この記事は、【Sisenseはじめの一歩】の第2回の記事です。 目次はこちら。
こんにちは、Sato-Gです。
1989年から週間少年マガジンで連載されてきた「はじめの一歩」に打ち切りの噂がもっともらしく流れている。このブログですら締め切りを守れない僕としては、実に20年もの間、同じマンガを描き続けている森川ジョージさんには敬意を表するしかない。

さて、今日時点でのAmazonの情報学・情報科学の売れ筋ランキングの3位は「コンピュータにかわいいを教えたら何がおきたか」。この本、うちの会社のCEOが書いた本で、明日(2019年3月7日)発売となる。
内容は経営データの可視化が中心で、データの整理の仕方、可視化パターン、顧客事例などをコンパクトにまとめた内容になっているので、ご興味のある方は是非手にとっていただきたい。因みに僕が関わったプロジェクトもいくつか含まれている。
...とちゃっかり宣伝が終わったところで、Sisenseはじめの一歩の第2回は、サンプルデータを取り込んでいく過程を体験してみる。
Sisenseにおいては「Hello,Sisense World!」で紹介したElastiCubeでデータモデルを構築する方法とデータベースに直接接続したたまリアルタイムにデータを取得するライブ接続があるが、今回はElastiCubeを用いたデータモデリングを紹介していく。
データベースなど準備するのは面倒なので、今回はテキストファイル(CSV形式)を取り込んで簡単にデータモデルを作ってみよう。
取り込むデータについて
今回のトライアルで使用するファイルを以下のURLよりデータを取得しよう。
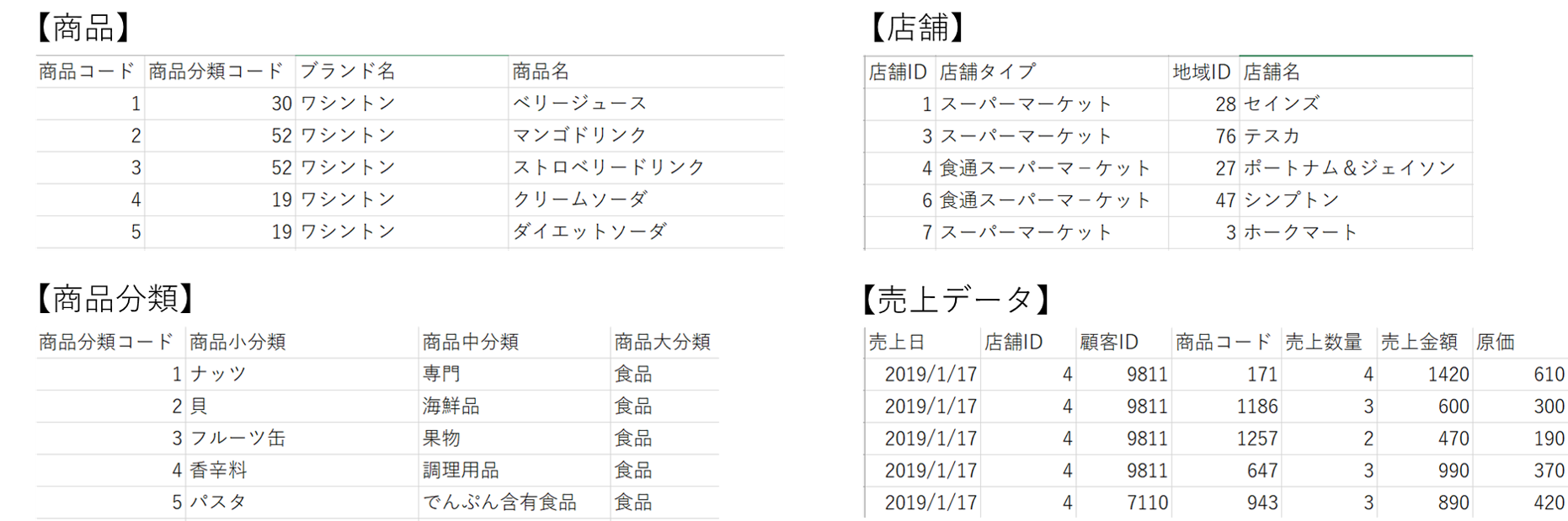
