はじめに
データの準備が終わったら、データを使った分析です。実際の段階ごとに解説します。まずは課題発見の手法としてフレームワークを紹介します。
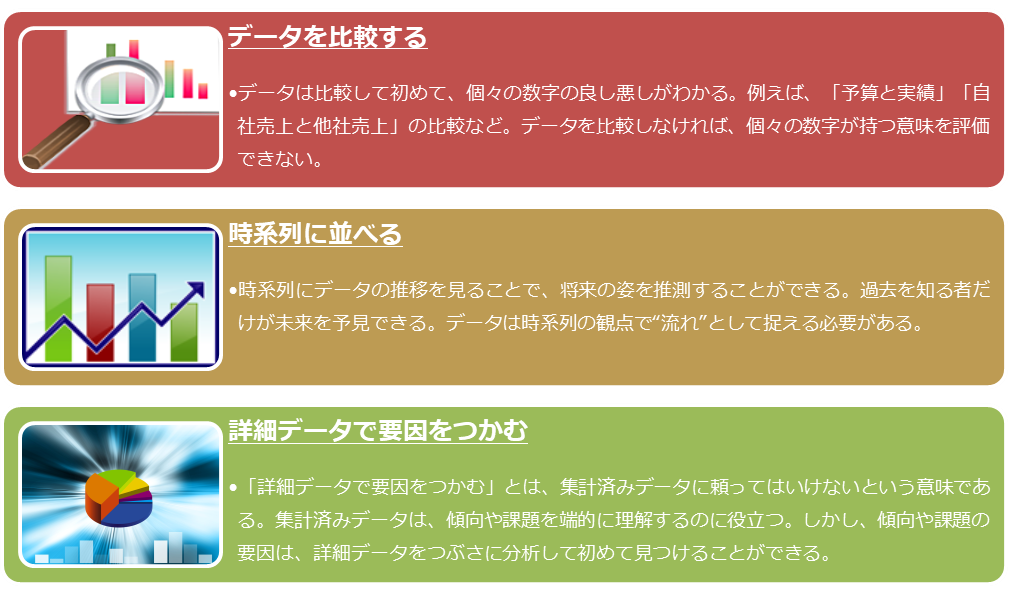
先人が積み重ねてきた分析手法が数多くあります。この枠組みに現状を当てはめてみて、そこから分析に使うデータをあぶりだしていきます。このデータを計算し、だれもが直感的に判断できるように可視化するという段階が分析の核心部分になります。その可視化は10のパターンに集約できます。
何をなぜ分析するのかを確認する
分析結果は、最終的に人間が判断を下す材料となります。人間が正しい意思決定を下すサポートとして使えない分析は、無意味です。
まず、何を明らかにする分析かを明らかにしなければなりません。アナリティクスの世界ではディメンションと呼びますが、切り口、分析軸とご理解下さい。そしてそのディメンションにしたがってメジャー(測定値)を設計・算出して、判断材料とします。ディメンションとメジャー、この組み合わせの出来が分析の成否を決定づけます。
構造としてはじつにシンプルにできていますが、これは人間の思考からしかうまれてきません。どんなに分析ツールが優れていても、コンピュータの能力が高くても、ディメンションとメジャーという土台がゆがんでいては、良い結果は得られません。まずはディメンションの作り方を順に追って解説します。
ステップ1 フレームワークで課題を発見する
何を分析するのか。これを明らかにする思考法をフレームワークと呼びます。ビジネスに関わるデータは、「こちらの記事で紹介したように」非構造化、つまり極めて多種多様なものがあります。そこから何を選び出すのか、特に分析対象の規模が大きくなるほど、漫然と対象を観察しただけでは課題が見つけにくくなります。目の前に巨大な山が出現したようなものです。
山を登るには、地図やコンパスといったツールが必要なように、データを体系化して整理するのがフレームワークを使って分析する目的です。
フレームワークはフレーム、つまり枠組みに当てはめて考えてみることが基本です。企業の活動や組織に共通した法則を抽象化しているフレームが、長い時間に数多く開発され、現場で実践されています。目的に応じて適切なものを選び、それを通して観察すれば、見落とすことも少なく全体を俯瞰できます。各フレームワークの特徴はフレームをはめる視点の違いにあります。
代表的な手法としては、「4P分析」「バリューチェーン分析」「3C分析」「SWOT分析」などがあります。マーケティングの世界では常識的な手法ですが、改めて解説しましょう。
4P分析 :4P分析の4つのPとは
製品(product)
顧客ターゲットに製品を差別化するための製品のあり方を決める。流通の場合は品揃え。製品のカテゴリー、市場における製品の位置づけ、性能や機能、サポートやアフターサービスに関するデータ
価格(price)
顧客にとっての価値に合った価格であり、かつ利益の出る価格。流通では値付けの方針と基準作り。競合を含めた価格、直接・間接のコスト、人気や品質の評価、希少性などに関するデータ
