BI (Business Intelligence:ビジネスインテリジェンス) の登場
「データ分析とは」では、データ分析を定義する中で、基幹システムとデータ分析の目的の違いから要求されるシステムのプラットフォームが異なることをご説明しました。
1980年代のデータ集計・データ分析においては、基幹システムのデータベースからデータを抽出し、テキストファイルなどで保存した上で、集計・分析を加える方法が多く取られてきましたが、必要に応じて抽出するのは効率的ではありません。また基幹システムはミッションクリティカルなため、業務遂行に必要な期間のデータしか持っていないため、取得できるデータも制約を受けてしまいます。
そこで、予め定期的にデータを別のデータベースに格納し、基幹システムには影響を与えない形態で実現しようとしたのが、BI(Business Intelligence:ビジネスインテリジェンス)の始まりです。
このページでは、BIについて、BIの基本的な考え方から、BIの歴史に沿って、ご紹介します。
INSIGHT LABでは、BIの選定から導入、運用までまるっとご支援しています。
BI (Business Intelligence:ビジネスインテリジェンス)とは
BI(Business Intelligence:ビジネスインテリジェンス)という概念は、1989年に米国ガートナー社のハワードドレスナーにより提唱されました。その基本的な考え方をこれから説明します。
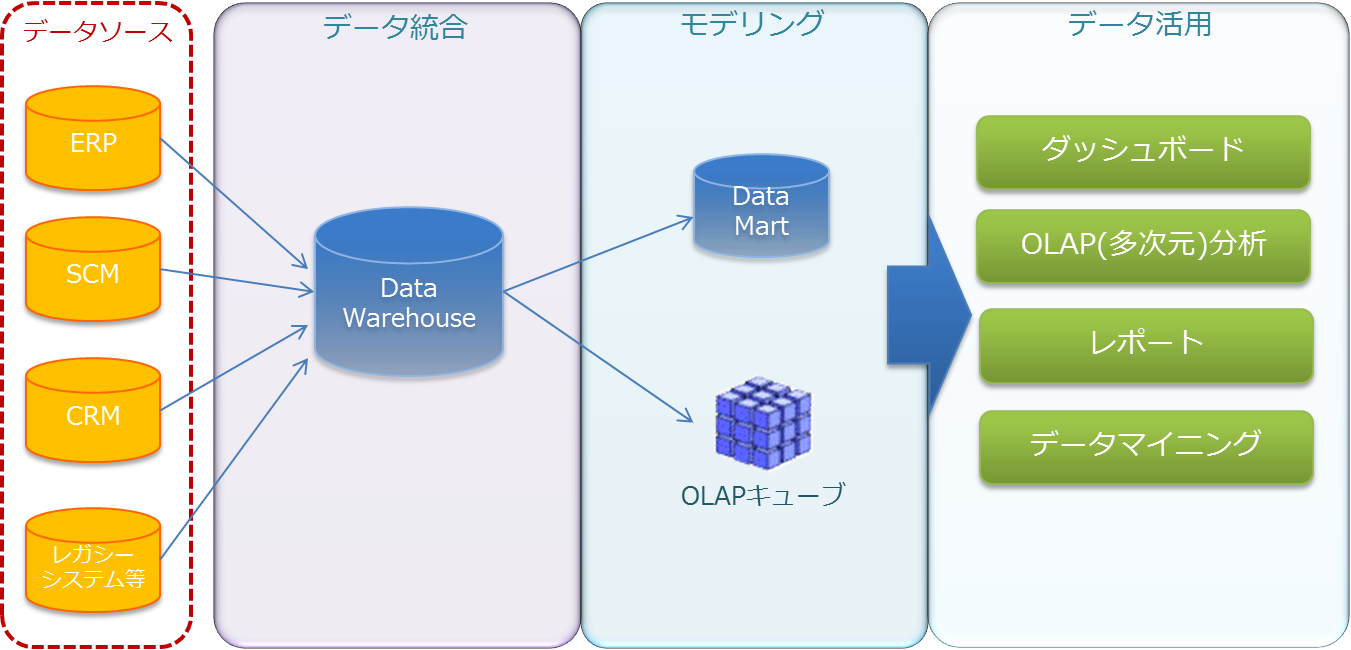
上図は基幹システムなどのデータソースからデータ分析をする過程を「データ統合」「モデリング」「データ活用」という3つのフェーズで説明した概念モデルです。
この概念で最も重要な要素はDWH(Data Warehouse:データウェアハウス)です。直訳すると「データの倉庫」。DWHにおいてはディメンションテーブル、ファクトテーブルといった一定の構造上のルールに基づき、データが整理されるようデータベースが設計されます。
DWHにデータソースからデータを格納するための処理をETL(Extract-Transform-Load)といい、DWHにデータを格納するために、様々なデータベースやデータファイルからデータを抽出し、必要な変更処理を施した上で、格納するためのツール(ETLツール)が提供されています。
DWHに格納されるデータは膨大なデータとなります。従って、通常のSQL言語によるデータアクセスはパフォーマンス上、好ましくありません。データが数百万件、数千万件というオーダーになってくると、場合によって結果が表示されるのには数十分の時間を要することもあります。そのためにモデリングという概念が必要となります。
モデリングでは、データ活用で必要となる分析の軸や項目に応じて、次のいずれかで整理します。
- データマート
DWHの明細データを粒度の粗いデータに集計しておき、DWHと関連づけておきます。 - OLAPキューブ
多次元キューブと呼ばれ、分析の軸を中心として、キューブという論理的な構造体を定義し、DWHと関連づけておきます。
ここで留意しておきたいのは、データマートにせよ、OLAPキューブにせよ、データ分析に必要とされる分析の軸や項目が事前にあって初めて作成されるという点です。
想定されるデータ分析の目的に応じてデータマート・OLAPキューブを作成しておきますが、データを利用しながら見直し、さらに改善を加えていくのが、このモデリングです。
モデリングにおける見直しのポイントは主にデータの集計・分析におけるパフォーマンスと分析の視点の追加・変更が中心です。
BIにおけるエンドユーザインタフェイスは「データ活用」のフェーズです。データ活用にはダッシュボード、集計レポート、多次元分析、データマイニングなどが含まれます。
- ダッシュボード
企業の現在の状況を俯瞰してみるための画面で、社内でも最も重要視されるKPIなどの指標を1つの画面上に表示するような目的で作成されます。 - レポート
大量データからBIのアーキテクチャーを使用して、高速に集計されるレポートです。分析の軸に沿って作成されたOLAPキューブやデータマートを活用して、高速化が図られています。 - 多次元分析
BIの最も特徴的な利用方法で、スライス(データからある視点でデータを切り出してみる)、ダイス(分析の視点を切り替えながらみる)、ドリルダウン(集計結果を階層を下げてみる)、ドリルスルー(特定の条件まで絞り込んで該当するデータを抽出する)など自由度の高いデータ集計・分析が行えます。 - データマイニング
データマイニング(Data Mining)は直訳すると「データを掘り起こす」と解されることから、多くの人がBIのOLAP分析が実現するものと誤解しているようです。