zipファイルを解凍すると、以下のようなファイルが現れる。この中で今回使用するファイルは「商品.csv」「商品分類.csv」「店舗.csv」「売上データ.csv」の4つになる。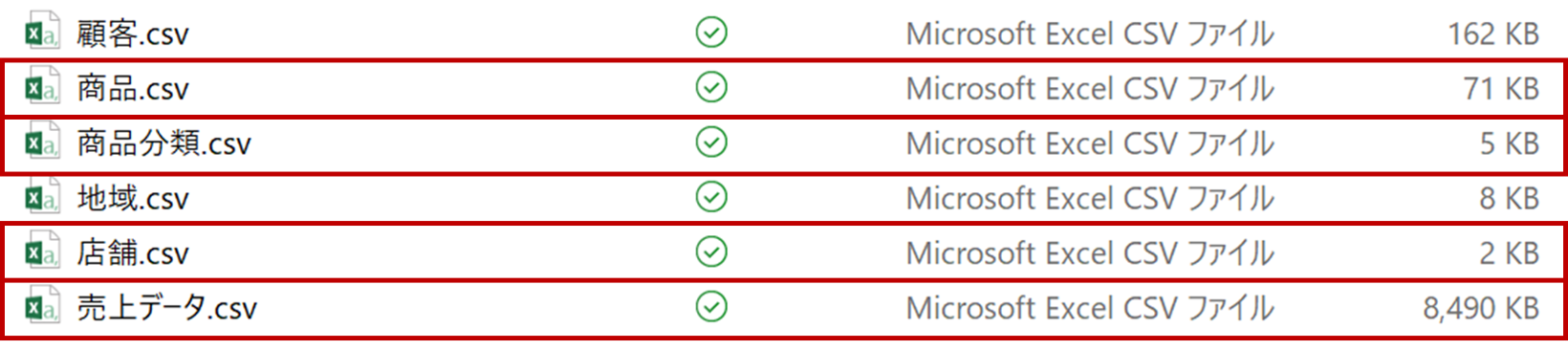
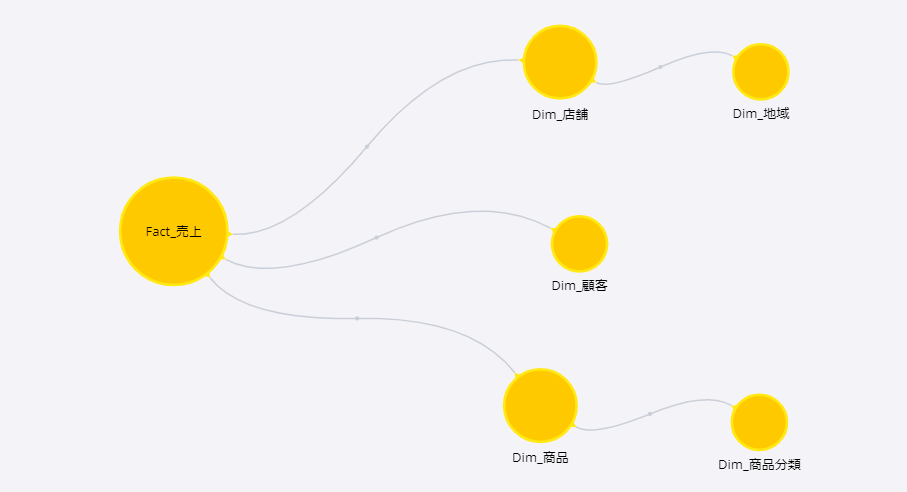
ファイルは売上データにキー項目があり、それに対応する商品、店舗のテーブルがある。さらに商品にある商品分類コードに対応して商品カテゴリがある。
こんなふうにデータがきっちり正規化されているのはごく稀なケースだけど、トライアルでサクッと作りたいので、予めデータを整理しておいた。
データモデリングの方針
データモデルを作成する前に押さえておきたいルールがある。
まあ、スタンダードなBIの経験者であれば、何を今さらという感じだろうけど、あえて解説しておく。基本的なデータモデルはファクトテーブルとディメンションテーブルからなり、通常はファクトテーブルを囲む形でディメンションテーブルが紐付いている。
詳細はまたいつか解説するが、それぞれのテーブルはこんなふうに捉えておけばいい。
・ファクトテーブル
集計対象となるデータを含んだテーブルで、今回のデータでは「売上データ」から作成するテーブル
・ディメンションテーブル
分析軸を含むデータを含んだテーブルで、今回のデータでは「商品」「商品分類」「店舗」のデータから作成するテーブル
以下はファイルの概要仕様。
①売上データ
顧客ID、店舗ID、商品コードはキー項目で、ディメンションテーブルに紐づく。売上数量、売上金額、原価は集計対象となる項目で「メジャー」と呼ぶ。
②商品
商品コードで売上テーブルに結合される
③商品分類
商品分類コードで商品テーブルに結合される
④店舗
店舗IDで売上データテーブルに結合される
Data DesignerでCSVファイルを読み込む設定
さて、データの準備ができたので、データを取り込んでいこう。
