はじめに
「Snowpipe Streaming」は、2023年に発表された比較的新しいロード手法です。
Snowpipeと名前が似ていますが、Snowpipeを置換するものではなく、Snowpipeを補完することを目的とした機能です。
本記事は機能の概要をまとめつつ、「Snowpipe Streaming」を動作検証してみました。
詳しくは公式ドキュメントを参照ください。
Snowpipe Streamingの特徴
概要
ざっくりとした理解では、「Snowpipe Streaming」はSnowpipeよりもリアルタイムなデータ連携を実現したい場合に利用され、以下のような特徴があります
- 行単位でロードする
- ロード遅延が少ない
- リアルタイムなデータストリームに適している
- Snowpipe Streaming API を利用することで、データロードする
Snowpipeはクライアント側でファイルを作成して、ファイル単位でデータロードするのに対して、「Snowpipe Streaming」は行単位でロードします。この違いにより、ロード遅延が短縮され、リアルタイムなストリームを実現しています。
Snowpipeとの比較
公式ドキュメント通りですが、Snowpipeと「Snowpipe Streaming」の違いをまとめてみます。
| Snowpipe Streaming | Snowpipe | |
|---|---|---|
| データ形式 | 行 | ファイル |
| データの順序 | チャネル(後述)内で保証 | サポート対象外 |
| ロード履歴 | SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY | LOAD_HISTORYおよび COPY_HISTORY |
| 利用するオブジェクト | チャネル(後述) パイプは利用しない |
パイプ |
通常のSnowpipeは、外部ストレージにファイルを置いた順番にロードされるとは限らないですが、「Snowpipe Streaming」は、チャネル単位で順序が保証されるようです。
ソフトウェア要件
現状は、JavaSDKのみが利用可能で、SDKを利用してクライアントアプリケーションを構築する形になります。また、SDKはこちらのMavenレポジトリからダウンロードできます。
現状JavaSDKのみというのは、(勝手な憶測ですが)、KafkaConnectorで利用されるためだと理解しています。
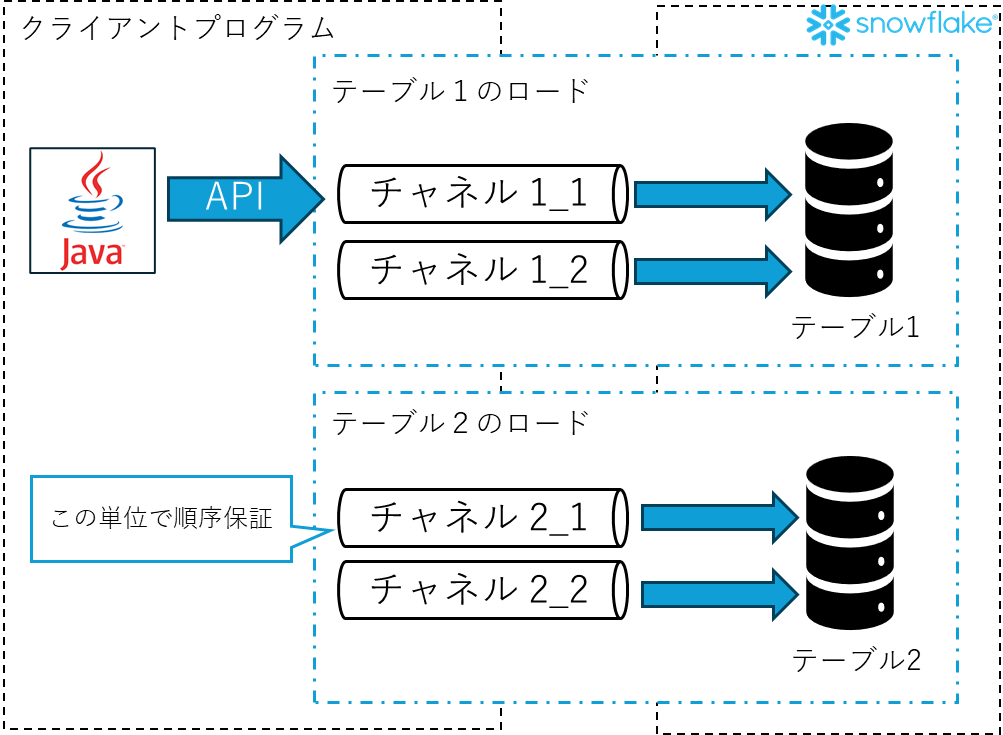
チャネル
「Snowpipe Streaming」で利用される特徴的なオブジェクトとして、「チャネル」があります。チャネルの役割、特徴は以下のように理解しています。
- クライアントと、ロード対象のテーブルの接続を表す
- 1つのチャネルは、1つのテーブルにマッピングされる
- 1テーブルで、複数のチャネルを作成することができる
- 行の順序は、チャネル単位で保証される
上記の内容を概念図的に表すと以下のように理解しています。
また、作成されたチャネルの一覧は、SHOW CHANNELS コマンドで確認できます。
権限
Snowpipe Streaming API を呼び出すには、次の権限を持つロールが必要になります。
| オブジェクト | 権限 |
|---|---|
| テーブル | OWNERSHIP または、INSERTとEVOLVE SCHEMA |
| データベース | USAGE |
| スキーマ | USAGE |
クライアントプログラム実装
動作検証のためにクライアントプログラムを実装してみます。
公式ドキュメントでこちらのサンプルコードが紹介されていますので、こちらをベースに実装します。環境構築手順などは、READMEに記載されてますので、そちらも参照ください。
事前準備
Java環境構築
クライアントプログラムの環境要件の概要は以下になります
- Java8以上
- Mavenプロジェクトをビルド可能な環境
私はEclipseをインストールして、上記環境を作成しました。また、SDKを利用するためにMavenの
pom.xmlに、以下の記述を加えます。<!-- Add this to your Maven project's pom.xml --> <dependency> <groupId>net.snowflake</groupId> <artifactId>snowflake-ingest-sdk</artifactId> <version>2.0.5</version> </dependency>
キーペア認証設定
- 現状認証方法は、キーペア認証のみが利用可能です。こちらを参照してキーペア認証を設定してください。
設定ファイル作成
プログラムで利用する設定ファイルを準備します。接続URLやアカウントなど、認証情報を記載したJSONファイルです。private_keyには、キーペア認証で作成した秘密鍵の情報を設定してください。
{ "url" : "<account_url>", "user" : "<user_name>", "private_key" : "<private_key>", "role" : "<role_name>" }
テーブル作成
チャネルは、クライアントプログラムから作成可能で事前に作成する必要はありません。ただし、チャネルの作成時点でテーブルが存在しないとエラーが発生する模様です。
そのため、先にロードの対象とするテーブルを作成しておきます。create or replace TABLE snowpipe_streaming_verification.snowpipe_test ( id NUMBER(38,0) , channel_name VARCHAR );今回は、単純な2列のテーブルとしています。
作成プログラム全文
作成したプログラムの全文を以下に示します。
SDKの詳細は、こちらのドキュメントを参照ください。
package com.example.snowpipestreaming;
/*
* Copyright (c) 2021 Snowflake Computing Inc. All rights reserved.
*/
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Properties;
import net.snowflake.ingest.streaming.InsertValidationResponse;