流通(place)
効果的・効率的な顧客へのリーチ方法。店舗配置、通販の選択、店員配置方針などのこと。販売拠点数、物流の能力とコスト、販売チャネル数、顧客の分布などに関わるデータ
プロモーション(promotion)
効果的・効率的な顧客への情報提供。広告や店内でのプロモーション、説明員の配置などマスから1対1まで内容は多岐にわたる。広告宣伝費、インセンティブや店頭プロモーションなどの販売促進費、ウェブサイトやカタログなどの制作費に関わるデータ
ほとんどの事業において、企業が取り得る手段は、この4項目に集約できると、マーケティング研究の世界的権威であり4P分析提唱者のフィリップ・コトラー氏は教えています。つまり、これは商品やサービスを4つの側面という枠組みにはめてみて検討するのです。そして、4つを変数として組み合わせて試行錯誤を繰り返すことで問題を発見し、解決します。組み合わせることをマーケティングミックスと呼びます。
バリューチェーン分析
バリューチェーン分析は、数々の競争戦略理論を打ち立てたマイケル・ポーター氏が提唱した、事業の競争優位性を分析するための思考法です。最初に日本に紹介された時点では「価値連鎖」という言葉が使われましたが、同じものを指します。バリューチェーンとは、どんな事業であっても企業活動は5つの機能に分解でき、これが連鎖することで価値が創造されるという発想法です。その5つとは
購買 製品の原材料の調達保管配分など
オペレーション 原材料を最終製品の形に変換させる活動
出荷 製品を保管、出荷し、買い手に届ける活動
マーケティング/営業 製品を買える手段の提供、買いたくなるように仕向けるプロモーション
サービス 製品の価値を高めたり維持するサービス
流通の場合は、購買を仕入れ、出荷を販売、サービスをアフターサービスと位置づければ応用できます。つまり、商品やサービスが生まれる時系列で分解するという考え方です。さらに、この5つの活動を支える支援活動として、企業インフラ(全体の管理)、人材マネジメント、技術開発、調達の4つのカテゴリーが全体に関わってきます。
これら9つの活動の各部分でどのように付加価値が生まれているかを検討することで、ライバルとの競争力がより詳細に正確に分析できるというのがバリューチェーン分析です。改善は各部分での問題解決を試みながら、連鎖する事業の全体の改善に繋げようと考えます。
実際の分析においては、雑多なデータがそれぞれ、9つの段階のどこに関わっているのかを見極めながら整理していきます。
3C分析
3C分析とは1982年に経営コンサルタントの大前研一氏が、日本企業の競争力を解説した英文の著書のなかで提示したツールです。
3つのCとは
- 顧客(customer)
- ライバル企業(competitor)
- 自社(company)
顧客は、時に市場にも読み替えられます。このCがもっとも重要です。市場はどこにあるのか、何が求められているのかを、最初に検討します。コーヒーという市場で考えてみましょう。
