Snowflake Python UDFについて色々試してみた!
本記事はSnowflakeアドベントカレンダー9日目の記事となります。
概要
SnowflakeではUDFs(ユーザー定義関数)を定義して、システム定義関数では実現できないようなデータ加工を実現することができます。 UDFを利用することで、柔軟にデータ加工ができるため、データ加工をSnowflake上のみで完結させて、シンプルなデータ基盤を構築するようなことも可能かと思います。
UDFは、様々な言語で記述可能ですが、Python でも記述することができるようになりました。以下に、UDFとして利用可能な言語と、それぞれの特徴をまとめてみます。
| 言語 | 表形式 | ループ・分岐 | プリコンパイル | インライン | 共有可能 |
|---|---|---|---|---|---|
| SQL | ◯ | × | × | ◯ | ◯ |
| JavaScript | ◯ | ◯ | × | ◯ | ◯ |
| Jave | ◯ | ◯ | ◯ | ◯ | × |
| Python | ◯ | ◯ | ◯ | ◯ | × |
個人的な意見ですが、PythonはJavaやJavaScriptよりも、プログラマ以外の方がとりつきやすいと思いますし、SQLが対応できないループや分岐が利用できることから、Snowflakeでのデータ加工がより身近になり、対応可能な要件も増えたのではないかと思っています。
そこで、本記事ではPython UDFについて、いくつかの機能を使ってみた結果をまとめていきます。主な検証内容は以下の通りです。
- 基本的な使い方
- エラー処理の取り扱い
- 内作モジュール/内作パッケージの利用
- 外部パッケージの利用
- UDTFs の利用
少し分量が多いですが、気になる部分だけでもご一読いただき、参考になれば幸いです!
基本的な使い方
UDFはCREATE FUNCTION ステートメントにより作成します。必須の指定内容は以下の通りです。
- SQLから利用する際のSQL関数名
- UDF呼出しの際のハンドラー関数
- 引数/戻り値の型
- 利用するPythonのバージョン
- 利用するPythonのコード
「ハンドラー関数」とは、UDFの呼出しの際に呼び出される関数のことです。Pythonソースコードのうち、「ハンドラー関数」以外のコードについては、UDFの初期化時に1回のみ実行され、毎回実行されるわけではありません。引数/戻り値の型はPythonとSnowflakeの間で型マッピングがあるので、対応がとれるように指定します。Pythonのバージョンは、現状「3.8」がサポートされているようです。
利用するPythonコードの指定は、以下のいずれかの方法を指定します。
- インラインコード
- CREATE FUNCTIONステートメントの一部として、Pythonソースコードを指定する
- ステージからアップロード
- Snowflakeの内の既存のPythonソースコードの場所を指定する
インラインコードを利用した場合の定義の例は、以下のようになります。
一方、ステージからアップロードする場合の定義の例は、以下のようになります。
上記は、ユーザーステージに配置された「sleepy.py」というモジュール内にある、「snore」という関数をハンドラー関数とする例となります
本記事での以降の検証は、基本的にインラインコードを利用した場合を用います。