import net.snowflake.ingest.streaming.OpenChannelRequest;
import net.snowflake.ingest.streaming.SnowflakeStreamingIngestChannel;
import net.snowflake.ingest.streaming.SnowflakeStreamingIngestClient;
import net.snowflake.ingest.streaming.SnowflakeStreamingIngestClientFactory;
import java.io.File;
public class SnowflakeStreamingIngestExample {
private static String PROFILE_PATH = "profile.json";
private static final ObjectMapper mapper = new ObjectMapper();
public static void main(String[] args) throws Exception {
Properties props = new Properties();
String path = new File(".").getAbsoluteFile().getParent();
System.out.println(path);
// 設定ファイル読込
Iterator<Map.Entry<String, JsonNode>> propIt =
mapper.readTree(new String(Files.readAllBytes(Paths.get(PROFILE_PATH)))).fields();
while (propIt.hasNext()) {
Map.Entry<String, JsonNode> prop = propIt.next();
props.put(prop.getKey(), prop.getValue().asText());
}
try (
// snowflakeへ接続し、APIエンドポイントを利用可能なクライアントを作成
SnowflakeStreamingIngestClient client =
SnowflakeStreamingIngestClientFactory.builder("MY_CLIENT").setProperties(props).build()) etProperties(props).build())
{
// チャンネル作成用のリクエスト作成
OpenChannelRequest request1 =
OpenChannelRequest.builder("CHANNNEL_1")
.setDBName("sample_db_name")
.setSchemaName("snowpipe_streaming_verification")
.setTableName("snowpipe_test")
.setOnErrorOption(
OpenChannelRequest.OnErrorOption.CONTINUE) // Another ON_ERROR option is ABORT
.build();
// チャネルオープン
SnowflakeStreamingIngestChannel channel1 = client.openChannel(request1);
// データ作成とINSERT
final int totalRowsInTable = 1000;
for (int val = 0; val < totalRowsInTable; val++) {
// データ作成
Map<String, Object> row = new HashMap<>();
row.put("id", val);
row.put("channel_name", "CHANNNEL_1");
// データINSERT
InsertValidationResponse response = channel1.insertRow(row, String.valueOf(val));
if (response.hasErrors()) {
// Simply throw if there is an exception, or you can do whatever you want with the
// erroneous row
throw response.getInsertErrors().get(0).getException();
}
}
// オフセットの確認
final int expectedOffsetTokenInSnowflake = totalRowsInTable - 1; // 0 based offset_token
final int maxRetries = 100;
int retryCount = 0;
do {
String offsetTokenFromSnowflake = channel1.getLatestCommittedOffsetToken();
if (offsetTokenFromSnowflake != null
&& offsetTokenFromSnowflake.equals(String.valueOf(expectedOffsetTokenInSnowflake))) {
System.out.println("SUCCESSFULLY inserted " + totalRowsInTable + " rows");
break;
}
retryCount++;
} while (retryCount < maxRetries);
// チャンネルクローズ
channel1.close().get();
}
}
}筆者はJava未経験ですが、オブジェクト指向プログラミング経験はあるので、ゴリゴリにデザインパターンが利用されているのは理解できます。
作成プログラム詳細解説
設定ファイル読込
以下で、事前準備で作成した設定ファイル読込を実施しています。設定ファイルは、Mavenプロジェクトのトップに配置されることを想定されたコードです。