日本人になじみの深いコーヒーといえば、缶コーヒーでしょう。缶コーヒーの消費量は1990年代以降、一貫して減少しています。しかし、リキッドコーヒーと呼ばれるジャンルの商品が別にあります。ペットボトルや紙パックなどに入れられた、缶以外のパッケージの液体コーヒーです。この市場はスーパーでの安売りが増えたことなどが要因となって拡大しています。「ちびちび飲み」に対応したペットボトル入りが最近登場しているので、今後も伸びが予想されます。このリキッドコーヒーを加えれば、液体コーヒー市場は安定的に伸びているといえます。
2013年から、コンビニ店頭で挽き立てコーヒーが売られるようになりました。最大手のセブンーイレブンだけで年間10億杯が売られており、1杯100円としても年間1000億円。瞬く間に登場した巨大市場といえるでしょう。こうしたコンビニコーヒーの登場などに牽引されて、コーヒー豆の消費面から見た全体の市場は10年間で10%近く拡大しています。このどこを取るかで、市場の見え方は変わってきます。
これが次の2つのC、ライバル企業と自社の分析に関わってきます。ライバル企業はだれなのか。缶コーヒーならば、縮小している市場なので、新規参入は考えなくてもいいでしょう。既存メーカーとパイの奪い合いとなります。液体コーヒーとなると、コーヒーチェーンが店頭売りしている商品や乳製品メーカーのものもあります。主戦場はスーパーになるので、チャネルの考え方も違ってきます。コーヒー市場全体となると、喫茶店やコーヒーチェーン、コンビニエンスストアまでが対象となるでしょう。戦う相手がまったく変わってくるのです。
こうして特定したライバル企業と自社について「ヒト」(組織および人材の質や数、企業のカルチャーなど)「モノ」(製品サービスの質や価格、生産技術、研究開発、販売ネットワークなど)「カネ」(資金調達力と各部門の予算額、間接部門の陣容など)などの観点から比較し、競争戦略を立案してきます。
SWOT分析
SWOT分析は自らの分析に使われるツールです。戦略づくりではなく、現在置かれている状況を確認するもので、企業や組織ばかりでなく、非営利団体や個人にも適用できるとされます。
- 強み(strength)
- 弱み(weakness)
- 機会(opportunity)
- 脅威(threat)
これら4つの視点に分けて、現状を把握していきます。強み・弱みを内部環境、機会・脅威を外部環境と定義することもあります。内部環境については、技術力、ブランド力、価格競争力、設備、資産、販売チャネルなど、外部環境は景気、市場トレンド、法整備、他社の動向など、必要に応じて項目を立てて分析を行います。
ここから強みや機会を生かす、弱みや脅威を克服する方向で戦略を練り上げていくのですが、その際には別のツールが役に立ちます。
フレームワークには、これ以外にも有名な方法がいくつもありますが、ここで紹介するのは本題から外れます。ここで理解していただきたいのは、課題発見するためには、順を追ってこうしたツールを活用していけば、比較的容易に「正しい問い」を得ることができるのだということです。
