dbtとは
dbt (data build tool) は、データパイプラインを構築するためのツールです。データの前処理(ELT)におけるTransform(変換)を担当し、SELECT文を記述するだけでデータウェアハウス内のデータをできます。
公式リンク:https://www.getdbt.com/
dbtでできること
-
DWH(今回はSnowflake)上にテーブル・ビューの作成
-
作成するテーブルのタイプを指定して作成
-
テーブル作成時のスキーマの指定
-
作成したモデル(dbt上に作成したSELECTステートメント)のテスト
-
定期実行するためのデプロイ環境の作成
-
DWH上に作成したテーブルの増分更新
実践
- Snowflakeとdbtを接続する
-
Snowflake上にテーブルを作成する
-
テーブルのタイプを指定して作成する
-
スキーマの指定してテーブル作成する
-
モデルをテストする
- 定期実行するためのデプロイ環境を作成する
-
Snowflake上に作成したテーブルの増分更新
Snowflake上にテーブルを作成する
Snowflakeとdbtの接続方法についてはこちらのページにて解説しています。
参考
Snowflake上にテーブルを作成する
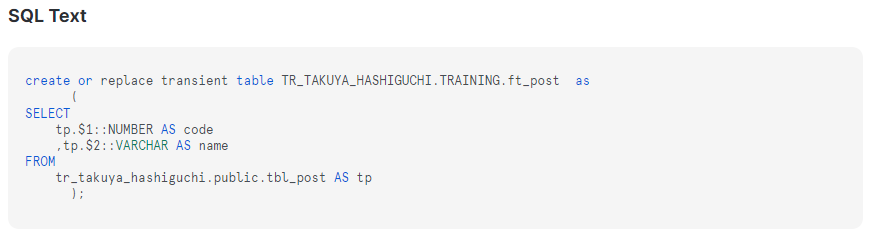
dbtはSELECT文を記述したSQLファイル(モデル)を実行することで、DWH上にテーブルを作成できます。
今回はSnowflake内に配置した以下のCSVデータからテーブルを作成します。
models配下にフォルダとファイルを作成して、以下のように記述します。
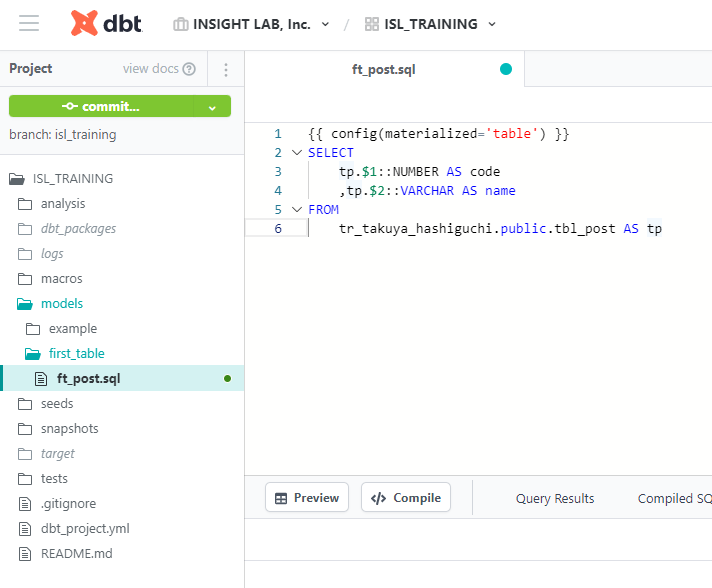
記述したら画面右上の [save] をクリックし、画面右下に "Ready" と表示されれば実行可能です。
実行には画面下の入力スペースに "dbt run" と入力して、[Enter] をクリックします。
(特定のファイルのみ実行する場合、"dbt run --select ファイル名"(拡張子は不要)と入力します。)
