データ集計とデータ分析の違い
いきなりですが、問題です。
あなたはスーパーマーケットの売り場責任者だとします。
そして、取り扱い商品であるカレーについて以下のような2つの商品があるとしましょう。
- A社 レッドカレー 販売価格200円
- B社 ブルーカレー 販売価格200円
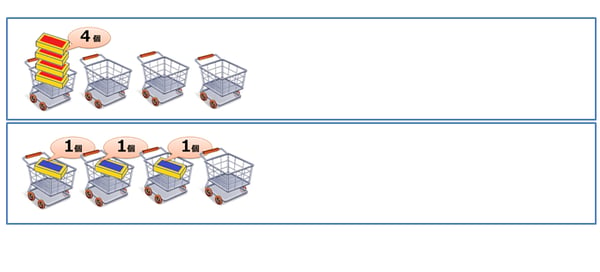
A社のレッドカレーはレジを通った計4名のお客様のうち、1名のお客様が4個購入しました。
一方B社のブルーカレーは同じく4名のうち、3名のお客様が1個ずつ購入しました。
この場合、あなたはレッドカレー、ブルーカレーのいずれのカレーを評価しますか?
…という問題です。
この問題には正解はありません。
ただし、一般的な企業の情報システムにおいて見逃しがちなポイントを端的に示す例として、弊社で開催しているセミナーなどで皆さんに考えていただいております。
単純に計算すると、A社のレッドカレーは売上が4個、ブルーカレーは1個ですので、レッドカレーのほうが売上が多いということになります。企業においても、日次、月次という集計期間で集計する場合、一般にはこのような計算結果しか導き出されません。
しかしながら、下図のように計算方法を変えてみたらどうなるでしょう。
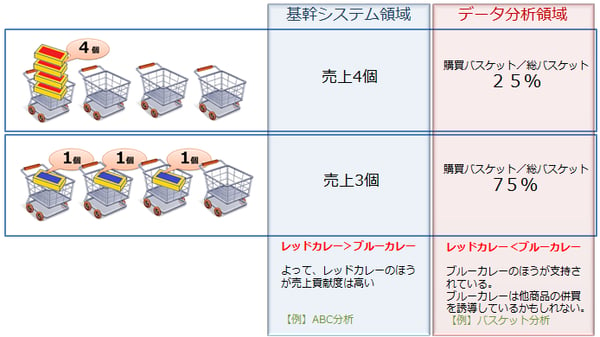
この図における「基幹システム領域」は一般的な売上集計方法です。
これに対し、バスケットという概念で計算し直した「データ分析領域」では、それぞれのお客様に購買されたか、されなかったかという「1」か「0」かという計算を施しています。
計算式は以下のようになります。
- レッドカレー … 購買バスケット数 / 総バスケット数 = 1 / 4 → 25%
- ブルーカレー … 購買バスケット数 / 総バスケット数 = 3 / 4 → 75%
この25%、75%という数値は、何を意味するでしょうか?
全体のお客様のうちどれだけのお客様が購入したかという点で考えると、この比率はその商品がどれだけのお客様に指示されているかを意味していると言えそうです。
一般に、上記のような分析方法をバスケット分析といい、特にスーパーマーケット業界などで使用されている分析手法です。
この方法はウォルマートにおいて「週末にビールを購入するお客様は同時に紙おむつも購入する」という、一見因果関係のない商品が同時購入される法則を見出したことに端を発します。
普通に考えても、「カレーが安ければ、今夜はカレーにしようと考え、同時に肉、玉ねぎ、じゃがいも、人参も買ってしまう」ことは容易に想像できます。
その時、支持されていない商品を安くするより、より支持されている商品を安くしたほうが効果的であるはずです。
企業においては月次実績表などで営業会議などをする企業は多いと思いますが、月間という期間で集計されてしまった数値は、これ以上細かく見ることは不可能です。あなたの会社ではいかがでしょうか?
