


こんにちは、皆さん。
最近SnowVillageに出演させていただいてSnowflakeの味を占めたBudoこと荻本です。
Snowflake×機械学習に関して色々と調べていくと、とあるキーワードが目につきました
「Snowpark」
なんぞこれ?
どうやら、AWSホスティングされているSnowflakeアカウントであれば利用できる機能のようです。(2021年9月現在)
また、データをわざわざローカルに移動させなくともSnowflake上で処理できるアプリケーションを作成することができるようです。(現在はScalaでのみ利用可能)
つまり、自作のScalaで書いた処理をSnowflake上の計算リソースで実行できる機能ということです。
これにより、Snowflakeでは出来ない込み入った処理やPMMLを利用した機械学習モデルの推論処理がSnowflake上のデータに適用可能となります。
ということで、今回はSnowparkで開発できる環境を作り、テーブルにアクセスするとこまでやってみようと思います。
Metals導入-プロジェクト立ち上げ
今回はSnowparkの公式ドキュメントにも記述があったMetalsというVS Codeで使えるJava/Scala環境プラグインを使います。
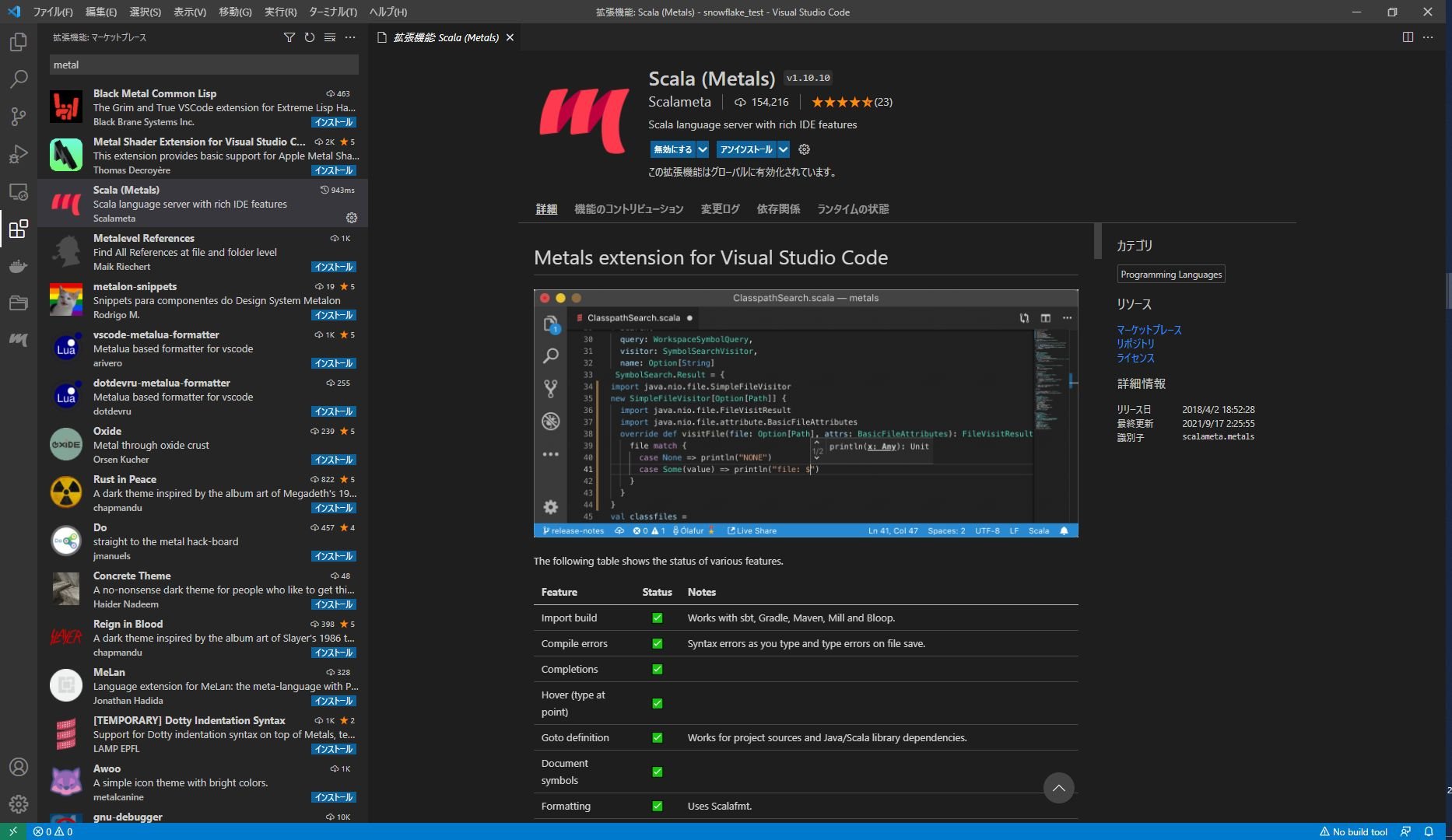
VS Codeの[拡張機能]のアイコンをクリックし、「Metals」と検索すると「Scala(Metals)」というプラグインが出てくるのでインストールします。
インストールが出来たら左側のタブにMetalsのアイコンが出てきますので、アイコンをクリック。
すると左側にMetalsのタブが出現します。
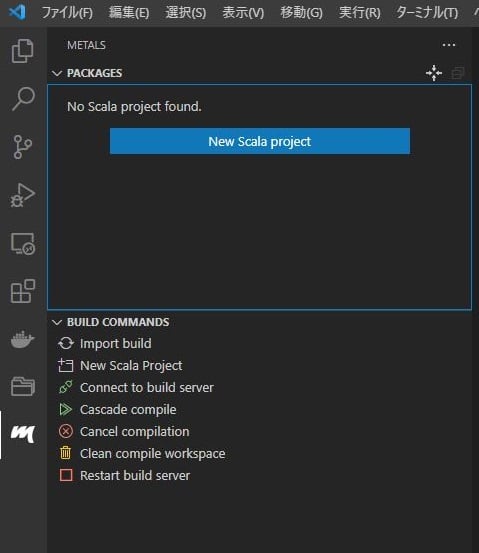
ここで[New Scala project]をクリックすると以下のような選択肢が出てきます。
これは、プロジェクトのテンプレートを選択可能な状態です。
今回は、「scala/hello-world.g8」を選択します。
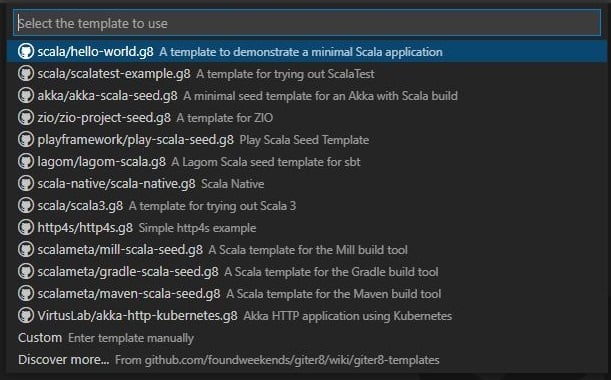
すると次は、ワークスペースディレクトリを聞かれるので任意のディレクトリを選択します。

次にプロジェクト名を入力します。

その後、右下に以下のような選択肢が出てくるので[Yes]を選択すると別ウィンドウでプロジェクトが開きます。
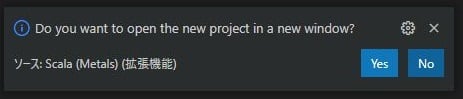