private static String PROFILE_PATH = "profile.json";Properties props = new Properties(); String path = new File(".").getAbsoluteFile().getParent(); System.out.println(path); // 設定ファイル読込 Iterator<Map.Entry<String, JsonNode>> propIt = mapper.readTree(new String(Files.readAllBytes(Paths.get(PROFILE_PATH)))).fields(); while (propIt.hasNext()) { Map.Entry<String, JsonNode> prop = propIt.next(); props.put(prop.getKey(), prop.getValue().asText()); }
snowflake接続・APIエンドポイントのクライアント作成
作成した設定ファイルの内容を利用して、snowflakeへ接続し、Snowpipe用のAPIエンドポイントを利用可能な状態とします。
// snowflakeへ接続し、APIエンドポイントを利用可能なクライアントを作成 SnowflakeStreamingIngestClient client = SnowflakeStreamingIngestClientFactory.builder("MY_CLIENT").setProperties(props).build())builderメソッドに指定しているMY_CLIENTという文字列は任意で問題ありません。
また、設定ファイルの認証情報に何かしら誤りがあると、この時点でエラーが発生します。
チャネルオープン
リクエストオブジェクトを作成してから、チャネルオープンします。リクエストには対象のテーブル名や、作成するチャネル名を設定します。
builderメソッドに指定しているCHANNNEL_1という文字列がチャネル名になります。任意で問題ありません。
// チャンネル作成用のリクエスト作成 OpenChannelRequest request1 = OpenChannelRequest.builder("CHANNNEL_1") .setDBName("sample_db_name") .setSchemaName("snowpipe_streaming_verification") .setTableName("snowpipe_test") .setOnErrorOption( OpenChannelRequest.OnErrorOption.CONTINUE) // Another ON_ERROR option is ABORT .build(); // チャネルオープン SnowflakeStreamingIngestChannel channel1 = client.openChannel(request1);
データ送信
データを作成してから、送信するというのをfor文で1000回繰り返します。
データの内容はMapに、カラム名をキーとして、1列単位で設定していきます。// データ作成とINSERT final int totalRowsInTable = 1000; for (int val = 0; val < totalRowsInTable; val++) { // データ作成 Map<String, Object> row = new HashMap<>(); row.put("id", val); row.put("channel_name", "CHANNNEL_1"); // データINSERT InsertValidationResponse response = channel1.insertRow(row, String.valueOf(val)); if (response.hasErrors()) { // Simply throw if there is an exception, or you can do whatever you want with the // erroneous row throw response.getInsertErrors().get(0).getException(); } }
オフセットの確認・クローズ
チャネルは内部的に何行分のデータを送信しているかをオフセットで保持しています。
今回は、1000行のデータを送信したので、終了時点でオフセットが999まで進んでいることを確認してから終了にしています。// オフセットの確認 final int expectedOffsetTokenInSnowflake = totalRowsInTable - 1; // 0 based offset_token final int maxRetries = 100; int retryCount = 0; do { String offsetTokenFromSnowflake = channel1.getLatestCommittedOffsetToken(); if (offsetTokenFromSnowflake != null && offsetTokenFromSnowflake.equals(String.valueOf(expectedOffsetTokenInSnowflake))) { System.out.println("SUCCESSFULLY inserted " + totalRowsInTable + " rows"); break; } retryCount++; } while (retryCount < maxRetries); // チャンネルクローズ channel1.close().get();クライアントプログラム側で、オフセットの確認ができることで、送信タイミングの調整なども可能です。
動作確認
Elipseのデバッグ機能を用いて、コードを途中まで実行しながら、snowflake上での動作を確認していきます。
プログラム実行前は、テーブルは空で、チャネルも存在しない状態です。
設定ファイル読込~チャネルオープンまで
チャネルオープン(以下の部分)まで実行してみます。
// チャネルオープン
SnowflakeStreamingIngestChannel channel1 = client.openChannel(request1);この時点で、snowflake上で、show channelsコマンドを実行してみると、チャネルが生成されているのが確認できます!