データ集計は集計することが目的ですから、集計された結果の数値しか評価の対象としません。
しかしながら、その数値を正当に評価しようと思ったら、その背後にある様々な要因(「週末」という時間的要因や顧客要因など)が複合的に絡み合ってその数値が導き出されているという事実を重要視すべきです。もし結果しか見ないのでしたら、
それは部門の評価であったり、商品の評価を目的とした評価のための集計にすぎず、経営にとって何ら改善はなされないことになります。
このように結果しか見ない企業は「精神論」的経営に終始し、時に誤った判断を下すだけでなく、従業員のモチベーションをも下げ、内部崩壊を招いてしまう危険性をもはらんでいるともいえます。
データ分析とは
会議などで「○○部長からは鋭い質問が飛んでくる」などとささやかれる、視点の鋭い方はいるものです。
そのような鋭い方というのは、実務経験に裏打ちされた知恵を持たれた方といってよいと思います。
一方、IT部門などは一番システムのことを知っているにも関わらず、「集計する」「出力」することを仕事としているため、時に現場がほしい「視点」が理解できず、「現場はわがままばかり言う」とグチをこぼす方もいらっしゃいます。
全面的に現場を支持するわけではありませんが、
企業の情報システム(のデータ)によって、現場は制約を受けるのは事実です。
その図式をまとめてみました。
データ分析の要求
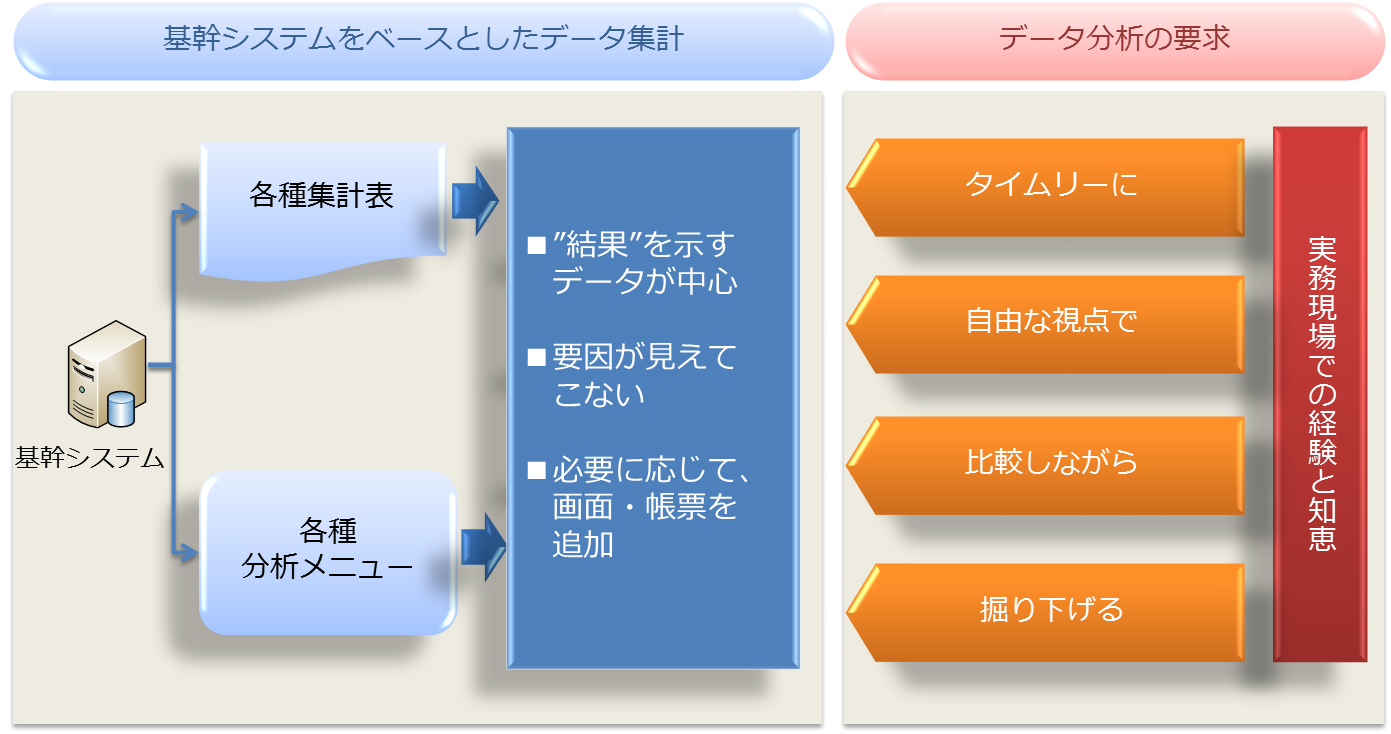
基幹システムは、企業内で必要となる指標をいち早く、正確に集計することを目的としています。いわばミッション・クリティカルなシステムです。このシステムに求められるのは、結果を出力することであり、データ構造自体が効率重視でできています。
一方、データ分析は基幹システムで出力された結果の要因を探ることが目的です。
この「分析」とは本来はコンピュータに頼らなくても、先に述べたような「実務現場での経験と知恵」を持つ人であれば「タイムリーに」「自由な視点で」「比較しながら」「掘り下げる」ということを実際に行なっています。