以下のように表示されれば実行は完了です。
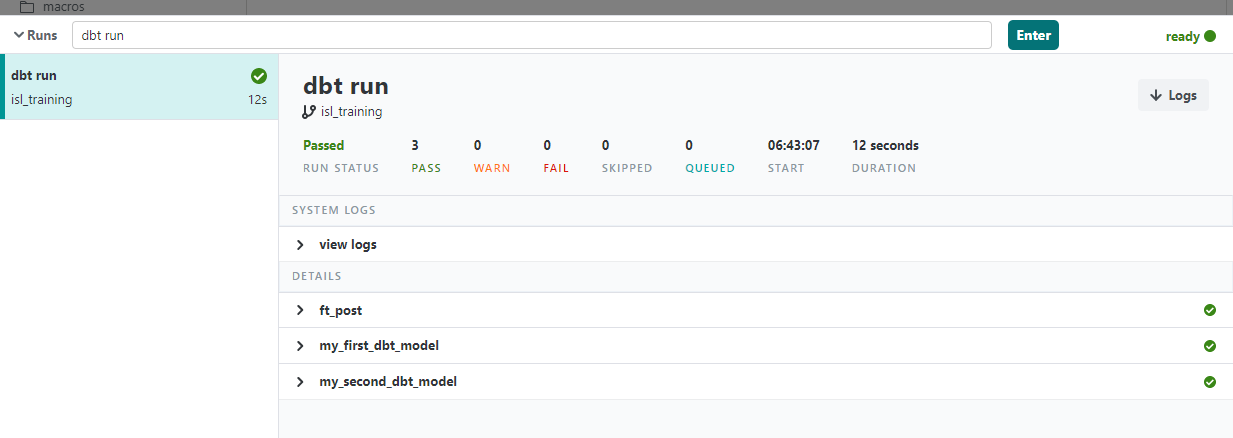
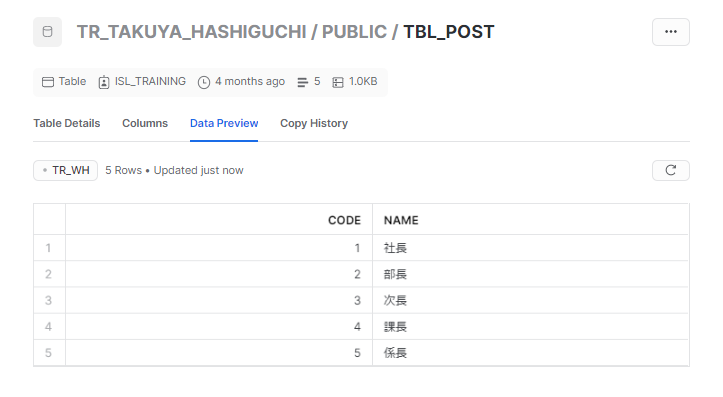
Snowflake側を確認すると、テーブルが作成されていることが分かります。
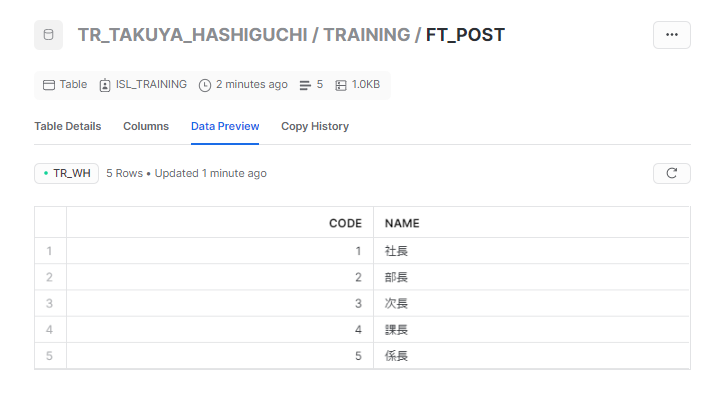
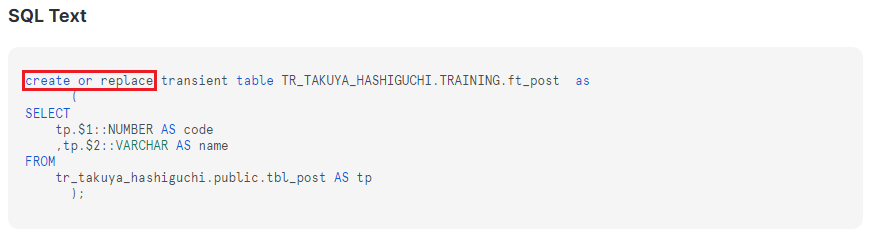
テーブルはSnowflakeとdbtの接続時に設定したスキーマ上に、dbt側のSQLファイルの名前で作成されます。
また、dbt側で実行したのはSELECT文でしたが、Snowflake側では "create or replace" として処理されていることが分かります。
また、dbt内にCSVファイルを作成して、DWH上にテーブルを作成することもできます。CSVファイルはdbtのseedsフォルダ内に作成します。
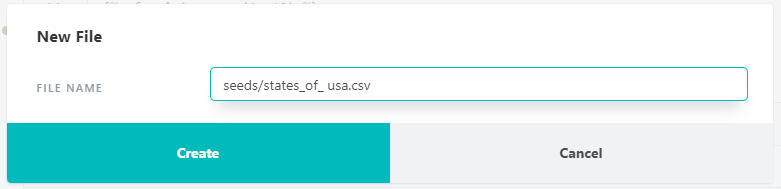
アメリカの州のコード、州名を記述したファイルを作成しました。seeds内のファイルの実行は、"dbt seed" コマンドで実行します。
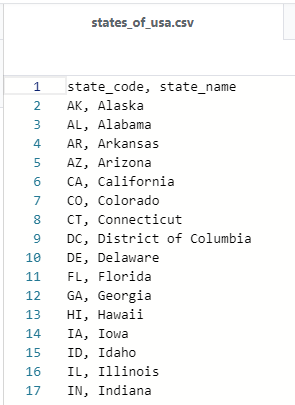
実行後Snowflake側を確認すると、作成した「states_of_usa」のテーブルができていることが分かります。
注意として、dbtのシード機能を使用したCSVファイルのロードは、大容量データに対してパフォーマンスが低いので、ファイルが大きい場合は他ツールからDWHにロードをすることが推奨されています。
参考
テーブルのタイプを指定して作成する
Snowflakeにはテーブルのタイプとして「Temporary(仮)」「Transient(一時)」「Permanent(永続)」の3種類があり、dbtでモデルを実行する際、デフォルトではすべてTransientテーブルとして作成されます。
- Transientテーブルの特徴