Sisenseでデータモデリングを行うには以下の2つの方法がある。
(1)Data Designer(Webブラウザベース)
(2)Desktop ElastiCube Manager(Windowsアプリベース)
(2)は、接続するデータソースのコネクタのサポートが多く(1)より細かな設定ができるが、今回の範囲なら(1)で十分なので、まずはData Designerを使って取り込むことにする。とにかく簡単に済ませることが「はじめの一歩」の目的なので、必要最低限な機能だけ使うことにして細かい説明は今回は省くことにする。
Sisenseを立ち上げ、グローバルメニューの「データ」をクリックするところから始まる。
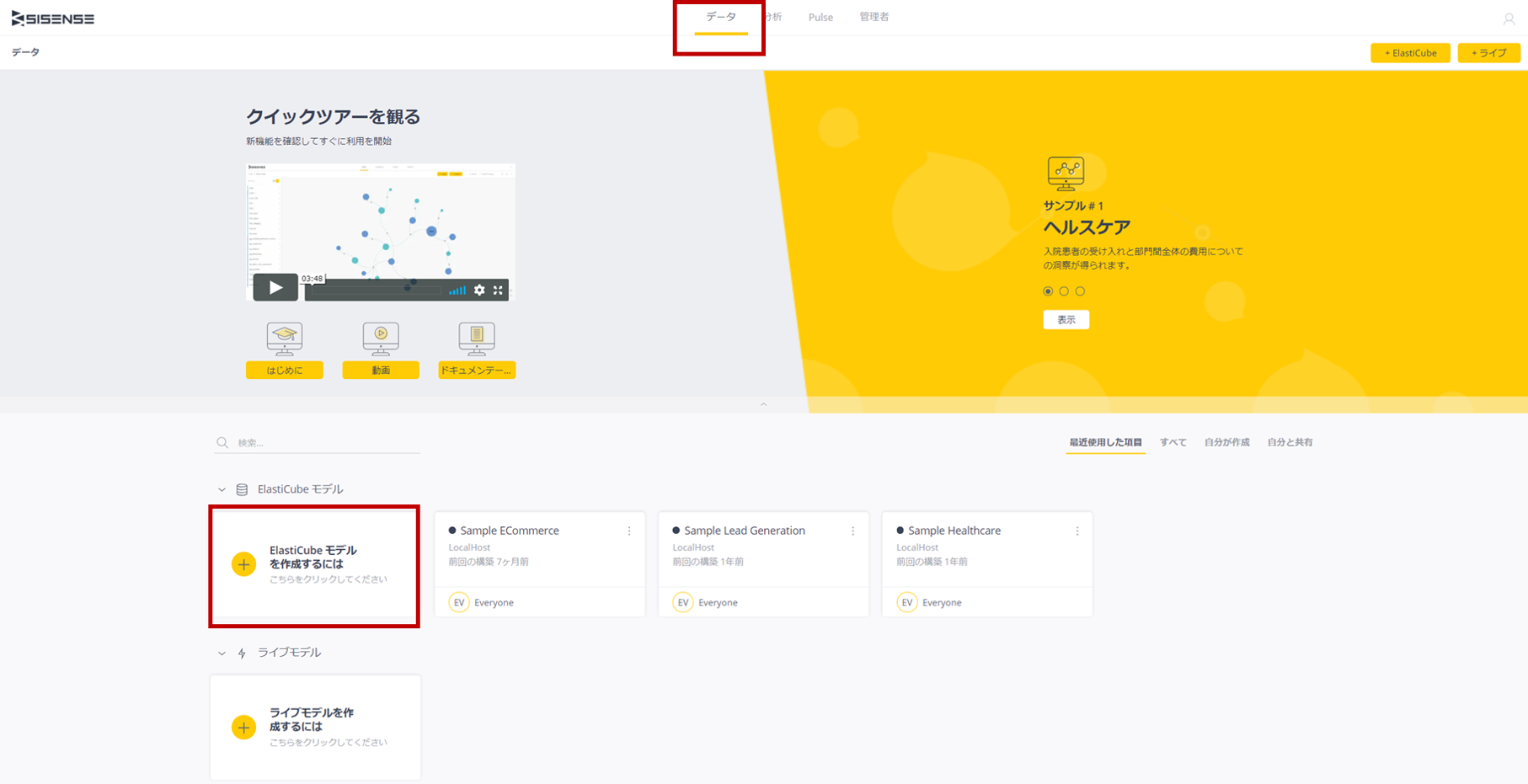
画面の下には「ElasitiCubeモデルを作成するには」「ライブモデルを作成するには」のアイコンがあるので、今回は「ElasitiCubeを作成するには」の⊕をクリックする。
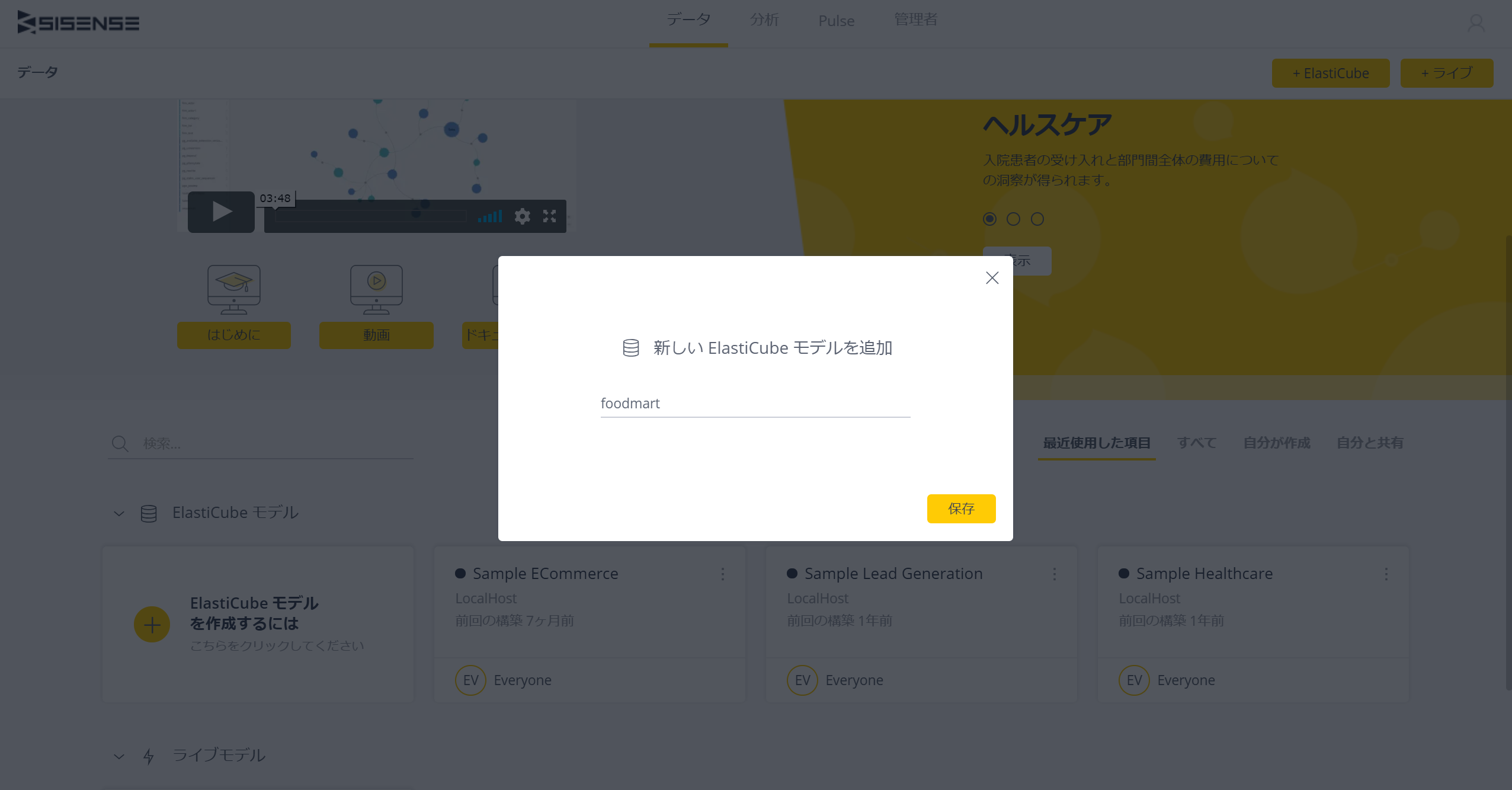
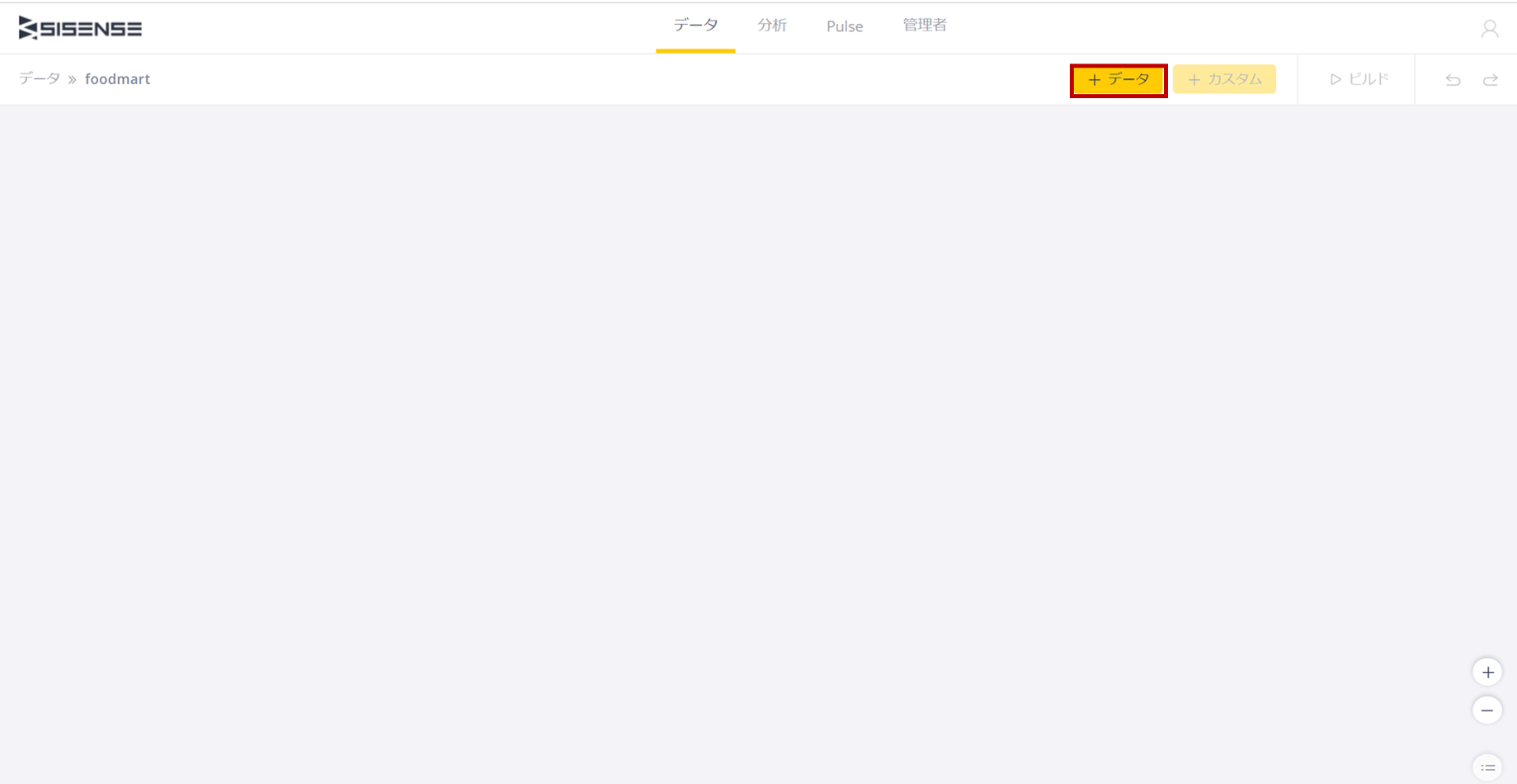
今回のElastiCubeのデータベース名を「foodmart」とし、[保存]ボタンを押すと、まっさらな画面に変わるで、ここで[+データ]ボタンを押すと、以下のようにデータソースの種類を選択する画面が表示される。

ここで見ればわかるように、WebベースのData Designerで使用できるのは、2019年3月現在でRedshift, CSV, JDBC, Excel, MySQL, Oracle, PostgreSQL, SQL Serverであり、それ以外はDesktop ElastiCube Managerで利用可能だ。