しかし、実際のデータマイニングはデータ解析の一つアプローチであり、統計解析ともやや異なります。これらをここで論じることはしませんが、データマイニングは「決定木」「ベイジアンネット」「ニューラルネット」「クラスタ分析」などこれまでの多くの知見から確立され、さらに研究が進められているデータ解析手法です。データマイニング専用のソフトウェア製品もあり、その中にはBIとの連携が図られている製品もあります。
BIの動向
BIは、基幹システムには負荷をかけず、蓄積された大量のデータを分析に活かす上で、大変効率的な仕組みですが、昨今のビッグデータ活用シーンにおいては、さらに改善が加えられています。
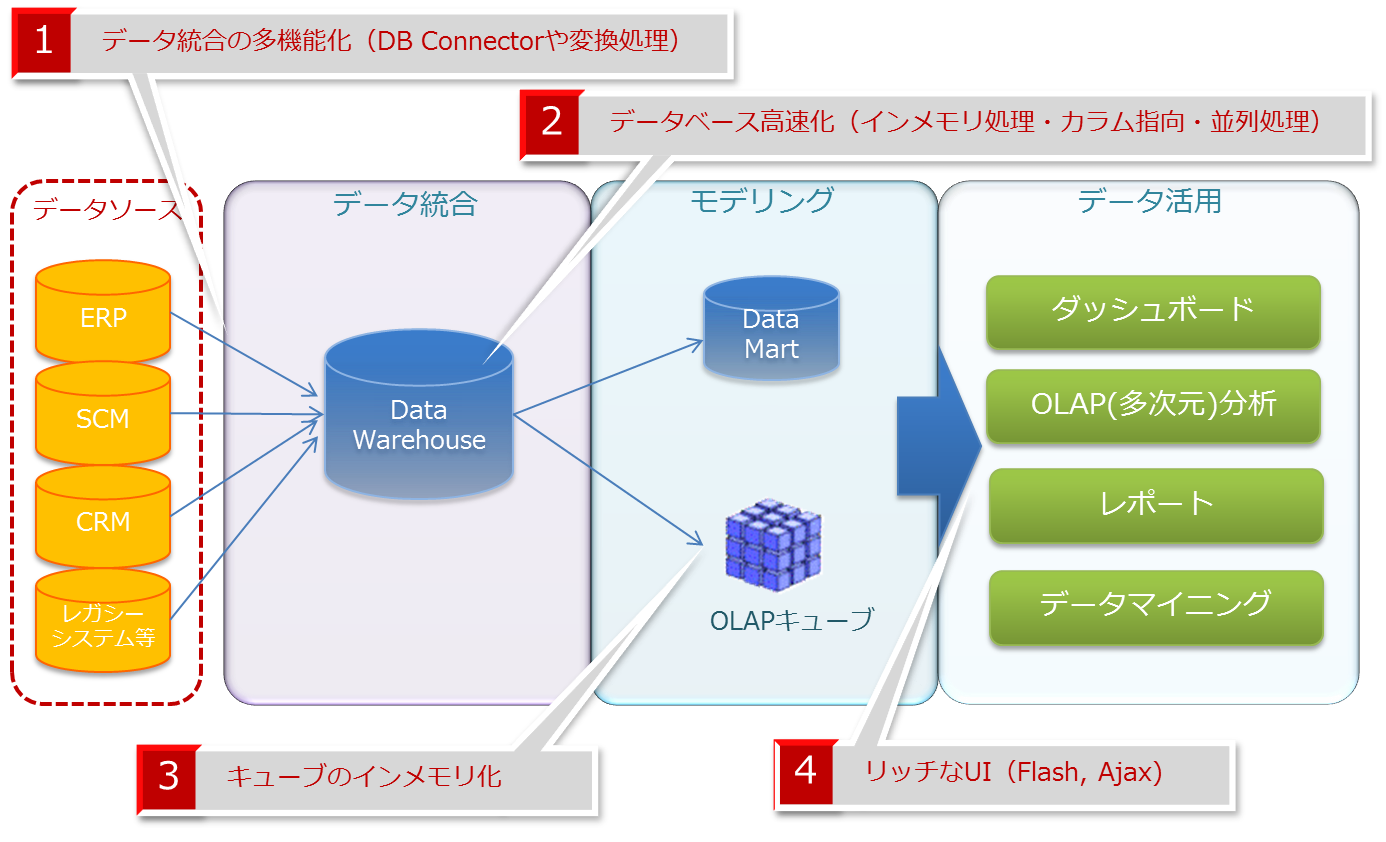
上図にて示されるように、昨今のBI製品は次の4つのポイントで強化されています。
- データ統合の多機能化
先に述べたように、データ統合において、データの抽出から変換、格納に至るプロセスはETLツールによって行われます。一般には各BI製品の体系にETLツールが含まれていますが、昨今は非常に素晴らしいETL製品が次々に開発されています。
最新製品では、様々なデータベースやファイル形式に対応したコネクターが用意されていますし、世界で最も著名なERPであるSAPやSalesforceのようなクラウドサービスのコネクタまで標準で準備されています。
元々、ETL製品の変換処理では、処理フローをGUIで設計でき、ノンコーディングで変換処理を定義できるのが一般的で、変換処理の多機能化も進んでいます。 - データベースの高速化
DWHで使用されるデータベースは多くの場合、RDBMSが使用されます。しかしながら、BIがいくら高速といっても、一般的なRDBMSを使用する限り、データベース製品のアーキテクチャー自体のボトルネックが現に存在します。
Oracle、SQL Server、MySQL、PostgreSQLなど主要なデータベースにてベンチマークを実施してみましたが、データ件数が300万件程度でもかなりのパフォーマンスの低下が認められました。
このパフォーマンスの低下はデータベース自体が、コンピュータ上ではハードディスクに存在することからデータ増に対する物理IOのボトルネックの制約も大きく影響します。
これに対応するため、インメモリ型データベースエンジンなどが登場する一方、カラム指向データベースなどの新たなアーキテクチャーを持つデータベースも注目されています。
特にカラム指向データベースは、通常のOLTP処理が行単位のデータアクセスであるのに対し、列方向にデータアクセスを行うもので、主にBIなどの分野での利用を前提に開発されたものです。
また、サーバハードウェアの超並列処理アーキテクチャーに最適化されたDWH専用のデータベースエンジンも登場しています。これはビッグデータに対して負荷バランスを取りながら超並列処理するため、専用ハードウェアとのアプライアンス製品となっているのが一般的で、NetezzaやTeradataなどが代表的な製品です。
さらに、最近では、クラウド型DWHのSnowflake(スノーフレイク)という製品も登場しており、全世界で3,000社を超える顧客が利用しています。1日に3億回以上のクエリーが実行されていることから、グローバルで高く評価されているサービスであるといえます。 - キューブのインメモリ化
BIが一般のSQLベースのデータアクセスより高速な理由は、分析に必要な分析の軸(ディメンション)、軸の項目とその階層、集計値(メジャー)を予めOLAPキューブに定義していることによります。
昨今のインメモリ型BIの中心となる技術はこのキューブのインメモリ化です。キューブのインメモリ化では、より時間のかかるクエリをメモリにキャッシングしておきます。製品によっては、データベースのカラムデータを圧縮して、インデックスをメモリにキャッシングするなどの技術も採用されており、今後もこの技術は様々な発展を遂げていくと予想されます。 - リッチなUI
エンドユーザが利用する画面(UI)は、ブラウザベース、あるいはクライアントベースのアプリケーションとなっています。企業内に多くのユーザがいる場合は、クライアント環境に依存しないブラウザベースのUIが選択されます。ブラウザベースのアプリケーションでは、クライアントベースに比べると、操作性や表現力の面で劣ってしまうのは致し方ないのですが、それも改善されてきています。
高性能なのに低価格なクラウド型DWH「Snowflake」とは
第1世代BI(トラディショナルBI)の問題点
ここまでBIの基本的な概念と、BIの中心となっている技術的な側面にスポットを当てて説明してきました。皆さんはどうお感じになりましたか?
