はじめに
以前こちらの記事で、Google Teachable Machine という AutoMLツールを使って、顔写真の表情分類モデルを作成しました。本記事は、(自分の勉強用に)この分類モデルをコーディングで作ってみようという主旨です。また、こちらの記事で、TensorFlow Playground を使用したので、ライブラリも TensorFlow を使おうと思います。
学習に使用する画像は 48x48 の JPEG形式で、Happy, Angry, Sad, Surprise のフォルダに分かれており、それぞれのフォルダには以下の枚数の画像が含まれています。
- Sad: 4830枚
- Surprise: 3171枚
これらの画像を使用して、感情分類モデルを TensorFlow を使用して作成します。
モデル作成
1. ライブラリのインストールとインポート
まず、必要なライブラリをインストールし、インポートします。
pip install tensorflow matplotlib
次に、Pythonスクリプトで必要なライブラリをインポートします。
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
2. データの準備
データジェネレータを使用して、トレーニングデータとテストデータを準備します。
# データジェネレータの設定
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
validation_split=0.2 # トレーニングデータの20%を検証データとして使用
)
ImageDataGenerator: 画像データの前処理やデータオーグメンテーションを行うためのクラスです。
train_datagen: トレーニングデータの前処理とデータオーグメンテーションを設定します。
rescale=1./255: 画像のピクセル値を0-255から0-1に正規化します。
shear_range=0.2: 画像をランダムに傾けます。
zoom_range=0.2: 画像をランダムにズームします。
horizontal_flip=True: 画像をランダムに水平反転します。
validation_split=0.2: トレーニングデータの20%を検証データとして使用します。
test_datagen: テストデータの前処理を設定します。
rescale=1./255: 画像のピクセル値を0-255から0-1に正規化します。
# トレーニングデータのジェネレータ
train_generator = train_datagen.flow_from_directory(
'emotional/train',
target_size=(48, 48), # 画像のサイズを48x48に設定
color_mode='grayscale', # グレースケール画像として読み込む
batch_size=16, # バッチサイズを16に設定
class_mode='categorical',
subset='training' # トレーニングデータ
)
# 検証データのジェネレータ
validation_generator = train_datagen.flow_from_directory(
'emotional/train',
target_size=(48, 48), # 画像のサイズを48x48に設定
color_mode='grayscale', # グレースケール画像として読み込む
batch_size=16, # バッチサイズを16に設定
class_mode='categorical',
subset='validation' # 検証データ
)
flow_from_directory: ディレクトリから画像を読み込み、前処理を行い、バッチ単位でデータを生成します。
'emotional/train': トレーニングデータが格納されているディレクトリのパス。
target_size=(48, 48): すべての画像を48x48ピクセルにリサイズします。
batch_size=16: 1バッチあたりの画像の数を16に設定します。(Google Teachable Machineの設定に合わせました)
class_mode='categorical': 出力ラベルが複数クラスに分かれていることを示します。
subset='training': トレーニング用のデータを生成します。
3. モデルの構築
TensorFlowを使用してシーケンシャルモデルを構築します。
# モデルの構築
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(48, 48, 1)),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(4, activation='softmax') # 出力層(4つのクラス)
])