ここに表示されている以外にも多くのコネクタがあり、ここからダウンロードできるようになっているので
今回はCSVファイルなので「CSV」アイコンをクリックし、ファイルを選択していく。
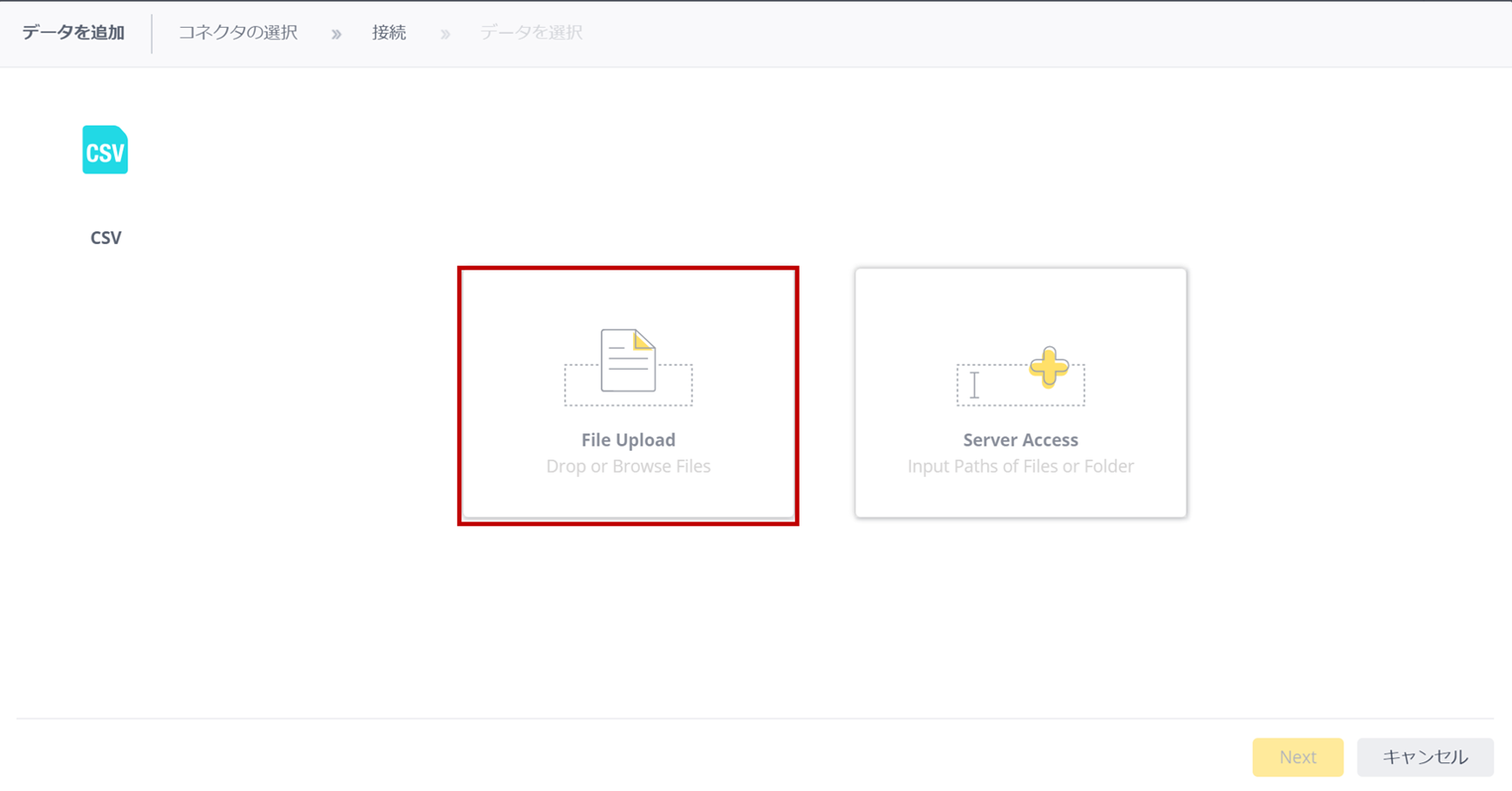
ファイルの選択は、クライアントPCからサーバにファイルをアップロードする「File Upload」とServer内のフォルダからデータを取り込む「Server Access」がある。
今回はPCからアップロードを行う(実は評価環境ではローカルPCがサーバになっているので、Server Accessでもいいんだけど)。
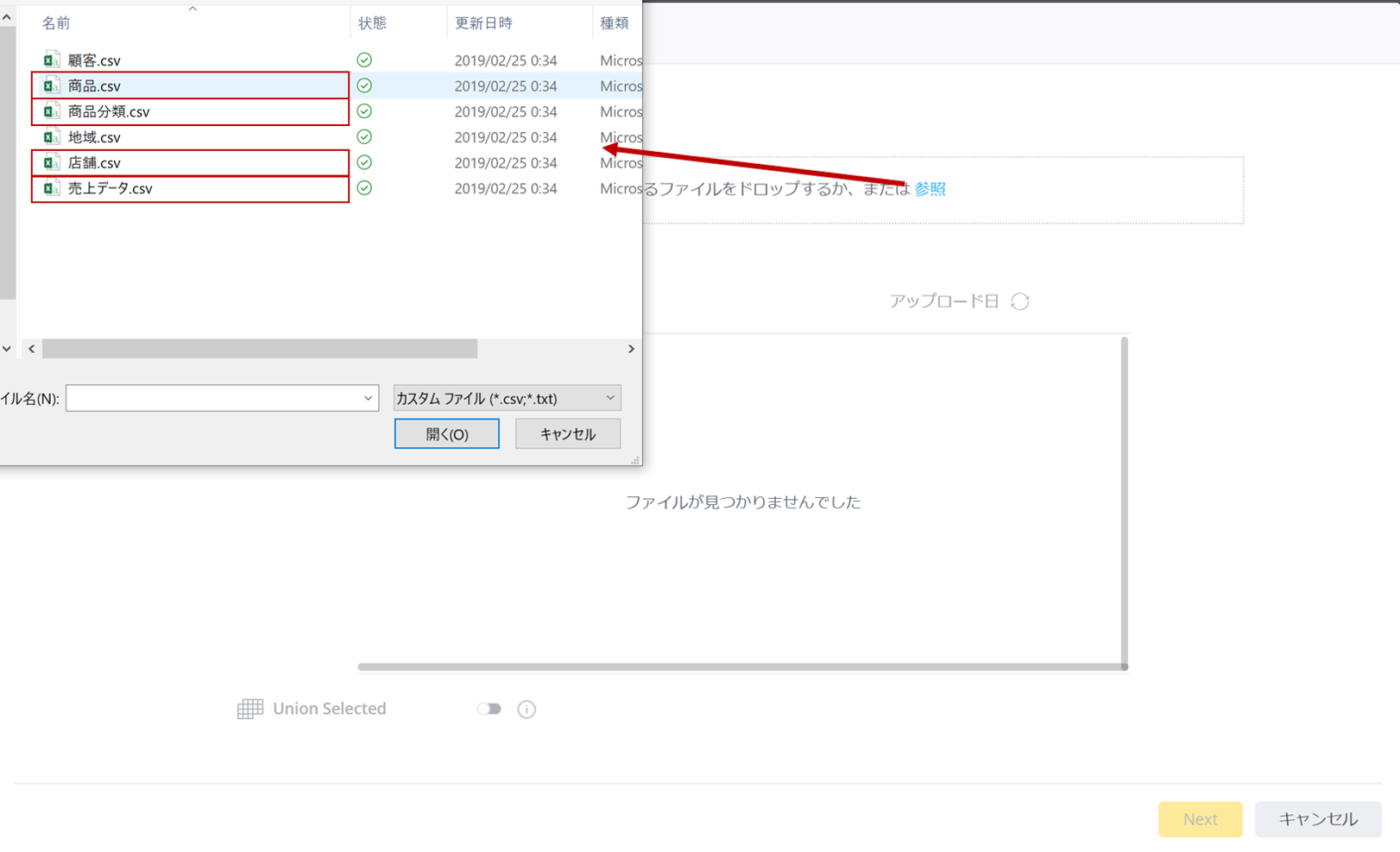
ファイルをアップロードするには、「参照」のリンクをクリックし、ファイルを指定する(今回は商品、商品分類、店舗、売上データの4つ)。
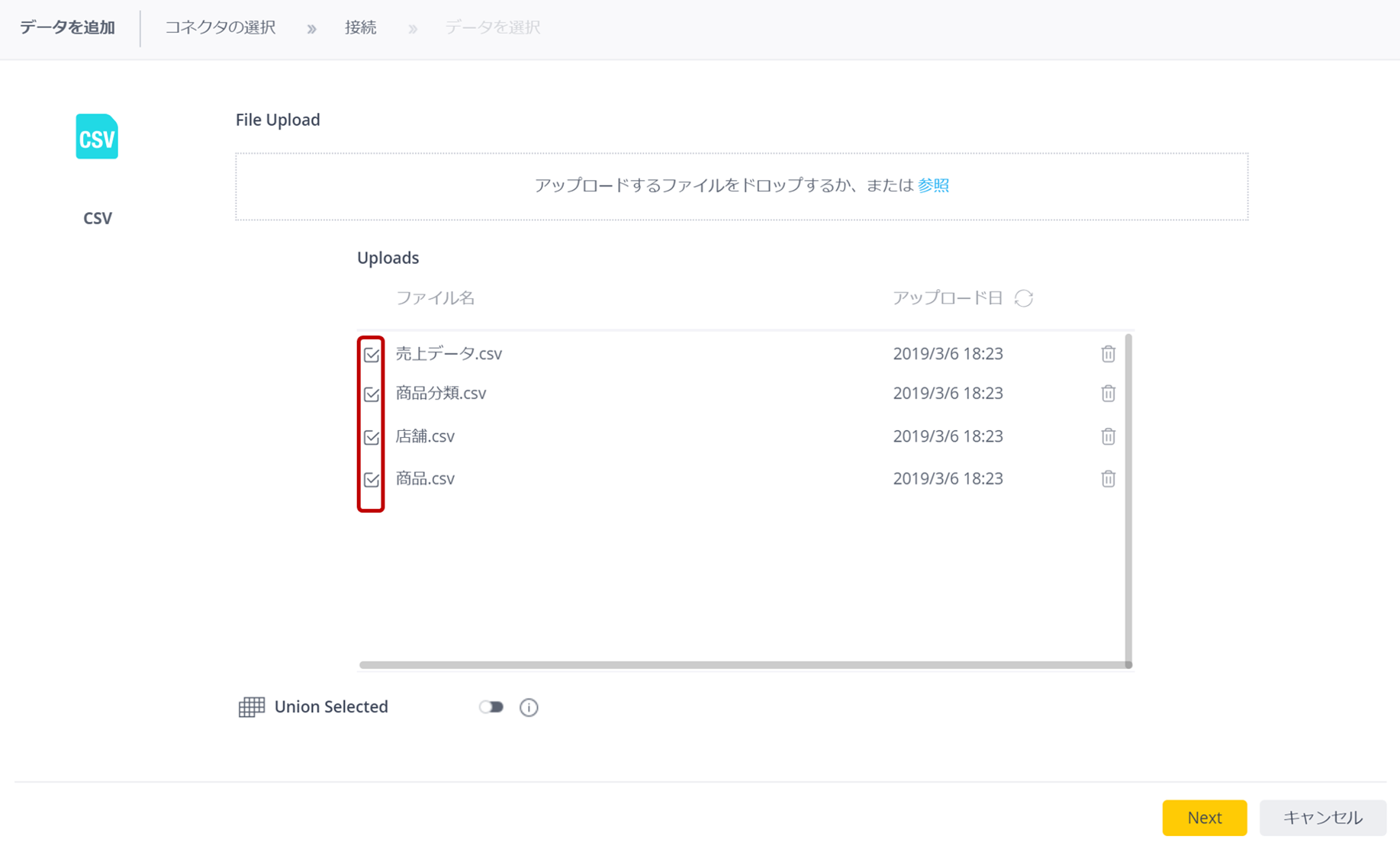
アップロードするファイルの一覧が表示されるので、4つのファイルにチェックを入れ、[Next]で次へ進む。
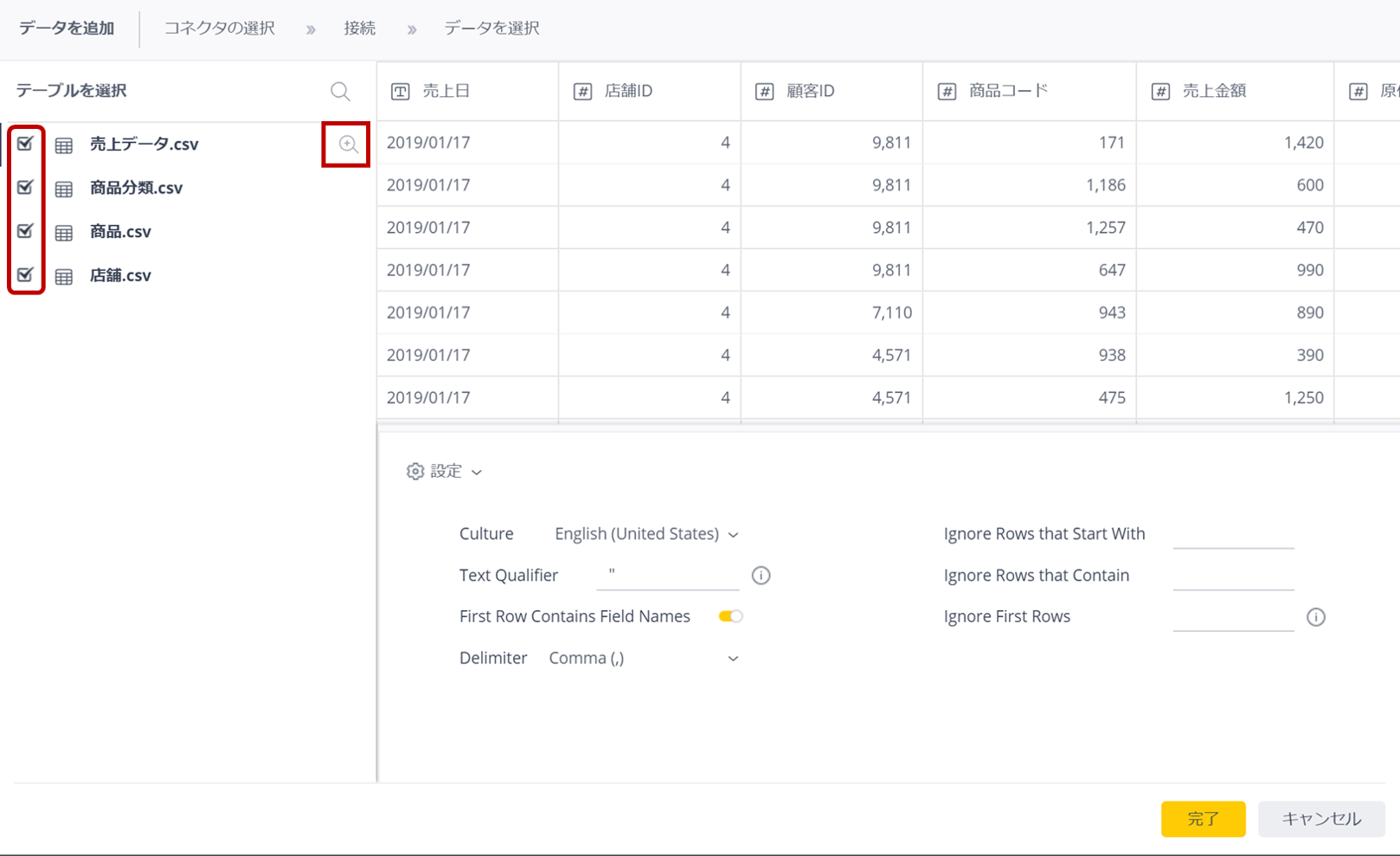
取り込むデータを選択する。ここの設定通りにテーブルができることになるので、少し細かな設定ができるようになっている。テーブルの横にある虫眼鏡のアイコンをクリックするとデータがプレビューされ、プレビューの下の「設定」読み込みの設定を行う。
・Culture: 国固有の表記に対応(おそらくここはデフォルトで問題ない、JapaneseにするとGMT +9:00の表示になって紛らわしかった)
・Text Qualifier: テキストのダブルクォート括りなどの設定
・First Row Contains Field Names: 1行目をフィールド名とするかの設定