show channels;
show channelsコマンドでは、以下のような内容が確認可能です
- name
- チャネル名称
- table_name
- チャネルでロード対象としているテーブル名
- offset_token
- チャネルで管理しているオフセット
- 作成時点ではNULLとなっている
データ送信
データ送信を実行します。実行後のテーブルでは、1000行のデータがロードされています。
select * from snowpipe_streaming_verification.snowpipe_test order by 1;
また、実行後に再度show channelsコマンドを実行すると、オフセットが999まで進んでいることが確認可能です。

オフセットの確認・クローズ
クライアントプログラムからもオフセットを確認して、オフセットが想定通り進んでいるか確認します。

SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORYの確認
Snowpipe Streamingを利用した結果は、account_usageスキーマのSNOWPIPE_STREAMING_FILE_MIGRATION_HISTORYビューで確認可能です。
select * from snowflake.account_usage.SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY
order by 1
limit 20;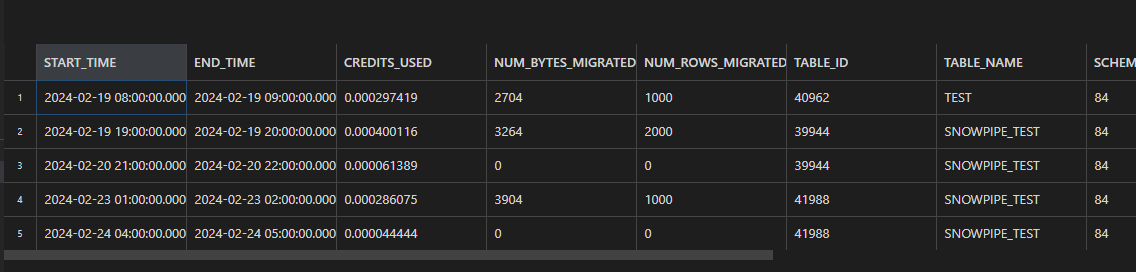
この検証で利用したぐらいのデータ量であれば、クレジットも微量です。データの内容としては、以下の理解をしています。
- 時間を1時間単位で区切っている(END_TIMEとSTART_TIMEの差分が1時間)
- 該当の1時間毎に、テーブル単位で、クレジットの消費内容が表示される
- データのロードが無くても、クレジットを利用した場合、表示される
- チャネル単位でなく、複数チャネルが同じテーブルにINSERTした場合も、マージして表示される
Kafka Connectorとの連携について
KafkaからのデータロードはデフォルトではSnowpipeが利用されますが、Kafkaの構成プロパティを変更することで、Snowpipe Streamingを利用するように変更可能です。
現状、Snowpipe Streamingが利用されるユースケースとしては、本ケースが1番多いのではないかと思ってます。
本記事では、動作確認はしませんが、公式ドキュメントはこちらを参照ください。
まとめ
公式ドキュメントに紹介されたクライアントプログラムをベースに、Snowpipe Streamingの動作検証をしてみました。今後、Kafka Connectorを利用したものも動作検証してみたいです。
Snowflakeを体験してみませんか?
INSIGHT LABではSnowflake紹介セミナーを定期開催しています。Snowflakeの製品紹介だけでなく、デモンストレーションを通してSnowflakeのシンプルなUI操作や処理パフォーマンスの高さを体感いただけます。