既存の、先人の知恵によって確立されてきた「枠」に当てはめてデータを整理し、フレームが指し示す方向で「正しい問い」を考えていきます。それで完全な答えが出るほど単純ではありませんが、体感的には8割方、正しい方向が見えてくるものです。あとは個別の課題を詳細に検討しながら、ディメンションの設定を修正していけばいいのです。
評価の高い有名なフレームワークのツールは、どれも使いやすいものである半面、一見するだけで分かったような気になってしまいがちです。しかし、実際に使う場面ではデータの分類や選択に迷うことも多く、経験を必要とします。まずは自ら使ってみるとこが重要です。ここで、架空の事例を使って分析のプロセスを整理してみましょう。
全国展開している家電量販店A社。この会社の利益改善に取り組むことになったとします。フレーミングによって、以下の課題が浮かび上がってきたとします。
- 新規顧客の獲得は順調だが、売上高の伸びが鈍化している
- 全社レベルでのキャンペーンのレスポンス率が低下しているが、顧客層にキャンペーンが効いているかが分からない
今回は主に4P分析とバリューチェーンのフレームワークから、分析軸を以下の4つ設定しました。そうして次の段階に進みます
- 商品ディメンション(商品ジャンル別の集計)
- 部門ディメンション(販売部門ごとの集計)
- 時間ディメンション(販売日ごとの集計)
- 地域ディメンション(地域ごとの集計)
ステップ2 分析手順を決めてデータを整理する
マネジメントで重視されるのは、現場レベルでの達成すべき数値目標であるKPIです。後で詳しく説明しますが、各部門には、このKPIが数値として示され、その達成が求められます。
フレームワークで課題を発見したら、課題解決の目標数値を設定します。それがKPIであり、データ分析はKPI達成のために行うというのが基本です。つまり、データ分析は何のためにやるのかという問いに対しては、遠い目標としては「収益改善」であり「経営改革」なのですが、手の届く近い目標としてはKPIの達成があると考えるのです。そのためにビッグデータから分析に必要な項目をあぶり出してきます。これがメジャー、ここではKPIを構成する売上高や顧客数などの具体的な数値を明らかにするという作業です。
先に説明してきたように、使えるデータはさまざまな形式、多岐にわたる項目があります。そこから必要なものを決めるために、前段階でディメンションの設計、つまり分析軸の組み合わせを決めてあります。ディメンションが指し示す方向性に従ってデータを取捨選択していけば、迷うことも行き詰まることもありません。
分析するデータを用意して、データの組み合わせや計算など分析のための集計方法を定義し、ディメンションテーブルにデータをセットして、さまざまな組み合わせを試行錯誤する形で分析できる状態にしておくことが、データの整理と定義のゴールとなります。