BIに積極的に取り組んでみようと闘志に燃えるエンジニアリング指向の方もいれば、ハードルが高すぎて半ば挫折しそうな方もいるでしょう。このようにBIはかなり奥深く、一朝一夕にスキルを身につけるのは難しい分野であることも事実です。
現に1990年代に脚光を浴びたBI(トラディショナルBI)は2000年代に入り、すっかり影を潜めてしまいました。それは主に以下のような理由からです。
- 製品価格が高すぎた
そもそもBI製品は価格が高すぎました。特に1990年代の製品群は少なくとも数千万円という価格体系で、導入後も高額なソフトウェア保守料がかかりましたので、導入できるのは一部の大企業だけでした。そして「BIが良いのはわかるが高い」というレッテルが貼られ、中堅~中小企業ではすっかり興味が薄れてしまいました。
2000年代のBI製品は、かなりリーズナブルになってきましたが、バブル崩壊後の日本国内で重要視されたのはIT投資を抑制しつつ基幹システムを維持した上で、チャンスを覗って再構築することでした。
その間で、BI製品のメーカは、一部は姿を消し、一部は企業買収の憂き目に合いつつ、現在のBI製品の勢力図が成り立っています。
ガートナー社のレポートで、最新のアナリティクス市場の概要を把握できます
- BIベンダーが少ない
BI構築には特殊なスキルやノウハウが要求されます。特に経験知が物を言い、未経験のベンダーが初めてこの分野に参入するのは一苦労です。従って、BIベンダーはごく少数に限られており、BIの概念が難解であることも相まって、高額な構築費用、サポート費用が要求されてきました。需給バランスといえばそれまでですが、それがまたBI導入の障壁にもなっていたのも事実です。 - サイジングが困難だった
データが膨大になってくると、従来のアーキテクチャーでは、パフォーマンスの低下の問題に直面するケースが多くありました。パフォーマンス対策はハードウェアの増強、データウェアハウスの再構成、データマート追加、キューブのチューニングなどの複合的な要素が絡んできます。そもそも事前にどのようなスペックのサーバが必要なのか明確なサイジングルールが存在しないため、実際に構築してみなければわからないというのが実態でした。高額なハードウェアでは事前評価も困難であり、導入後にパフォーマンスの問題が噴出し、延々と対策を施しながら騙し騙し使っているというようなユーザもありました。 - データ分析は社内の一部の人間しか使わないと思われていた
これは未だにその風潮があるのですが、日本企業の多くはデータ分析と聞くと社内の一部の人間のみしか利用しない特殊な領域と捉えられてきました。分析自体が利益を生むという考え方は浸透していませんでしたので、本来は分析することで対策の施しようがあったことも、従来の「経験」と「勘」に頼った経営をしてきました。現在、欧米諸国に比較すると日本のBIの導入率が極端に低いという現状はその意識の現れとも言えます。
ある意味では、これは「データ分析により見える化しよう」と言いながら、そのゴールを示すことができなかったベンダー側の責任もあるのではないかと私は考えます。
本来は「データ分析により見える化することで、経営に何が起こるか」ということが重要であり、「見える化」というキーワードの本質を顧みず、踊らされてきた不透明な時代が長く続いていたわけです。
最も重要なことは、データ分析の担当者がいても一向に構いませんが、その分析のプロセスや分析の結果を企業内で共有するということです。そのような企業内のコンセンサスがなければ、BIは無用の長物となってしまいます。
第2世代BI製品
このように問題山積みのBIの世界をブレークスルーする次の世代のBIツールが登場しました。インメモリ型であることを大きな特徴とする次の世代(第2世代)のBIツールです。以下に第2世代BI製品の代表となる製品の概要を紹介します。
QlikView(クリックビュー)
「QlikView」は、データ分析プラットフォームです。ユーザが自由に分析でき、データの中から業務(Business)に必要な情報を、探索(Discovery)することのできるBIツールです。スウェーデンの大学研究所で生まれ、特許取得済みの連想技術を用いてインメモリによる高速処理を実現するユーザー主導型です。
Qlik Sense(クリックセンス)
「Qlik Sense」は、QlikTechが新しく開発した次世代のBIツールであり、セルフ・サービス型のデータビジュアライゼーション及びデータ探索製品です。
Tableau(タブロー)
「Tableau」は、分析における専門的な知識を持たない人でも簡単に扱うことができるBI(Business Intelligence:ビジネスインテリジェンス)ツー ルです。従来のBIツールのように分析対象や分析の視点をあらかじめ決める必要はなく、ユーザが 必要な時に必要な分析をすることができます。
ここからは、第2世代のBIツールを代表して”QlikView”という製品についてより詳細に解説していきます。
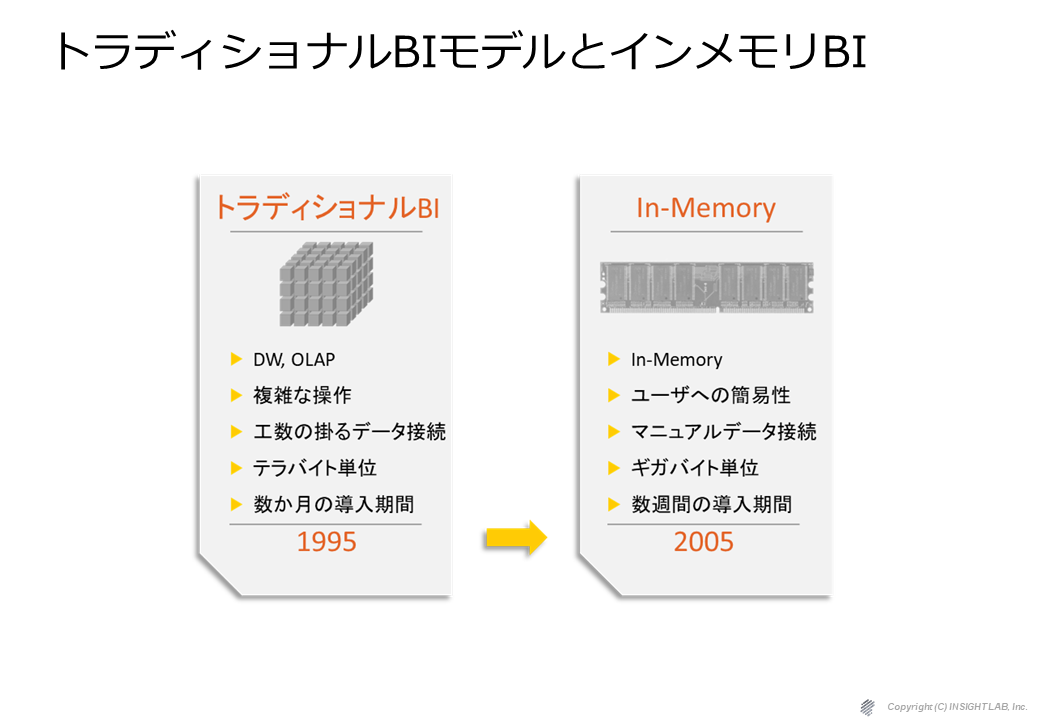
第1世代(トラディショナルBI)から第2世代(インメモリBI)の切り替わりがほぼ10年ぐらい前にありました。
第2世代BIツールというのは、QlikViewやTableauといったインメモリ型のBIと言われる製品群ですが、第1世代のBIというのはデータをETLで統合してDWHに貯めてキューブやデータマート経由でユーザが見るというような体系でした。
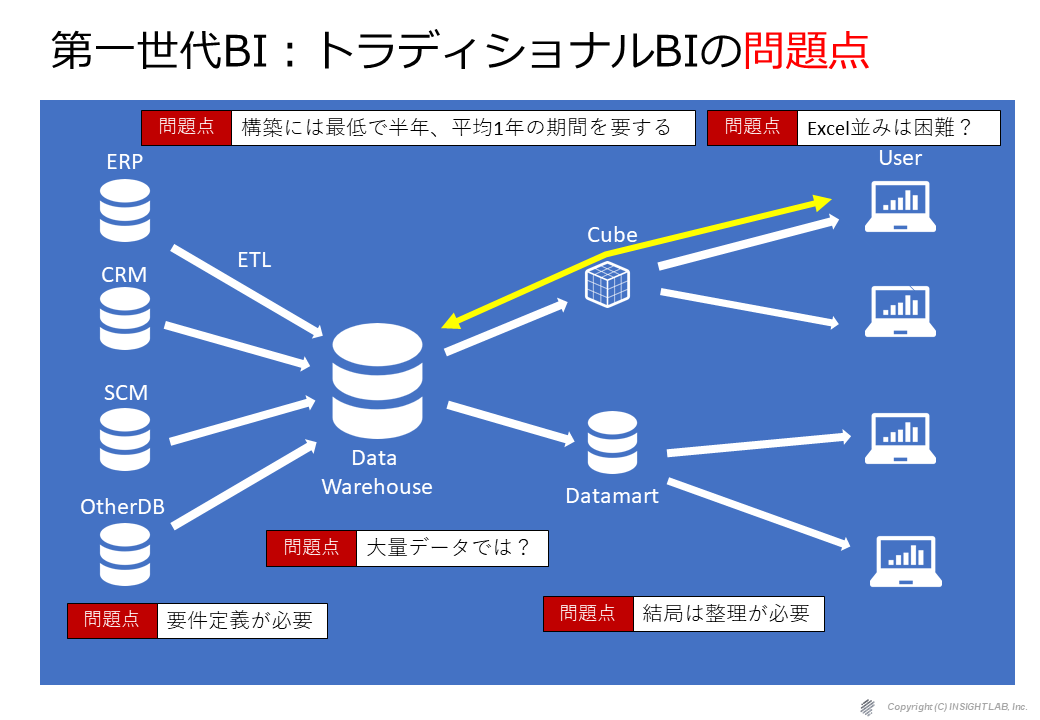
私達も当時、第1世代BI(トラディショナルBI)を使って開発をしていましたが、しっかりとした要件定義が必須であり、大量データに弱く、結局データが多すぎるからキューブやデータマートのようなもので整理をしなければならず、かつ、 Excel 並みの操作性は困難、一番の問題は、構築時間が少なくとも1年はかかるということでした。
第2世代のBI(インメモリBI)は、もっとシンプルで、データを統合してDWHというよりは、アプリケーションのファイルにいったん落としてそれをメモリに展開して、そのメモリにユーザがアクセスをして使うというような形に変わっています。
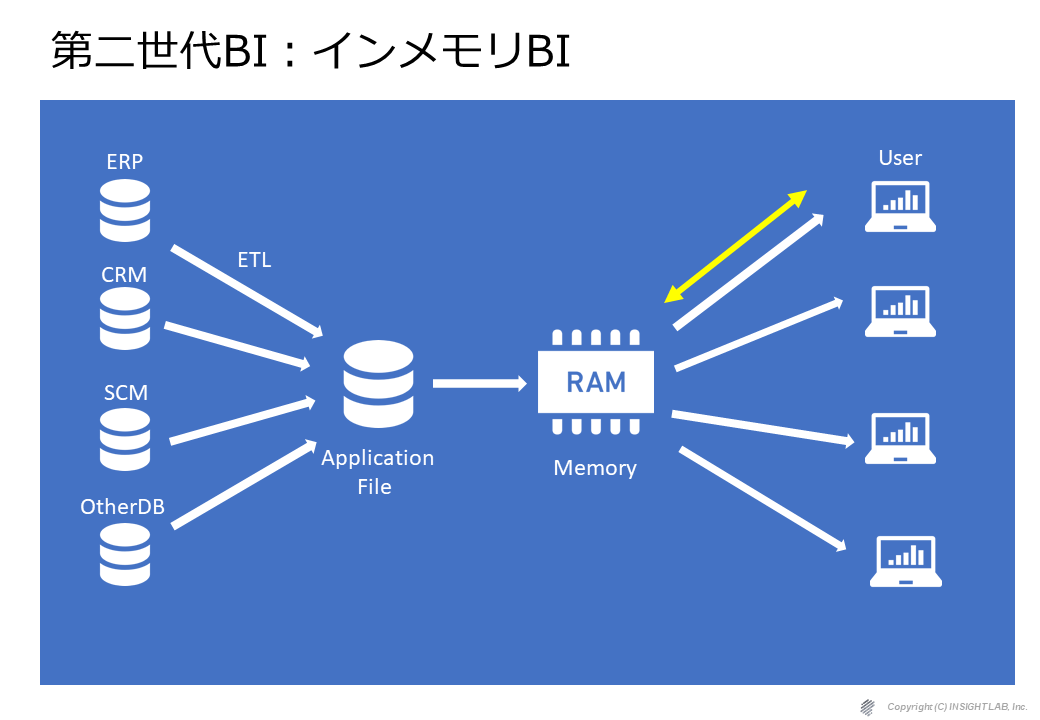
第2世代BIツールを代表するQlikView(クリックビュー)とは
この製品は、1993年、メモリやハードディスクが非常に高価な時代にスウェーデンの大学発ベンチャー企業が開発した製品で、限られたハードウェア資源を高い効率で活用できるAssociative Technology(連想技術)という独自のデータ圧縮技術とインメモリ処理技術をベースにしています。
ここ数年、メモリやCPUの低価格化が進み、コンピュータ当りの集積度は飛躍的に向上しています。高レベルのチューニングを行うより、メモリやCPUの集積度を上げるほうがはるかに投資効率が高い時代になり、”QlikView”は一気にBI界のスターダムに載るに至りました。QlikViewの開発元であるQlikTech社は現在、米国ペンシルバニア州に本社を置き、2010年7月にはNASDAQにも上場を果たしています。

上図はIDCとQlikTechが共同で調査したユーザ調査の結果です。いずれも驚異的な数字を示していますが、このようにユーザ満足度が高く、投資効率が高い上に、短期間で導入が可能なQlikは、現在BI製品の中で最も注目されている製品の一つです。
これまでの第1世代BI製品(トラディショナルBI)と何が違うのか?
