


まとめ
・Azureのリソースグループ名に英数以外の文字を使用すると、Data Factoryなどで「Request headers must contain only ASCII characters.」エラーが発生する
・リソースグループのリネームはできないため、最初から英数のみを使用した方が良い
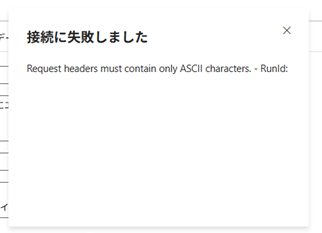
・Azureのリソースグループ名に英数以外の文字を使用すると、Data Factoryなどで「Request headers must contain only ASCII characters.」エラーが発生する
・リソースグループのリネームはできないため、最初から英数のみを使用した方が良い

現代のビジネス環境において、ソフトウェアは企業の成長を支える中核になっています。しかし、開発現場では以下のような課題がしばしば発生します。

Webアプリケーション開発では、コードの見通しを良くし、保守性を高めるために「設計パターン」がよく使われます。その中でも代表的なのがMVCモデルです。MVCはアプリケーションの役割を3つに分けることで、開発を効率化し、複数人での開発や長期運用にも強い構造を作ることができます。この記事では、MVCモデルの基本から具体的なコード例、メリット・デメリット、さらには採用されている代表的なフレームワークまでわかりやすくご紹介します。

このナレッジでは、Cloud Run Jobs を活用して、BigQuery 上に蓄積された売上ジャーナルデータに対する店舗情報の不整合を自動的に検出し、Cloud Logging を用いて記録・可視化する仕組みについて解説します。
具体的には、「東京都の売上データに神奈川県に属する店舗の情報が含まれている」といった、地域コードや店舗コードの不一致による整合性エラーをどのように検知するかについて、本記事でご説明します。
.png)
AWS Step Functionsの直列処理を定期運用で使用している際、途中で落ちても最後まで処理を実行したいという要件がありました。
ただし、処理が一つでも落ちたら最終的にはエラー終了にて終わらせるように設計する必要があります。
上記内容を実現するための方法をまとめましたので参考にしてください。
.png)
Databricksとは、データの収集・加工から可視化や機械学習モデルの開発、それらの運用などのタスクを一気通貫で行うことのできるクラウド型プラットフォームです。
・Dataflowとは、統合されたストリーム データ処理とバッチデータ処理を大規模に提供する Google Cloud サービスです。Dataflow を使用して、1 つ以上のソースからデータを読み取り、変換し、宛先に書き込むデータ パイプラインを作成します。

Webサイトからデータ取得をおこない、データ分析を実施したい。
Pythonでは、データフレームの操作にPandasがよく使われていますが、設計に上限のあるメモリ使用量や処理速度が問題になる場合があります。Polarsはこれらの問題を解決するための高速でモダンなデータフレームライブラリです。
今回はそのPolarsについて学習しましたので、Pandasでできるデータフレーム処理を、PolarsとPandasのスクリプトを比較しながら紹介します。
まずはCSVの読み込みをしてみます。読み込むデータはKaggkeからこちらのオープンデータを使用します。サイズも約1.6GBと大きめとなっています。
また比較のため、実行時間を計ってみます。(あくまで参考)
Pandas例
start_time = time.time()
df_pd = pd.read_csv('archive/dataset/train.csv')
print(df_pd.head())
print(f'Pandas CSV読込時間: {time.time()-start_time:.5f}秒')
結果は以下になります。
実行時間は約 47 秒となりました。
続いてPolarsでCSVを読み込んでみます。
Polars例
start_time = time.time()
df_pl = pl.read_csv('archive/dataset/train.csv')
print(df_pl.head())
print(f'Polars CSV読込時間: {time.time()-start_time:.5f}秒')
スクリプトはPandasと変わらず read_csv() でCSVファイルを読み込めます。
表示の仕方もPandasとは異なっており、枠線が追加されてます。
時間は約 11 秒と、Pandasより短い時間で読込が完了しました。
PolarsはPandasと同様に、先頭行を表示する head と 末端行を表示する tail は使えるようです。
次に行選択を比較します。
Pandasでは loc で列名を指定するか、iloc でインデックスを指定することでデータを抽出できます。
Polarsでは、先ほどの出力結果を見た通り、インデックス列がないため、loc や iloc は使えませんが、Python標準のスライスは使うことができます。
Pandas例
start_time = time.time()
# 行選択
sliced_df_pd = df_pd.iloc[1001:2000]
print(sliced_df_pd.head())
print(f"Pandas 行選択時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 行選択
