はじめに
本記事は以下の検証をまとめたものになります。
- Schema Detectionでソースファイルから取得したメタデータからテーブルを自動生成
- Schema Evolutionでソースファイルのカラム順の変更や増減を上記のテーブルに自動反映しデータを継続的にロード
先日のリリースで、Schema DetectionにJSONとCSVが対応し、データロード時にソースファイルのデータ構造の変化を自動でテーブルに反映するSchema Evolutionがプレビューになったので、この2つの機能を使って一生放置できる(と言っていいくらいの)データロードの仕組みを作ってみたいと思います。

https://docs.snowflake.com/en/release-notes/2023-06#schema-detection-for-json-and-csv-preview
環境
- DWH:Snowflake
- Storage:S3
- File:JSON
用語
Schema Detection
スキーマ検出は、内部・外部ステージにステージングされたファイルのスキーマ(カラムやデータ型などの情報)を自動的に検出します。それを可能にする関数がINFER_SCHEMAです。また、CREATE TABLE ... USING TEMPLATEを用いることで、検出したデータ構造を元にテーブルを生成することも可能です。
- 対応ファイル
- Apache Parquet
- Apache Avro
- ORC
- CSV(プレビュー)
- JSON(プレビュー)
https://docs.snowflake.com/ja/sql-reference/functions/infer_schema
Schema Evolution
スキーマ進化(と呼ぶことにします)は、異なるデータ構造のファイルがステージングされた場合でも、エラーで止まることなくデータを継続して取り込むことができます。データの活用の幅が広がりつつある中、ビジネスの性質によってはデータ構成が頻繁に変更されることも予想されます。この機能を有効し、データ構造の変更にあわせてスキーマを進化させることで、継続的なデータパイプラインを実現します。方法は対象テーブルに対してENABLE_SCHEMA_EVOLUTIONを有効にするだけです。
https://docs.snowflake.com/en/user-guide/data-load-schema-evolution
事前準備と検証概要
事前準備
- 検証用S3フォルダの作成
- ストレージ統合と外部ステージの作成(本記事では割愛)
