はじめに
以前こちらの記事で、AWS SageMaker Canvas という AutoMLツールを使って、医療費の予測モデルを作成しました。本記事は、(自分の勉強用に)この回帰モデルをコーディングで作ってみようという主旨です。また、こちらの記事で、TensorFlow Playground を使用したので、ライブラリも TensorFlow を使おうと思います。
学習に使用するデータは CSV で、カラムの構成は以下になっています。
- age: 主たる受取人の年齢
- sex: 保険契約者の性別
- bmi: BMI指数。身長に対する体重の相対的な高低。
- children: 健康保険に加入している子供の数/扶養家族の数
- smoker: 喫煙
- region: 米国内の受給者の居住地域(北東部、南東部、南西部、北西部)
- charges: 健康保険から請求された個々の医療費
これらのデータを使用して、回帰モデルを TensorFlow を使用して作成します。
モデル作成
1. ライブラリのインストールとインポート
まず、必要なライブラリをインストールし、インポートします。
pip install pandas scikit-learn tensorflow次に、Pythonスクリプトで必要なライブラリをインポートします。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.metrics import mean_absolute_error, mean_squared_error2. データの準備
データを読み込み、データを特徴量(X)とターゲット(y)に分割、カテゴリカルデータのエンコードと数値データの標準化を行い、データを学習用とテスト用に分割します。
# データの読み込み
data = pd.read_csv('insurance_data.csv')
# 特徴量とターゲットの分割
X = data.drop('charges', axis=1)
y = data['charges']
# カテゴリカルデータのエンコードと数値データの標準化
categorical_features = ['sex', 'smoker', 'region']
numeric_features = ['age', 'bmi', 'children']
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(), categorical_features)
])
# データの前処理
X_processed = preprocessor.fit_transform(X)
# トレーニングデータとテストデータの分割
X_train, X_test, y_train, y_test = train_test_split(X_processed, y, test_size=0.2, random_state=42)- 特徴量とターゲットの分割:
charges列が予測対象(ターゲット)となるため、これをyとして分離し、他の列を特徴量Xとして扱います。
- カテゴリカルデータのエンコード:
categorical_featuresに指定された列(sex,smoker,region)はカテゴリカルデータです。これらは数値データではないため、モデルが直接利用できません。
OneHotEncoderを使用してカテゴリカルデータをバイナリ(0または1)に変換します。この手法により、カテゴリカルデータを数値データとしてモデルに提供できます。
- 数値データの標準化:
numeric_featuresに指定された列(age,bmi,children)は数値データです。これらのデータはスケールが異なることが多いため、モデルが効率的に学習するためにはスケーリングが必要です。
StandardScalerを使用して標準化を行います。標準化は、各特徴量を平均0、標準偏差1にスケーリングします。これにより、すべての数値データが同じスケールで扱われ、モデルの学習が安定します。
- データの前処理:
ColumnTransformerを使用して、数値データの標準化とカテゴリカルデータのエンコードを一度に処理します。これにより、前処理のステップを簡潔に行うことができます。
- トレーニングデータとテストデータの分割:
- データセットをトレーニングデータとテストデータに分割することにより、モデルの性能を評価するための新しいデータセットを保持します。
train_test_splitを使用して、データを80%のトレーニングデータと20%のテストデータに分割します。random_state=42を指定することで、分割の再現性を確保します。
3. モデルの構築
TensorFlowを使用してシーケンシャルモデルを構築します。
# モデルの構築
model = Sequential([
Dense(64, activation='relu', input_shape=(X_train.shape[1])), # 入力層と第1隠れ層
Dense(64, activation='relu'), # 第2隠れ層
Dense(1) # 出力層
])Sequential: モデルの各層が順に積み重なっていく単純なスタックモデルを定義するためのクラス。
Dense: 全結合層。ユニット数と活性化関数を指定。各ニューロンが前の層のすべてのニューロンと接続されていることを示します。64: ユニットの数。この場合、64個のユニットを持つ全結合層を追加します。(ここでは64)は層の出力の次元を指定。
