


本記事はSnowflake Advent Calendar 2020の13日目の記事となります。
外部テーブルの紹介
外部テーブル(EXTERNAL TABLE)とは、オブジェクトストレージサービスに配置したデータをSnowflakeから直接参照可能にするテーブルのことです。
現在外部テーブルとして連携・利用できるストレージサービスは下記です。
- Amazon S3

- Google Cloud Storage

- Microsoft Azure Blob Storage

実態は、ファイルをPARSEしたJSONオブジェクトをテーブルとして表示しています。
データレイクとして扱っている各ストレージサービスをそのままDWHのように扱えるため連携コスト・それに準じた運用コストなどが抑えられると考えています。
更に詳しい仕様や利用例などは、Snowflakeの公式ドキュメントを合わせて参考になさって下さい。
やってみたこと
今回は表題の通り、Amazon S3に配置したTSVファイルをSnowflake上でテーブルとして定義し、実際にクエリを叩いて使えるのかどうかを検証してみました。
途中でいくつかつまずくこともあるので、そういった部分も振り返りながら解説していきたいと思います。
前提環境
まず、前提条件として作成しなければならないものが下記のようにあります。
- Amazon S3へのストレージ統合
- 接続・認証設定のようなものです。
- 対象BucketのAmazon リソースネーム (ARN)が必要になります。
- Amazon S3への外部ステージ
- 接続後のロードやアンロードに関する更に細かい仕様を設定するものです。
- この設定でS3のBucketが参照できるようになります。
外部テーブルの定義(本題)
統合とステージの作成後、ようやく外部テーブルの定義です。
Amazon S3の状態
先ずはAmazon S3側の説明です。
下記の様なTSVファイルがGZIP形式で、Amazon S3にアップロードされています。
※1行目は、ヘッダーです。
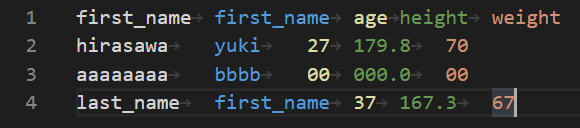
こちらがAmazon S3側です

[BUCKET_NAME]/SAMPLE/[yyyymmdd]/[yyyymmdd].tsv.gz のような形式で格納しています。
最初の[yyyymmdd]は実行日で最後の[yyyymmdd]は、データの断面と想定してアップロードしています。
※Amazon S3へ連携したツールは、TalendやTroccoなどのETL/ELTツールです。
CREATE EXTERNAL TABLEの実施
ソースコードの全体像を以下に記載します。
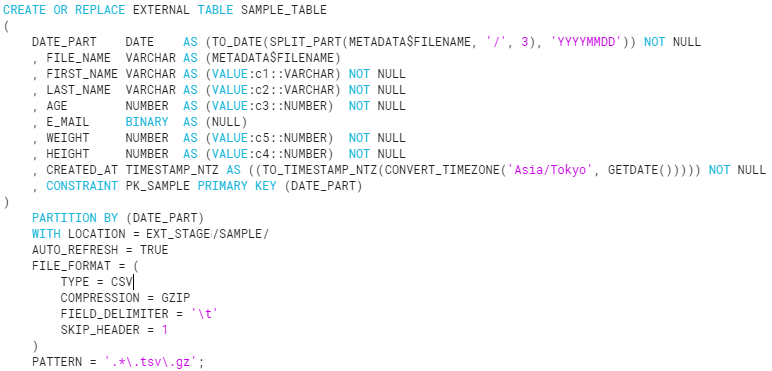
上記を実行してテーブルが作成されたことを確認します。