新しく開いたウィンドウでbuildをインポートするか聞かれるので、[Import build]を選択します。
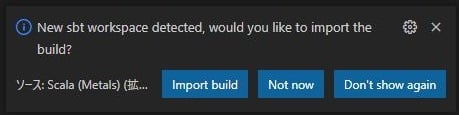
以上で、Scalaのプロジェクトが立ち上がりました。
ここで、src/main/scala/Main.scalaを開いて動作確認をします。
上記の開いたエディタ上で「Run」をクリックするとデバッグコンソールが開き、「Hello, World!」と表示されます。
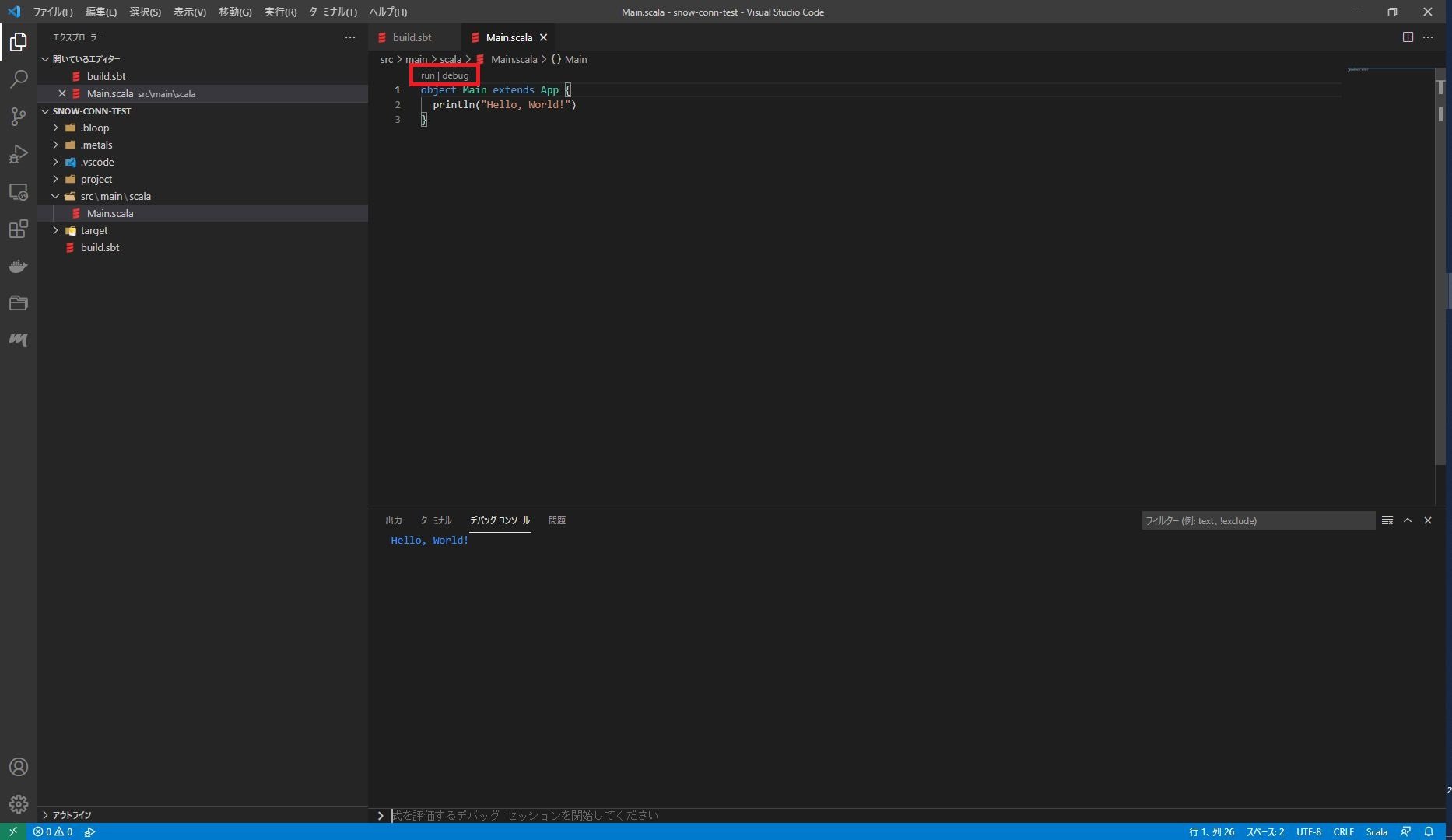
これで、Scalaの開発環境が整いました。
ライブラリ設定 + Scalaバージョン設定
Snowparkを利用する為にライブラリの設定とScalaのバージョンを設定します。
カレントディレクトリ下の「build.sbt」を開き編集します。
まずは、Scalaバージョンを変更します。
Metalsでプロジェクトを立ち上げるとScalaのバージョンが2.13.xxとなっています。
現状、Snowparkは2.13.xxはサポートしておらず、2.12.9以降がサポートされています。(2021/9現在)
なので、「scalaVersion」の変数を"2.12.14"に変更します。
また、OSGeoのリポジトリ追加とSnowparkライブラリの依存関係追加を記述します。
追加で設定ファイルの読み込みができるライブラリも記述します。
具体的には以下のスニペットを「build.sbt」に追記します。
resolvers += "OSGeo Release Repository" at "https://repo.osgeo.org/repository/release/"
libraryDependencies ++= Seq(
"org.scala-lang.modules" %% "scala-parser-combinators" % "1.1.2",
"com.snowflake" % "snowpark" % "0.6.0",
"com.typesafe" % "config" % "1.4.1",
"org.pmml4s" %% "pmml4s" % "0.9.11"
)これでライブラリ設定とScalaのバージョン設定が完了しました。
設定ファイル作成
Snowflakeへのアクセス情報を設定ファイルに記述します。
src/main/resources/application.confというファイルを作成します。