上図の数値はこれまでの第1世代BIツール(トラディショナルBI)では実現しえないものでした。それではQlikViewは従来のBIツールと何が異なるのでしょうか?
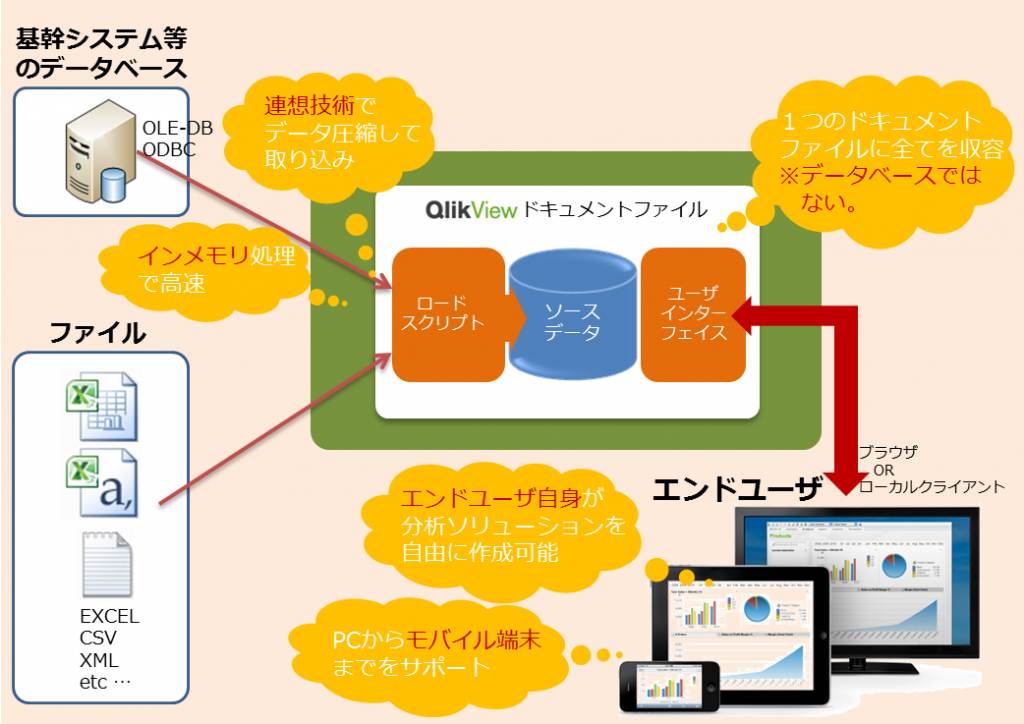
まず、データウェアハウスやキューブ、データマートがありません。
よく考えると、これらはデータ分析に必要な要件を充足させるために必要な構造体だったのです。では、その代わりに何があるかというと「QlikViewドキュメントファイル」です。
このドキュメントファイルの中に分析に必要なソースデータが格納されています。さらにデータを取り込む「ロードスクリプト」と「ユーザインターフェイス」も含まれています。イメージが湧きにくい人のために申し上げますと、「Excelファイルみたいなもの」とお考え下さい。
でも専用のデータベースがなくて、「大量データが扱えるの?」「処理速度は大丈夫?」という疑問が湧いてきます。ここがQlikViewの優れたところで、ロードスクリプトを介して取り込む際に「連想技術」という独自技術でデータを圧縮してしまうのです。
さらに、QlikViewアプリケーションがこのファイルを呼び出すと同時に、メモリ上(インメモリ)にファイルを載せ、処理しますので高速に処理できます。
ユーザインターフェイスは、Excelのようなシート形式でグラフやピボットテーブルを容易に作成できるようになっています。
このように高速大量処理ができ、自由度の高い分析ができるツールがQlikViewです。さらに第1世代BIと大きく異なるのは、構築のプロセスがシンプルであるということであり、従来のBIにおいて構築・再構築で必要とされてきたリソースを大幅に削減することができます。
第2世代BIツール(インメモリ型BI)QlikViewの特長
- インメモリ処理
QlikViewはデータウェアハスウスを構築しない、つまりデータベースに依存しないファイルベースのインメモリ処理を行います。従って、ハードディスクの物理IOのボトルネックがなく、ビッグデータを高速処理できます。まずは、そのしくみを解説していきます。
RDBMSベースのBIではデータベースはハードディスク内にあるため、データ量が増えれば増えるほど、ハードディスクへのアクセスが追いつかず、パフォーマンスの低下を招いていました。それに対し、QlikViewではデータソースをQlikViewドキュメントファイル(.qvwファイル)に格納しています。図3-2のようにQlikViewからドキュメントファイルを呼び出すと、データはメモリ上に展開され、それ以降はメモリ上で処理を行います。
さらに、データ検索、演算処理はQlikViewのアプリケーション側に実装されており、高速に処理を実行しますので、数千万件を超えるような膨大なデータ量になったとしても、メモリが許す限りストレスなく分析が行えます。
メモリの低価格化が進む昨今、インメモリ型のアプリケーションが今後の主流となってきています。その中でもQlikViewはデータベースに頼らないインメモリBI製品として注目されています。
QlikViewのデータ処理が高速であるもう一つの理由は、マルチスレッド処理にあります。下図は、Intel社のWebサイトに掲載されている Xeon 7300番台のベンチマークの結果です。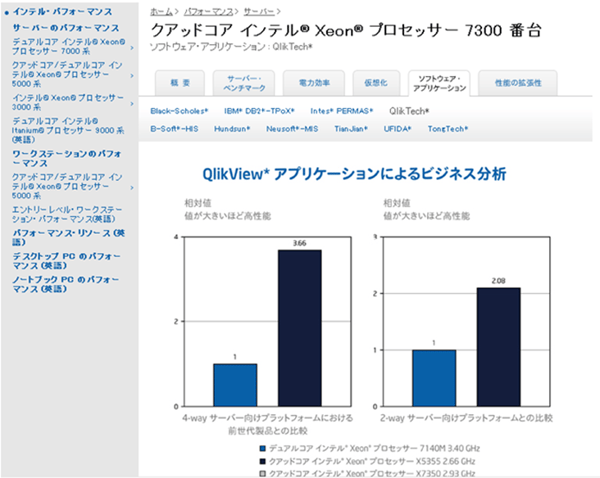
RDBMSの中には、見た目マルチスレッドに対応していながら、その実、一部の処理がシングル処理であったり、インメモリといいながら、その処理そのものがシングル処理であるがために、期待された程のパフォーマンスを発揮していないケースもあります。
一方、QlikViewの開発元クリックテック社はインテル社の技術パートナーとして、CPUの試作段階から協力関係にあります。上のグラフを見ていただければわかるように、Qlikviewは、コア数に比例してパフォーマンスを発揮しています。