- 明示的に削除するまで持続する
-
タイムトラベルは最大1日まで(Enterpriseプランでも)
-
フェイルセーフ期間がない
各テーブルタイプの詳細についてはこちらを参照:
上記のような特徴があるため、タイムトラベルの期間を一定期間設けたい場合、dbt側で設定が必要になります。先ほど作成したテーブル「ft_post」を確認してみると・・・
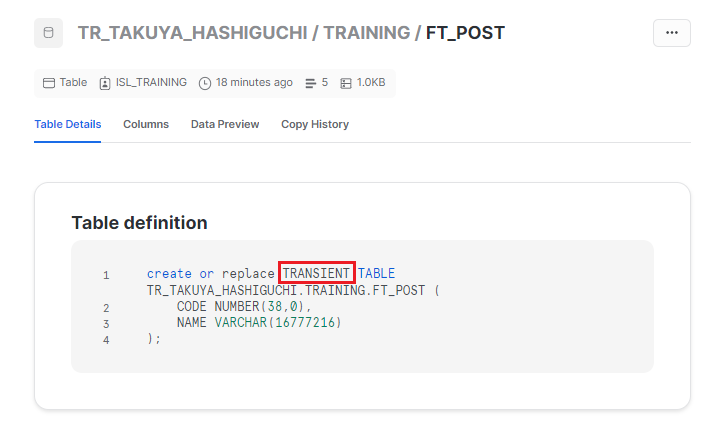
コード内に "TRANSIENT" とあり、Transientテーブルとして作成されていることが分かります。
【テーブルタイプの設定方法】
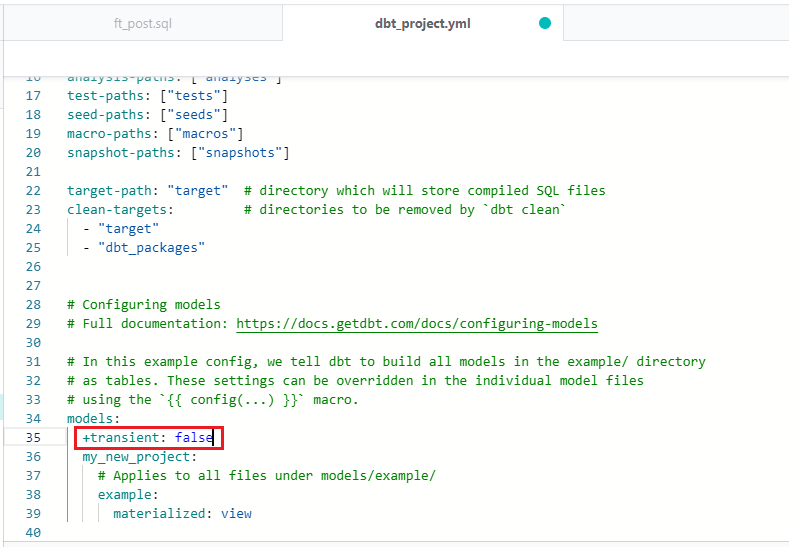
プロジェクト全体に適用させるには、「dbt_project.yml」ファイルを編集します。
「dbt_project.yml」を開き、以下の場所に "+transient: false" と記述すれば完了です。
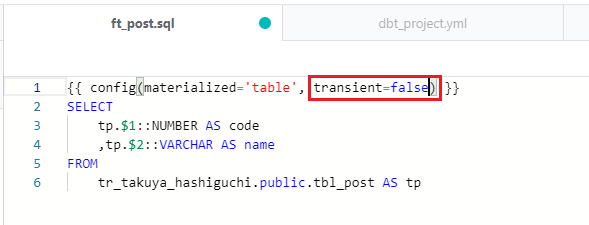
モデルごとに適用させるには、各モデルの "config" を編集します。テーブルタイプを変更したいモデルを開き、以下のように "transient=false" と記述すれば完了です。
設定後に実行した結果を見てみると・・・
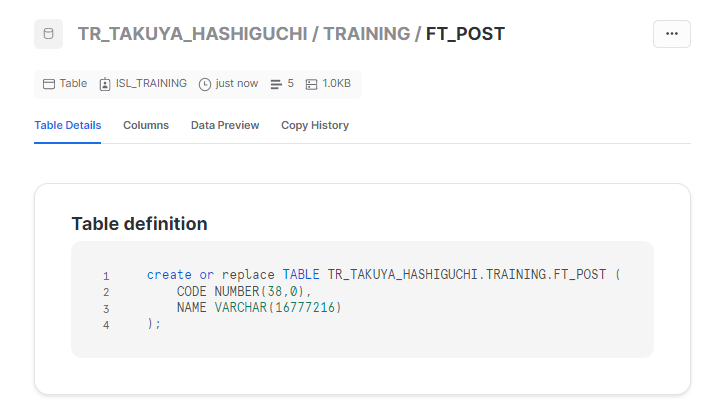
"TRANSIENT" という表記がなくなりました。
参考
スキーマを指定してテーブル作成する
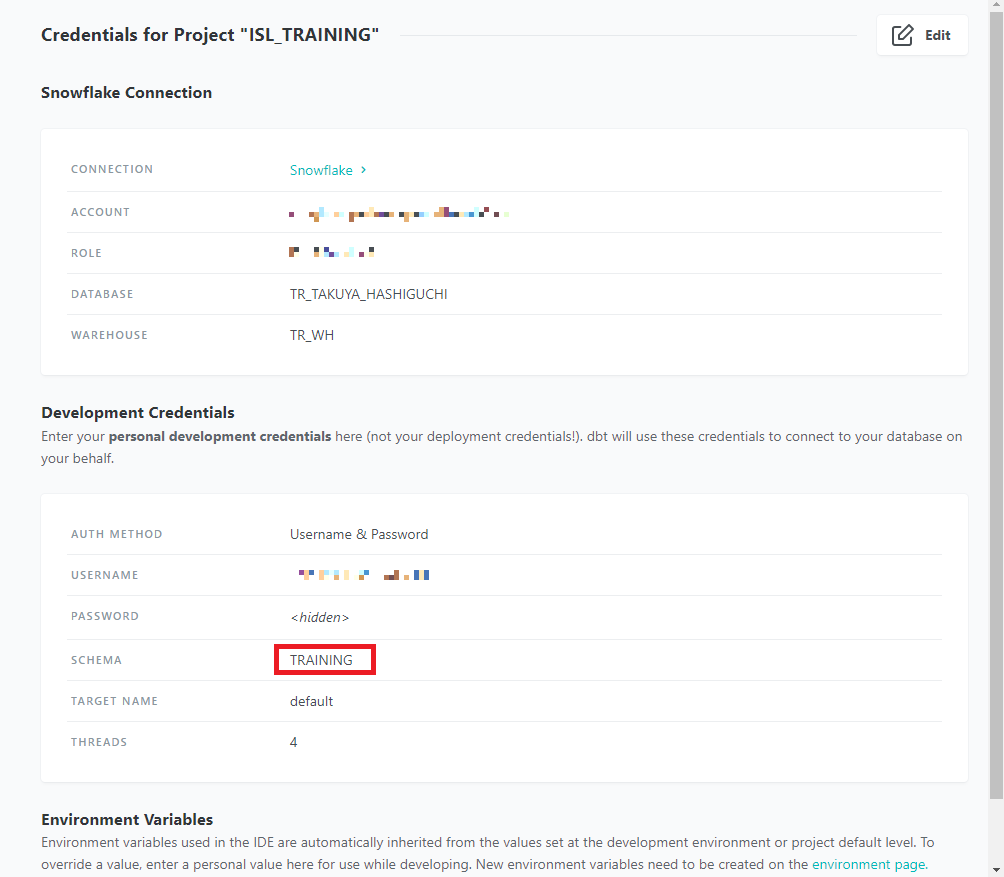
モデルを実行すると、環境構築の際に設定したスキーマ(ターゲットスキーマ)にテーブルが作成されます。以下のように今プロジェクトではTRAININGスキーマがターゲットスキーマとなり、TRAININGスキーマにテーブルが作成されます
dbtの階層が複数になり、Snowflakeにもフォルダに対応したスキーマを設けたい場合には、dbt側でカスタムスキーマを設定できます。
【フォルダごとの適用】