しかしながら、データが膨大になった場合、同じように分析することは不可能となりますので、コンピュータがその手助けをしてくれるのであれば、それに越したことはありません。
「データ分析システム=コンピュータが勝手に分析してくれる」というものではありません。
人間が結果を導き出した要因やプロセスを探索するために行う
「タイムリーに」
「自由な視点で」
「比較しながら」
「掘り下げる」
という行為をより迅速に正確に補助してくれるツールに過ぎません。
従って、私達が「データ分析してみましょう」とお勧めした時に
「そんなもの入れても何にもならない」とおっしゃる経営者の方もいらっしゃいますが、
それもそのはずで、分析を行う主体は人間そのものですから、分析できる人(つまり数値の意味を理解しようとする人)がいなければデータ分析システムなどを導入しても何も改善されないでしょう。
数値を見て改善する近道はシステムに頼ることではなく「データ分析の原則」をしっかり押さえ、企業内のデータの因果関係を探求する意識や企業文化の醸成であると考えます。
データ分析の3原則
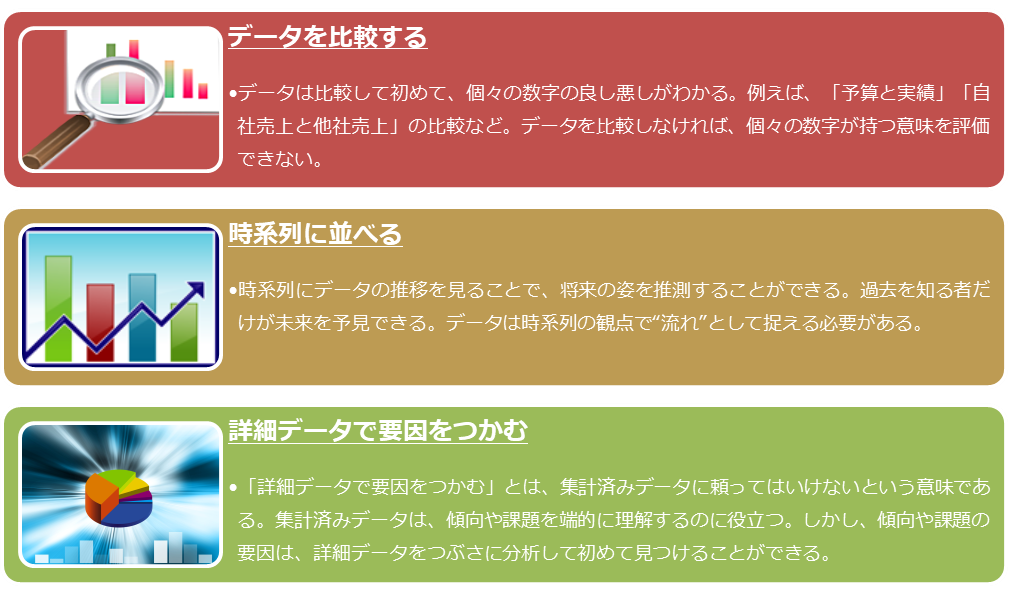
「データ分析の3原則」である①比較する、②時系列に並べる、③詳細データで要因をつかむについて、解説します。
(1) 比較する
データ分析の最初の原則は「比較する」ということです。
この比較するという方法は「予算対実績」「前年対比」「部門対比」「地域対比」など、企業内のレポーティングで頻繁に使用されています。この目的は比較することで、数値を評価することにあります。そもそも数字を漫然とみていても、その数値が良いのか悪いのか判断できません。比較する対象があって初めて、その数値の良し悪しが判断できるのです。
上記の「予算対実績」「前年対比」…というように列記した例は、企業内でも一般的なものですが、以下のようなものはどうでしょうか?