今回の事例では、社内に蓄積されているデータ(これこそが本書が定義するローカルビッグデータです)から、必要なデータ項目を洗い出します。
今回の場合は、マーケティング部分での分析を行うので、ポイントカードを所持しており、個人の特性を把握できる顧客データを対象に
「店舗コード」「伝票番号」「受注番号」「受注日」「支払い方法」「提供ポイント」「出荷日」「顧客コード」「顧客住所」「受注数」「単価」「ブランド番号」
を抜き出してデータウェアハウスにまとめておきます。これを使って必要なデータを抜き出して処理します。それを目的別に整理されたデータ群がデータマートです。
ここで重要な作業がふたつあります。カテゴライズとKGI、KPIの設定です。
分析目的によって使い分けるカテゴライズ
各データのなかでの数値のグルーピング、それがカテゴライズです。たとえば商品コードは製造でも販売でも必ずついて回りますが、ほとんどは個別のコード番号です。クルマでいえば同じ車種でもグレードや色が異なれば番号が違います。靴下などになると、模様やサイズが違えば違う番号が与えられます。
商品の管理上は、ここまで細分化する必要があるのですが、分析する場合は逆効果になるのです。というのも、分析したいのは各サイズの靴下ではなく、「子ども向けの靴下」という商品群であり、クルマのブランドごとの動向なのです。商品群を大括りにまとめるカテゴライズをしないと、正しい傾向を見誤ることになります。そこで、商品コードの上位概念となるカテゴリーデータを探してくるか、あるいはデータを「丸める」必要があるのです。
この丸め方には、分析の目的が大きく関係してきます。地域というカテゴリーの場合、「関東」なのか「東京」「神奈川」「千葉」「埼玉」という都道府県別なのか、あるいは市区町村別まで必要なのか。関東に山梨を入れるのか入れないのか、新潟は東北なのか北陸なのかは、流通網や支社の管轄によって変わります。商品カテゴリーでは最新型の外国製掃除機は、掃除機なのか、インテリア家電なのか、白物家電なのか。これもマーケティング戦略によって変わってきます。
このようにカテゴライズの正解はデータ分析の目的によって決まります。一方で、細分化しすぎてデータが膨大になると処理速度が極端に落ちてしまうこともあるので、慎重に最適化して分析軸をまとめあげていかなければなりません。じつは、「とりあえず全部のデータを処理してしまおう」と、カテゴライズの作業を軽視して後で行き詰まってしまうケースが非常に多いのです。
最終目標のKGI、部分的目標のKPI
KGIとKPIの設定もこの段階の作業です。要するに、数値目標の設定です。KGIはKey Goal Indicatorの略で重要目標達成指標と訳されます。分析の最終的な数値のゴールです。どんな分析であっても仮説検証は、KGIの数値を達成できるかどうかで判断されなければなりません。
今回は収益改善をKGIとしていますが、KGIにこだわらなければならない理由は、部分の最適にこだわって最終的な目標が達成できないという事態が往々にして起きるからです。部分最適と全体最適のズレの問題で、これを「合成の誤謬」と呼びます。
