesは、Snowflakeの新しいテーブルタイプで、シンプルなSQLステートメントを使って、データパイプラインの結果を宣言的に定義することができます。Dynamic Tablesは、データの変更に応じて自動的に更新され、最後に更新された時点以降の新しい変更に対してのみ動作します。これを実現するために必要なスケジューリングとオーケストレーションも、Snowflakeによって透過的に管理されます。
(とある翻訳ツールより)
https://www.snowflake.com/blog/dynamic-tables-delivering-declarative-streaming-data-pipelines/
本記事でStreamから変更データ抽出しTaskを用いて後続を更新していましたが、Dynamic Tablesで作られたテーブルはStreamとTaskを介さず同様の更新処理が自動的に行われます。
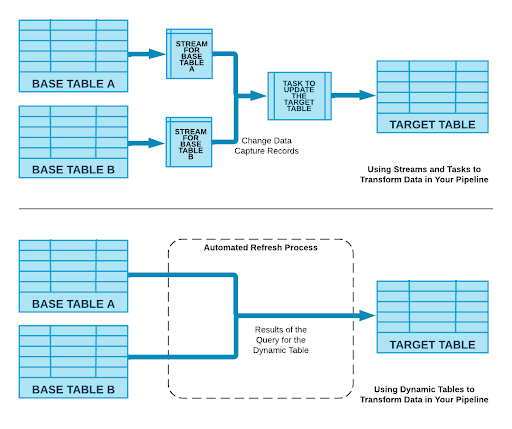 画像は記事より引用
画像は記事より引用
つまり、Dynamic TablesがGAされたらStream×Taskは不要!
...とはならず、オブジェクトの用途によって使い分けが必要とされています。
- マテリアライズドビュー
- クエリの書き換えが頻繁に行われる場合
- 外部テーブルの高速化など
- Dynamic Tables
- テーブルリフレッシュをより細かく行うなど
- Stream×Task
- 依存関係の管理を柔軟に行いたい
- UDF/UDTF、ストアドプロシージャ、外部関数を使用する場合など
現時点ではまだprivate previewみたいなので、触れるようになったらいろいろ試してみたいですね。
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。