このファイルには、以下のような情報を記述します。
snowflake {
url = "https:///[YOUR_SNOWFLAKE_ACCOUNT].snowflakecomputing.com:443",
user = "[USER]",
password = "[PASSWORD]",
role = "[ROLE]",
warehouse = "[WAREHOUSE]",
db = "[DATABASE]",
schema = "[SCHEMA]"
}これで設定ファイルの作成は完了しました。
セッションを作成⇒クエリ実行
ここからはScalaを記述してSnowflakeでクエリの実行をしてみましょう。
src/main/scala/Main.scalaを開いて以下の様にコードを書き換えます。
import com.snowflake.snowpark._
import com.snowflake.snowpark.functions._
import com.typesafe.config._
object Main {
def main(args: Array[String]): Unit = {
val conf = ConfigFactory.load()
val configs = Map (
"URL" -> conf.getString("snowflake.url"),
"USER" -> conf.getString("snowflake.user"),
"PASSWORD" -> conf.getString("snowflake.password"),
"ROLE" -> conf.getString("snowflake.role"),
"WAREHOUSE" -> conf.getString("snowflake.warehouse"),
"DB" -> conf.getString("snowflake.db"),
"SCHEMA" -> conf.getString("snowflake.schema")
)
val session = Session.builder.configs(configs).create
session.sql("select * from IRIS_TEST").show()
}
}あとは、動作確認時に行った手順通りにScalaを実行すると以下のような出力が出てきます。
[main] INFO (Logging.scala:22) - Closing stderr and redirecting to stdout