- 検証用データの作成(ChatGPTにお願いしました。内容は記事の末尾に)
検証概要
- データ形式:JSON
- 列は文字列と数値を交互に設定
- ケース1:10カラム10レコードのJASONファイル
- ケース2(列追加パターン検証):20カラム20レコードのJSONファイル
- ケース3(列欠損パターン検証):15カラム15レコードのJSONファイル
file1.json
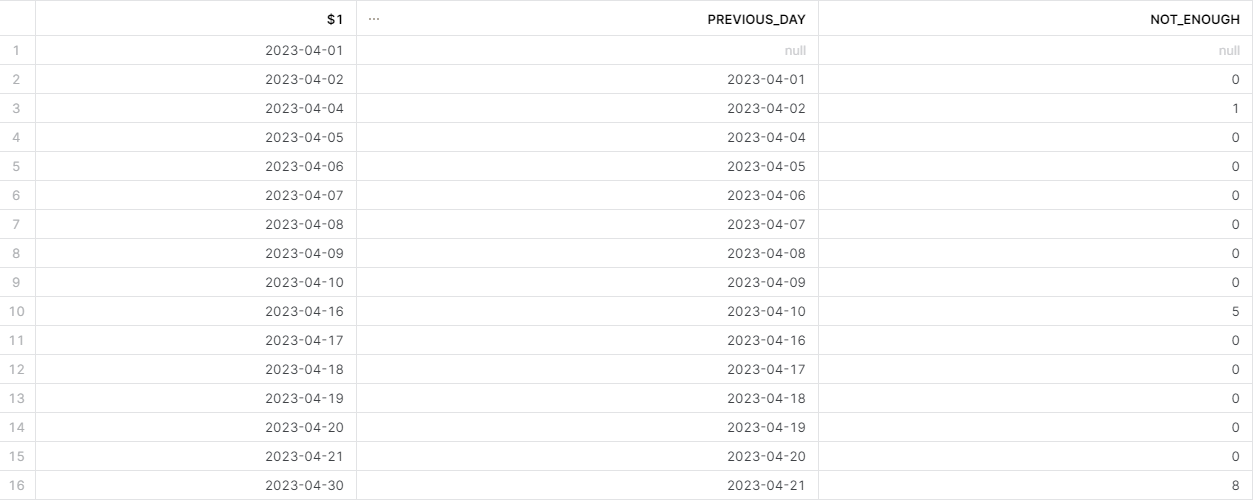
検証結果(ケース1)
file1.jsonをアップロード
s3にfile1.jsonをアップロード。
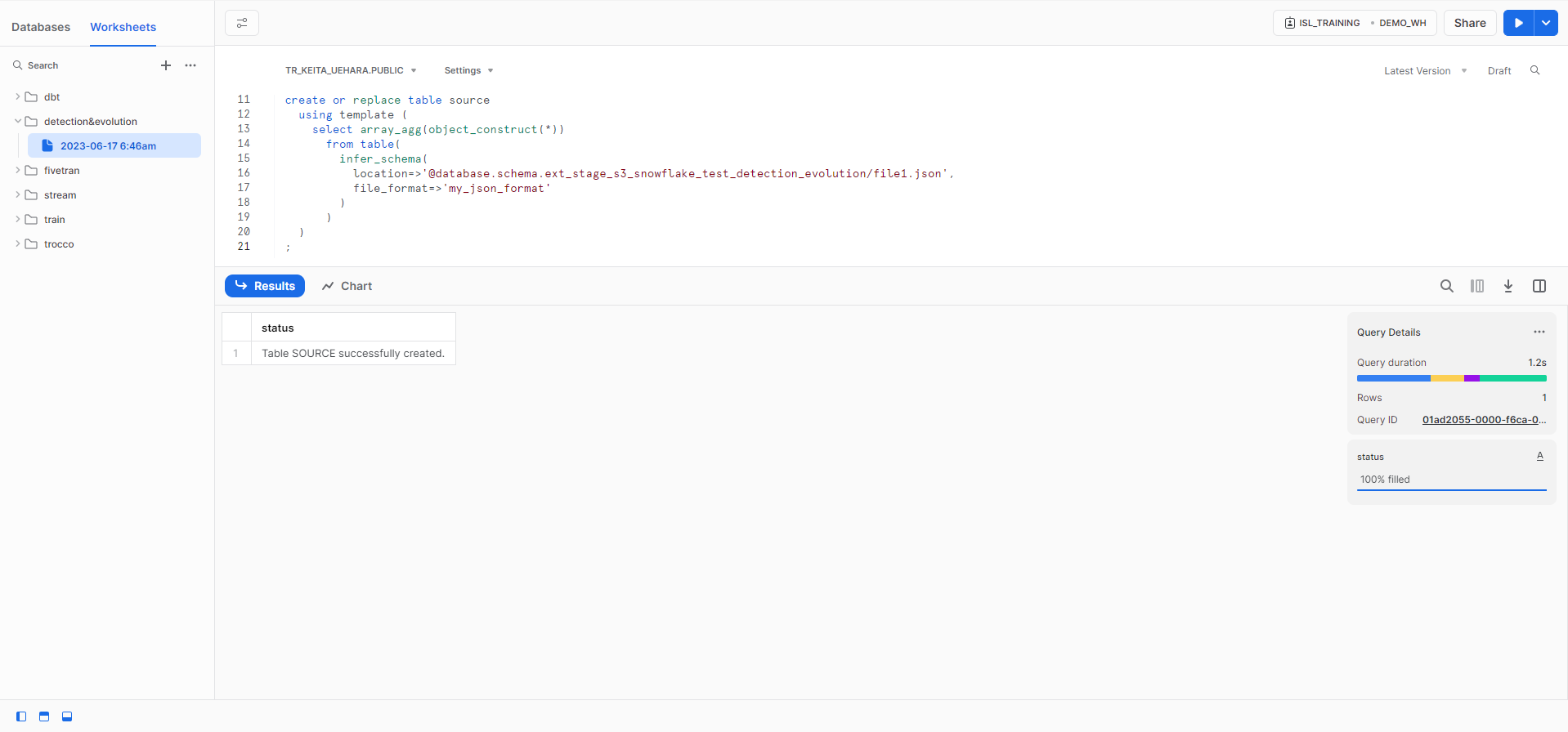
INFER_SCHEMAを使用したテーブル自動作成
json用ファイルフォーマットを作成し、INFER_SCHEMA関数を用いてテーブル構造を自動生成。
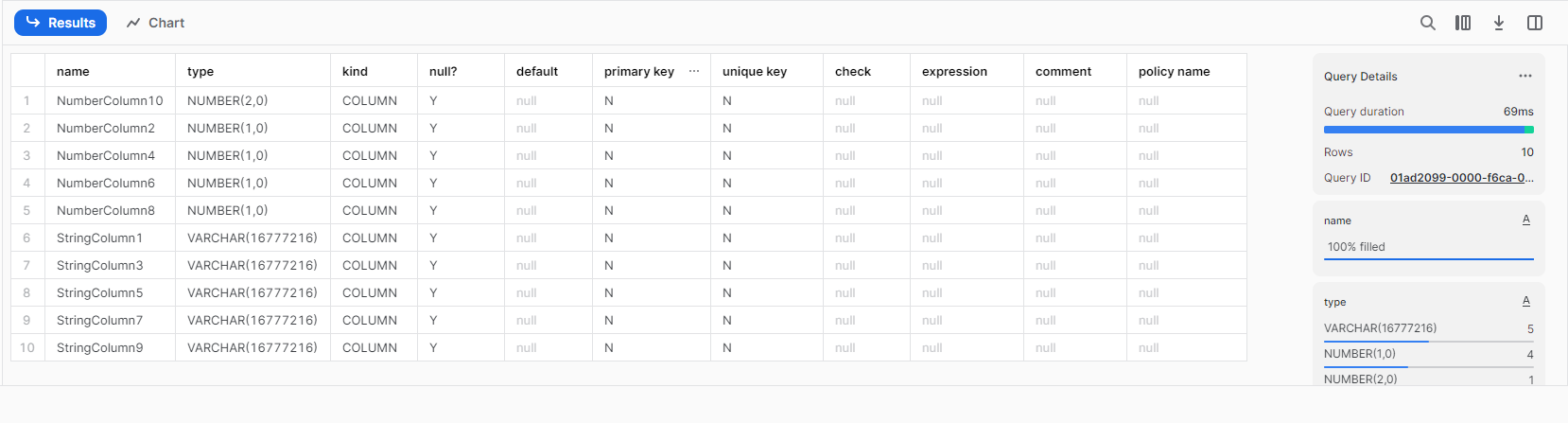
現在のテーブル構造を確認。
file1.jsonをテーブルにロード
外部ステージを経由して、S3のfile1.jsonを一括ロード。file1.jsonをもとに生成したテーブル構造なので特に問題なくロードされる。
検証結果(ケース2)
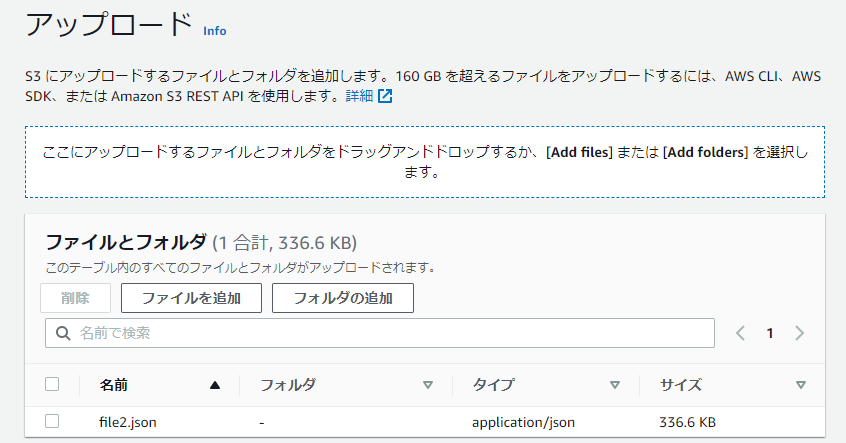