Sequential:ニューラルネットワークモデルの各レイヤーを順次積み重ねるためのクラスです。このモデルでは、各レイヤーが順番に追加されていきます。
Conv2D: 2次元の畳み込み層。フィルタの数、カーネルサイズ、活性化関数、入力形状を指定。
32: フィルターの数。この場合、32個のフィルターを使用します。
(3, 3): フィルターのサイズ。この場合、3x3のフィルターを使用します。
activation='relu': 活性化関数としてReLUを使用します。ReLUは、負の値を0にし、正の値をそのまま通します。
input_shape=(48, 48 1): 入力データの形状を指定します48x48ピクセルのグレースケール画像(1チャンネル、カラー画像なら3)を入力とします。この指定は最初の層にのみ必要です。
MaxPooling2D: プーリング層。プーリングサイズを指定。
pool_size=(2, 2): プーリングサイズ。この場合、2x2の領域ごとに最大値を取得します。
Flatten: 2次元の特徴マップを1次元のベクトルに変換します。この変換により、全結合層(Dense Layer)にデータを渡すことができます。
Dense: 全結合層。ユニット数と活性化関数を指定。
512: ユニットの数。この場合、512個のユニットを持つ全結合層を追加します。
activation='relu': 活性化関数としてReLUを使用します。
Dropout: ドロップアウト層。過学習を防ぐために一部のユニットをランダムに無効化。
0.5: ドロップアウト率。この場合、ランダムに50%のユニットを無効化します。
softmax: 出力層の活性化関数。分類問題で使用され、クラスごとの確率を出力。
4. モデルのコンパイル
モデルをコンパイルします。
# モデルのコンパイル
model.compile(
optimizer=Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy']
)
optimizer=Adam(learning_rate=0.001): オプティマイザーは、モデルの重みをどのように更新するかを決定するアルゴリズムです。ここではAdamを使用します。Adamは、学習率の調整を自動で行い、収束が速いとされる最適化アルゴリズムです。学習率を0.001にしているのは、 Google Teachable Machine のデフォルトに合わせました。
loss='categorical_crossentropy': 損失関数として、多クラス分類に適したカテゴリカルクロスエントロピーを使用します。
metrics=['accuracy']: モデルの評価指標として精度を使用します。精度は、正しく分類されたサンプルの割合を示します。
5. モデルのトレーニング
トレーニングデータを使用してモデルをトレーニングします。
# モデルのトレーニング
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // train_generator.batch_size,
validation_data=validation_generator,
validation_steps=validation_generator.samples // validation_generator.batch_size,
epochs=50
)
model.fit: モデルのトレーニングを行うメソッドです。このメソッドを呼び出すことで、モデルは指定されたデータで学習を開始します。
train_generator:トレーニングデータのジェネレータです。このジェネレータは、ディスクからバッチ単位で画像を読み込み、前処理を行い、モデルに供給します。
steps_per_epoch: 1エポックあたりのトレーニングステップ数です。train_generatorのサンプル数をバッチサイズで割った値です(train_generator.samples // train_generator.batch_size)。これは、1エポックでトレーニングデータ全体を一度処理するために必要なステップ数を示します。
validation_data: 検証データのジェネレータです。トレーニング中にモデルの性能を評価するために使用されます。トレーニングデータと同じディレクトリから、検証用に指定された画像データを読み込みます。
validation_steps: 1エポックあたりの検証ステップ数です。validation_generator のサンプル数をバッチサイズで割った値です(validation_generator.samples // validation_generator.batch_size)。steps_per_epoch と同様。
epochs:トレーニングを行うエポック数です。1エポックは、モデルがトレーニングデータセット全体を一度学習することを意味します。ここでは、50エポックを指定しており、これも Google Teachable Machine のデフォルトに合わせています。
