データ準備 - 機械学習モデルの作成
まずは、Pythonを使い機械学習モデルを作成していきます。
実は、前回アクセスしたDBには機械学習分野でよく利用されるデータセットであるアイリスデータセットの一部がテスト用データセットとして存在していました。
事前にScikit-learnからデータセットを入手してテストデータセットと教師データセットに分けています。
以下のコードはデータ準備用のPythonコードになります。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df = df.rename(
columns={
'sepal length (cm)': 'SEPAL_LENGTH',
'sepal width (cm)': 'SEPAL_WIDTH',
'petal length (cm)': 'PETAL_LENGTH',
'petal width (cm)': 'PETAL_WIDTH',
'target': 'TARGET',
}
)
df['index'] = df.index
train_df = df.sample(frac=0.7)
train_index = train_df['index'].tolist()
train_df = train_df.drop('index', axis=1)
train_df.to_csv('data/iris_train_dataset.csv', index=False, encoding='utf_8_sig')
test_df = df[~df['index'].isin(train_index)]
test_df = test_df.drop('index', axis=1)
test_df.to_csv('data/iris_test_dataset.csv', index=False, encoding='utf_8_sig')
print(df.head())ここでは、教師データとテストデータの比率を7:3としています。
この内、テストデータに関しては事前にSnowflake上にアップしています。
実際にデータの内容としては、以下のようなものとなっています。
| SEPAL_LENGTH | SPEAL_WIDTH | PETAL_LENGTH | PETAL_WIDTH | TARGET |
| 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 7.0 | 3.2 | 4.7 | 1.4 | 1 |
| : | : | : | : | : |
| 6.5 | 3.0 | 5.2 | 2.0 | 2 |
このデータセットは、アヤメのがくの幅と長さ、花弁の幅と長さから3つの品種を分類するという問題設定がなされています。
なので、0-2の値をとるTARGETが今回の目的変数になり、それ以外のカラムが説明変数となります。
では、このデータセットを使いロジスティック回帰での分類モデルを作成していきます。
以下、モデルを作成するPythonコードになります。
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn2pmml.pipeline import PMMLPipeline
from sklearn2pmml import sklearn2pmml
from sklearn.model_selection import cross_val_score
train_df = pd.read_csv("data/iris_train_dataset.csv", encoding='utf_8_sig')
train_data = train_df.drop('TARGET', axis=1).values
train_label = train_df['TARGET'].values
model = LogisticRegression(max_iter=200)
model.fit(train_data, train_label)
scores = cross_val_score(model, train_data, train_label, cv=5, scoring='accuracy')
records = [[index+1, score] for index, score in enumerate(scores)]
records = pd.DataFrame(np.array(records), columns=['try-num', 'score[accuracy]'])
print(records)
print('5-Foled-Cross-Validation average score: {}'.format(scores.mean()))
pipeline = PMMLPipeline([
(
"classifier",
LogisticRegression(max_iter=200)
)
])
pipeline.fit(train_data, train_label)
sklearn2pmml(pipeline, "models/LogisticRegression.pmml", with_repr=True)上記のコードは、ロジスティック回帰での分類モデルを作成すると同時に交差検証での評価も行っています。
今回利用した評価指標としては、accuracyを利用しています。
実行結果は以下の通り
try-num score[accuracy]
0 1.0 1.000000
1 2.0 0.952381
2 3.0 0.952381
3 4.0 0.952381
4 5.0 0.904762
5-Foled-Cross-Validation average score: 0.9523809523809523正答率9割程度のモデルが完成しました。
また、分類モデルを作成するとモデルの内容を記述したPMMLファイルが出力されます。
このファイルをSnowparkにアップすることで推論実行が可能になります。
UDF実行の為の依存関係ライブラリ準備
先ほど作成したPMMLファイルを利用できるようにUDF内で利用するライブラリを準備します。
今回必要となるライブラリは以下の通りです。(コチラからダウンロードできます。)
ここで注意ですが、利用しているScalaのバージョンを合わせてダウンロードする必要があります。
- pmml4s
- spray-json
- scala-xml
また、PMMLファイルもjarファイルへの変換が必要となります。
実行コマンドは以下の通りです。
jar cvf iris_model.jar LogisticRegression.pmml実行するとiris_model.jarが生成されます。
入手したjarファイルに関しては、src/main/resource配下に配置しておきます。
SnowparkのUDF機能での推論実行
さて、事前準備は済みました。
機械学習の推論が実行できるUDFをScalaで実装して実行しましょう。
src/main/scala/Main.scalaを以下の様に書き換えます。
import com.snowflake.snowpark._
import com.snowflake.snowpark.functions._
import com.snowflake.snowpark.types._
import com.typesafe.config._
import org.pmml4s.model.Model
class IrisLogistic extends Serializable {
val rfFunc = (
sepal_length: Double,
sepal_width: Double,
petal_length: Double,
petal_width: Double) => {
import java.io._
var resourceName = "/LogisticRegression.pmml"
var inputStream = classOf[com.snowflake.snowpark.DataFrame]
.getResourceAsStream(resourceName)
val model = Model.fromInputStream(inputStream)
val v = Array[Double](sepal_length, sepal_width, petal_length, petal_width)
val pred = model.predict(v).map(_.asInstanceOf[Double])
model.classes(pred.indices.maxBy(pred)).toString()
}
}
object Main {
def main(args: Array[String]): Unit = {
// Replace the below.