メモリ同様、CPUもマルチコア化、低価格化が激的に進行しており、高スペックなCPUも低価格なマシンに搭載される時代になりました。このようにQlikViewは現時点のハードウェアインフラの趨勢に合致したBI製品と言えるでしょう。 - 連想技術
インメモリ処理の解説を読み進めながら、ファイルベースでは大量データになるとメモリに載らないのでは?という疑問が湧いてきた人も多いことと思います。もちろん、通常は大量データとなるとメモリに載せるのは現実的ではありません。
Microsoft Excelはファイルベースですが、ファイルをメモリ上に展開して処理するという点では理屈は同じですが、数百万件のデータが含まれたファイルを開くことを考えると現実的ではないことはExcelユーザならすぐわかると思います。
これに対し、QlikViewでは連想技術(Associative Technology)を駆使して、データを圧縮して、ファイルに格納します。この連想技術という圧縮技術は非常に圧縮率が高いため、インメモリで処理する際にメモリの占有を抑えながら高速に処理を実行できます。
以下、QlikViewの連想技術について解説していきます。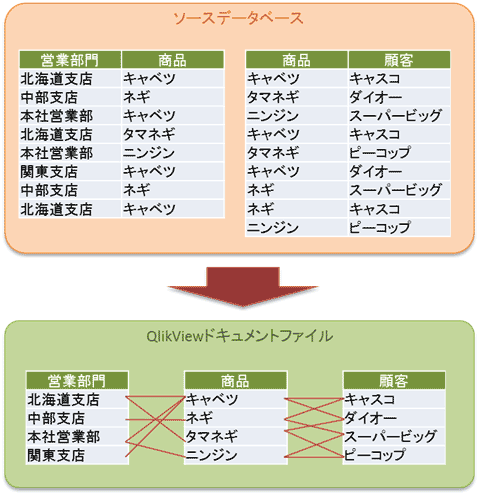
ソースデータは、上図のようにデータが正規化され、データベース内に格納されています(実際にはコード化されているため、数値データであることが多い)。これをQlikViewのロードスクリプトを介して取り込む際に、連想技術により超正規化データに変換され、「QlikViewドキュメントファイル」内に格納されます。
ソースデータでは「北海道」は3件、キャベツは4件、キャスコは3件のデータがあります。このように正規化されたデータベースにおいては、重複したデータの持ち方をするのが一般的です。一方、QlikViewにおいては、「同じ項目に同じデータは1つしか持たない」形式に集約されます。さらにデータ間はポインターで連結されており、このポインターを辿ることで、 全てのデータが検索キーとなります。
このように連想技術により、データの重複を排除し、独自のデータ間の連結により効率のよいデータベース構造を持っているのが、QlikViewのデータファイルの大きな特長です。
経験値では大量データの圧縮率は5分の1から20分の1と非常に高く、インメモリ処理にも有効に働きます。「インメモリ」と「連想技術」、この2つが効果的に働くからこそ、QlikViewは高速大量処理が可能なのです。 - インタラクティブな操作性
インメモリ、連想技術とQlikViewの技術的な側面から解説してきましたが、QlikViewはそれ以上にユーザビリティの面での恩恵が非常に大きな製品です。QlikViewでは数時間のトレーニングを受けるだけで、データの取り込みから、チャートを含んだ分析アプリケーションの作成までを習得することができます。
では、どのようにシンプルなのか、そのしくみを解説していきます。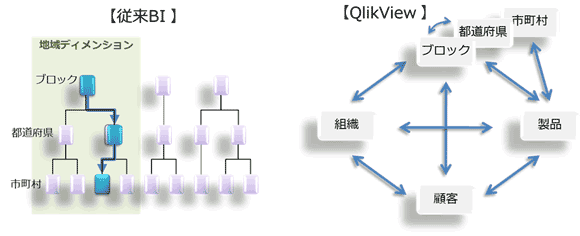
従来型のBIは事前定義が必要です。特に重要な定義は次の2つです。
- ディメンション
分析の視点に応じて定める軸です。上図では「地域」ディメンションを定義し、「地域ディメンションテーブル」を作成します。そのテーブル内にはブロック、都道府県、市町村といった項目を含むよう設計する必要があります。これは通常、データウェアハウスに適用されるものです。 - ヒエラルキー
分析の順番に上位から項目を階層化します。こちらはOLAPキューブの中で定義するものです。
従来型のBIではOLAPキューブがエンドユーザからの接点で、「地域」という分析の軸の中に「ブロック」→「都道府県」→「市町村」の順番で項目が並んで見えます。といっても、エンドユーザには中々理解し難いのですが…