- 価格帯別の売上数量
- 1ケ月当りの売上金額別のユーザ数
- 来店頻度別の顧客数
先に列記したものと上記の3つは、分析の軸に用いる項目の性格が異なります。通常は分析の軸はデータの項目そのものですが、上記の3つでは分析の軸自体が「集計値」になっているわけです。集計値を軸に分析を行うことで、従来は見えて来なかった数値の良し悪しが見えてくることもあります。
このようにデータ分析においては「比較」することが重要であり、どのような比較を行うべきかは、様々な参考書や分析サンプルなどが参考になります。これらを参考にしながら、オリジナルの手法を確立していくとよいでしょう。
(2) 時系列に並べる
時系列で分析することも「比較する」ことに他ならないのですが、時間という軸の特性は値が連続しているということです。このように連続した項目の値を並べる場合は特に表より折れ線グラフのようなチャートのほうが直感的でわかりやすいですよね。ここで直感的に何を掴もうとしているかというと、それは「傾向」に他なりません。
何らかの分析をするとき、人間は分析の軸に「時間」という軸を重要視しがちです。それは「将来、自分はどうなるのか」という危機感にも似た、いわば本能のような欲求があるからだと私は思います。将来どうなるかは、これまでの時系列のデータの傾向を掴まなければ、予測できません。それは「過去」から「将来」に向けた流れであるからです。
月別売上集計表のような表も有効ではあるのですが、例えば12ケ月の数値を順番に見比べて行くのに比べ、チャートのほうが瞬時に把握できますし、何と言っても説得力が違います。また、「比較する」で述べたような「価格帯別」「売上金額別」「来店頻度別」などの集計値をデータ軸として使用することで、「高価格商品が売れなくなってきている」とか「客は増えているが、個々の売上額が減ってきている」といった新たな傾向も見えてくるかもしれません。
このように時系列分析は、データから様々な傾向を読み取り、対策を施すという点で、企業にはなくてはならない分析といえます。
(3) 詳細データで要因をつかむ
「データ分析とは」で記載したデータ分析の目的は、要因やプロセスをつかむことでした。何度も申し上げますが、基幹システムで集計された数値は結果を表しているにすぎず、要因はその裏に隠されています。
また、「(1) 比較する」、「(2) 時系列に並べる」ことで、数値の良し悪しや傾向を掴んだら、その内訳(要因)を知りたいというのは自然の欲求です。
しかしながら、データの最小粒度が大きければ大きいほど、要因を掘り下げるには限界があります。例えば「商品別集計は月でサマリされているから日別には出せない」というようなケースがあるかもしれません。また、「明細データは13ケ月しか持っていない」という企業も多くあります。
一般的に基幹システムなどのミッションクリティカルなシステムにおいては、資源(具体的にはCPUパワーやメモリ・ハードディスクなど)の有効活用とパフォーマンス、システムダウンなどのリスク回避を重要視しますので、業務遂行に適したデータ粒度で、しかも保存期間なども制限してデータを保持しています。
このようなシステム環境で、詳細データで要因をつかむにも自ずと限界がありますので、ミッションクリティカルでない(例えば、システムダウンしても業務は止まらない)形態で、専用にシステムを導入したほうが効率的です(その方法論は後で述べます)。
さて、「詳細データで要因をつかむ」ケースについて考えてみます。
「比較する」「時系列に並べる」場合、その分析では様々な軸が考えられます。それは「比較する」で述べたとおりです。まずはその複合条件で絞込みができるかです。定型的なレポートは予め決められた指標の数値を把握するのに有効ですが、それを「商品カテゴリー」「時間」「地域」などの軸で絞り込んで即座にデータが表示できなければ、要因をつかむことはできません。定型的なレポートの場合、分析の視点が加わる度に、新たなレポートを作成するか、既存のレポートを改造する必要が出てくるでしょう。