・Delimiter: 区切り文字の設定(今回はCSVなのでカンマ区切り)
・Ignore...: 読み込まない行の設定(Ignore First Rowsの場合は何行目から読み込むかを設定できる)
リレーションシップの設定
リレーションシップとはデータベース経験者なら改めてご説明するまでもないのだが、簡単に言うとテーブル間の結合のことを意味する。Sisenseではパフォーマンスの関係上、シングルクエリーパスが推奨されているので、テーブルとテーブルを紐付けるキーは1つにするほうがベター。
今回、データモデルを構成するファイルは上で説明したとおり、「商品.csv」「商品分類.csv」「店舗.csv」「売上データ.csv」の4つ。
ファイルを指定したら、それぞれのデータの中身が解読され、こんなふうにテーブルが表示される。この時点ではまだデータそのものは取り込まれておらず、原始的なスキーマができている状態だ。
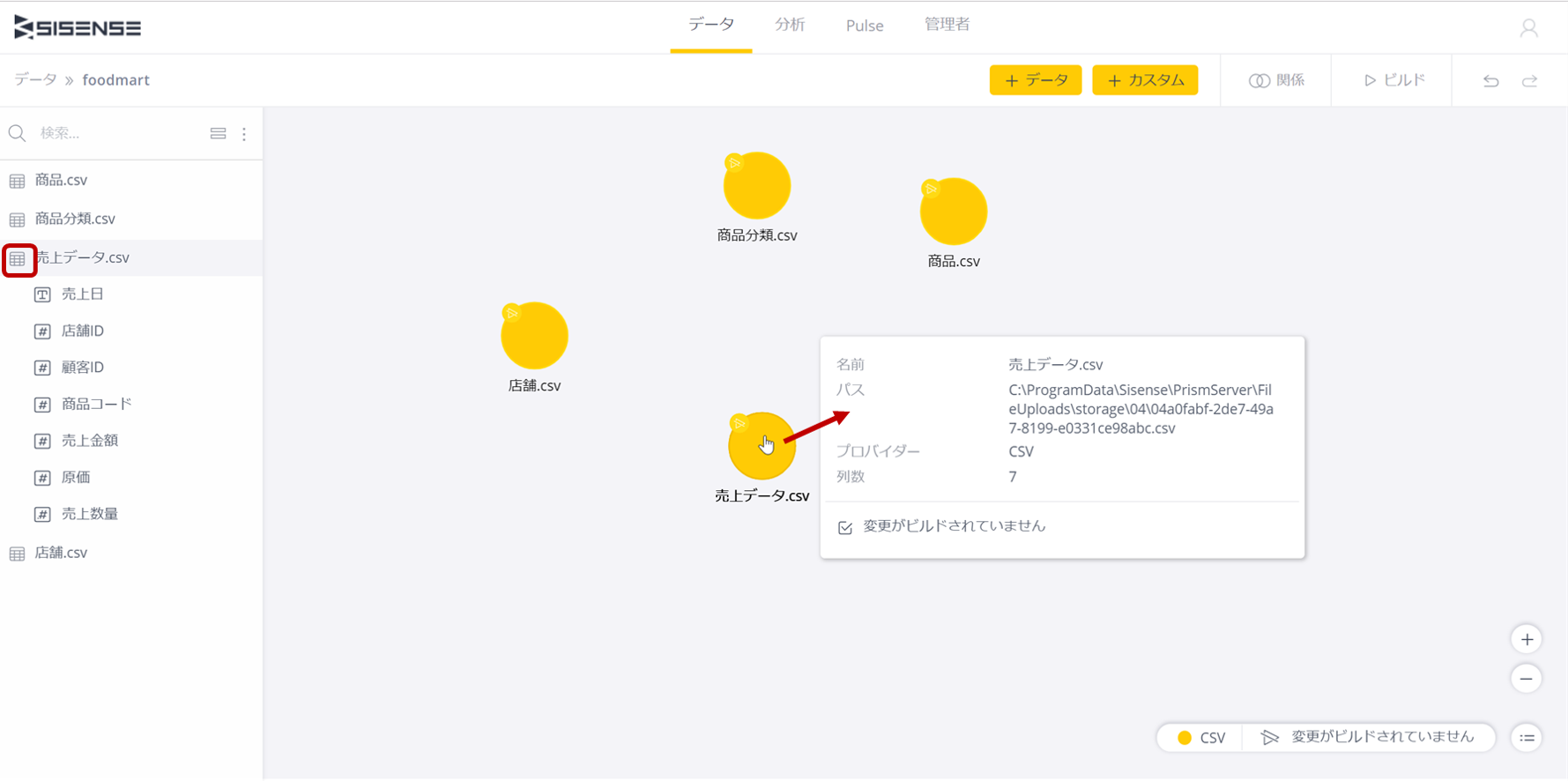
この画面、どっかのBIで見たような…知ってる人はBIマニアかQlikユーザだね。
おっと言っちまったか…
各テーブルをマウスオーバーするとデーブルの情報が表示される。また左のテーブルのアイコンをクリックするとテーブル内のフィールドが表示されるが、それぞれのフィールドの左のアイコンはデータ型を意味している。
今回はデータはCSVのため、データ型は自動判定されているが、売上日がテキストになっているため、日時に変更しておこう。
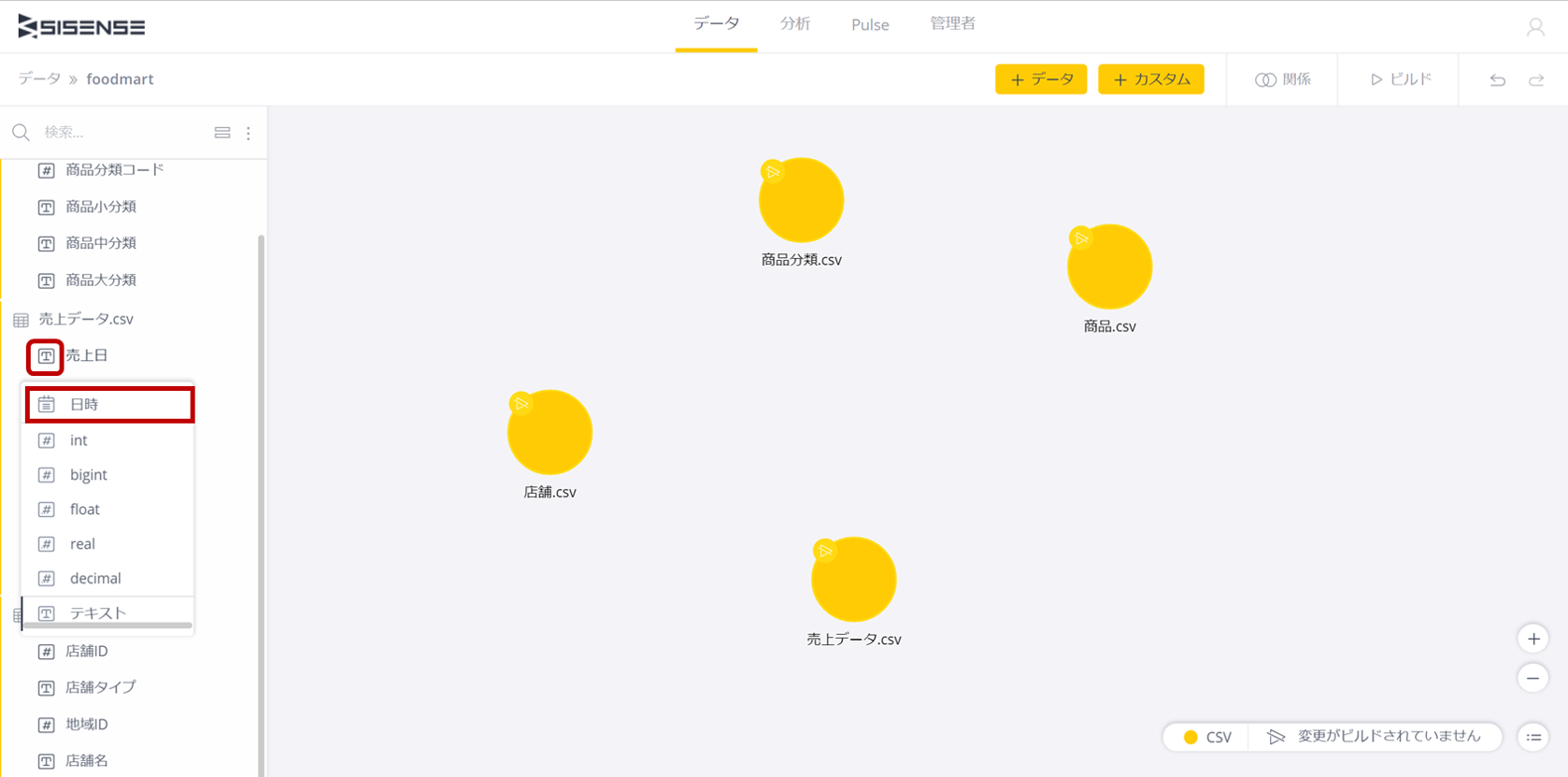
それでは、リレーションシップを設定していこう。
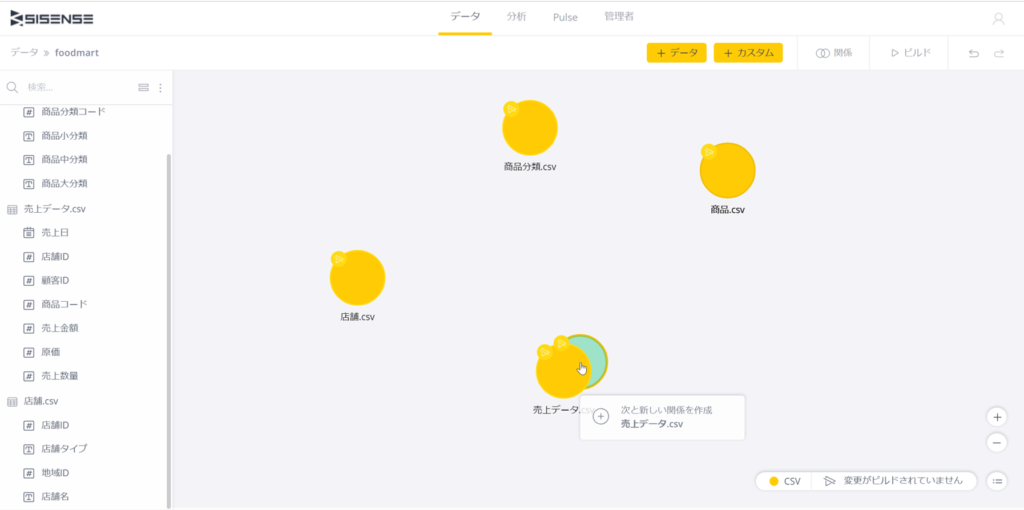