これら従来型のBIは事前定義ありきのため、キューブに定義されていない項目は、データウェアハウスを参照してキューブを作成・改造しなければいけません。データウェアハウスになければ、さらにソースデータまで遡り、データウェアハウスの再設計から行う必要があります。
では、QlikViewではどうでしょう。
先に述べましたように、QlikViewは連想技術によってデータ項目が連結されています。 上図の右のように、各項目は独立した点ですが、その組み合わせは自由であり、そもそもがQlikViewの中で全項目が「見えて」います。これらの項目を自由に組み合わせて、分析の軸やドリルダウンのための項目の上下関係を、分析アプリケーションを作成する時に定義することができます。つまり、事後定義型というわけです。
一度作成した分析アプリケーションにて、例えばシート上のグラフの項目を変えたり、分析しているうちにさらに項目を追加して掘り下げたいなどの場合、このQlikViewのインタラクティブ性が大いに役に立ちます。
そもそも私達がデータと向き合った時、提示された数字を見て原因がわからなければ、そこに新たに視点を追加して原因を追求しようとする習慣があります。
従来のBIではどんな視点で、どんな掘り下げ方ができるのかが直感的にわかりにくいものです。場合によってはIT部門の手を煩わせることになりますし、要求レベルがそれを超えてしまえば、外部の専門ベンダーに依頼しなければいけなくなります。
QlikViewではExcel等の表計算ソフトを操るのと同様、ノンプログラミングで高度な分析アプリケーションを作成できます。そのためにBIの特別な知識は必要ありません。逆にBIの知識がある方には、これはBIではなく全く違うジャンルのアプリケーションとして映るでしょう。
第2世代BI(インメモリBI)の問題点:その①
第1世代のBIツールと比較して、これだけ素晴らしい第2世代のBIツール(インメモリ型BI)ですが、私達はここ10年近く第2世代のBIツールの導入を行ってきて、色々な問題点に気付いてきました。
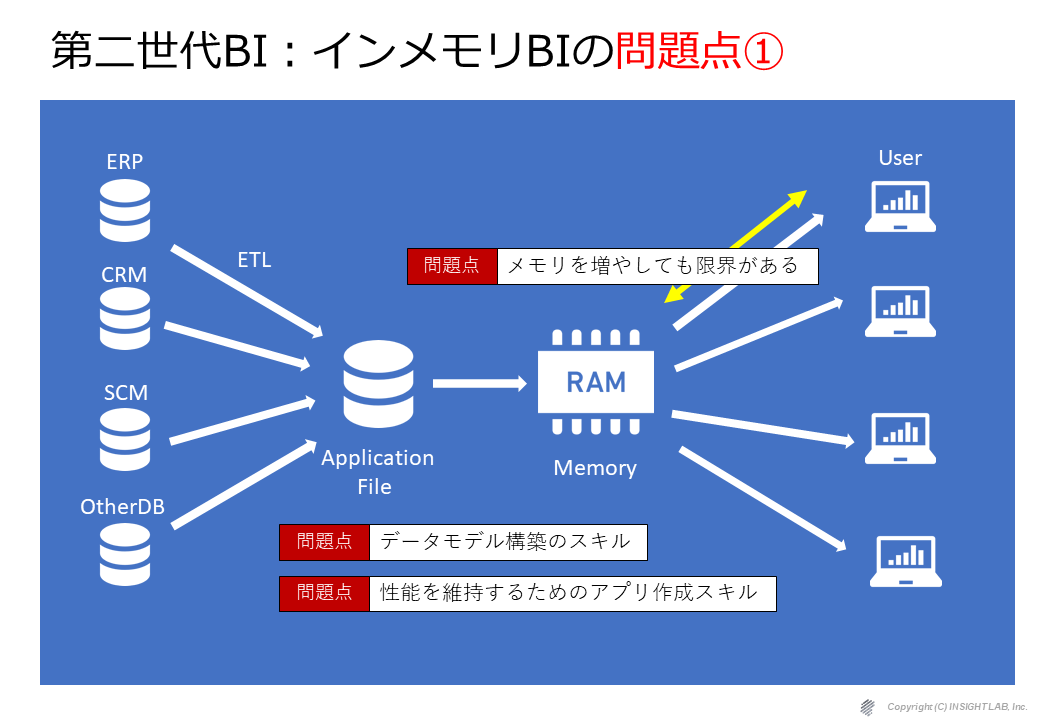
まずはデータ量の問題です。扱うデータ量が多くなった時に、いくらメモリやCPUを増やしても限界が来てしまうことがわかりました。
インメモリ型ならそのメモリを増やせば、増やした分だけ対応できるのでないかと想定していましたが、そう都合良くはいかず、ある一定のデータ量までくると頭打ちになることがわかりました。そのようなケースでは、アプリケーション側(特にデータモデル)の構築のスキルで対応できる部分もありますが、非常に高い技術力が要求されますし、やはり、そこにも限界があります。
第2世代BI(インメモリBI)の問題点:その②
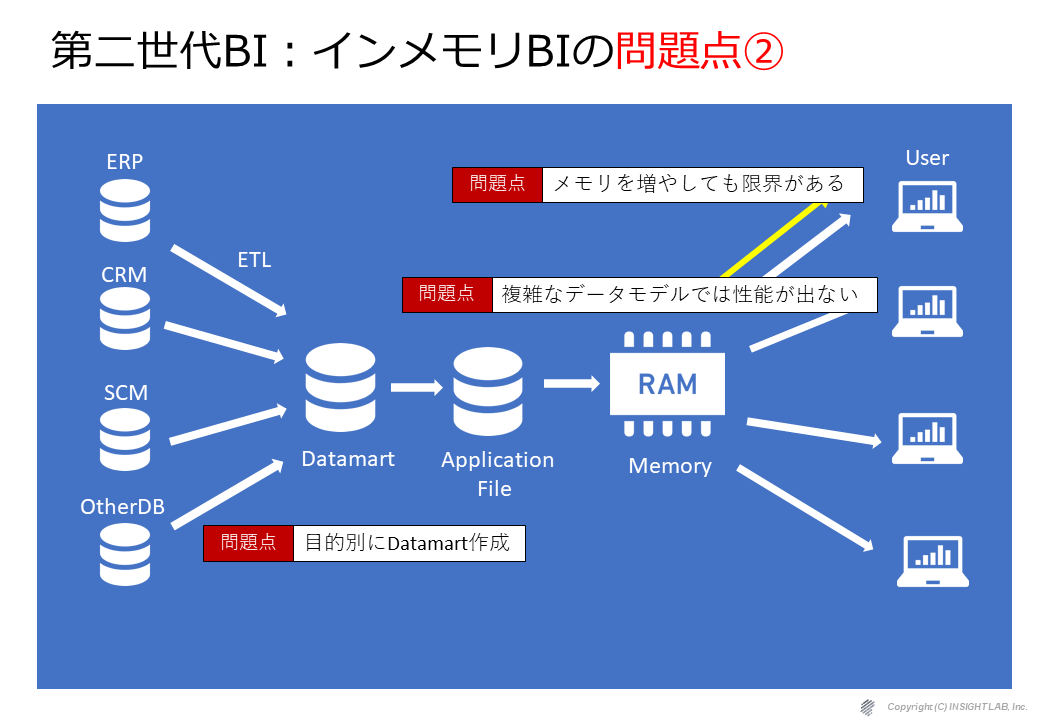
また、もう1つのパターンとして、複雑なデータモデルに非常に弱く、そのために目的別にデータマートを作るという、第1世代で問題となっていた対応がここでも必要になってしまうケースがあります。
第2世代BI(セルフサービスBI)の問題点:その③
第一世代のBIツールは、データ構造からグラフの至るところまで、事前に細かく要件定義から設計、実装までを情報システム部門が構築して、やっとビジネスユーザが利用できる状況にあったため、ちょっとした分析シートをつくりたいだけでも、普通に数ヶ月の時間が必要でした。
そう言った状況を著しく解決に導いてくれたのが、第2世代BIツールのTableauを代表するようなセルフサービスBIツールでした。
しかし、またここで1つ問題が発生します。
ビジネスユーザみんなに、分析環境を与えたところ、結局使っているのは、ごくごく一部の人間。
その中でも、BIツールとして使う必要がある分析は、ほんのわずか。
また、ある企業では、各メンバーが好き勝手に分析アプリを作り放題になったために、
会社として管理ができなくなる野良アプリ問題へと繋がりました。
第3世代BIの登場