その他、詳細な利用方法については、公式ドキュメントを参照ください。
エラー処理の取り扱い
Pythonの「try-except」を用いて、ハンドラー関数内でエラーをキャッチ可能です。例外をキャッチしない場合、Snowflakeが例外のスタックトレースを含むSQLエラーを発生させます。
try-exceptなしで例外発生
具体的な動きを見ていきます。まずは、以下のように意図時に例外をキャッチせずに発生させるUDFを作成してみます。
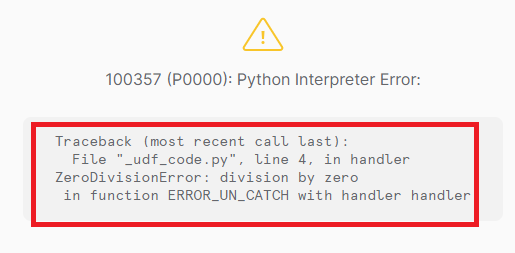 図の通り、例外の内容を含むスタックトレースを、エラーメッセージとして表示してくれました。すごく便利です。
図の通り、例外の内容を含むスタックトレースを、エラーメッセージとして表示してくれました。すごく便利です。
エラーメッセージに引数の内容を含める
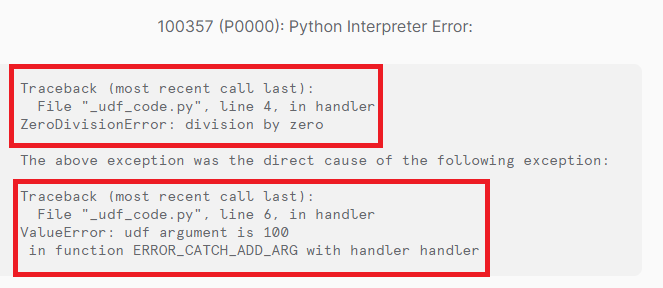
エラーメッセージに、UDFに指定した引数の内容が含まれていると、デバッグが捗るかと思います。引数の内容を含めたい場合、関数全体をtry- exceptで囲んで、引数の内容を含む例外を改めて発生させます。
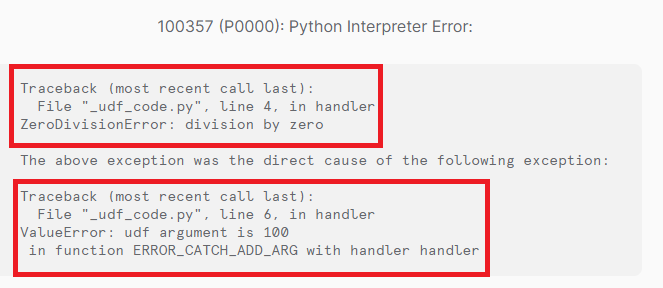
スタックトレースが2つ表示されています。上部が直接の原因となった例外で、下部で引数の内容を表示したメッセージが表示されています。
例外キャッチ後、fromの後にNoneを指定すると、キャッチ後のメッセージのみ表示してくれます。
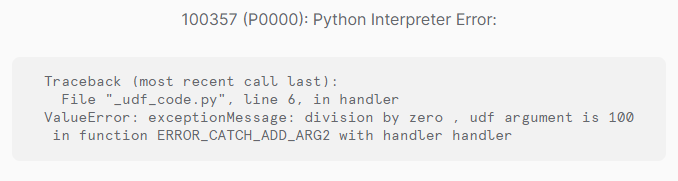
例外発生しても、処理を継続する
SnowflakeでのTRY_TO_XXX関数のように、エラー時に処理を中断せずに、NULLやデフォルト値を利用したい場合もあるかと思います。 UDFで上記を実装する場合、例外をキャッチした後にNoneやデフォルト値をリターンします。
例外が発生した場合も、NULL値として処理が継続できました。
タスクやプロシージャからコールする
個人的な利用法としては、UDFはタスクやプロシージャ経由で利用することが多いです。そのため、タスクやプロシージャからUDFをコールした際の挙動も確認してみます。
例外を発生させるUDFをコールするタスクを作成し、実行します。
information_schema.task_historyでエラーの内容を確認してみます。

error_messageカラムに、UDFのエラーが格納されていることが確認できました。ERROR INTEGRATION を利用すれば、SlackなどにUDF内で発生したエラーを通知することも可能です。プロシージャ経由でコールした場合も、UDFのエラー内容はしっかりと確認できました。
自作モジュール/パッケージのimport
過去開発で作成したモジュールや、パッケージをUDFで利用したい場合もあるかと思います。Python UDFでこのようなことを実現するための方法を調べてみました。
モジュール
こちらは、公式ドキュメントに記載がある「UDFハンドラーを使用したファイルの読み取り」を利用すれば、簡単にできそうです。
公式ドキュメントには、以下の記載があります
CREATE FUNCTIONのIMPORTS句でファイルのステージ位置を指定すると、SnowflakeはステージングされたファイルをUDF専用のインポートディレクトリにコピーします。ハンドラーコードはそこからファイルを読み取ることができます