Data Designerでのリレーションシップの設定はテーブルをドラッグして行う。まず、商品テーブルを選択し、売上データテーブルへドラッグする。
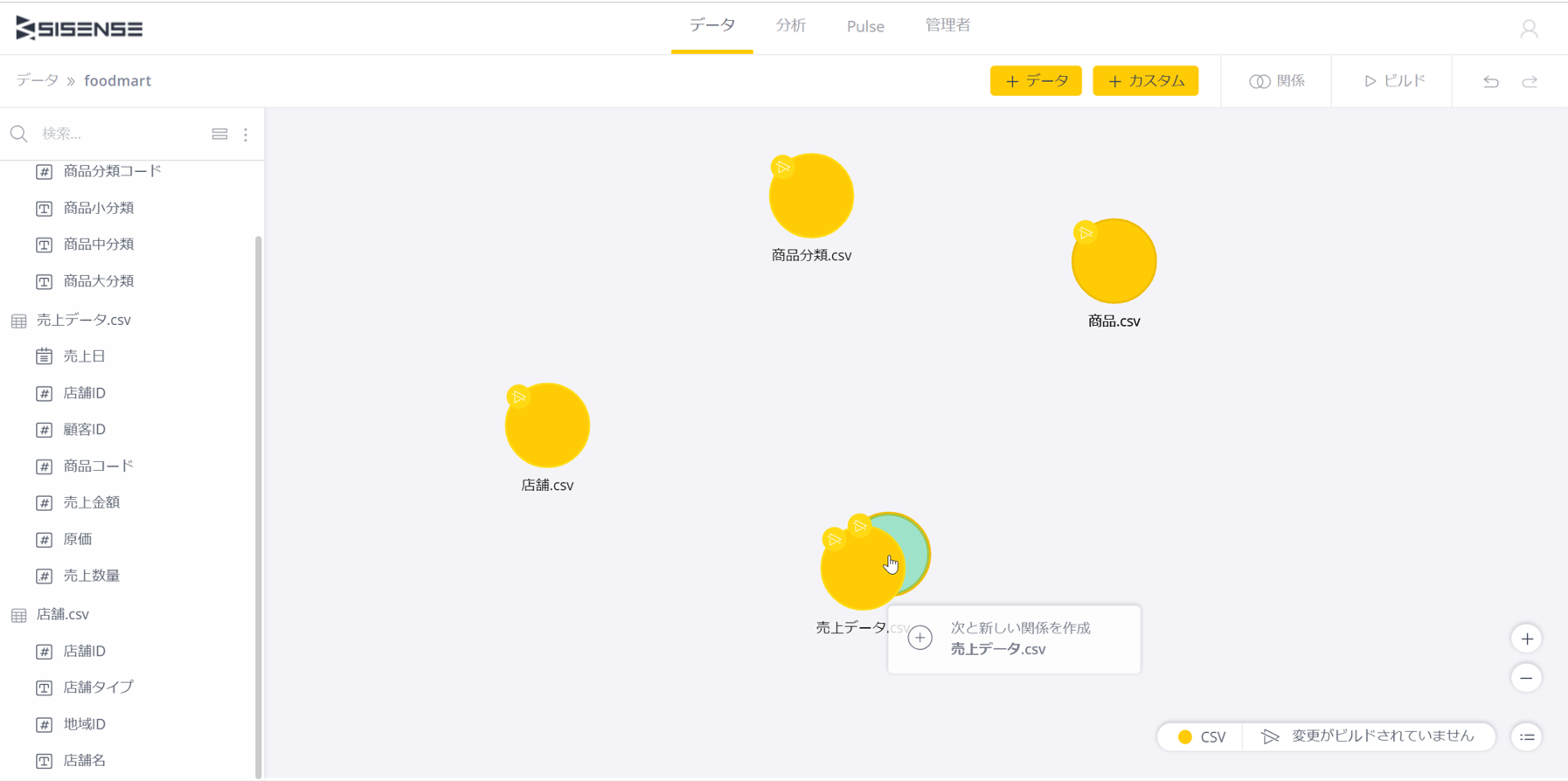
リレーションシップを設定しようとしている2つのテーブルは下記のように左側に並んで表示されるので、2つのテーブルを結合するためのキーをクリックして選択する。ここでは商品、売上データとも「商品コード」である。
商品テーブルを見た時に、結合に利用される「商品コード」を「プライマリーキー」と言い、それに対応する売上データテーブルの「商品コード」を外部キーと呼ぶ。
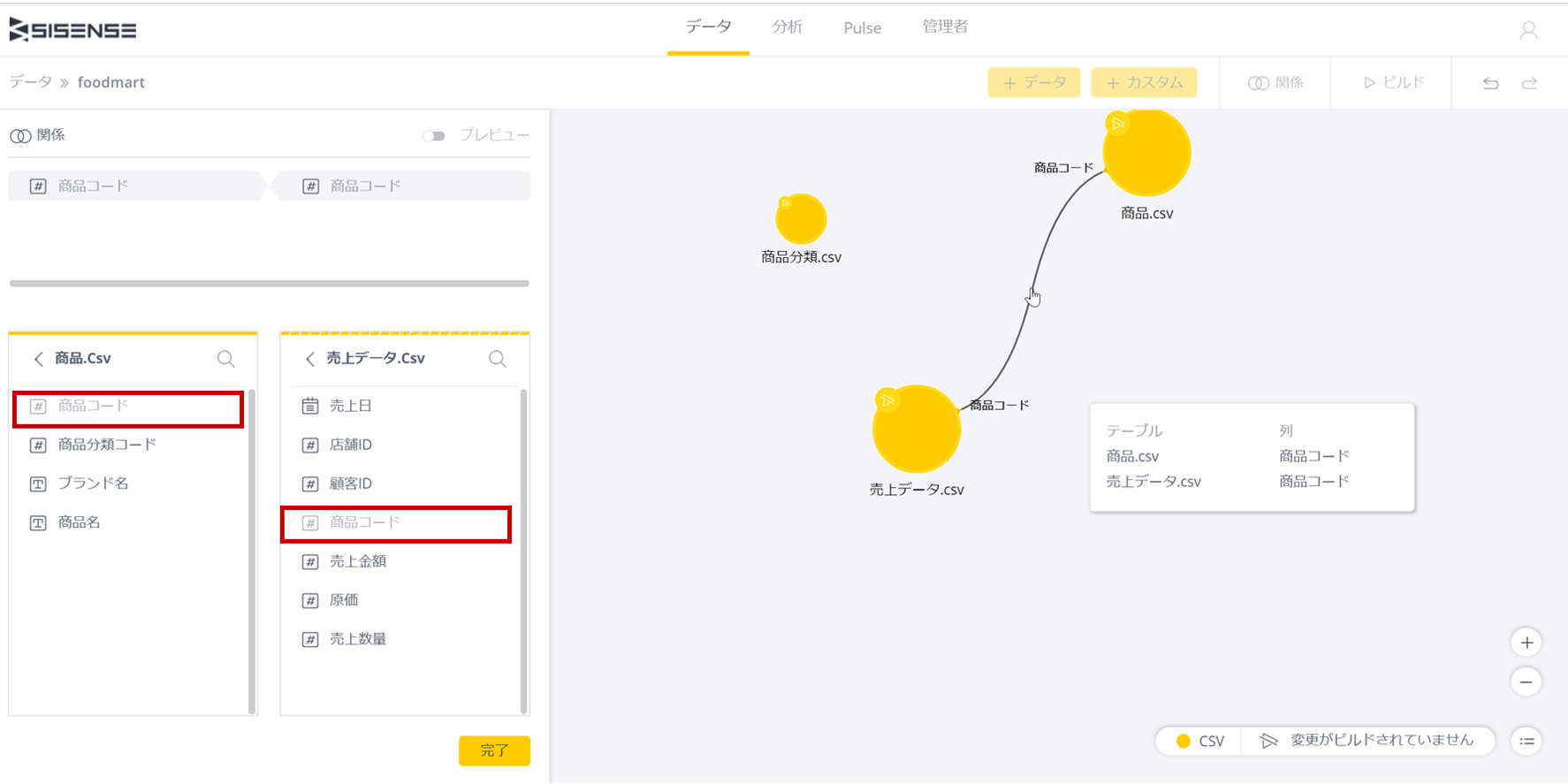
設定が完了すると画面左の2つのテーブルのフィールドリストの上に、リレーションシップを表すキー項目が2つ表示される。
また右側には2つのテーブルが線で結合され、それぞれのテーブルのキー項目が何かも表示される。
上記と同じ操作を他のテーブルでも行う。
・店舗テーブルと売上データテーブル(キーは両方とも店舗ID)
・商品テーブルと商品分類テーブル(キーは両方とも商品分類コード)
もし、結合に誤りがあった場合は、下記のように対応するキーの右にゴミ箱のアイコンが表示されるので、削除してリレーションを切っておく。
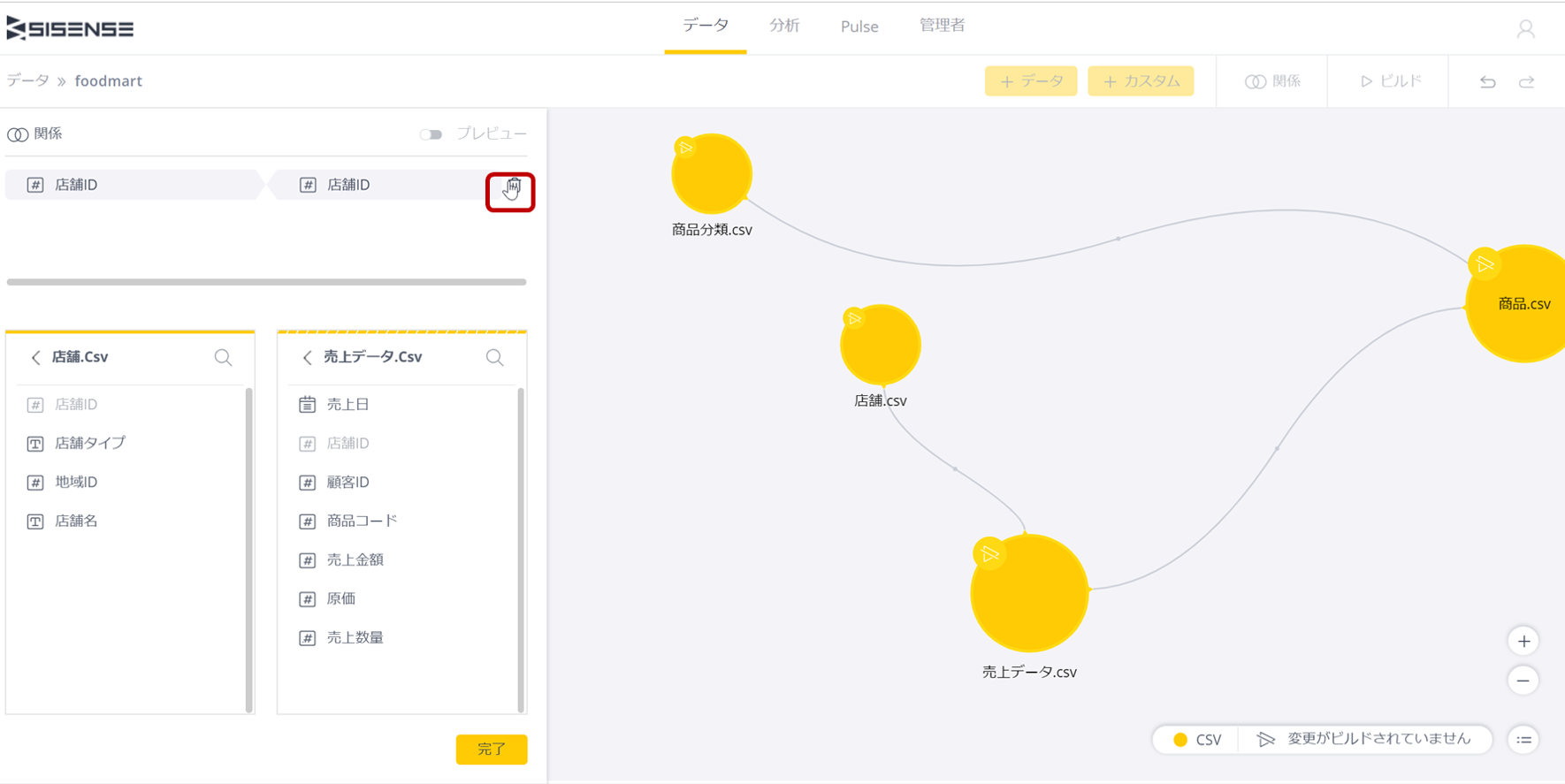
一旦、データモデルはできたかに見えるが、このデータモデルにさらに細かい設定を行ったり、修正を加えたりするにはテーブル名の右をクリックし、メニューを表示する。ここでは、テーブル名がファイル名のままなので、テーブル名を変更しておきたいよね。
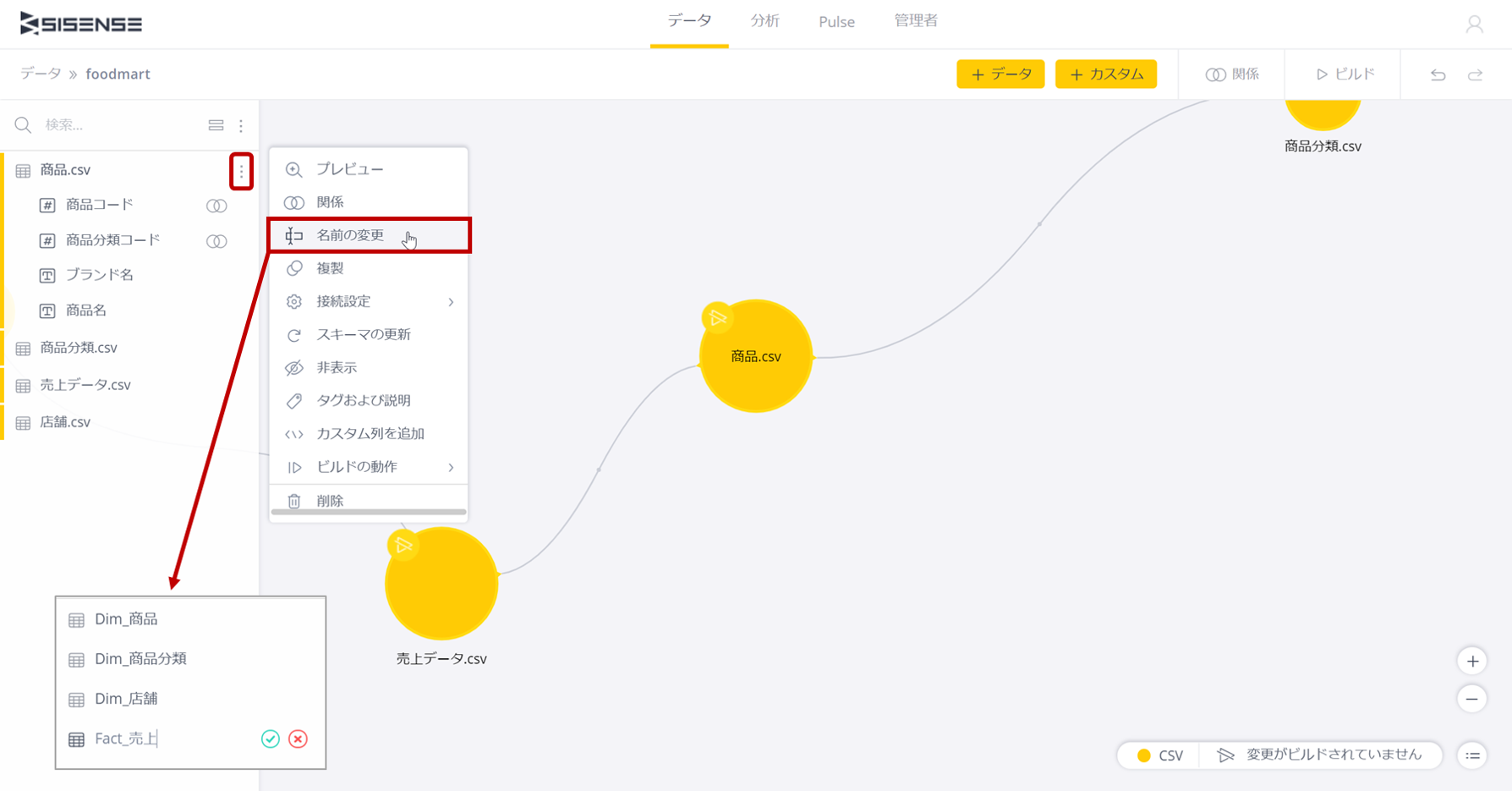