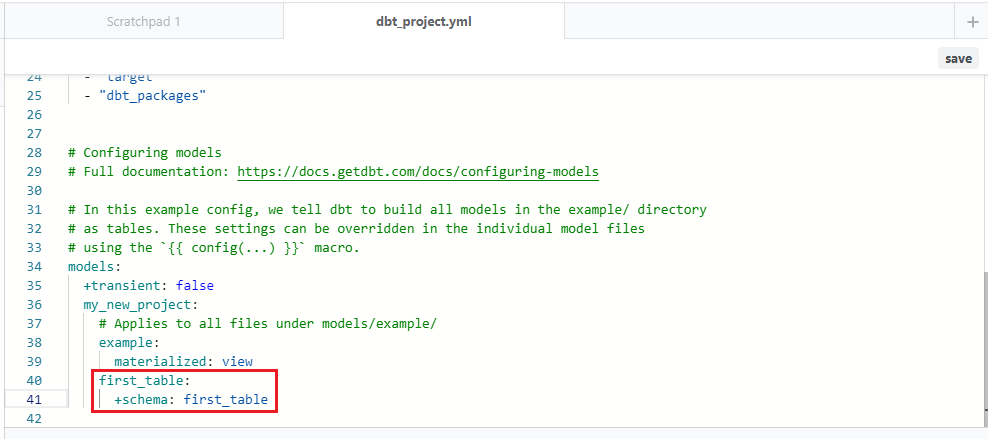
フォルダごとに適用させるには、「dbt_project.yml」ファイルを編集します。「dbt_project.yml」を開き、以下の部分に "first_table", "+schema: first_table" と記述します。
【モデルごとの適用】
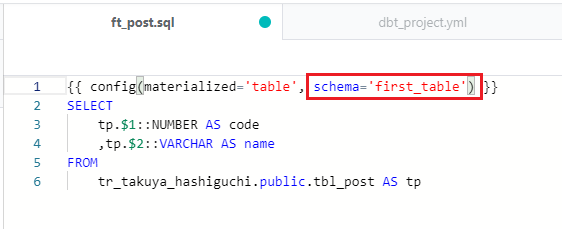
モデルごとに適用させるには、各モデルの "config" を編集します。カスタムスキーマを設定したいモデルを開き、以下のように "schema=first_table" と記述します。
カスタムスキーマで設定したスキーマがSnowflake側に存在しない場合、新たにそのスキーマを作成し、そこにテーブルが作成されます。実行してみると・・・。
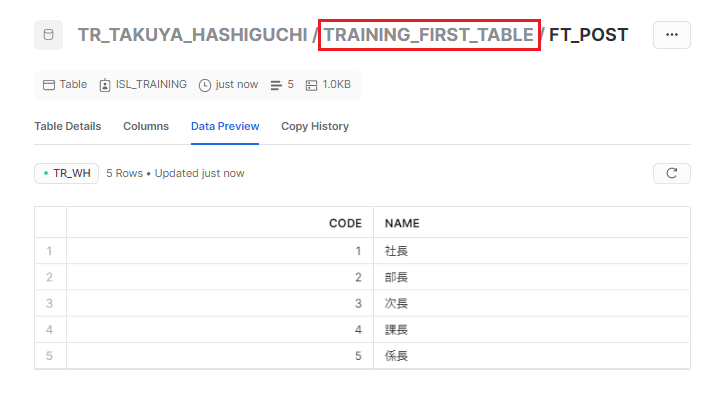
「TRAINING_FIRST_TABLE」というスキーマが作成され、そこにテーブルが作成されました。
スキーマ名が「ターゲットスキーマ_カスタムスキーマ」になっているのは、各dbtユーザー間、開発モデルと本番モデル間でのスキーマ名の競合を減らすためのdbtの仕様のようです。
スキーマ名の生成に別の命名規則を使用したい場合は、マクロを使用することで設定することができます。
macrosフォルダ内に "generate_schema_name.yml" というファイルを作成し、下のように記述します。
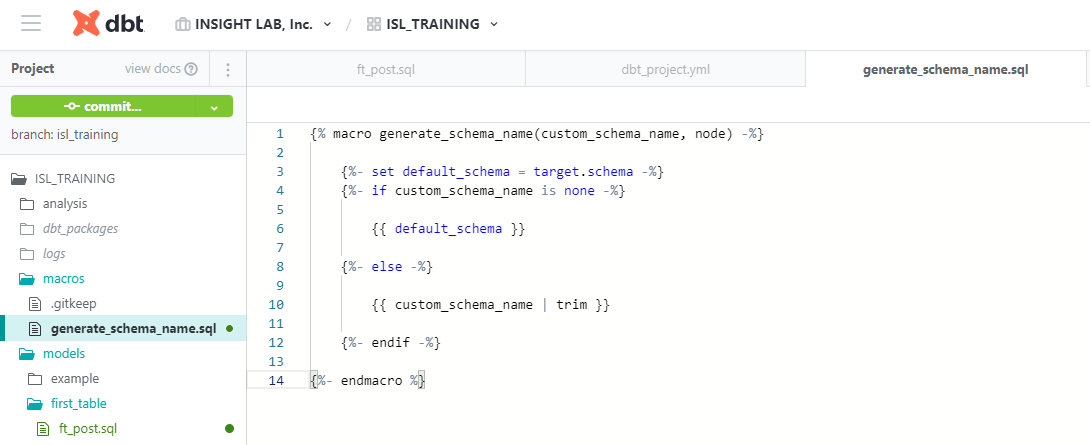
この中の "default_schema" というのは環境準備の際のSnowflakeの設定で記入したスキーマ名(ターゲットスキーマ:TRAINING)、
"custom_schema_name" というのは、先ほど「dbt_project.yml」内で設定した各スキーマ名(カスタムスキーマ:FIRST_TABLE)、
「カスタムスキーマが設定されていない時はターゲットスキーマ、そうでない時はカスタムスキーマを使う」という命名規則が設定できました。