activation='relu': 活性化関数としてReLUを使用します。
input_shape=(X_train.shape[1]): 最初の層にのみ必要で、入力データの形状を指定。
ここでは、トレーニングデータX_trainの特徴量の数を指定しています。
- 出力層: 出力層には活性化関数を指定していません。通常、回帰問題では出力層の活性化関数は使用しません。
4. モデルのコンパイル
モデルをコンパイルします。
# モデルのコンパイル
model.compile(optimizer='adam', loss='mean_squared_error')optimizer='adam': モデルの重みを最適化するためのアルゴリズム(ここではAdamオプティマイザーを使用)。
loss='mean_squared_error': モデルがどれだけ悪いかを定量化するための損失関数(ここでは平均二乗誤差(MSE)を使用)。
5. モデルのトレーニング
トレーニングデータを使用してモデルをトレーニングします。
# モデルのトレーニング
history = model.fit(X_train, y_train, epochs=100, validation_split=0.2, batch_size=32)model.fit: モデルのトレーニングを行うメソッドです。このメソッドを呼び出すことで、モデルは指定されたデータで学習を開始します。epochs: トレーニングデータ全体を何回繰り返すかを指定。
validation_split: トレーニングデータの一部を検証データとして使用する割合を指定(ここでは20%)。
batch_size: 1エポックでトレーニングに使用するデータのサブセットのサイズを指定。
6. トレーニング過程の確認
トレーニング過程をプロットし、トレーニング中のモデルパフォーマンスを確認します。
# トレーニング過程のプロット
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
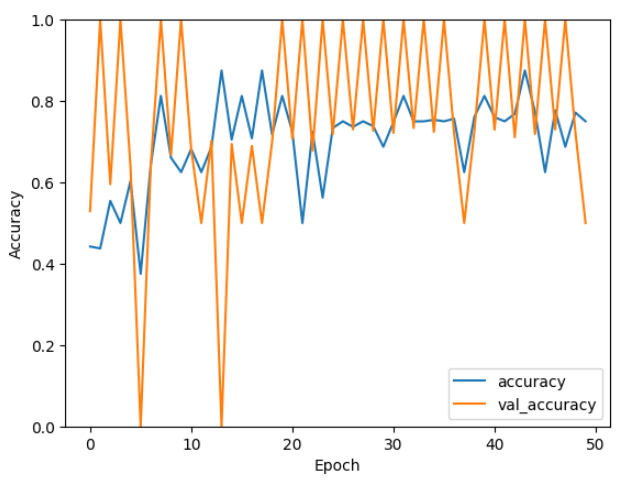
plt.show()Matplotlib に関しては割愛します。結果は以下の通り。
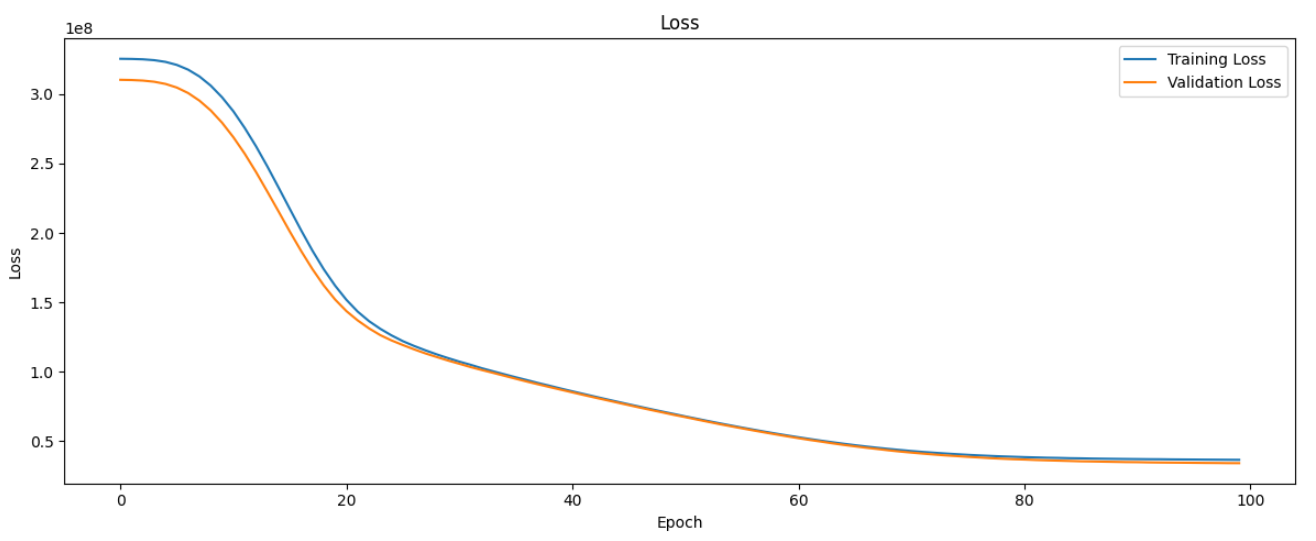
横軸はエポック数(Epoch)、縦軸は損失(Loss)を表しています。青い線はトレーニングデータに対する損失、オレンジの線は検証データに対する損失を示しています。
損失がエポック数が増えるにつれて安定していることから、モデルの学習が収束していることがわかります。つまり、これ以上学習を続けても損失の減少が期待できない状態に達しています。
7. モデルの評価
テストデータを使用してモデルの予測を行い、評価指標を計算します。
# テストデータでの予測
y_pred = model.predict(X_test)
# モデルの評価
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = mean_squared_error(y_test, y_pred, squared=False)
print(f'MAE: {mae}')
print(f'MSE: {mse}')
print(f'RMSE: {rmse}')model.predict(X_test): トレーニング済みのモデルを使って、テストデータ (X_test) に対する予測を行う関数です。この関数は、テストデータに基づいてモデルが予測した値を返します。mean_absolute_error(y_test, y_pred): 平均絶対誤差(MAE)を計算します。これは、予測値と実際の値の差の絶対値の平均です。MAEが小さいほど、予測の精度が高いことを示します。
mean_squared_error(y_test, y_pred): 平均二乗誤差(MSE)を計算します。これは、予測値と実際の値の差の二乗の平均です。MSEが小さいほど、予測の精度が高いことを示します。
mean_squared_error(y_test, y_pred, squared=False): 平方根平均二乗誤差(RMSE)を計算します。これは、MSEの平方根を取ったものです。RMSEが小さいほど、予測の精度が高いことを示します。
結果ですが、以下が出力されました。
MAE: 4060.9136578962225
MSE: 32895051.458825566
RMSE: 5735.4207743482575
ちなみに AWS SageMaker Canvas の結果は以下でした。
MAE: -
MSE: 23578592.000
RMSE: 4855.799
どちらも良い結果ではないですが、比較では Canvas の方が良い結果となりました。
まとめ
以上の手順で、医療費(Charges)の予測モデルを作成しました。評価を見るに、まだ改善の余地はありますが、回帰モデルを TensorFlow を使って作成することができました。Canvas の方が良い結果となりましたが、TensorFlow(ニューラルネットワーク)でなく他の手法を使うなどすればまた変わってくると思うのでまた試してみたいと思います。
Canvas については GUI ベースの使いやすい AutoMLツールであるので、興味があれば使ってみてください。