メニューから「名前の変更」を選択し、テーブル名を変更する。ここでは商品テーブルはディメンションテーブルなので、"Dim_"というプレフィックスをつけることにした。同様にファクトテーブルには"Fact_"のプレフィックスをつけることとし、以下のようにテーブル名を変更しておく。
・商品分類.csv → Dim_商品分類
・店舗.csv → Dim_店舗
・売上データ.csv → Fact_売上
下記のようにテーブルをクリックすると、テーブルの円を囲むようにアイコンが配置されるので、ここからテーブル名を変更することができる。ここで表示されるアイコンの機能は上記の操作で現れる機能と同じなので、どちらで行ってもいい。
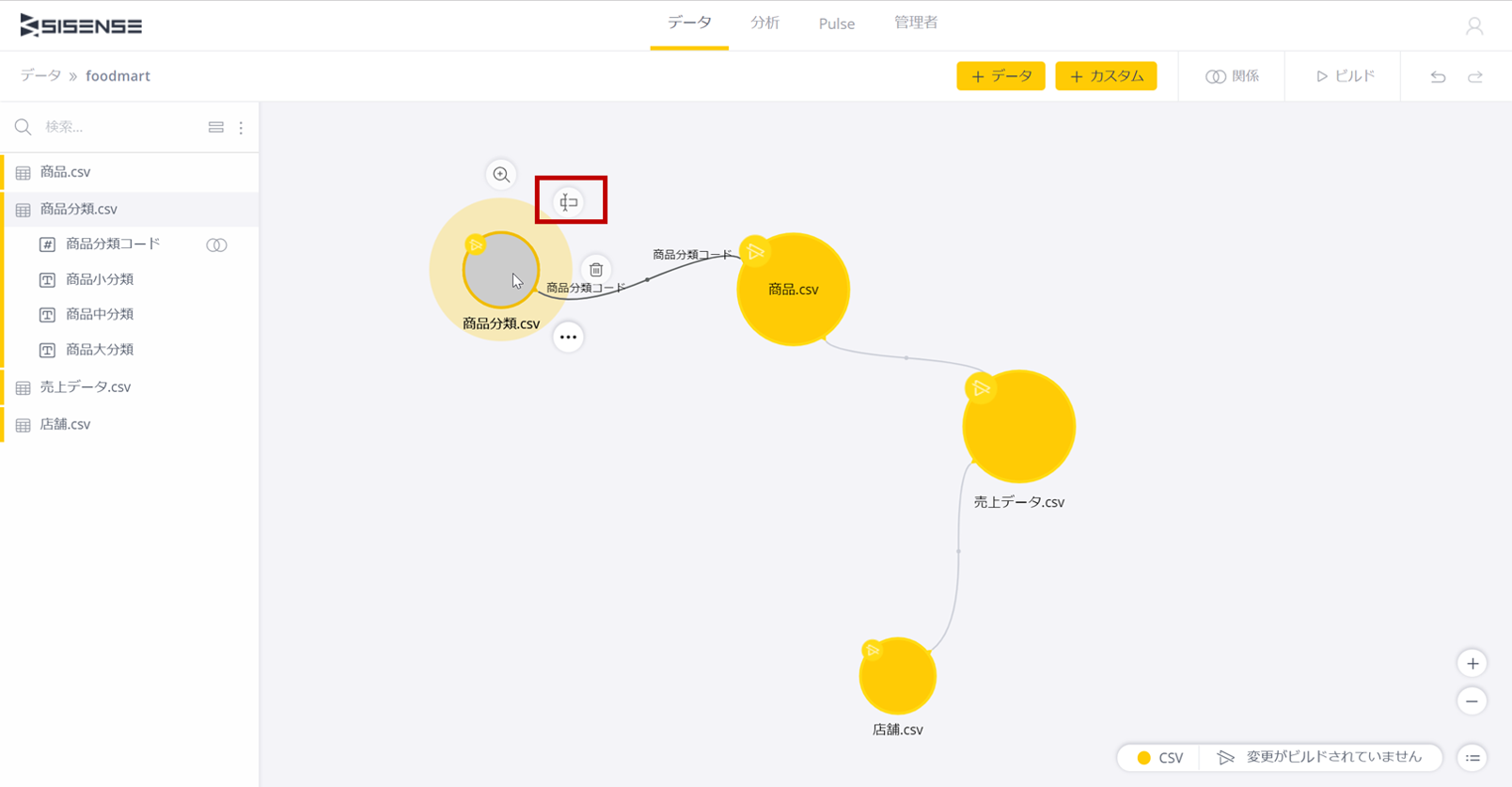
以上で簡単なデータモデルが完成した。しかしながら、まだデータは取り込んでいないので入れ物ができたに過ぎない。データを取り込むには次で説明する「ビルド」という処理を行う。
ビルド
Sisenseではデータの更新処理を「ビルド」と呼ぶ。ビルドは下記のように画面上のビルドボタンを押して行う。
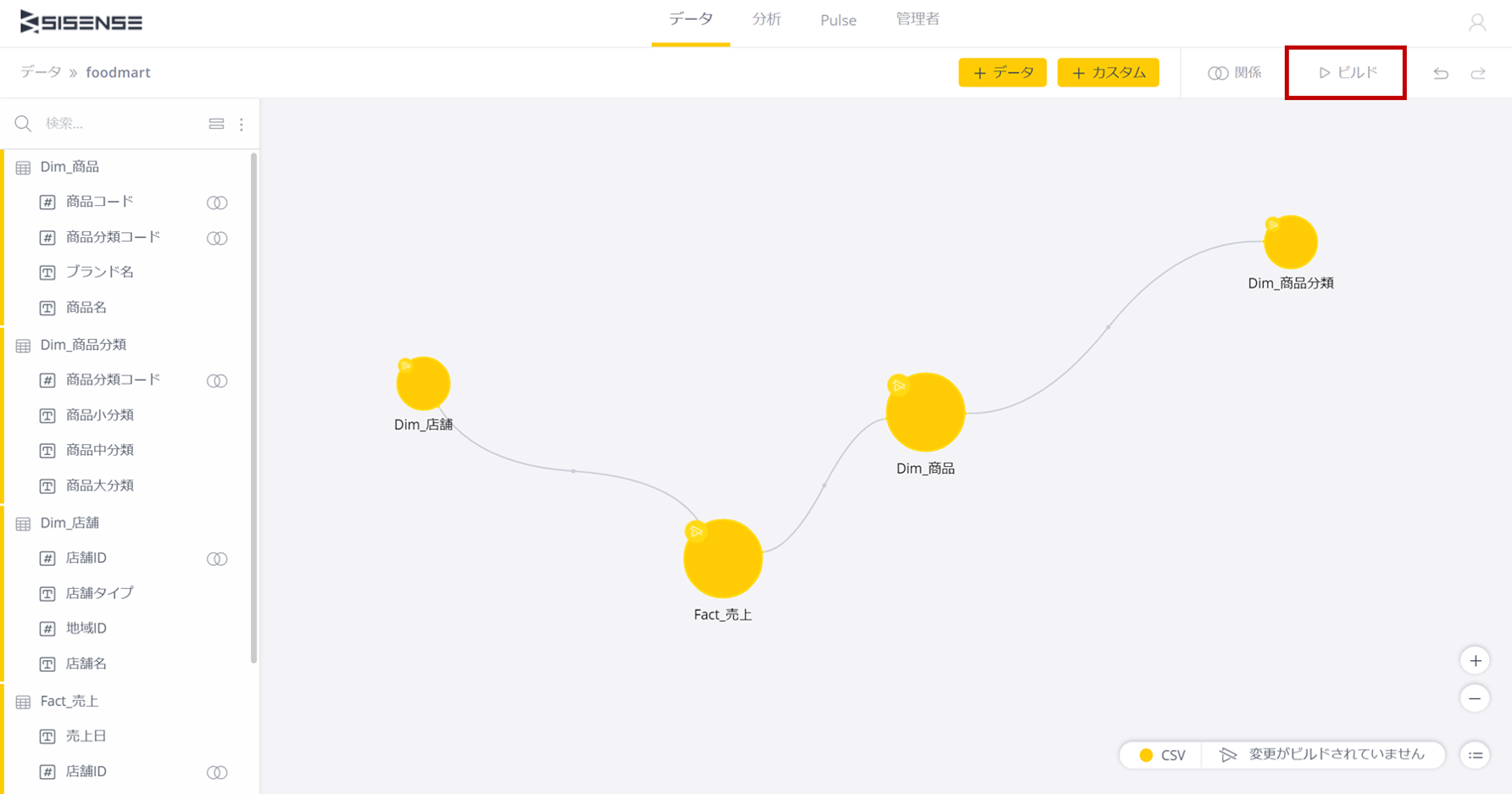
ビルドでは3つのモードがある。
・すべて置き換え
・変更のみ
・追加
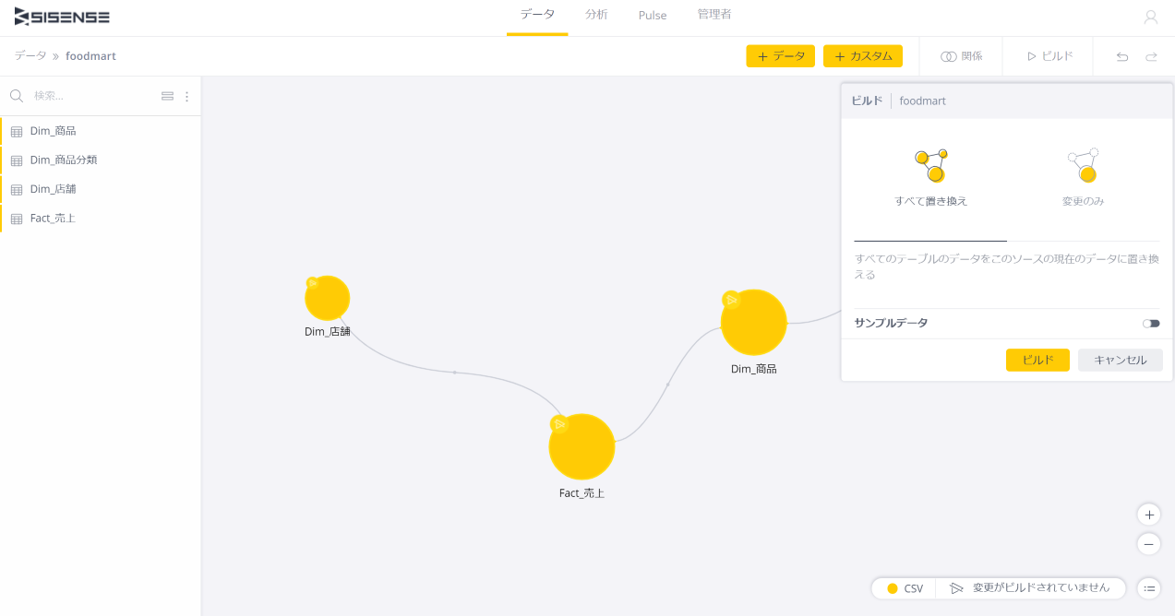
今回は初めて読み込むので「すべて置き換え」でビルドする。いわゆる「洗い替え」だ。
全件読み込むと時間がかかり、開発に支障を来すような場合は「サンプルデータ」をONにして、読み込む件数を抑えることも可能となっている。
ビルドを実行すると下記のようなダイアログで進捗を確認できる。
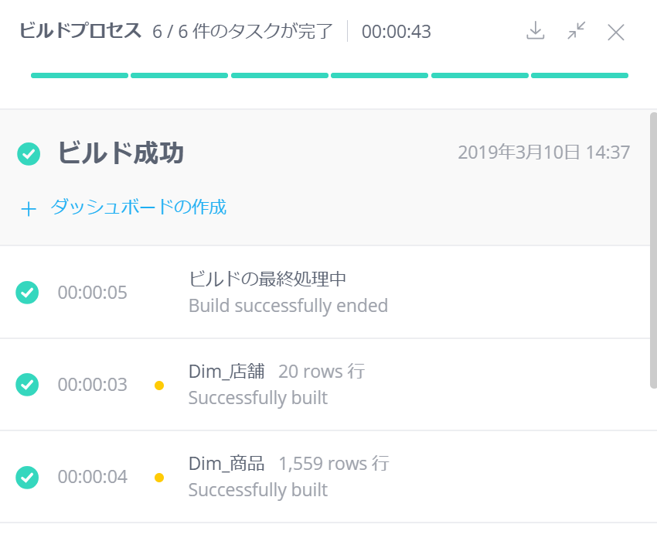
初期化と最終処理で少し時間がかかるように感じるが、データの読み込み自体は、高速なようだ。