そこで、第2世代のBIツールが世の中にでて10年以上経った今、また新たな世代として、第3世代のBIツールが登場し始めています。
日本国内では、まだ多くの人には知られていない状況ではありますが、Looker(ルッカー)や、Sisnese(サイセンス)といった第3世代のBIツールが登場しており、Sisense(サイセンス)は、すでに全世界で2,000社以上に導入されています。
2019年時点で、ガートナー社によるBIベンダーの市場調査では、3年間で評価がリーダーに迫るところまで上昇し、このままの勢いで伸びれば、2020年以降にはリーダーに選定されることが予想されています。
第三世代BIツール:Sisense(サイセンス)
ここからは、第3世代BIツールを代表してSisenseをご紹介します。
Sisenseの最大の特徴は、組み込み分析に特化した機能と高速な分析を可能にするインチップという技術です。後ほどご説明しますが、インチップとは、CPUのキャッシュを効果的に使う技術です。
データモデリングの面では複雑なデータモデルを組んでもかなりのパフォーマンスを出します。
シンプルなデータモデルとなっており、データを統合して elastic キューブというキューブの中にデータを格納しますが、これは第1世代BIのキューブとは違います。
どう違うかというと、第1世代のキューブは論理的なものでしたが、第3世代BIのキューブというのは物理的にファイルとして存在するものです。
データに対するコネクタも非常に多く存在していますし、
高速なライブ接続というのもcloud nativeな技術で実現しています。
ダッシュボードのデザインはほとんどがマウス操作で可能です。
自社Webサービスへの組み込みや、オリジナルのダッシュボードをカスタマイズしたければ、HTML、CSSあるいはJava script を使ってかなり凝った画面を作ることもできます。
①Sisenseの特徴:インチップ技術
インチップという聞き慣れない技術をご説明したいと思います。
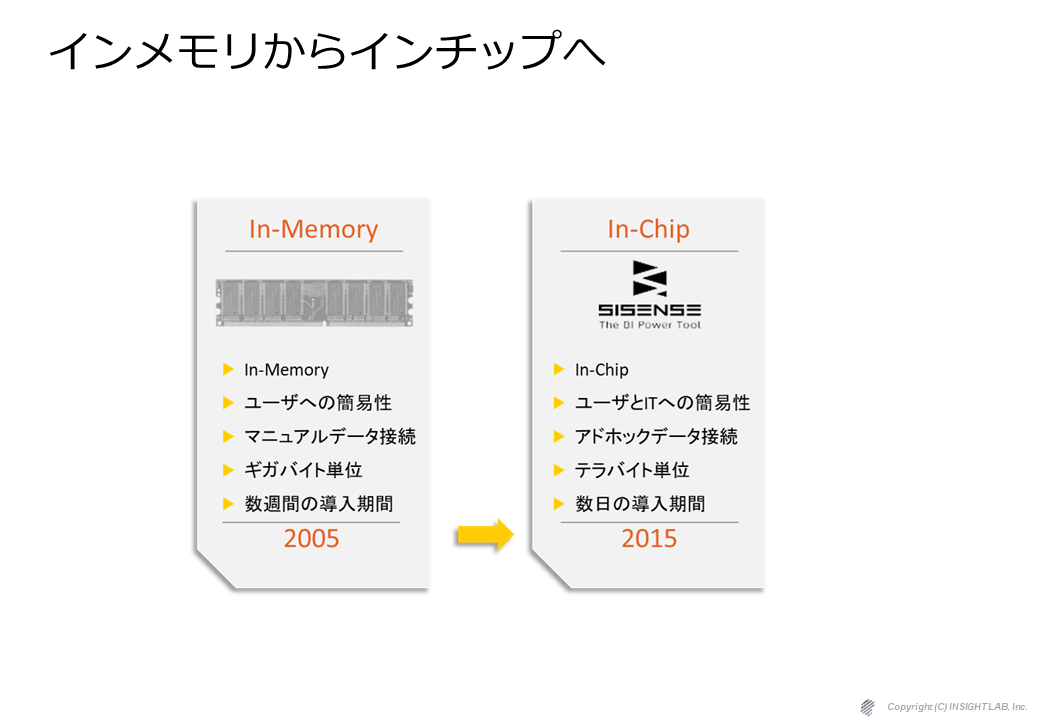
インチップというテクノロジーは、
CPUに最も近いキャッシュを効率的かつ効果的に利用する技術です。
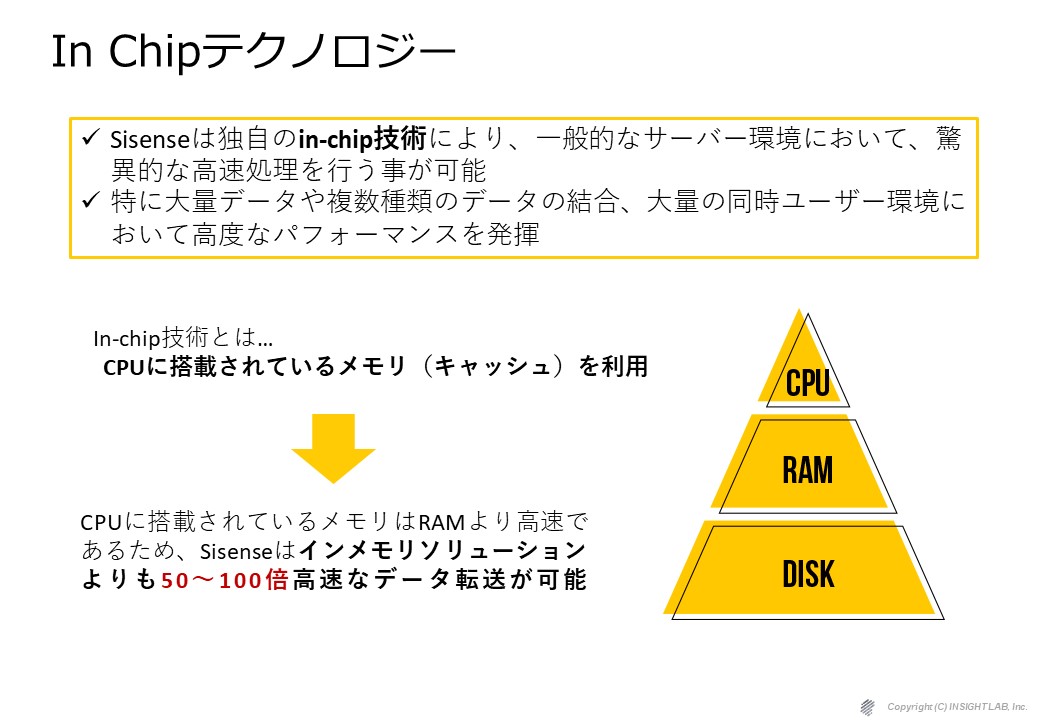
CPUのキャッシュのお話をしましたが当然CPUのキャッシュは1番高速です。
その次がRamメモリで、その次がディスクなんですが、
キャッシュでも L1、L2、L3というように分かれており、
その中でL1というのは最も高速です。
一番よく使われるデータはL1に配置します。
次の優先事が高いものをL2に配置します。
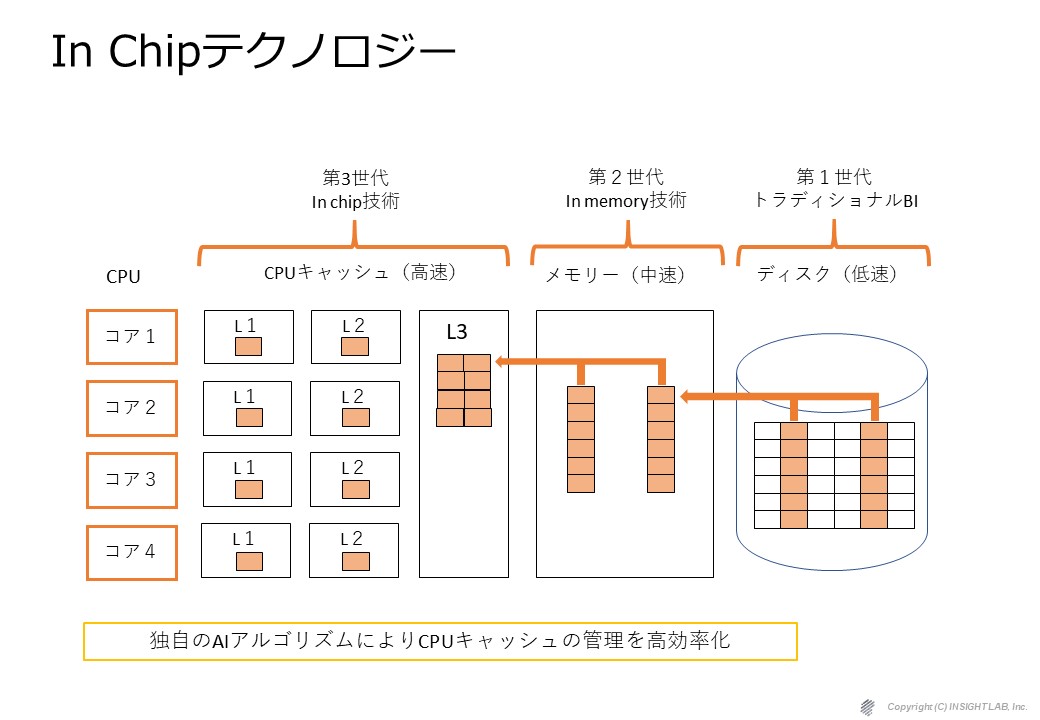
このように優先順位に応じてデータを配置するという技術になっています。
これは裏側で機械学習のように学習されて使えば使うほど賢くなる技術です。
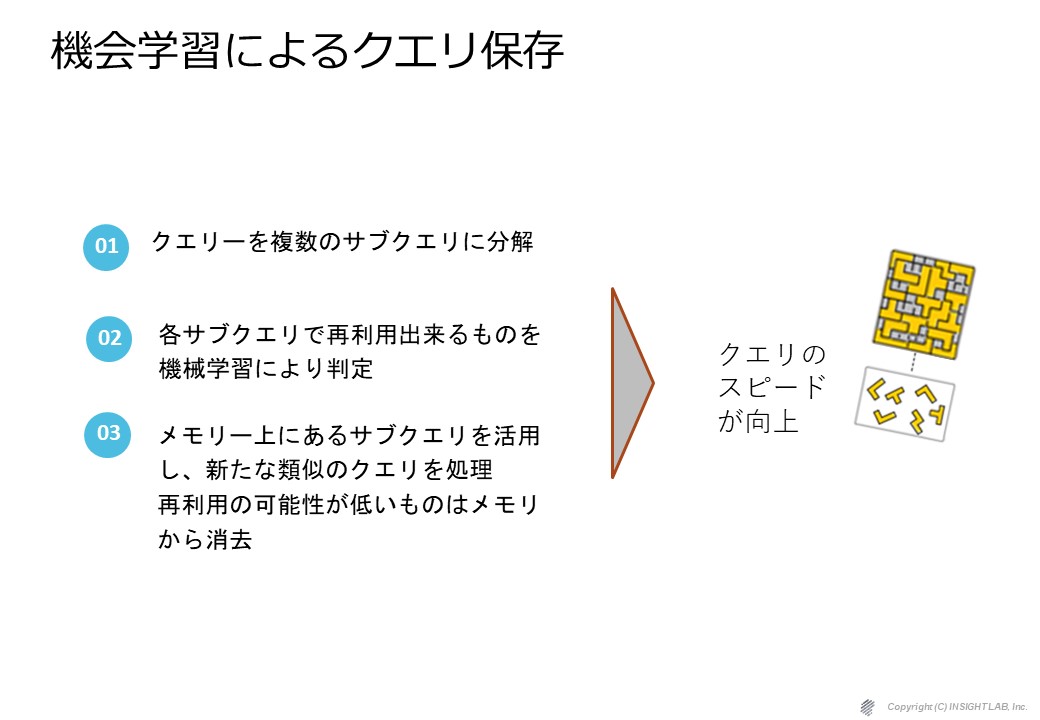
CPUのキャッシュは元々小さすぎないかという話なんですが、
そのために何をやっているかというと一つのクエリを複数のサブクエリに分解して最も使われる頻度の高いクエリを機械学習で判定してそれを指標に置くというような技術になっています。
そうすることでクエリーのスピードを向上させるという技術です。
それを支えているのがカラムナーですが、
通常のインメモリーのBI製品はディスクから丸ごとメモリーに転換して使います。
Sisenseの場合はカラムナーです。
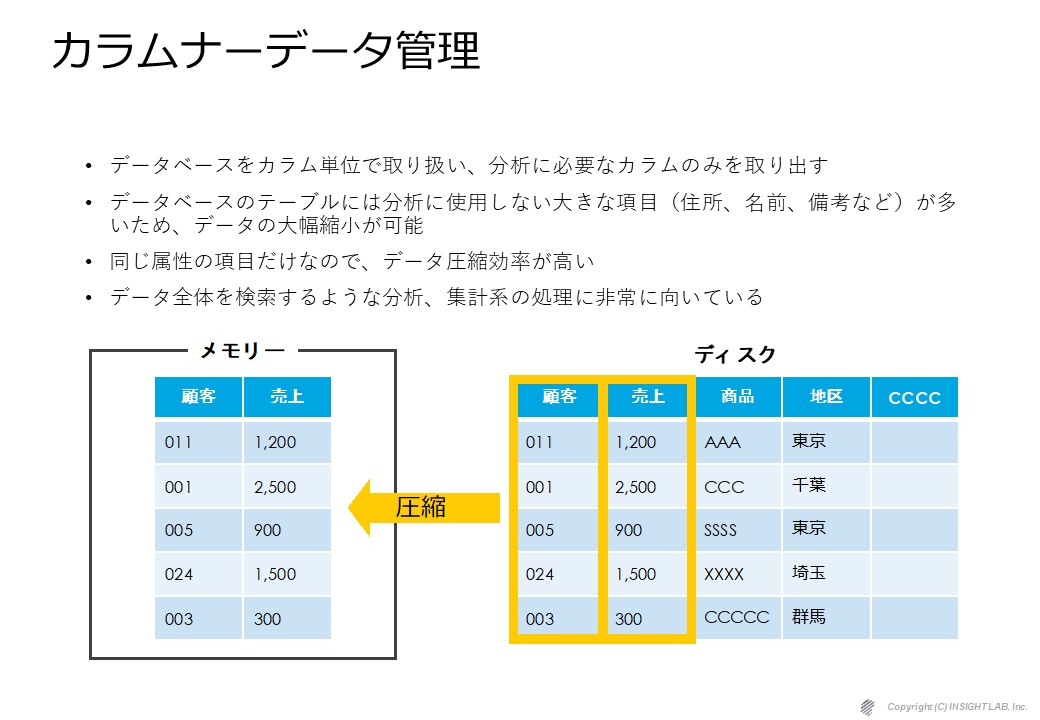
例えば顧客別の売上の集計を行う場合は関連するカラムだけしか持って来ません。
それを持ってきてメモリに展開、あるいはキャッシュに展開をして集計を行います。
使わないカラムはどこにあるのかといったら依然としてディスクにあります。