[main] INFO (Logging.scala:22) - Done closing stderr and redirecting to stdout
[main] INFO (Logging.scala:22) - Actively querying parameter snowpark_lazy_analysis from server.
[main] INFO (Logging.scala:22) - Execute query [queryID: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX] SELECT * FROM (select * from IRIS_TEST) LIMIT 10
------------------------------------------------------------------------------
|"SEPAL_LENGTH" |"SEPAL_WIDTH" |"PETAL_LENGTH" |"PETAL_WIDTH" |"TARGET" |
------------------------------------------------------------------------------
|4.9 |3.0 |1.4 |0.2 |0 |
|5.4 |3.9 |1.7 |0.4 |0 |
|5.1 |3.8 |1.5 |0.3 |0 |
|5.2 |3.4 |1.4 |0.2 |0 |
|4.7 |3.2 |1.6 |0.2 |0 |
|4.9 |3.6 |1.4 |0.1 |0 |
|5.1 |3.4 |1.5 |0.2 |0 |
|4.4 |3.2 |1.3 |0.2 |0 |
|5.1 |3.8 |1.9 |0.4 |0 |
|4.8 |3.0 |1.4 |0.3 |0 |
------------------------------------------------------------------------------無事に任意のテーブルが参照できました。
最後に
Snowparkの開発環境の設定をVS Codeで行いクエリの実行を行いました。
Metalsのおかげで簡単に環境設定が出来たかと思います。
今後は、SnowparkでのUDFでの機械学習モデルの推論実行を試してみたいと思います。
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。