データの確認
ビルドが終了したらデータの確認を行ってみよう。
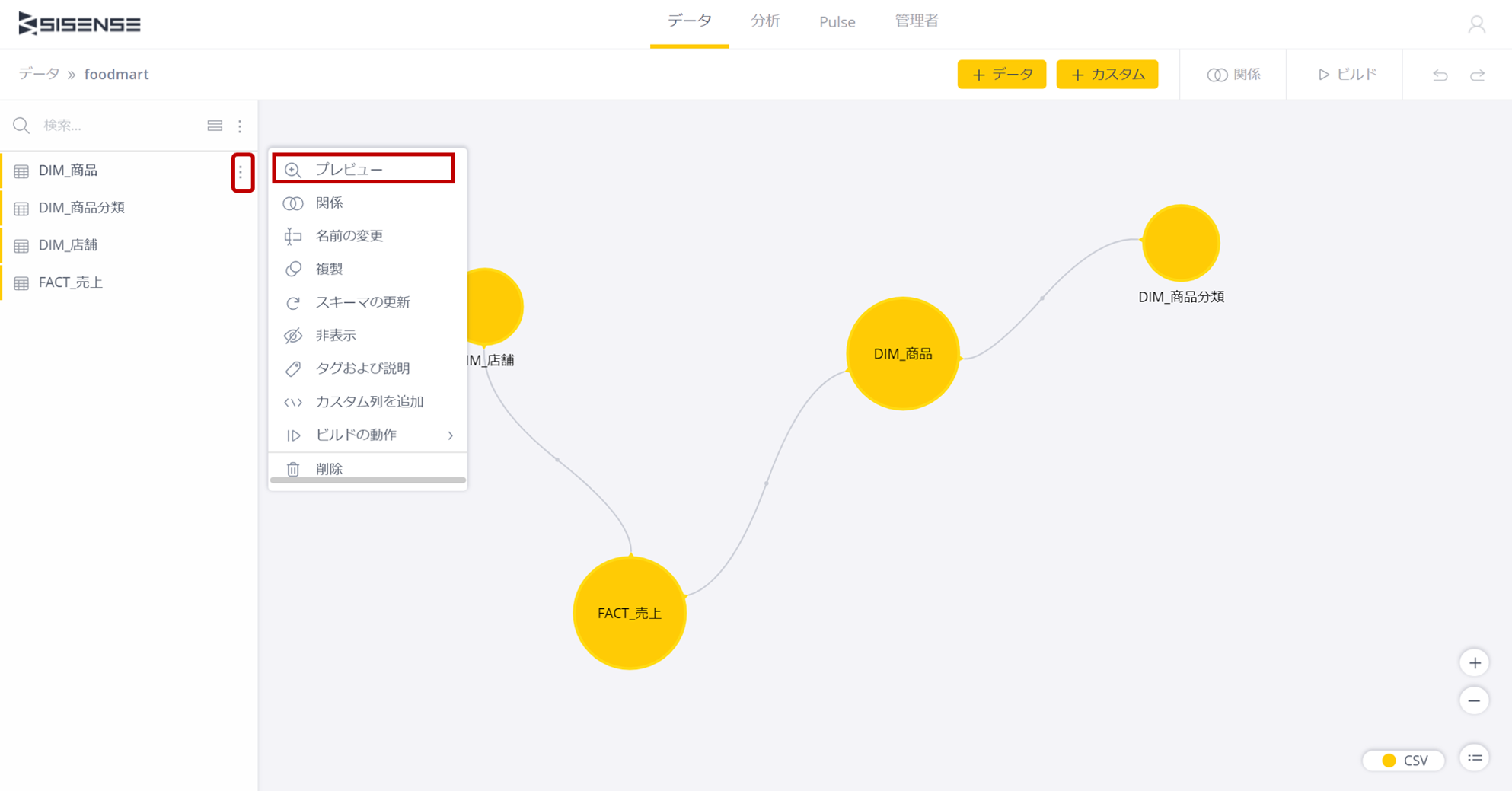
テーブル名の右でメニューを表示し、プレビューを選択して、テーブルの中身を確認してみる。
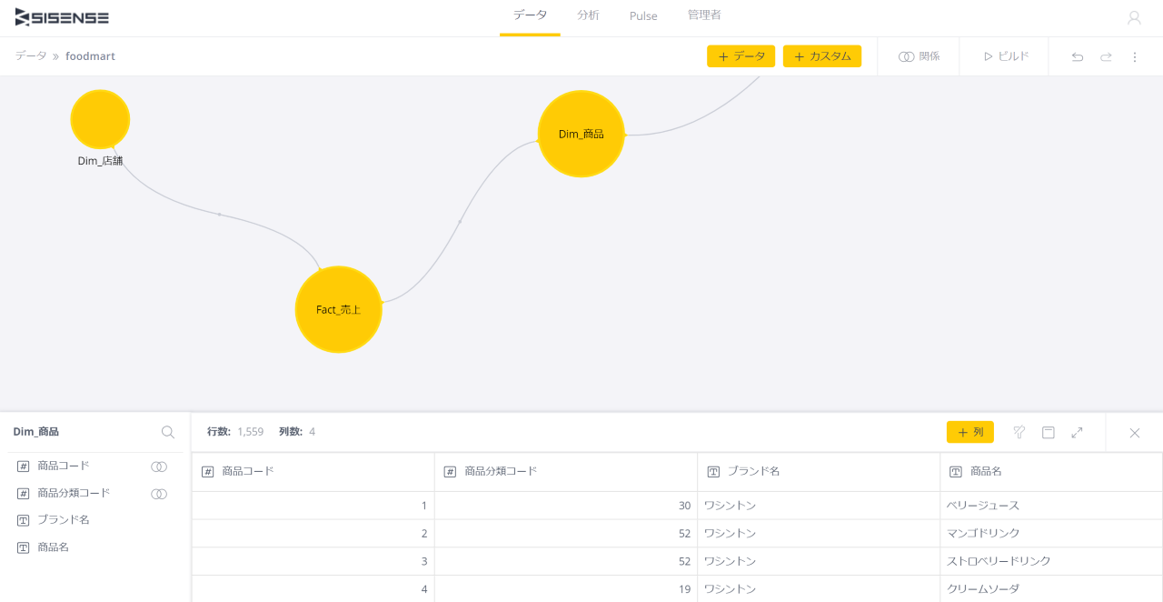
実際に取り込んだデータを確認し、データ型などの修正点があれば、さらに変更を加えていく。上記の画面では、最大化したり、プレビュー行数の設定、フィルタやソートなども設定できる。
全て設定や修正が完了したら、グローバルメニューの「データ」を選択し、最初に戻ろう。
以下のようにデータモデルが追加されていれば、すぐにダッシュボードを作成する準備ができているということだ。
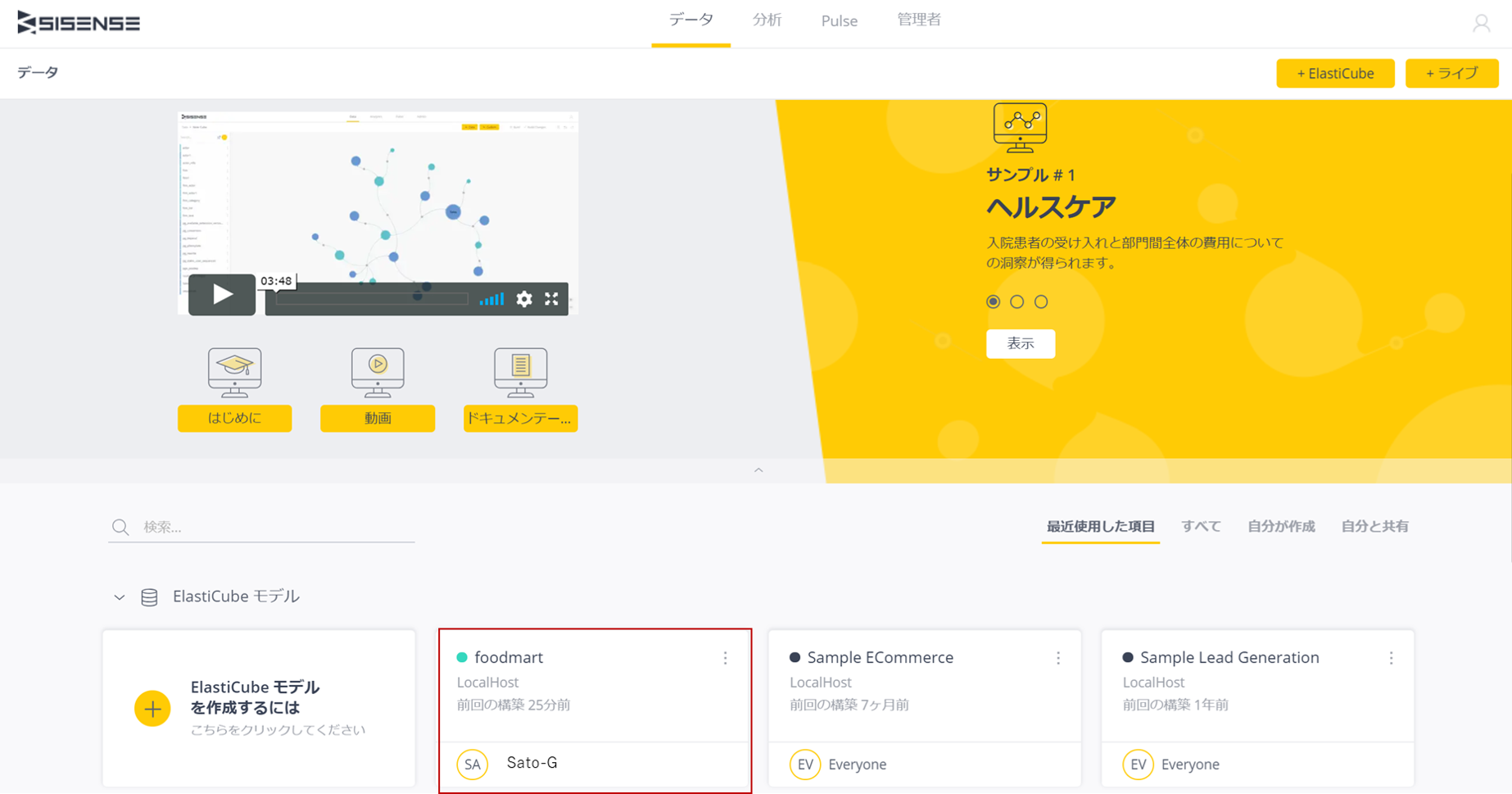
まとめ
以上、飛ばしながらData Designerを使用して簡単なデータモデルを作ってみた。操作は直感的にできて違和感はないし、Webブラウザ上でこれだけできれば全く問題なし。
また今回は基本となるモデルを作成してからビルドしたが、ビルドするまでの間、プレビューが効かなかったりするので、一旦ビルドダイアログの「サンプルデータ」をONにして読み込んでから作業したほうが効率がいいかもしれない。
次回は、引き続きData Designerを使用して、今回作成したものにさらにデータソースを追加したり、編集をしてみる。
Sisenseを体験してみませんか?
INSIGHT LABではSisense紹介セミナーを定期開催しています。Sisenseの製品紹介や他BI製品との比較だけでなく、デモンストレーションを通してSisenseのシンプルな操作性やプレゼンテーション機能を体感いただけます。