バリューチェーン分析を例に取れば、購買のところで安い部品を使うことにしてこの段階での利益がアップしても、不良品の発生でサービス段階でのコストが上回り、全体での利益がダウンすることがあります。こうした事態を避けるための絶対的な目標がKGIです。
KPIはKey Performance Indicatorの略で、重要業績評価指標のことです。これはKGIを達成するために各ディメンションやチームに課す中間目標です。
KGIを直接の改善目標にすることはありません。分析や、分析結果から浮かび上がった課題はKPIを設定して、KPIの数字達成という形で目標が管理されます。KPIでも現場の担当者からすれば、漠然として行動に繋げにくいときもあります。その場合は、もう一段階、メジャーを定義します。たとえばKGIが「会社全体の利益率を10%アップ」とし、KPIを「現場の売上高を30%向上させる」と設定したとします。これでは現場が具体的なアクションを起こしにくいはずです。こういうときに「新規顧客獲得数を月間100人」「売れ筋商品の欠品をゼロ%」「優良顧客80%にキャンペーン期間中の来店をプロモーション」とすれば、アクションが見えてきます。ここまでがデータの整理です。
ステップ3 分析に使うデータを定義して計算する
ここまで準備ができれば、次にデータモデリングです。モデリングとは、分析に利用する変数を選ぶことを意味します。
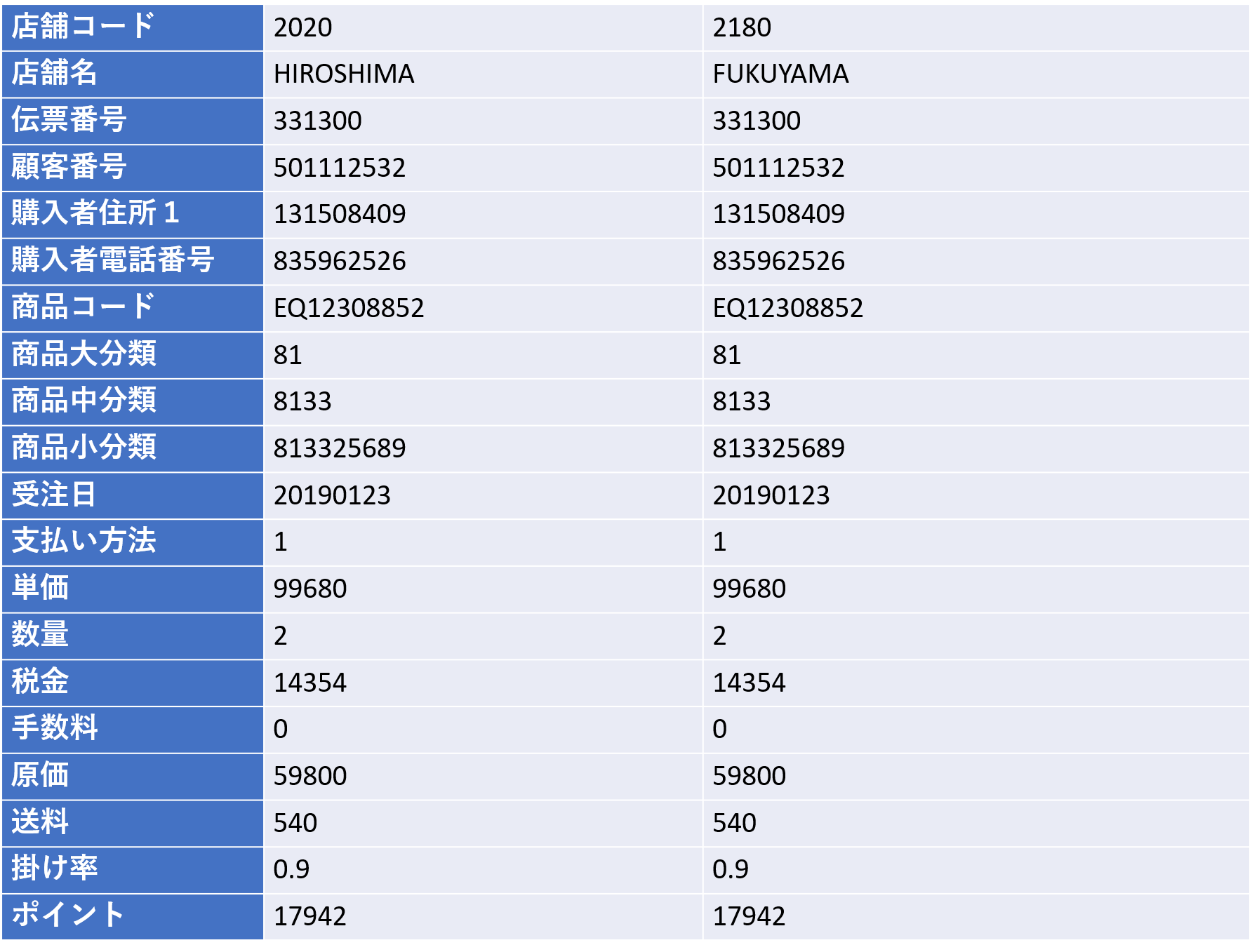
まずは検討するデータの計算式を設定します。ここで、前段階でファクトテーブル作製のために抜き出したデータ項目を下図で紹介していますが、この中に分かりやすく指標となる項目が少ないことにお気づきでしょうか。よくみると売上高や利益という概念の項目もありません。
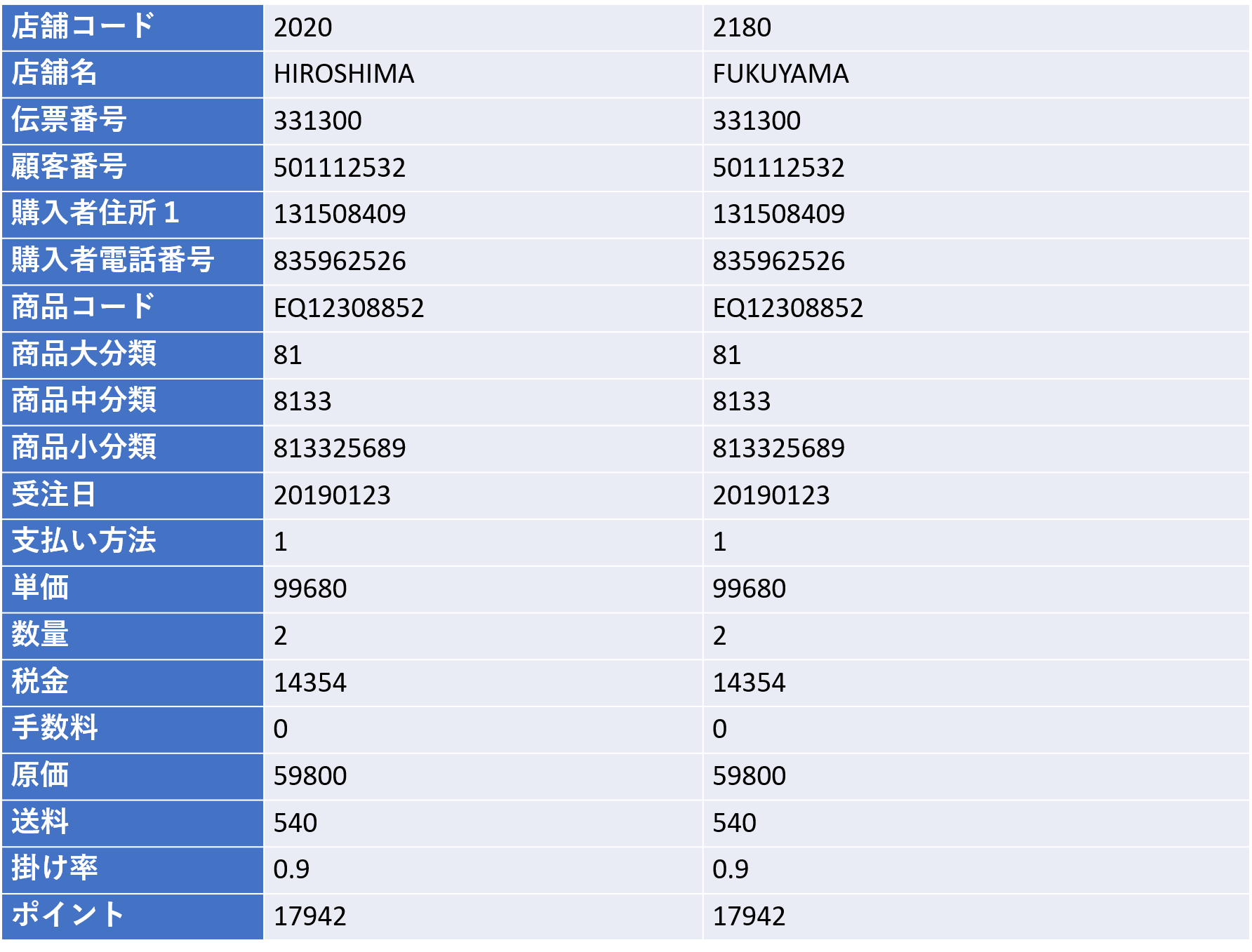
これがビッグデータの特徴の一つなのですが、データは業務の流れに従って自動的に生成されるものです。たとえば売上高のデータですが、生成されたデータは商品がレジを通った時点では、特定の商品が売れたという事実だけが記録されているにすぎません。この売れたというデータの種類と件数をカウントし、別に用意されている単価のデータを抜き出してきて算出をすることによって初めて売上高のデータができあがるのです。
このように、本来の目的ではない「分析」などにそのまま転用できる数値が揃っていることは、ビッグデータ上ではむしろまれで、分析の際には既存のデータを利用して定義をし、算出のための計算式を設定をする必要があります。これがモデリングです。
逆にいえば、発想次第で、一見役に立たなそうなデータからも、さまざまな指標を生み出すことができます。こうした指標の定義と算出は、分析の成否を分けるものです。