また、離反している(離反しそうな)お客様の傾向を見るようなケースでは、様々な条件で離反傾向のある顧客層を絞込み、「それがいつ頃から始まったのか」、「性別は?」、「年齢層は?」、「地域は?」、「購買していた商品は?」とつぶさに見ていくことで、内的要因、外的要因が見えてくる可能性が高くなります。
このような顧客のセグメンテーション化は顧客層を把握するだけでなく、プロモーション施策を打つ上でも有効です。ダイレクトメールやメルマガを闇雲に送付しても、受け取る側は迷惑でしかありません。そこで、顧客のシチュエーションに合わせたメッセージを送ることで、費用を抑えながら、効果的なプロモーションをすることができます。
データ分析の意義・メリット
データ分析によって、どのようなメリットがもたらされるのでしょうか?
実際には数多くの利点がありますが、ここでは以下の2つに分けて考えてみましょう。
現状の把握
データ分析の意義は、何と言っても今何が起きているか、自社のビジネスがどのような状況にあるのかなど、現状を把握できることです。
データがない場合には、数値化したり可視化することが困難であり、客観的に状況を捉えることができません。データから状況を把握できなければ、不確実性の高い感覚に頼るしかありません。
しかし感覚は人によってばらつきがあり、信頼性が乏しいケースも多々あります。そのような状況下で意思決定を下すことは、失敗するリスクも大きく、企業にとっては好ましくありません。
実際、現在のようにIT技術が発達していなかった時代には、ビジネスの全体像を俯瞰することも難しく、市場のトレンドや特異的な変化を捉えることも困難でした。
同時にある程度の規模の企業では、自社内の状況を把握するのでさえ苦労することが多く、業務効率の最適化や経営状況の把握、次年度の計画なども限定的な範囲で、かつ不確実性の高い状況で行わなければなりませんでした。
現在は技術進展やスマートデバイスの普及によって、SNSなどから市場のトレンドをリアルタイムで取得することができ、瞬時に顧客ニーズを解析することが可能になりました。
また企業内の各種手続きでは、これまでプリントされた紙媒体で行われていた作業が電子化されることで、内容を数値データとして処理することが可能になり、様々な切り口で分析できるようになりました。
これらのデータを分析することにより、ある作業に費やされる時間や工数を把握して人員配置を最適化したり、無駄な作業を特定して削減したりすることで、業務改善を実現することもできるようになります。
また外部データからの市場の声を拾い、自社の戦略がターゲット顧客のニーズに合っているのかを随時確認したり、乖離があった場合にすぐに修正をするなどのアクション取ることができます。
スピードが重視される現在のビジネスにおいて、現状把握と計画の早期修正ができる体制は、不可欠な要素となっています。
将来予測
データ分析の2つ目のメリットは、将来の予測に役立てることができる点です。
将来予測はビジネスの成功に重要な要素の一つですが、予測には高い正確性が求められます。もちろん将来の状況に100%の精度で一致することはあり得ませんが、可能な限り関与する要因を考慮して予測を立てることが重要です。
例えば小売店において、ある月の売り上げを予測したい場合、過去数年間の売り上げの実績値を年月別に比較することで、トレンドを把握し、今年の当該月の売り上げを予測することができます。