sliced_df_pl = df_pl[1001:2000]
print(sliced_df_pl.head())
print(f"Polars 行選択時間: {time.time() - start_time:.5f}秒")
結果
Pandas フィルタリング時間: 0.24555秒
Pandas フィルタリング時間: 0.04687秒
それぞれ大差なく、行抽出を行うことができました。
次にデータのフィルタリングを比較します。
Pandasでは df[df["column"]==""] のように条件を記述しますが、Polarsでは filter() と pl.col を組み合わせて条件を記述します。
Pandas例
start_time = time.time()
# 条件フィルタリング
filtered_df_pd = df_pd[(df_pd["PRODUCT_ID"] > 200000) & (df_pd["PRODUCT_TYPE_ID"] > 5000)]
print(filtered_df_pd.head())
print(f"Pandas フィルタリング時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 条件フィルタリング
filtered_df_pl = df_pl.filter((pl.col("PRODUCT_ID") > 200000) & (pl.col("PRODUCT_TYPE_ID") > 5000))
print(filtered_df_pl.head())
print(f"Polars フィルタリング時間: {time.time() - start_time:.5f}秒")
結果
Pandas フィルタリング時間: 11.27074秒
Polars フィルタリング時間: 0.27175秒
フィルタリングに関してはPandasの方がやや早い結果となりました。
次にデータの並べ替えを比較します。
Pandasでは sort_values を使用し、Polarsでは sort を使った同様の記述で並べ替えが可能です。
Pandas例
start_time = time.time()
# 並べ替え
sorted_df_pd = df_pd.sort_values(by="PRODUCT_ID", ascending=False)
print(sorted_df_pd.head())
print(f"Pandas 並べ替え時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 並べ替え
sorted_df_pl = df_pl.sort("PRODUCT_ID", descending=True)
print(sorted_df_pl.head())
print(f"Polars 並べ替え時間: {time.time() - start_time:.5f}秒")
結果
Pandas 並べ替え時間: 5.08156秒
Polars 並べ替え時間: 23.94773秒
並べ替えはデータ量によってかなり時間が増減すると思いますが、全量のソートとなると、PandasとPolarsでは処理時間に大きな差が生じるようです。
次にグループ化・集計を比較します。
Pandasでは、groupby でグループ化、agg で集計方法を記述します。
Polarsでは、Pandas同様に group_by (アンダースコア有・・・)と agg でグループ化と集計を行い、集計するカラムを col 、集計方法を sum() や mean() で指定して記述します。alias で新しいカラム名を指定します。
Pandas例
start_time = time.time()
# グループ化と集計
agg_df_pd = df_pd.groupby("PRODUCT_TYPE_ID").agg({
"PRODUCT_LENGTH": ["mean", "max"]
})
print(agg_df_pd.head())
print(f"Pandas グループ化と集計時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# グループ化と集計
agg_df_pl = df_pl.group_by("PRODUCT_TYPE_ID").agg([
pl.col("PRODUCT_LENGTH").mean().alias("AVG_PRODUCT_LENGTH"),
pl.col("PRODUCT_LENGTH").max().alias("MAX_PRODUCT_LENGTH")
])
print(agg_df_pl.head())
print(f"Polars グループ化と集計時間: {time.time() - start_time:.5f}秒")
結果
Pandasの方が早いようです。
次に列の追加を比較します。
Pandasでは直接列名を指定して計算結果を格納し、Polarsでは with_columns を使い、新しい列を追加します。
Polarsでは列名の変更に alias や、元の列名の前後に文字を追加する prefix や suffix を使用します。
Pandas例
start_time = time.time()
# 新しい列の追加
df_pd["UPDATED_PRODUCT_LENGTH"] = df_pd["PRODUCT_LENGTH"] * 1.1
print(df_pd)
print(f"Pandas 列追加時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 新しい列の追加