history:
model.fit メソッドは、トレーニングの過程(各エポックごとの損失と精度の履歴)を含む History オブジェクトを返します。
history オブジェクトを使用することで、トレーニング中のモデルのパフォーマンスを可視化することができます。
6. トレーニング過程の確認
トレーニング過程をプロットし、トレーニング中のモデルパフォーマンスを確認します。
# トレーニング過程のプロット
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
plt.show()
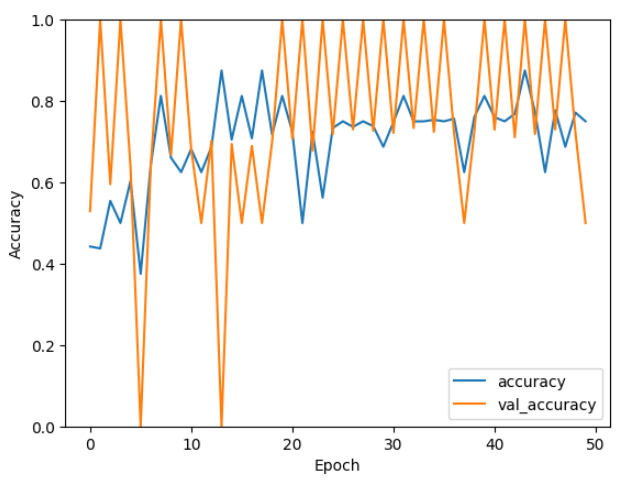
Matplotlib に関しては割愛します。結果は以下の通り。
横軸はエポック数(Epoch)、縦軸は精度(Accuracy)を表しています。青い線はトレーニングデータに対する精度、オレンジの線は検証データに対する精度を示しています。
- トレーニング精度(青い線): トレーニング精度はエポックが進むにつれて安定して上昇していますが、途中で変動が見られます。全体的には、エポック数が増えるにつれて精度が向上し、60%から80%の間で推移しています。
- 検証精度(オレンジの線): 検証精度は非常に不安定で、エポックごとに大きな変動があります。高いときには100%、低いときには0%に達しており、一貫性がありません。
本来であればデータの前処理、学習率の調整など再度行ったりしますが、今回はこのモデルの評価を行ってみます。
7. モデルの評価
テストデータを使って、モデルの評価を行います。テストデータも学習データと同様にフォルダ分けされており、それぞれ以下の枚数となっています。
# データジェネレータの設定
test_datagen = ImageDataGenerator(rescale=1./255)
# テストデータのジェネレータ
test_generator = test_datagen.flow_from_directory(
'emotional/test', # テストデータが含まれるディレクトリのパス
target_size=(48, 48), # 画像のサイズを48x48に設定
color_mode='grayscale', # グレースケール画像として読み込む
batch_size=16, # バッチサイズを16に設定
class_mode='categorical'
)
# テストデータの評価
test_loss, test_acc = model.evaluate(
test_generator,
steps=test_generator.samples // test_generator.batch_size
)
print(f'Test accuracy: {test_acc}')
(テストデータのジェネレータについては学習データ・検証データと同様です。)
model.evaluate: モデルを評価するためのメソッド。このメソッドを使用して、モデルの損失と精度を計算します。
test_generator: train_generator, validation_generator と同様です。
steps: 1エポックあたりのテストステップ数です。test_generator のサンプル数をバッチサイズで割った値です(test_generator.samples // test_generator.batch_size)。これは、テストデータ全体を一度処理するために必要なステップ数を示します。
test_loss: テストデータに対する損失値です。損失値は、モデルの予測と実際の値との誤差を示します。この値が小さいほど、モデルの予測精度が高いことを示します。
test_acc: テストデータに対する精度です。精度は、正しく分類されたサンプルの割合を示します。この値が大きいほど、モデルの予測精度が高いことを示します。
結果ですが、以下が出力されました。
Test accuracy: 0.752916693687439
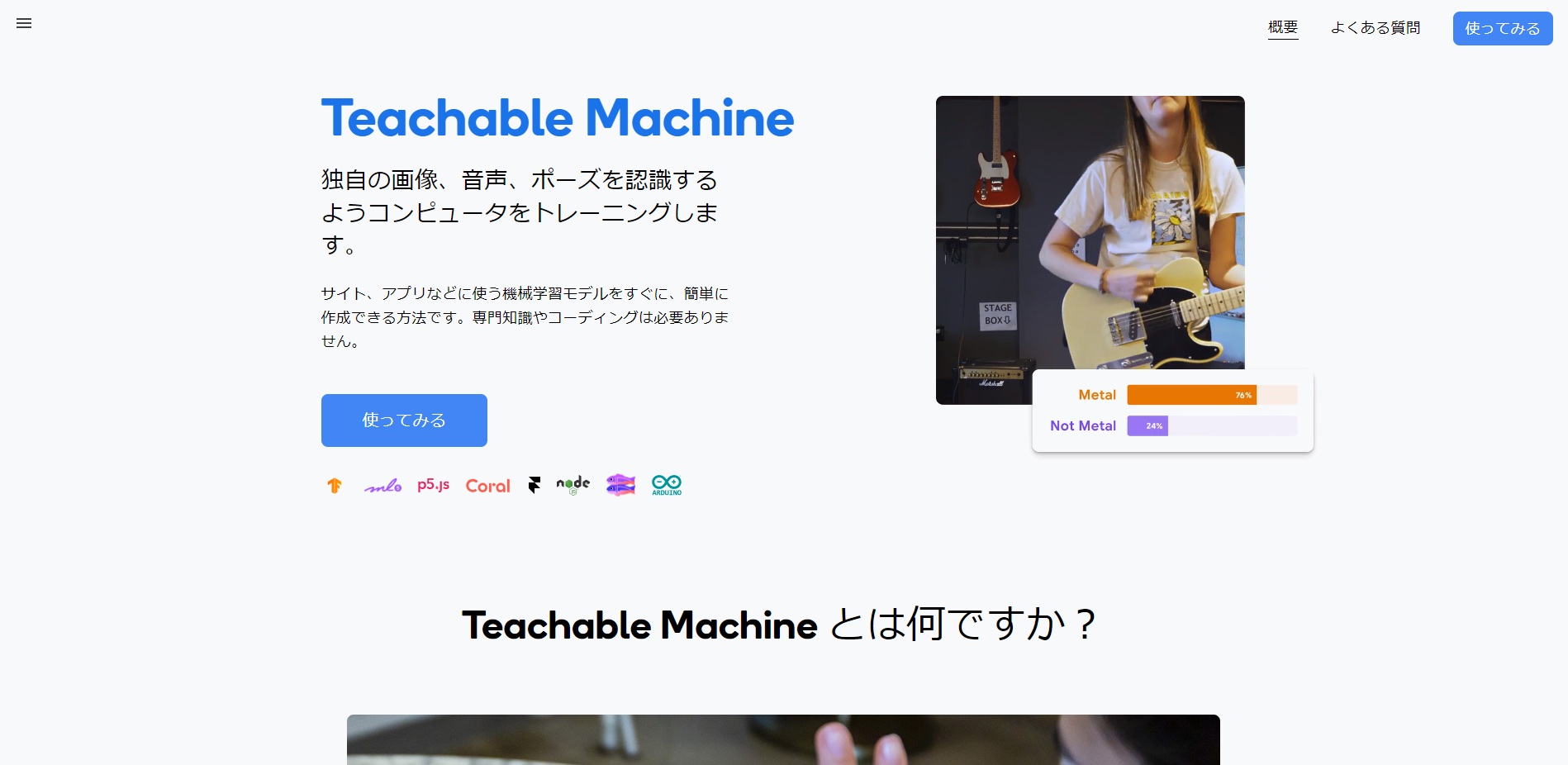
ちなみに Google Teachable Machine の結果は以下でした。
これと比較した限りでは悪くない結果ではないでしょうか。
まとめ
以上の手順で、画像分類モデルを作成しました。やはり AutoMLツールと比較して手間がかかりますが、技術の理解は深まると思います。簡単にモデルを作りたい場合だと Google Teachable Machine で作ってみるというのも選択肢の一つとしてアリかと思います。
Google Teachable Machine についてはこちらから無料で使うことができますので、興味があれば使ってみてください。
https://teachablemachine.withgoogle.com/








{kind=link}
{kind=link}