file2をアップロード
10カラムを追加したfile2.jsonをs3にアップロード。
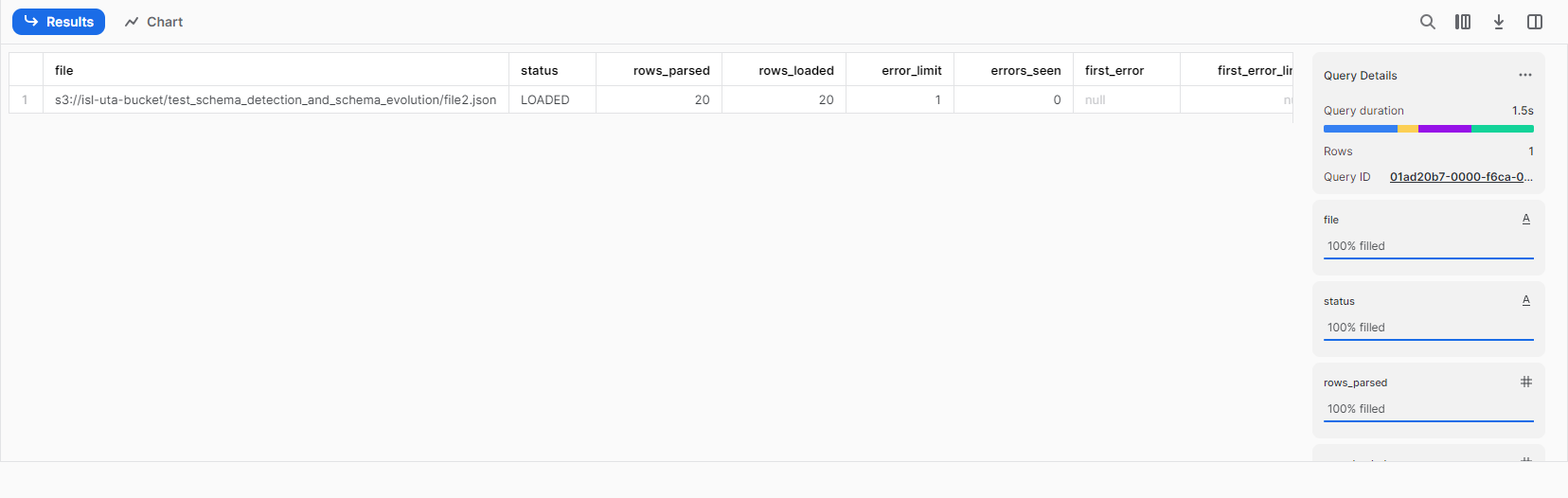
file2.jsonをテーブルにロード
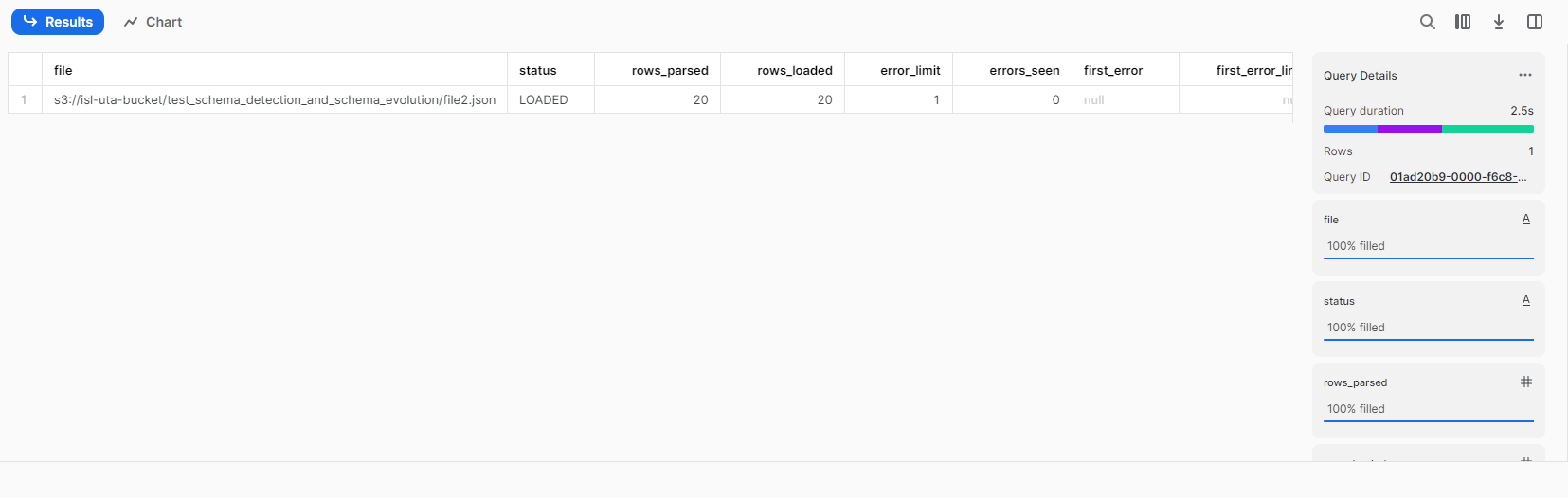
一つ目のファイルと同様にfile2.jsonを一括ロード。エラーは起きず実行される。
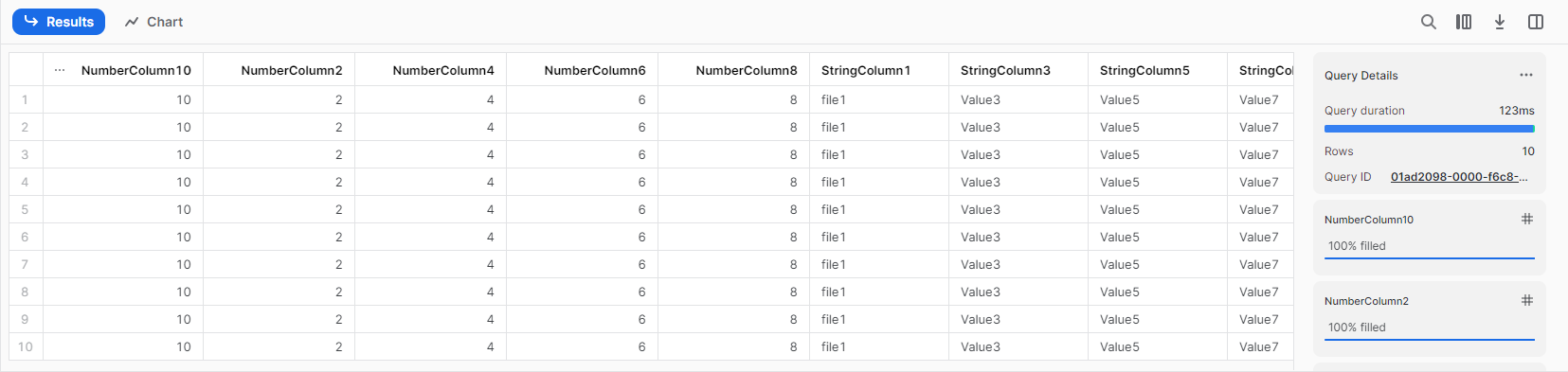
しかし、テーブル構造はそのまま、データを確認すると既存カラムのみのデータだけがロードされていました。
TimeTravelで時を戻します。

SchemaEvolutionの有効化
ここで、列を自動追加されるようにENABLE_SCHEMA_EVOLUTIONを有効にします。
※この操作にはテーブルの所有権を持つロールもしくはEVOLVE SCHEMA権限の付与されたロールが必要
再度、file2.jsonを一括ロード。エラーは起きず実行される。
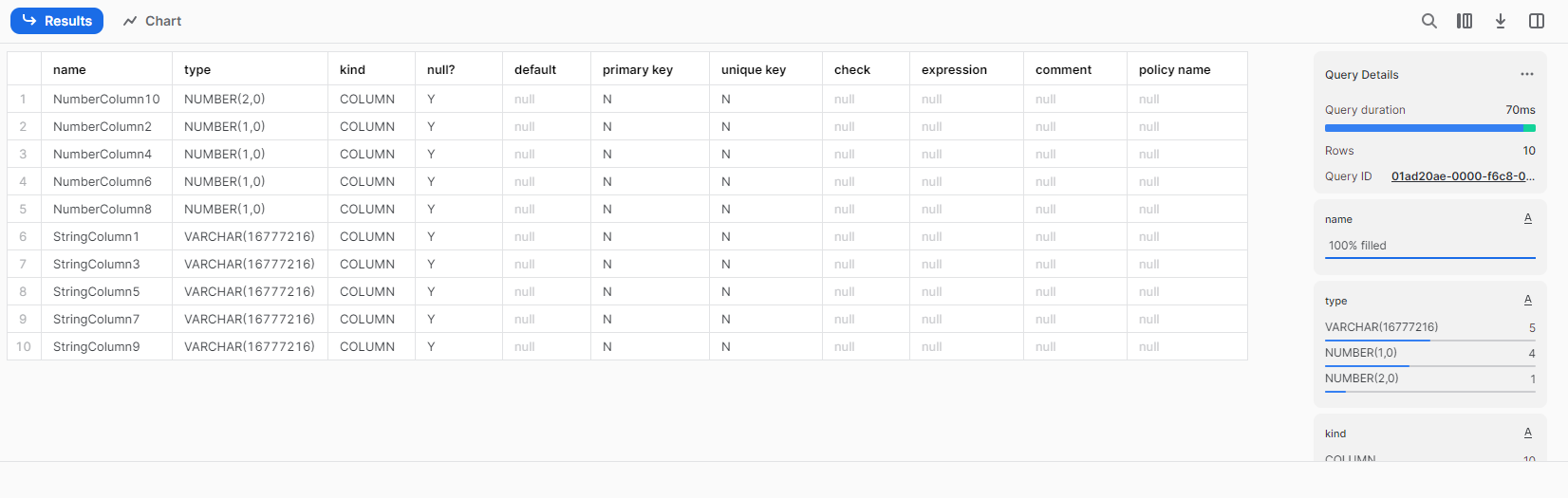
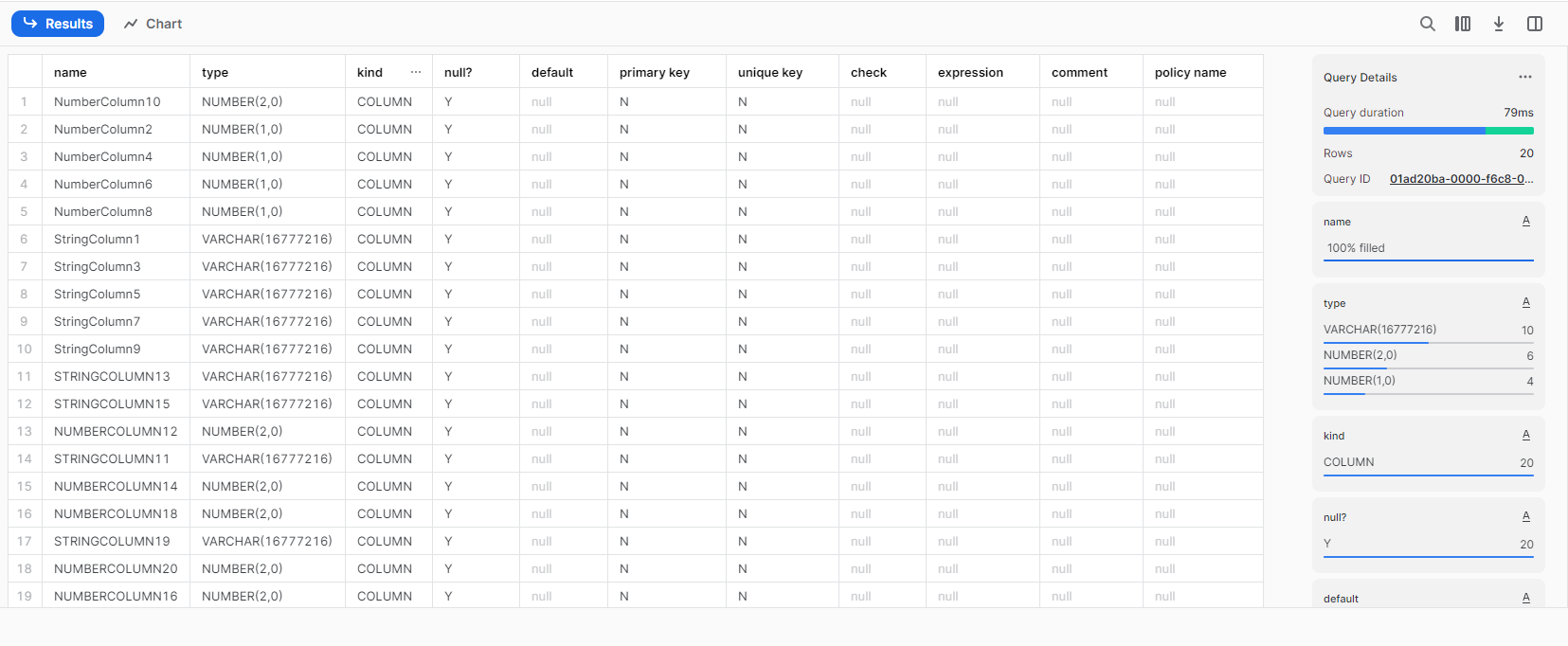
テーブル構造を確認すると、、