マクロ設定後もう一度実行してみると・・・。
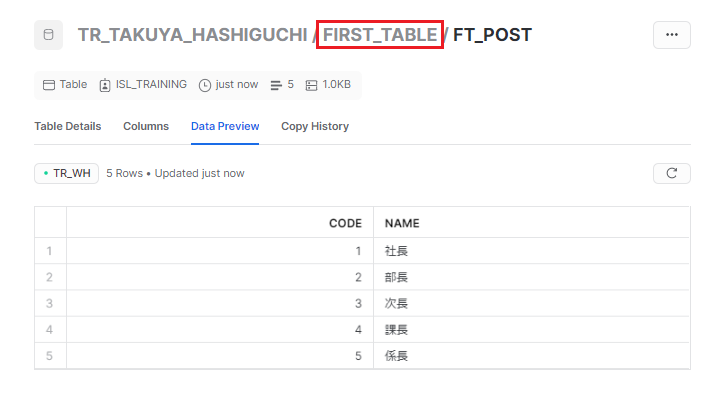
「FIRST_TABLE」というスキーマにテーブルが作成されました。
参考
モデルをテストする
dbtは作成したモデルに対してテストを行うことができ、テーブルやビューのデータが間違ってないかどうかテストできます。
dbtでは2種類のテストを定義できます。
-
単体テスト
-
SQLファイル(.sql)で定義する
-
エラー行を返すようにクエリを記述する
-
-
一般テスト
-
YAMLファイル(.yml)で定義する
-
データが「一意であるか」、「NULLがないか」、「指定値以外が入っていないか」、「参照元に存在するか」などのテストを実行できる。
-
どちらも "dbt test" コマンドで実行します。
【単体テスト】
testsフォルダ内にテスト用のSQLファイルを作成し、SELECT文を記述します。
テストしたい内容が検出されるように記述し、結果が0件だとデータに間違いがないという形です。
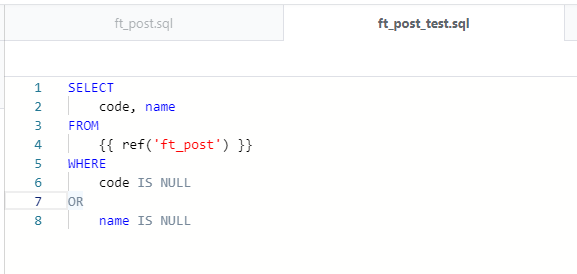
【一般テスト】
modelsフォルダ内にテスト用のYAMLファイルを作成し、テストを定義します。
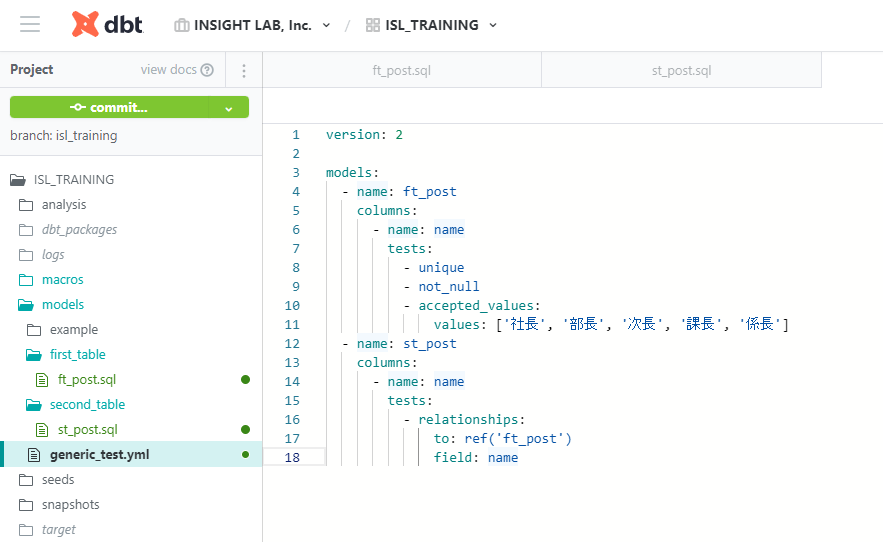
"models" 直下に "name: モデルのファイル名" 、"columns: テストしたいカラム名" 、
"columns" 直下に "name: テストするカラム名" 、"test: テストの種類"、のように記述していきます。
各テストの内容は以下になります。
-
unique:カラム内のデータが一意である
-
not_null:カラム内のデータにNULLがない
-
accepted_values:カラム内のデータは、values内のいずれかである
-
relationships:カラム内のデータは、すべて参照元に存在する