ちょっとした見方を変えるとデータが見つかることもあります。日経MJ2018年7月20日付けに面白い記事を見つけました。ストレス軽減を売り文句にした機能性表示食品のチョコレートの売上げ分析です。これによると、年齢・性別で分けた場合、もっとも多いのは30〜40代の男性。オフィス街で朝の時間帯に売れているので、出勤途中のビジネスマンであることが示唆されます。そして、「曜日ごとにみると月曜から徐々に購入が伸び、木曜にピークを迎える。金曜からは下落に転じ土日は大幅に下がる」と分析しています。
つまり、チョコレートの売れ行き動向から曜日ごとのストレス蓄積の度合いを示唆するデータを得ることができるのです。
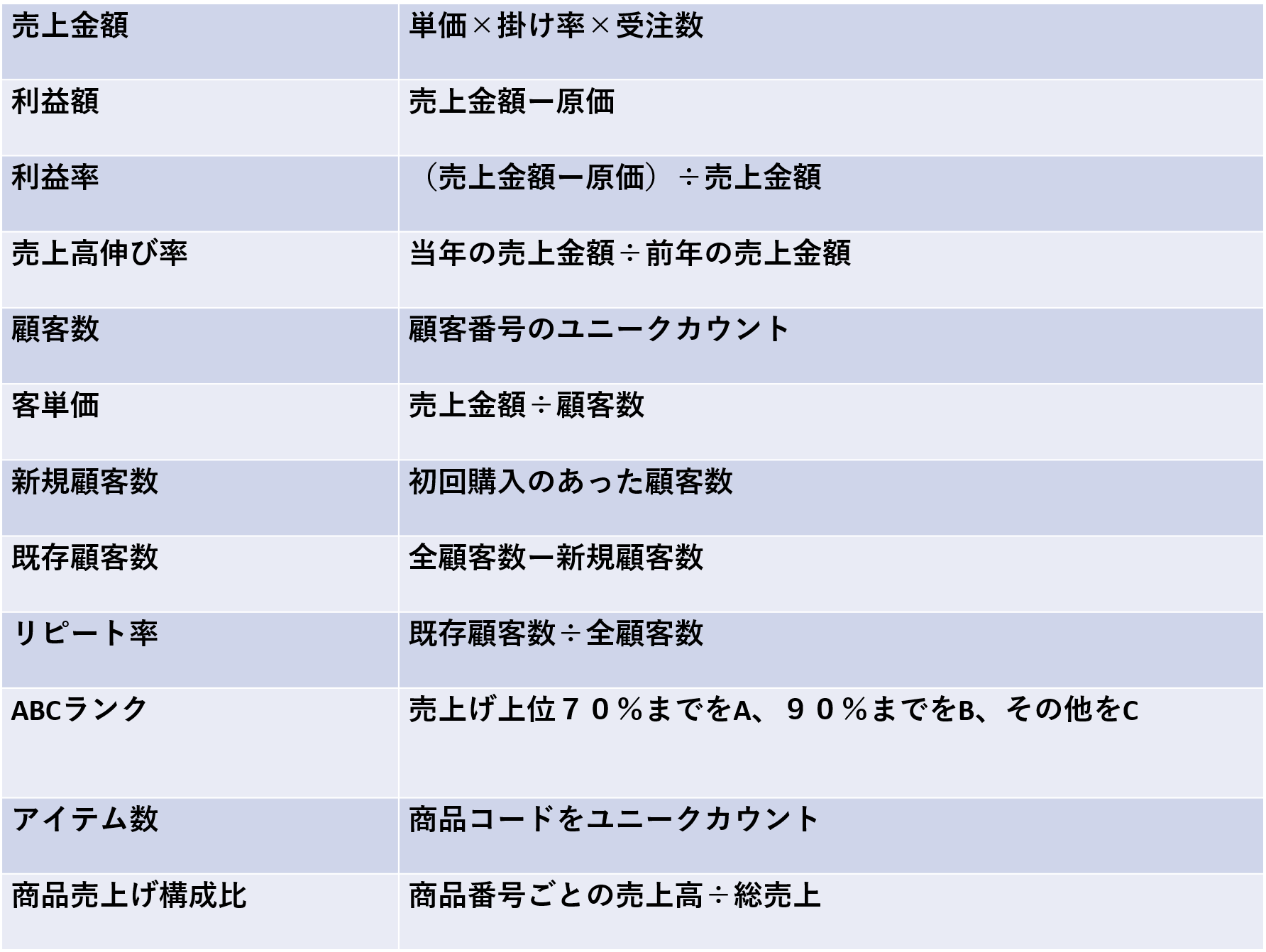
これは極端な例ではありますが、さまざまな場所にある既存のデータから、時に計算式を定義して数値を作成してディメンションテーブルに埋め込んでいくのですが、今回の事例の場合、図にあるように、設定した項目は12項目になりました。
その算出方法は、売上金額は「単価×受注数」、利益額は「売上金額ー原価」、客単価は「売上金額÷顧客数」、新規顧客数は「(カード保有のない)初回購入のあった顧客数」、既存顧客数は「全顧客数−新規顧客数」、ABCランク(集計対象を上位から一定割合でグルーピングして、その階層別に集計する手法)として「売り上げ上位から70%までをA、90%までをB、それ以外をC」などです。このようにして膨大なデータから課題の仮説検証に必要なデータを、項目の定義に従って作り上げていくのです。
様々なディメンションをクロス集計したり、フォーカスを変えて深掘りしながら、KPI、KGIを手がかりに収益改善の検討を何度も繰り返し行うことになります。考えられるだけの仮説を立てて、数字で検証する。ひたすらにそれを繰り返すことが最適解を見つける作業です。
ステップ4 判断を的確に、容易にする可視化
この段階では計算式から出てきた数字を縦横に組み合わせながら比較していきますが、高度な集計をするわけではありません。基本的には10パターンに集約でき、どんなに深い分析を行う際にも、裏側では、これら、もしくはこれらの組み合わせによって分析が行われているのです。
- 単純な値の比較(値比較)
- 単位の異なる値の比較(単位比較)
- 時系列で傾向を把握(時系列)
- 内訳・割合で比較(内訳)
- データ間の関連性を数値化(関連性)
- グルーピングして比較(グルーピング)
- プロセスを記録(プロセス)
- 空間に配置して関係性を表現(空間)
- リスト・順位を管理(リスト)
- 分析軸に選んだデータのクロス集計(クロス)
仮に今回の事例から仮説検証のパターンを考えてみます。KGIからさまざまなKPIを設定しておきますが、下の仮説とあるのが、そのひとつとお考えください。
仮説:広島店での企業向けパソコン販売の将来性はあるのか
検証:広島店での年度末に当たる各年3月のパソコン販売額を全国各店舗と比較する
仮説:キャンペーンは効果を発揮しているのか
検証:キャンペーンを実施した月における、各地域ごとの商品ジャンル別売上高伸び率をランキングする
仮説:顧客の購買行動に変化が起きていないか