上記の内容を初歩的な内容から確認していきます。Pythonのモジュール検索パスは、sys.pathで確認ができますので、UDF内でのsys.pathの内容を確認してみます。
※事前に「python_udf_stage」という内部ステージに、「sleepy.py」というモジュールをアップロードしています。
結果は、以下のようになります。
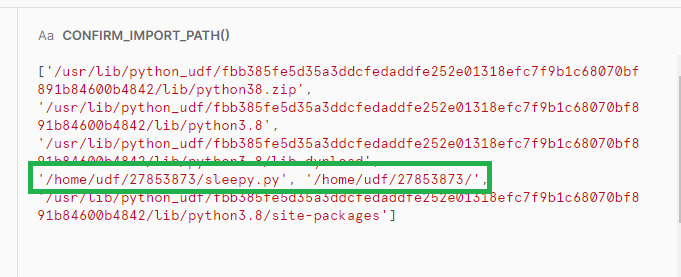
標準モジュールのパスに加え、「/home/udf/XXXXXXX」というパスが追加されており、そこにIMPORTS句で指定したモジュールも含まれています。別のUDFでも確認したところ、28853873という数値は、UDF毎に異なるので、UDF の識別子のようなものかと推測しています。この状態であれば、pythonのソースコード上で問題なくimportできますので、動作確認してみます。
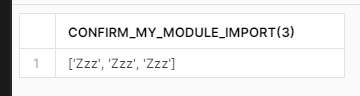
自作モジュールの内容が確認できました。
パッケージ
自作パッケージを利用することは不可能ではなさそうですが、ここで記載した方法は、あまりスマートなやり方ではないため、よっぽどの事情がない限り、利用しない方がよさそうです。
(※もっと良いやり方を知っている方がいれば、教えてほしいです…)
自作パッケージの利用が非推奨とした理由は、以下の通りです。
- パッケージとは、フォルダ単位でモジュールをまとめるものである
- 一方で、Snowflakeのステージにアップロード可能なのはファイル単位である
- UDFにも、ファイル単位でコピーされる
- UDF上で、書き込みができるは、
/tmpディレクトリのみ(公式ドキュメント参照)
上記の観点から、自作パッケージをimportしようとすると、以下の手順が必要となるかと思います
- パッケージフォルダをzipファイルなどにまとめて、ステージにアップロードする
IMPORTS句にzipファイルを含める
- UDF上でzipファイルを
/tmpディレクトリに展開する
/tmpディレクトリをPythonのモジュール検索パスに加える
具体的なUDFの定義は、以下のようになります。
コードに登場するsleepyfolder.zipは、展開すると以下のフォルダ構成を想定してます。
外部パッケージの利用
Anacondaによって提供されている多くのオープンソースのPythonパッケージが、Snowflake内ですぐに使用できるようになっています。
利用可能なパッケージの表示
information_schemaの、packagesビューにクエリを送信すると、利用可能なパッケージが確認できます。次のクエリは、pythonで利用可能なパッケージと、そのバージョンを確認しています。
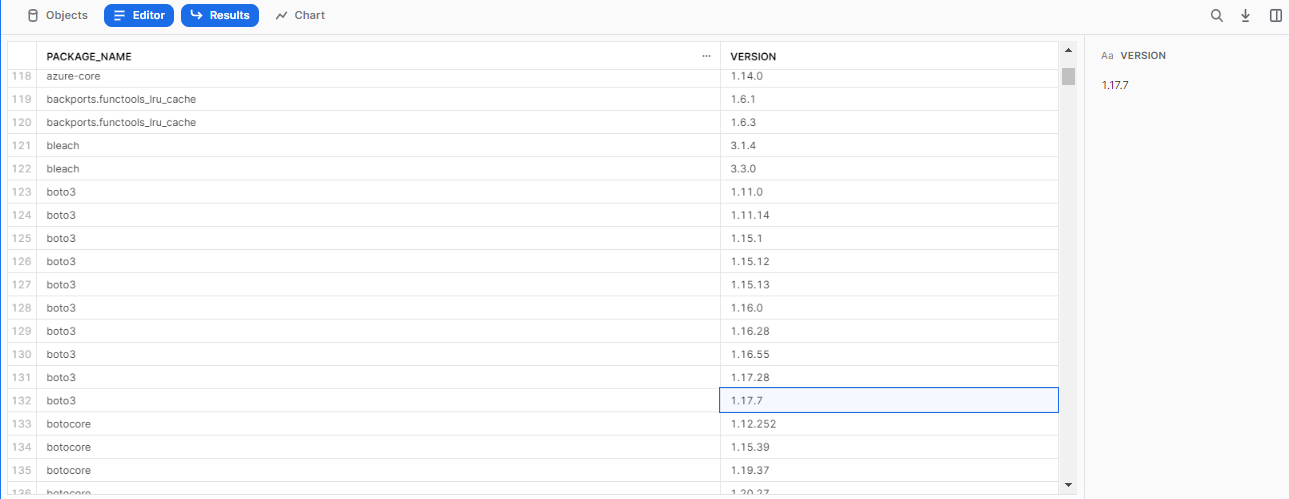
1つのパッケージでも、複数のパッケージが利用可能であることが確認できます。
デフォルトのバージョン
パッケージを利用する場合、CREATE FUNCTIONのpackages句を指定します。デフォルトのバージョンは、最新のバージョンとなります。

バージョン指定
パッケージのバージョンを指定したい場合は、==<versionpip>で、packages句を指定します。pipやrequirement.txtで利用できる>= や!=のような条件指定はUDF作成時にエラーとなり、できないようで、明確にバージョンを指定する必要があります。