df_pl = df_pl.with_columns((pl.col("PRODUCT_LENGTH") * 1.1).alias("UPDATED_PRODUCT_LENGTH"))
# df_pl = df_pl.with_columns((pl.col("PRODUCT_LENGTH") * 1.1).name.prefix("UPDATED_"))
# df_pl = df_pl.with_columns((pl.col("PRODUCT_LENGTH") * 1.1).name.prefix("_UPDATED"))
print(updated_df_pl.head())
print(f"Polars 列追加時間: {time.time() - start_time:.5f}秒")
結果
Pandas 列追加時間: 0.46741秒
Polars 列追加時間: 0.21647秒
ほぼ同じ早さのようです。
次に列の削除を比較します。
PandasもPolarsも drop を使用します。
Pandasでは引数に columns= でカラム名を指定しますが、Polarsではそのままカラム名を記述すればよいです。
Pandas例
start_time = time.time()
# 列の削除
df_pd = df_pd.drop(columns=["UPDATED_PRODUCT_LENGTH"])
print(df_pd.head())
print(f"Pandas 列削除時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# 列の削除
df_pl = df_pl.drop("UPDATED_PRODUCT_LENGTH")
print(df_pl.head())
print(f"Pandas 列削除時間: {time.time() - start_time:.5f}秒")
結果
Pandas 列削除時間: 20.98425秒
Polars 列削除時間: 0.02419秒
次にデータの結合を比較します。
Pandasでは merge を使い、2種のデータフレーム、結合キー、結合方法を指定して結合します。
Polarsでは、一方のデータフレームに join を使って、結合する他方のデータフレームと結合キー、結合方法を指定して結合します。
⇒Pandasの merge のもう一つの書き方、df1.merge(df2) に似ています。
結合方法は、Pandasと同じく、inner, left, right, outer (Polarsでは full), cross の他に、キーがマッチしない行を残す anti というものがあります。
Pandas例
# df_pd_2 = df_pd.head(300)
start_time = time.time()
# データフレームの結合
joined_df_pd = pd.merge(df_pd, df_pd_2, on="PRODUCT_ID", how="inner")
print(joined_df_pd.head())
print(f"Pandas 結合時間: {time.time() - start_time:.5f}秒")
Polars例
# df_pl_2 = df_pl.head(300)
start_time = time.time()
# データフレームの結合
joined_df_pl = df_pl.join(df_pl_2, on="PRODUCT_ID", how="inner")
print(joined_df_pl.head())
print(f"Polars 結合時間: {time.time() - start_time:.5f}秒")
結果
Pandas 結合時間: 0.74357秒
Polars 結合時間: 10.05689秒
Pandasの方が早いみたいですね。
先ほどは列方向の結合だったので、次に行方向の結合を比較します。
Pandas、Polarsともに concat を使用しますが、Pandasでは引数で行列の方向を設定しますが、Polarsでは自動的に行方向の結合になります。
Pandas例
# df_pd_2 = df_pd.head(300)
start_time = time.time()
# データフレームの結合
concat_df_pd = pd.concat([df_pd, df_pd_2], axis=0)
print(concat_df_pd.head())
print(f"Pandas 結合時間: {time.time() - start_time:.5f}秒")
Polars例
# df_pl_2 = df_pl.head(300)
start_time = time.time()
# データフレームの結合
concat_df_pl = pl.concat([df_pl, df_pl_2])
print(concat_df_pl.head())
print(f"Polars 結合時間: {time.time() - start_time:.5f}秒")
結果
Pandas 結合時間: 31.96616秒
Polars 結合時間: 0.24839秒
行方向の結合においては、先ほどと違いPolarsの方が早いようです。
次にファイル出力を比較します。
Pandasでは to_csv を使用し、Polarsでは write_csv を使用しますが、PolarsのCSV出力はUTF-8固定です。。。
Pandas例
start_time = time.time()