補足:Sisenseのビッグデータ処理におけるベンチマーク結果
補足として、Sisenseのベンチマーク結果をご紹介させていただきます。
10億レコードのベンチマークをアマゾンAWSの32 CPUの244ギガのメモリで行った結果ですが、クエリーの応答時間が平均で0.1秒最大で3.1秒という結果になりました。

メモリは、実際ディスク上には500ギガのファイルになっているものがメモリー上では100ギガしか使われず、CPUの平均的な使用率は10%から20%ぐらいということで、かなりBI製品の中では高速な製品であるということが実証されています。
詳細は、以下資料でまとめておりますので、ご参照下さい。
②Sisenseの特徴:埋め込み(Embedded)技術
①で紹介したインチップ技術は、それはそれで素晴らしい技術で、大いに価値はありますが、
ざっくり言ってしまえば、インメモリ技術の延長線でしかありません。
第3世代のBIツールの真骨頂は、なんと言っても埋め込み技術です。
今までも、組み込み分析や、エンベデッドアナリティクスと言った言葉で、存在はしていた機能や概念ですが、第3世代のBIツールは、埋め込み分析に最適化されたBIツールといっても過言ではありません。
埋め込み作業のイメージ👇
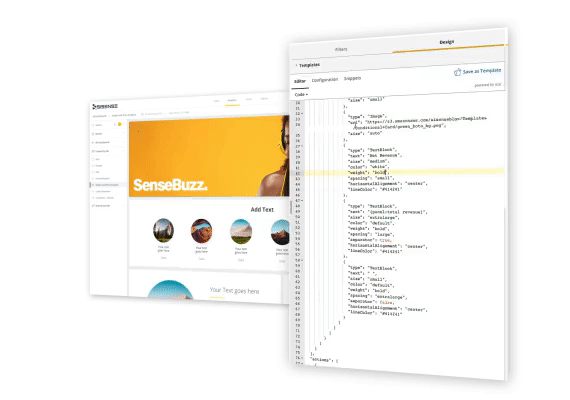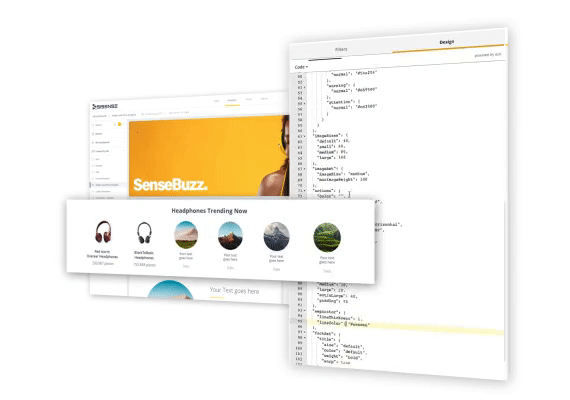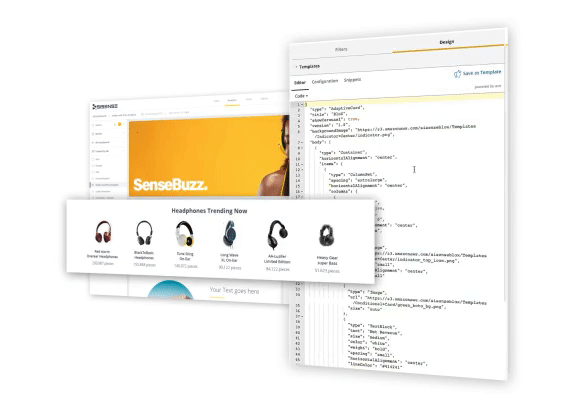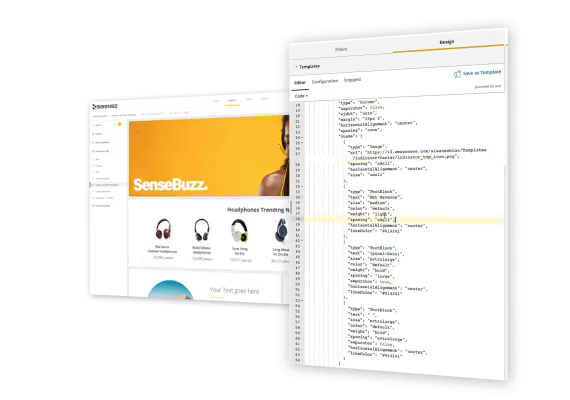
どうでしょう?
第二世代のBIツールで、こんな感じの埋め込み作業がイメージできますか?
Sisenseの埋め込み機能の特徴は、以下の3つ

- IFrame
HTML iframeを使用し、ダッシュボードとウィジェットを簡単に埋め込むことが可能 - Sisense.JS
ウェブのUIとSisenseのシステムをインタラクティブに連携ができる
iframe埋め込み用JavaScript APIキット - SDK
ダッシュボードをウィジェットに分解し、UIをカスタマイズしてもダッシュボードの属性が保持される埋め込み用のネイティブJavaScriptライブラリ
詳しくは、以下の記事で解説しています。
👉Sisenseの埋め込み分析機能【SaasにBIをEmbedded】
\ ⾃社プロダクトにOEMでBI実装を成功させる7つのステップ /

まとめ
第1世代BIツールは、ディスク自体がボトルネックになっていました。
第2世代BIツールは、第1世代BIツールが抱えていた問題点を解決し、とても扱い易いもので、現在、とても多くのユーザに利用されています。
第2世代BIツールが登場して10年以上経ち、デジタル化がさらに進む時代の中で、2つの大きな問題にぶつかりました。1つは、データ量も複雑性も増したビッグデータへの対応。2つ目は、BIツールそのものが活用されない現実と、セルフサービスBIの自由さがゆえのガバナンスの問題。
そのような難しい時代に登場した第3世代BIツールは、組み込み技術で業務の中に分析を同化させることで、BIツールを使うということを意識させずにビジネスユーザーに利用を促し、日々量も複雑さも増し続けるビッグデータは、インチップ技術によってCPUのキャッシュを有効活用するだけではなく、メモリとディスクも含めた全体のリソース管理を最適化することでそれらの課題を解決しようとしています。
今回はBIツールの概要を歴史を辿りながらまとめさせて頂きました。
INSIGHT LABでは、BIの選定から導入、運用までまるっとご支援しています。
BIツールを体験してみませんか?
INSIGHT LABでは、BIツールの無料紹介セミナー(動画)を配信しています。初めてBIツールをご利用される方を対象に、BIツールの概要や、複数あるBIツールの違いについて分かりやすくご説明いたします。

-3.png)