当然その年特有のイベントや社会的な動きに影響を受けるため、それらの要素を予測に含めることでさらに精度は高まります。一般に分析に利用できるデータ項目が多ければ、それだけ予測精度も向上する可能性が高まります。
データ分析の手法
データを分析する手法は無数に存在しますが、目的に応じて頻繁に利用される主要な分析手法が存在します。ここでは、ビジネスにおいて利用される典型的な手法を3つ紹介します。
クラスター分析
クラスター分析は、マーケティング領域でもよく使われる分析手法であり、3つ以上の多変量データが含まれるデータセット中から予測や分類などを行う多変量解析の一手法です。
例えば顧客をセグメンテーションしようとした場合、データを見ても特性に明らかな違いが見られず、どのような切り口で分類するか見当がつかないことがあります。
クラスター分析は、このような時に情報量を減らし、共通のパターンを発見して分類をサポートします。
回帰分析
こちらもあらゆる分野で頻繁に使われる分析手法ですが、2つの要素の相関関係を明らかにする際に用いられます。
ある小売店の販売に関するデータがあり、顧客一人当たりの購買金額や来店頻度、性別、年齢などの顧客属性が含まれている場合、回帰分析をすることにより購買金額と強い相関のある要因を明らかにすることができます。
例えば顧客一人当たりの総購買金額と来店頻度に強い相関関係があることが分かった場合、来店頻度を増やすことで一人当たりの総購買金額が高くなり、利益向上が期待できます。その結果、来店頻度を増やす施策について検討することができます。
コンジョイント分析
一般に顧客が製品やサービスに望むものは多種多様で、すべての要望を満たすことはできません。
コンジョイント分析はこのような場合に、どのような組み合わせで搭載する機能や価格を設定すればよいかを決めるための分析です。
例えば顧客が搭載候補となる機能や価格などについて、どの程度重視しているかを項目ごとに相対的な重要度として可視化することができます。この結果を新製品のデザインや価格、機能を決める際の参考にします。
データ分析のコツと注意点
上述したように、様々な切り口でデータを分析することによって、ビジネスに有用な結果を得ることができます。
しかし一方で、データさえあれば分析ができ、よい結果を得られるというものではありません。データ分析をする際には、目的を明確化することが大切です。目的に合った適切なデータを用意し、最適な分析手法を選択することで初めて有益な結果を得ることができます。
そして分析結果は最終的にビジネスの改善に結びつかなくてはなりません。データ分析は、あくまで現状把握やビジネスの意思決定に有益な情報を提供する手段であって、データを分析すること自体が目的ではありません。
まずはデータを用いてどのような分析結果を得たいのか、そしてその結果をどのように利用するかを明確に定義し、仮説を立てるところから始めましょう。この部分が明確になっていれば、有益なデータ分析を行うことが可能になります。
まとめ
ここまでデータ分析の基本や注意点について解説してきました。
日々のビジネスの中でデータは蓄積され、これらを活用して利益向上を目指すことは、どの企業でも始まっています。
しかし、実際に業務改善を実現したり、データから新たな知見を見出して継続的に利益の向上を実現している企業はまだまだ少ない状況です。
企業全体で、データ分析に対する理解とデータ活用の意識を高めなければ、理想的なデータ利用環境を構築することは困難です。本記事が、皆様のデータ分析に対する理解を深める助けになれば幸いです。
BIツールを体験してみませんか?
INSIGHT LABでは、BIツールの無料紹介セミナー(動画)を配信しています。初めてBIツールをご利用される方を対象に、BIツールの概要や、複数あるBIツールの違いについて分かりやすくご説明いたします。

-3.png)