テストを実行するには画面下の入力スペースに "dbt test" と入力して、[Enter] をクリックします。
実行結果は以下になります。
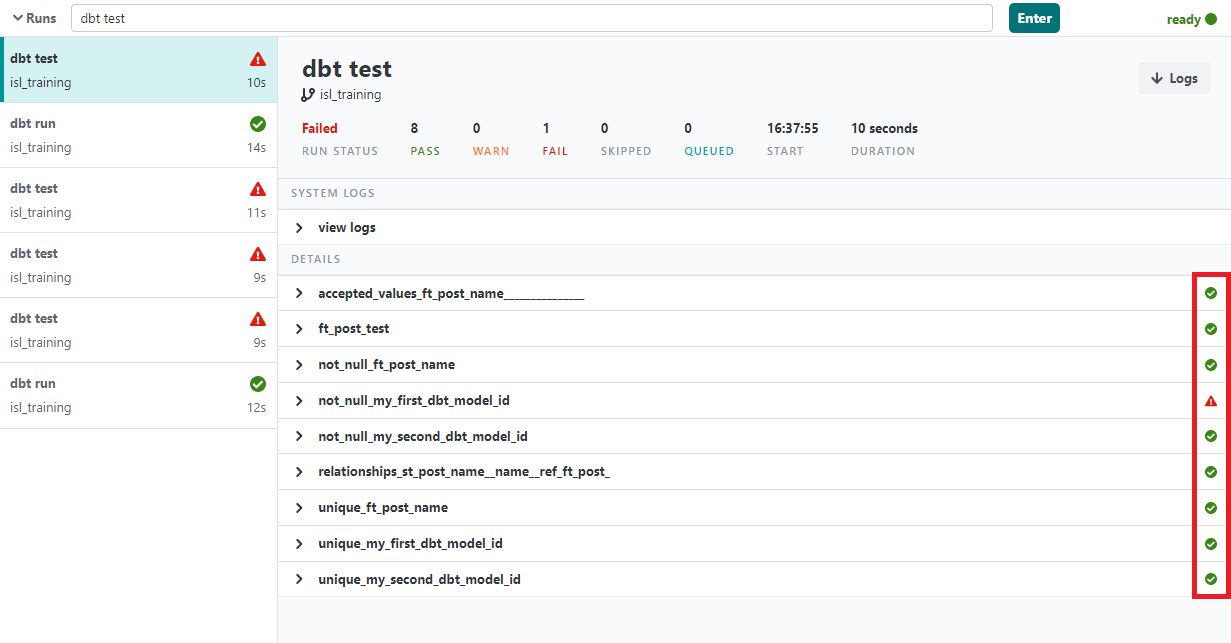
右のマークからどのテストが失敗しているのか判別できます。先ほど作成したテストに関してはすべてパスしています。(my_first_...、my_second_...はデフォルトのテストファイル。)
参考
定期実行するためのデプロイ環境を作成する
データが継続的に蓄積される場合、モデルを定期的に実行して、テーブルを最新の状態に更新するためのデプロイ環境を構築する必要があります。dbtのEnvironmentとJobsを使って、それら環境を構築することができます。
環境構築の前に、リポジトリに最新のコードが反映されるように、加えた変更をコミットする必要があります。
コミットするには画面左上の [commit...] をクリックし、メッセージ(変更点など)を記入して、[Commit] をクリックします。
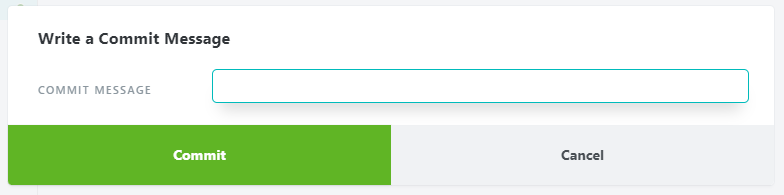
コミット出来たら、mainブランチにマージします。
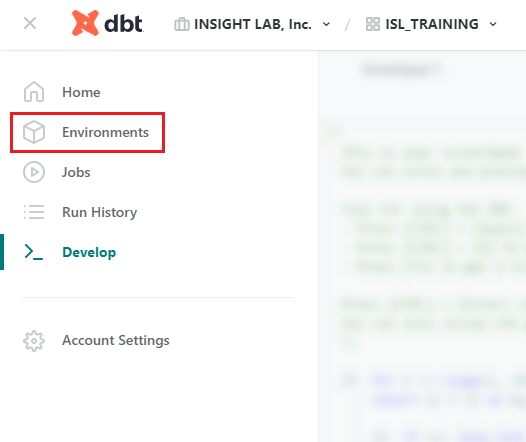
次に環境を作成します。
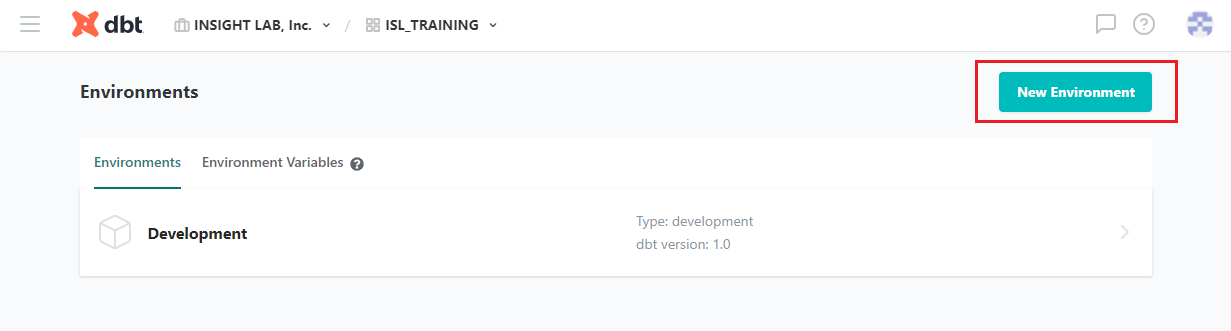
画面左上の [≡] から [Environments] をクリックし、[New Environment] をクリックします。
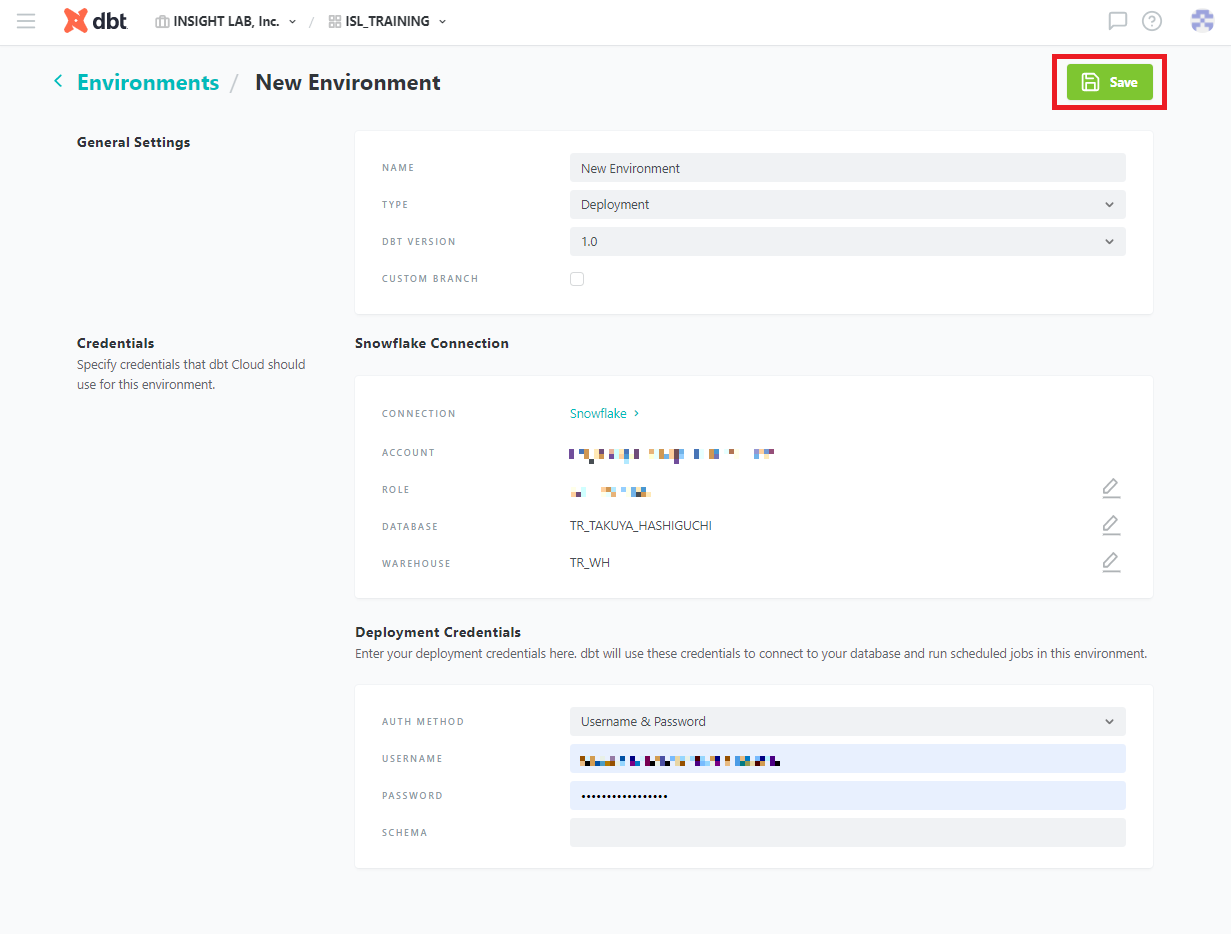
デプロイ環境に名前をつけ、「Deployment Credential」にSnowflakeの情報を入力し、[Save] をクリックします。
以下の画面に移れば、環境を作成完了です。
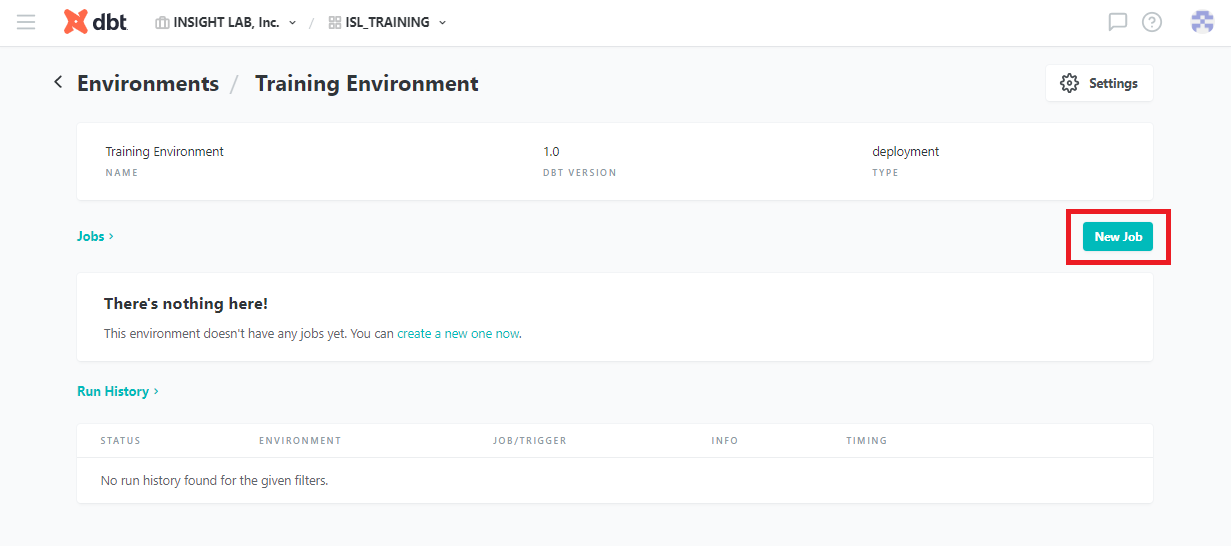
続いてスケジュールに従ってモデルを実行するための、ジョブを作成します。
上図の [New Job] 、または [≡] から [Jobs] をクリックした先の [New Job] からジョブを作成します。