検証:10年間のデータを比較して年齢層別顧客数や購買商品の変化をみる
など組み合わせはさまざまです。それらがKPIを達成しているか、あるいは達成する可能性があるかどうか、達していなければ改善すべき策はあるのかを検討して、新しい戦略に組み直していく作業が分析の実際です。
しかし、ここで終わりではありません。可視化による分析のためには、視認性の高さと操作性も重要なポイントとなります。特に意思決定層や現場の担当者が統計分析やパソコン操作に通暁していることはむしろまれだと考えておかなければなりません。かといって、意思決定の現場に担当者が立ち会って、リクエストに応じてデータをいじり回すというのも現実的ではありません。だれでも気兼ねなく利用できる使いやすさ、分かりやすさはシステムの稼働率に大きく影響するのです。
データ分析をビジネスに生かすことを早くから提唱し、「アナリティクス界のドラッカー」と呼ばれるトーマス・H.ダベンポート氏は、著書『真実を見抜く分析力』(日経BP社 2014年)のなかで、分析の結果に対して幹部社員は以下のような質問をすべきであると例示しています。
この結果で意外な点はどこか?
この結果を再確認する、あるいはそれを否定するために、さらに分析してもらえるか?
この新しく得られた結果に取り組むために、他の人々も関与させるべきか?
重要な洞察が見えてきたか?
この結果が真実だとわかったら、この問題に対する私の考え方はどう変わるか?
(同書292ページ)
この場合、分析担当者と意思決定者(幹部社員)は役割分担しているという前提で、分析の進め方が解説されています。本書のローカルビッグデータの分析の場合は、意思決定者自身がBIツールの助けを借りて、「問い」と「答え」は自分の中で繰り返しながら、仮説と検証から答えを見いだすところが違います。その意味で視認性は、上記の「問い」と「答え」が一人の人間の中で生まれやすいよう設計しなければならないという方向性が見えてきます。
ユーザーを納得させてアクションに移す気にさせるユーザーエクスペリエンス(UX)、視覚に強く訴えて理解を深めるためのユーザーインターフェース(UI)の作成テクニックは、効果的なプレゼンテーション資料の場合と同じですが、以下の点を意識して作成すればよいでしょう。
チャート分析の基本10パターン
- 分析シナリオを意識した構成
- レイアウトポリシーの決定
- 利用者のモニター解像度に合わせたサイズ設定
- 最適なフォントとサイズ、カラー
- 情報過多を回避
- 空白を有効活用
- 簡潔な説明、コメント付与
- 色使いのルールの決定
- Eye Candyの戒め
- 画面表示時間を短縮
詳しくは、以下ページを参照下さい。
以下ページでは、分析の具体な手法について紹介していきます。
BIツールを体験してみませんか?
INSIGHT LABでは、BIツールの無料紹介セミナー(動画)を配信しています。初めてBIツールをご利用される方を対象に、BIツールの概要や、複数あるBIツールの違いについて分かりやすくご説明いたします。