val conf = ConfigFactory.load()
val configs = Map (
"URL" -> conf.getString("snowflake.url"),
"USER" -> conf.getString("snowflake.user"),
"PASSWORD" -> conf.getString("snowflake.password"),
"ROLE" -> conf.getString("snowflake.role"),
"WAREHOUSE" -> conf.getString("snowflake.warehouse"),
"DB" -> conf.getString("snowflake.db"),
"SCHEMA" -> conf.getString("snowflake.schema")
)
val session = Session.builder.configs(configs).create
println("d")
val libPath = new java.io.File("").getAbsolutePath
session.addDependency(s"$libPath/src/main/resources/pmml4s_2.12-0.9.11.jar")
session.addDependency(s"$libPath/src/main/resources/spray-json_2.12-1.3.6.jar")
session.addDependency(s"$libPath/src/main/resources/scala-xml_2.12-1.2.0.jar")
session.addDependency(s"$libPath/src/main/resources/iris_logi.jar")
val df = session.sql("select * from IRIS_TEST")
df.show()
val transformationFunc = new IrisLogistic
val irisTransformationUDF = udf(transformationFunc.rfFunc)
val dfFitted = df.withColumn(
"predicted_label", irisTransformationUDF(
col("SEPAL_LENGTH"), col("SEPAL_WIDTH"), col("PETAL_LENGTH"), col("PETAL_WIDTH")
).cast(new DecimalType(38, 0))
)
dfFitted.write.mode(SaveMode.Overwrite).saveAsTable("predicted_iris")
}
}上記のコードは、事前にSnowflake上に配置していたIRIS_TESTというテーブルを読み込み、モデルを適用して"predicted_label"というカラムを追加して"predicted_iris"というテーブル名で保存しています。
結果をSnowflake上で確認してみましょう。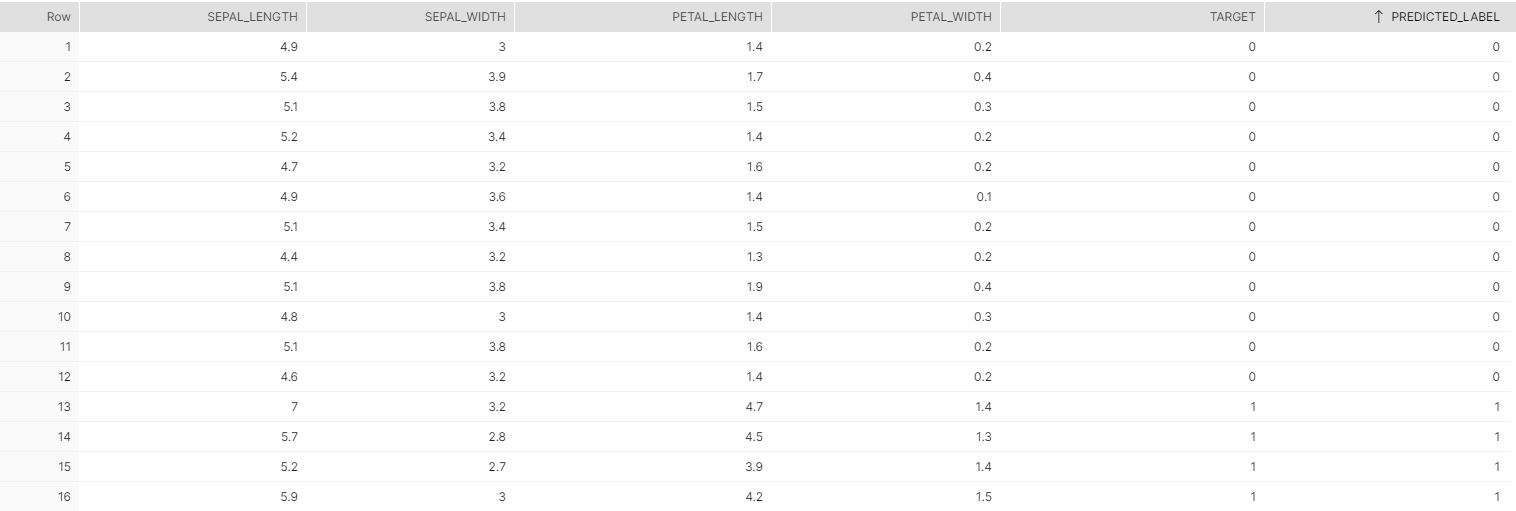
推論結果が無事反映されていますね。
ざっと見た感じほぼ正解していたのでPythonで作成したモデルでの推論実行されていることが分かります。
まとめ
Snowflake上での機械学習実行できましたね。
触ってみた所感としては、Scalaでの実行環境が必要なのである程度のScalaやJavaに対する知識が必要だと感じました。
Snowflakeで機械学習モデルの推論が可能になるというのは、かなり大きいインパクトになりえる機能だと認識しています。(個人的にはPythonがそのままつかえたら嬉しいですが、、、)
今後とも注目の機能であるSnowpark、何か新しい動向がありましたら紹介していきたいと思います。
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。