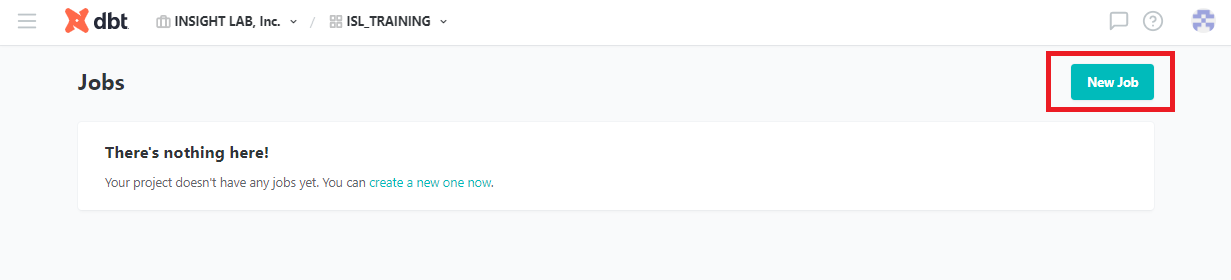
以下の画面に移るので、ジョブに名前をつけ、使用する環境をENVIRONMENTから選択します。
またGENERATE DOCS?にチェックを入れ、Commandsに実行するコマンドを入力、追加します。
コマンドには、"dbt run"、"dbt test" を含むようにします。
Triggersで、実行するスケジュールをなどを設定できますが、今回はチェックを外しておきます。
設定が完了したら、[Save] をクリックします。
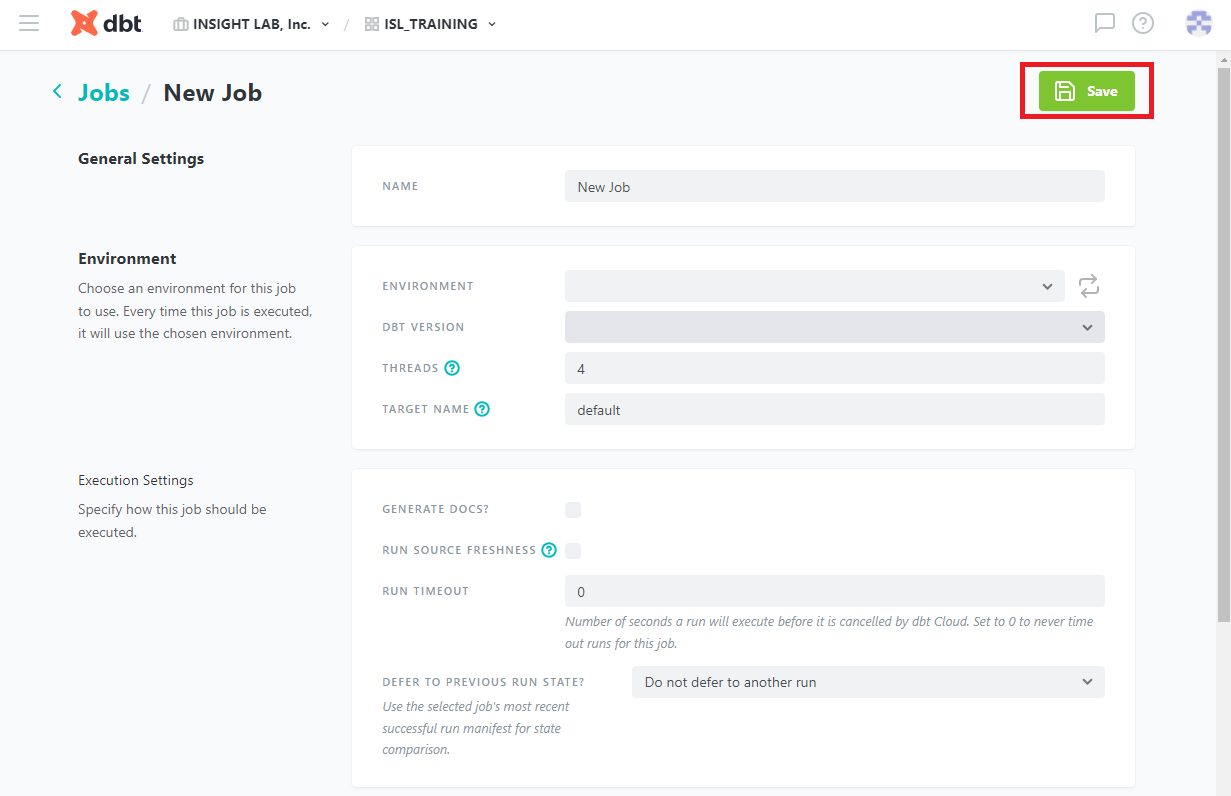
以下の画面に移れば、ジョブの作成完了です。
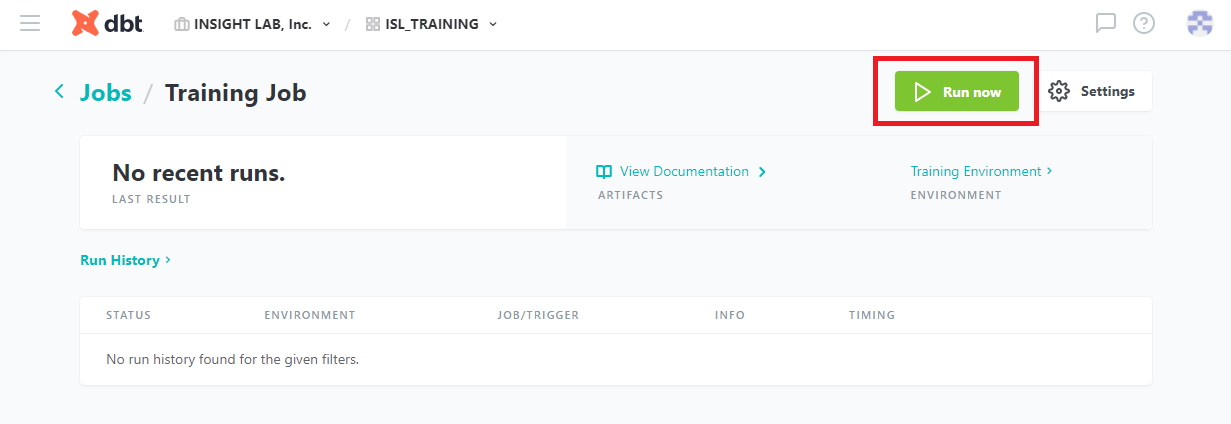
[Run Now] をクリックすることで、ジョブを手動で実行できます。実行した結果が以下になります。
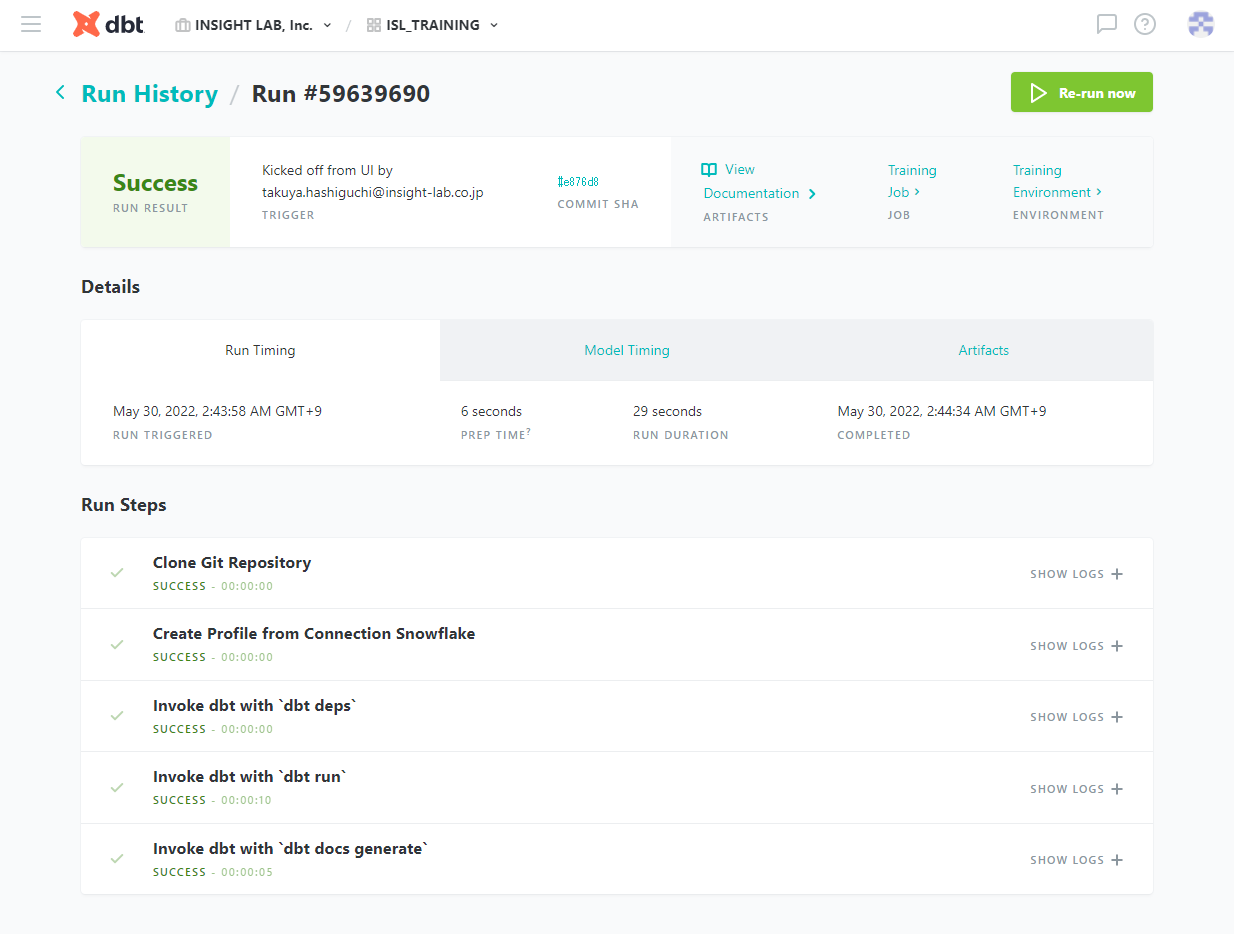
参考
Snowflake上に作成したテーブルの増分更新
テーブルを継続的に更新する際、扱うデータが大きいと、テーブルの再生成に毎回と大幅な計算コスト、実行時間を費やすことになります。
そのためdbtには、変換するデータを制限するモデルタイプ:incrementalモデルが存在します。incrementalモデルを使用すると、モデルが最後に実行されてから更新されたレコードを指定して、テーブルを段階的に構築することができます。
incrementalモデルを使用するためには、適用するモデルの "config" を編集します。incrementalモデルとするファイルを開いて、以下のように "materialized='incremental'" と記述します。
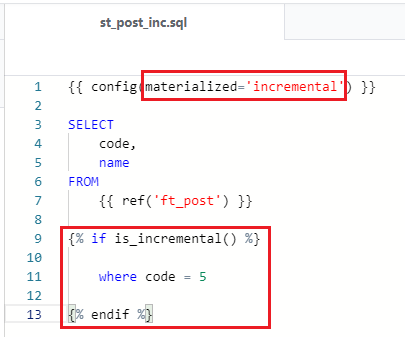