存在しないライブラリやバージョンを使いたい
存在しないライブラリを使いたい場合は、Snowflakeコミュニティの Snowflakeのアイデア ページにアクセスして、同様のリクエストが既にあれば投票、なければリクエストを新規作成するようです。
実際にアクセスしてみましたが、とてもシンプルなページで、既存リクエストへの投票は簡単にできそうでした。また、新規作成も以下のようなシンプルなUIで簡単に投票ができそうです。
UDTF(テーブルファンクション)
UDTFは、表形式の結果を返すユーザー定義関数です。基本的には、入力行ごとに実施する処理を記載しますが、入力パーティションごとに実行するロジックを作成することもできます。
UDTFの作成
UDFでは、「ハンドラー関数」を指定しましたが、UDTFを作成する場合は「ハンドラークラス」を指定します。CREATEFUNCTIONの戻り値に、tableを指定することで、UDTFを作成します。
「ハンドラークラス」には、以下のメソッドを実装します。
| メソッド名 | 必須/オプション | 説明 |
|---|---|---|
| __init__ | オプション | 入力パーティションの初期化を実施する。 |
| process | 必須 | 各入力行を処理し、表形式の値をタプルとして返す |
| end_partition | オプション | 入力パーティションの処理を終了する。表形式の値をタプルとして返すことも可能。 |
processメソッドや、end_partitionメソッドでは、タプル形式で値をリターン可能で、リターンした値が出力される表の1行のイメージとなります。また、公式ドキュメントに記載があるとおり、値を返すのは、yieldまたは return を使用します。
以下が、UDTFの実装例となります。シンボルと、単価・売上個数を入力として受け取り、売上金額をリターンするようなUDTFとなります。
上記の例では、1つのprocessメソッドに複数のyieldを指定しています。この場合は、1つの入力行に対して、複数の出力行が生成されます。
UDTFの動作確認
作成したUDTFの動作確認をしていきます。まずは入力として扱うテーブルを作成し、確認用のデータを挿入します。
上記のデータを利用して、UDTFをコールしてみます。UDTFの動作を確認する目的として、入力のテーブルはシンボルでパーティションします。
出力結果は、以下のようになります。

入力1行に対して、2つの行が生成されています。これらは、processメソッドでの2つのyieldに対応しています。また、パーティション単位での出力も確認できました。こちらは、end_partitionメソッドでの出力に対応しています。
確認した出力の表は、1つの列で複数の意味が含まれているため、あまり良いテーブル設計ではないですが、あくまでUDTFの動作を確認するための表となります。
まとめ
読んでくださった方ありがとうございました。 SnowflakeのPython UDF について、色々と試してみました。
- 基本的な使い方
- エラー処理の取り扱い
- 内作モジュール/内作パッケージの利用
- 外部パッケージの利用
- UDTFs の利用
少しでも参考になる部分がありましたら、幸いです!
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。