できてます。
外部テーブルの構文は以下に大別されると考えています。
- テーブル定義
- ファイル読み込み定義
テーブル定義の説明
まずはテーブルの定義から。- 構文
<col_name> <col_type> AS <expr> <inlineConstraint> - 例
FIRST_NAME VARCHAR AS (VALUE:c1::VARCHAR) NOT NULL
※Constraintで「Default」を設定することはできません。
上記のE_MAIL列のように("hoge")と指定すれば実質「Default」値となります。
基本的に「VALUE」というカラムにJSONオブジェクト形式でファイルの値が格納されていますのでそちらから定義を作成します。
上記の例では、「VALUE」に格納されているのKeyの「c1」を指定して「VARCHAR」で型定義した上で「FIRST_NAME」という外部テーブル上のカラム名を定義しています。
「VALUE」列に一体どのように格納されているのか例を下記に示します。
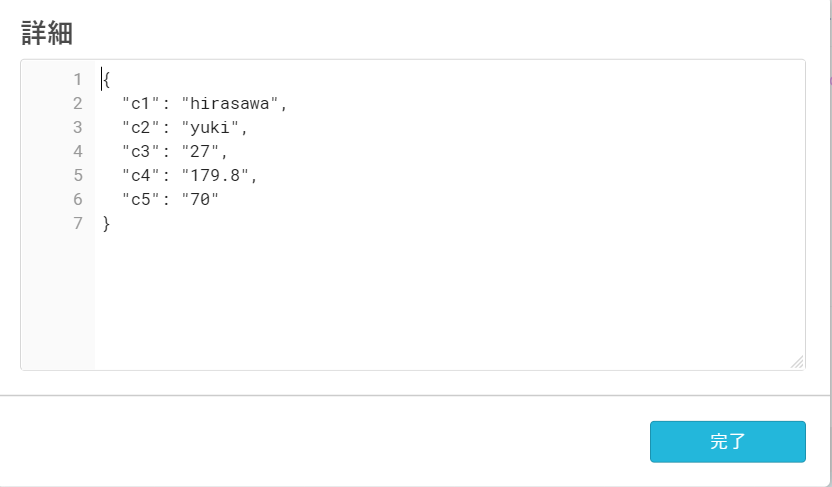
「{"Key" : "Value"}」の紛うことなきJSON形式です。
因みにTSVファイル中の値を二重引用符・カンマ("")で括ることはあまりおすすめしません。
括った場合、読み込む際に必ずVARCHARにしないとエラーになるのでテーブル定義によってはNUMBERでテーブル定義しているのに読み込みはVARCHARで型変換しないといけなくて…。といったように型変換が大量に発生するケースがあります。
どうしても文字列に\t(タブ)や\n(改行)が入るのでエスケープするために二重引用符・カンマ("")が必要な場合は、その列だけ、あるいはそれらの特殊文字列を置換することをおすすめします。
そして列定義時に「METADATA$FILENAME」で読み込んでいるファイルパスをメタ情報として取得できます。
これが便利で「[BUCKET_NAME]/SAMPLE/[yyyymmdd]/[yyyymmdd].tsv.gz」が丸々入っているためパーティション情報として利用できます。
ファイル読み込み定義の説明
次にファイル読み込み系の定義です。
- PARTITION BY (DATE_PART)
- パーティション設定です。設定後、WHERE句にカラムを含めることでクエリ時の負荷が下がります。
- WITH LOCATION = @EXT_STAGE/SAMPLE/
- S3のキープレフィックスを予め指定できます。
- AUTO_REFRESH = TRUE
- 本来はS3にファイルが置かれた場合に、「ALTER EXTERNAL TABLE TABLE_NAME REFRESH;」しないと外部テーブルで表示されなかったりするのですが、ちょっとよくわかっていません。すみません…。
- FILE_FORMAT = (
TYPE = CSV
COMPRESSION = GZIP
FIELD_DELIMITER = '\t'
SKIP_HEADER = 1
)- ファイルフォーマットです、「CREATE FILE FORMAT」で作成頂いたものも利用できます。
- PATTERN = '.*\.tsv\.gz';
- 読み込むファイルを正規表現で指定できます。
- 同じキープレフィックスの中で複数の拡張子がある場合は、こちらで目的のファイルだけ取ってこれるようにします。
外部テーブル定義の確認(結果)
少し説明が長くなりましたがいよいよデータをSnowflakeから見てみます。
SELECTした結果がこちら↓
(右半分:実態であるVALUE列~メタデータまで)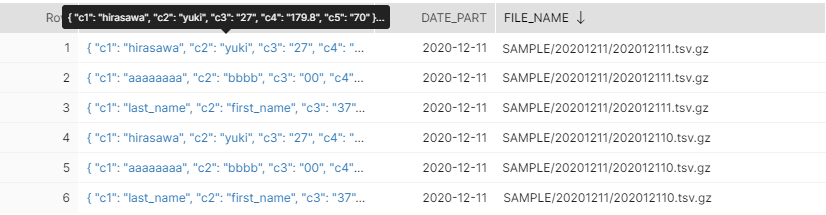
(左半分:VALUE列をもとに定義した仮想列)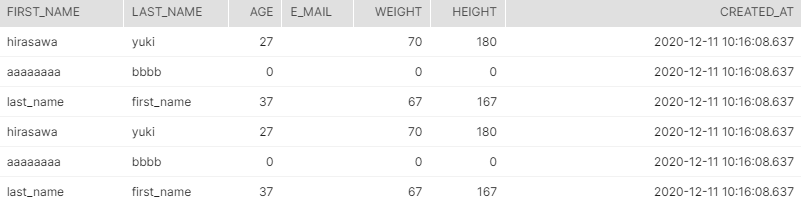
JSONでデータプレビューでカラム名が見えませんが、「VALUE」列が実態で、その他が外部テーブル定義で定義された通りの仮想列になっています。
利用してみた所感としては、やはり日付でのパーティションが組めるところが運用観点から見ても有用だと考えています。数百万件程度のクエリでも少し重くなる傾向にありますが、パーティションで日付を指定するとクエリの応答速度は早くなります。
ETL/ELTツールやSnowflakeのCOPYタスクを作成しなくても良いケースがありますので、実質的な障害点を減らすことができるとも考えています。
要検証点(今後のアクション)
TSVファイルを外部テーブル化して利用してみましたが、自動的に「c1~c〇〇」のようにVALUE列のKeyが生成されると下記の運用を想定した場合に大変そうです。
- 外部テーブル化した後、TSVファイル側でカラムの追加/削除が発生した場合
そもそも設計がおかしかったりするのかもしれませんが、TSVのファイル内で400カラム「c1~c400」を定義していたと想定し、運用中のスキーム変更で201番目にカラムが追加された場合に「c201~c401」の定義を変えたりする必要が出てきそうです。都度対応するのは少々大変そうです。
別のファイルフォーマット(JSON, PARQUET, ORC)ではどうなるのかを検証するのはいい手かもしれないと考えているので今後試してみたいところです。
最後に
今回は外部テーブルを定義してS3→Snowflakeでストレージからテーブルを定義してみました。
今後、Google Cloud StorageやAzure Blob Storageなどの他のストレージサービスやPARQUETやORCなどの実運用を想定したカラムナフォーマットに対して外部テーブル定義をしてみたいと考えています。
少々文字が多くなり見にくくなってしまったかもしれませんが、
ここまで見て頂きありがとうございます。
以上「【データ連携】外部テーブルを定義してAmazon S3にあるファイルをSnowflakeでテーブルライクに扱ってみた」でした!
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。