またincrementalモデルにおいて、変換するレコードを指定するため、is_incremental()マクロを設定する必要があり、マクロ内のWHERE句で更新するレコードを指定します。今回は簡単に以下のように code = 5 のレコードを変換するレコードとして指定します。実際に実行すると・・・
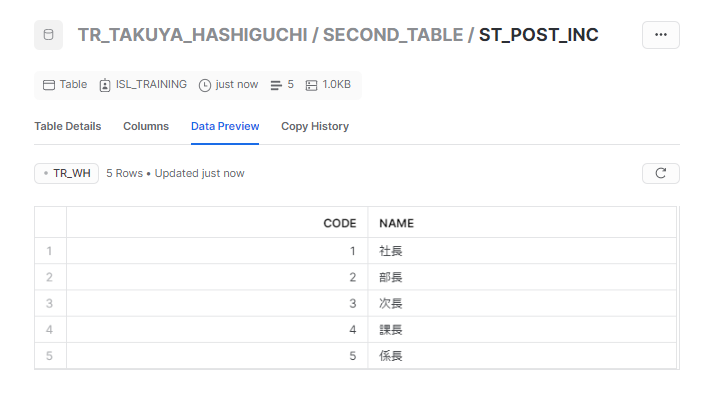
初回実行なので、参照元のデータと同様になっています。もう一度実行すると・・・
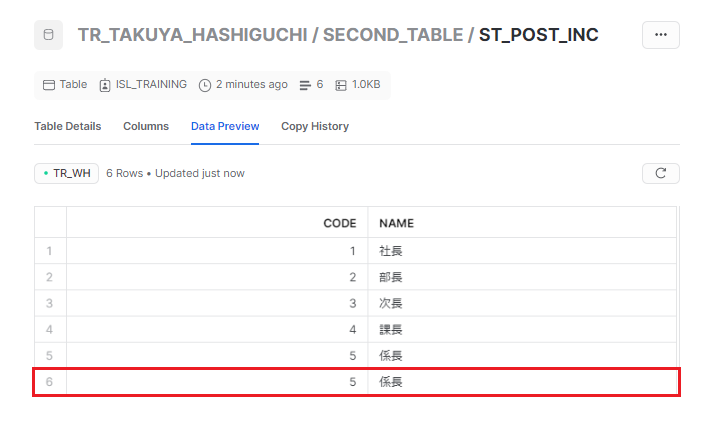
is_incremental() マクロのWHERE句で指定したレコードのみ追加されました。
Snowflake側で二回目実行のクエリを確認すると、insert文になっていることが分かります。
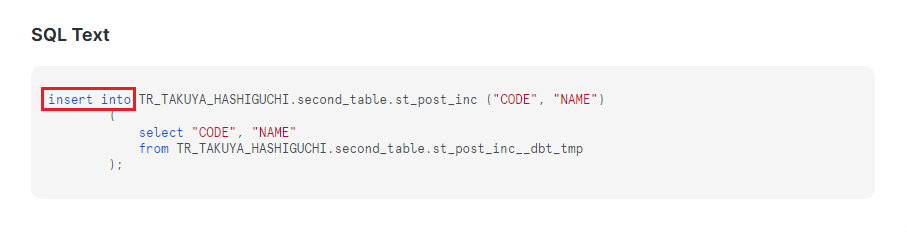
実際の利用方法としては、前回の実行以降に追加されたレコードを指定して、それだけ変換するようにします。前回の実行結果から参照するためには、is_incremental()内のFROM句に変数を使用し、以下のように記述します。
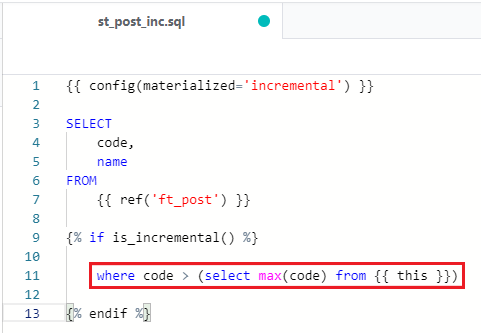
「code(通し番号)が前回の実行結果のcodeの最大値より大きい数値」を指定しています。
incrementalモデルを最初から再構築するには "dbt run --full-refresh" コマンドを実行します。
is_incremental()マクロの有効(テーブルの増分更新)には以下の条件があります。
-
DWH上にすでに、当モデルのテーブルが作成されている。
-
dbtが "--full-refresh" コマンドで実行されていない。
-
実行するモデルに "materialized='incremental'" が設定されている。
参考
まとめ
今回は、dbtでデータパイプライン構築のための機能を簡単に説明しました。
より詳しい情報については、dbt公式のドキュメントを参照ください。
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。