file2.jsonにしかないカラムが自動的に追加されています。
※カラム名を見てあれ?と思いますが、詳細は記事下の注意点に記載しています。
file1とfile2のデータを一部比較すると、file1では追加されたカラムはnullで埋められています。

検証結果(ケース3)
file3.jsonをアップロード
今度はカラムが20から15に列が欠損したケースを想定してロードを行います。

各ファイルのデータを比較すると、カラムが減少した場合もnullで埋められます。

注意点
SchemaDetectionとSchemaEvolutionを組み合わせた継続的なデータパイプラインを調査した中で、いくつか注意する点があったので、まとめておきます。
- 新しいデータファイル側で欠落しているカラムからNOT NULL 制約が自動的に削除される。
- JSONファイルで一括ロードを行う際は、MATCH_BY_COLUMN_NAMEオプションが必須。
- データのロードで実行するロールは、テーブルのEVOLVE SCHEMA権限
またはOWNERSHIP権限が必要。 - SchemaEvolutionを使用できるロードは、COPYINTOまたはSnowpipe
のみで、INSERTやSnowpipe Steramingはサポートされていない。(2023/06/17現在) - COPY操作ごとに最大10列の追加または1スキーマ以上の進化に制限される。(拡張したい場合はSnowflakeサポートに連絡)
また、SchemaEvolutionのドキュメントには載っていませんでしたが、カラム名の自動設定に関する挙動には注意が必要だと感じました。
- SchemaDetection(INFER_SCHEMA)で自動設定されるカラム名はファイルのまま(小文字大文字やアルファベットなど)
- SchemaEvolutionで自動設定されるカラム名は大文字に変換される
終わりに
本記事では、外部ステージに配置されたJSONファイルをSchema Detection(INFFURE_SCHEMA)で取得したメタデータを検出し、create table … templateで自動生成。テーブル生成後、外部ステージに配置されたファイルの列が増減してもパイプラインを停止させることなく、自動で列(カラム)を追加するパイプラインを構築しました。
システム要件やビジネス要件が多様化し、様々なファイルが上流から流れてきます。カラムが100を超えるようなソースデータがあると、データ定義を確認して手打ちでDDLを発行するのは大変な作業ですが、Schema Detectionを用いることでソースデータにあったテーブル定義で作成できます。
また、Schema Detectionでテーブルを作れたはいいものの、上流側でカラムが増えたり減ったりするとデータパイプラインを一旦停止させて、テーブルやタスクなどを修正する必要がありました。しかし、上記のテーブルをSchema Evolutionに対応させることで、データロードのタイミングでカラムを自動で追加し継続的にロードされるようになりました。
これで、上流側とのいざこざもなくなり(減り)、よりデータ分析基盤の強化に注力できるようになるはずです。連携するデータが多かったり、データ構造が頻繁に変わるようなデータを扱う場面に遭遇した際には、ぜひSchema DetectionとSchema Evolutionを試してみてください!
参考
INFER_SCHEMA | Snowflake Documentation
Table Schema Evolution | Snowflake Documentation
データのロードの概要 | Snowflake Documentation
CREATE TABLE | Snowflake Documentation
検証データ生成スクリプト
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。