# CSVファイルの出力
df_pd.to_csv("archive/dataset/train_pd.csv")
print(f"Pandas 結合時間: {time.time() - start_time:.5f}秒")
Polars例
start_time = time.time()
# CSVファイルの出力
df_pl.write_csv("archive/dataset/train_pl.csv")
print(f"Pandas 結合時間: {time.time() - start_time:.5f}秒")
結果
Pandas 結合時間: 82.69538秒
Polars 結合時間: 13.22587秒
Polarsでは読み込みと同様にPandasより早く出力できるようです。
Polarsでは、ファイル読み込みに read_csv ではなく scan_csv を使うことで LazyFrame と呼ばれる遅延実行を行えます。これにより並列処理とクエリの最適化を行うことで、最も高いパフォーマンスでデータ操作を行うことができます。Polarsにとっても推奨されているようです。
以下に、上記で実行したデータ処理をいくつか実行して、処理時間を確認したいと思います。
最後の collect を読むことで計算され、LazyFrame からデータフレームとして出力されます。
スクリプト
# 遅延実行を開始
start_time = time.time()
# LazyFrameでCSVファイルを読み込む
lazy_df = pl.scan_csv('archive/dataset/train.csv')
# 遅延実行のパイプラインを定義
result = (
lazy_df.filter(pl.col("PRODUCT_ID") > 200000) # フィルタリング
.group_by("PRODUCT_TYPE_ID") # グループ化
.agg([
pl.col("PRODUCT_LENGTH").mean().alias("AVG_PRODUCT_LENGTH"),
pl.col("PRODUCT_LENGTH").max().alias("MAX_PRODUCT_LENGTH")
]) # 集計
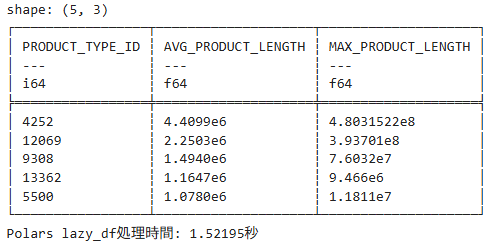
.sort("AVG_PRODUCT_LENGTH", descending=True) # 並べ替え
.collect() # 実行
)
# 処理結果を表示
print(result.head())
print(f"Polars lazy_df処理時間: {time.time() - start_time:.5f}秒")結果
処理時間は約 1.5 秒で、データフレームとして読み込んで処理するより圧倒的に早く処理できているようです。
今回はPolarsとPandasを比較してみました。
Polarsは早い印象ですが、処理によってはPandasの方が早かったりと得手不得手があるのかもしれません。ローカルでの実行なので、バックグラウンドソフトの影響もあるかと思います。
ただ最後の LazyFrame の処理時間はかなり早いようで、ファイルサイズが大きすぎて読み込めないといったときでも、すべて読み込む前に計算してメモリの節約になりそうです。
TensorBoardというTensorFlowの可視化ツールの存在を知ったので、以前TensorFlowで作成した画像分類モデルの学習過程の可視化を行ってみたいと思います。
TensorBoardは、TensorFlow用のツールで、機械学習モデルのトレーニングと評価の可視化を行うためのダッシュボードです。具体的には以下の機能があります。
これらの機能を活用することで、モデルのトレーニングプロセスをより深く理解し、調整やデバッグを効率的に行うことができます。使い方は、TensorFlowのトレーニングスクリプトにいくつかのログ記録のコードを追加するだけで簡単に始められます。
TensorBoardのセットアップ
TensorBoardを使用するためには、まずTensorFlowがインストールされている必要があります。まだインストールしていない場合は、以下のコマンドでインストールします。
pip install tensorflowログディレクトリの指定
モデルのトレーニング中にログを記録するディレクトリを指定します。
import tensorflow as tf
# ログディレクトリの設定
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)モデルトレーニング中のコールバックにTensorBoardを追加
モデルのトレーニングにおいて、fitメソッドにTensorBoardコールバックを追加します。
model.fit(
x_train, y_train,
epochs=10,
validation_data=(x_val, y_val),
callbacks=[tensorboard_callback]
)TensorBoardの起動
ログを記録した後、以下のコマンドでTensorBoardを起動し、ブラウザでダッシュボードを表示します。
tensorboard --logdir=logs/fitその後、ブラウザで表示されるURL(通常は http://localhost:6006/)にアクセスすると、トレーニングプロセスや結果の可視化ができます。
これで、モデルのトレーニング中の各種指標(損失、精度、重みのヒストグラムなど)をリアルタイムで確認できるようになります。
今回は、こちらの記事で実装したスクリプトに上記処理を追加して、可視化してみました。
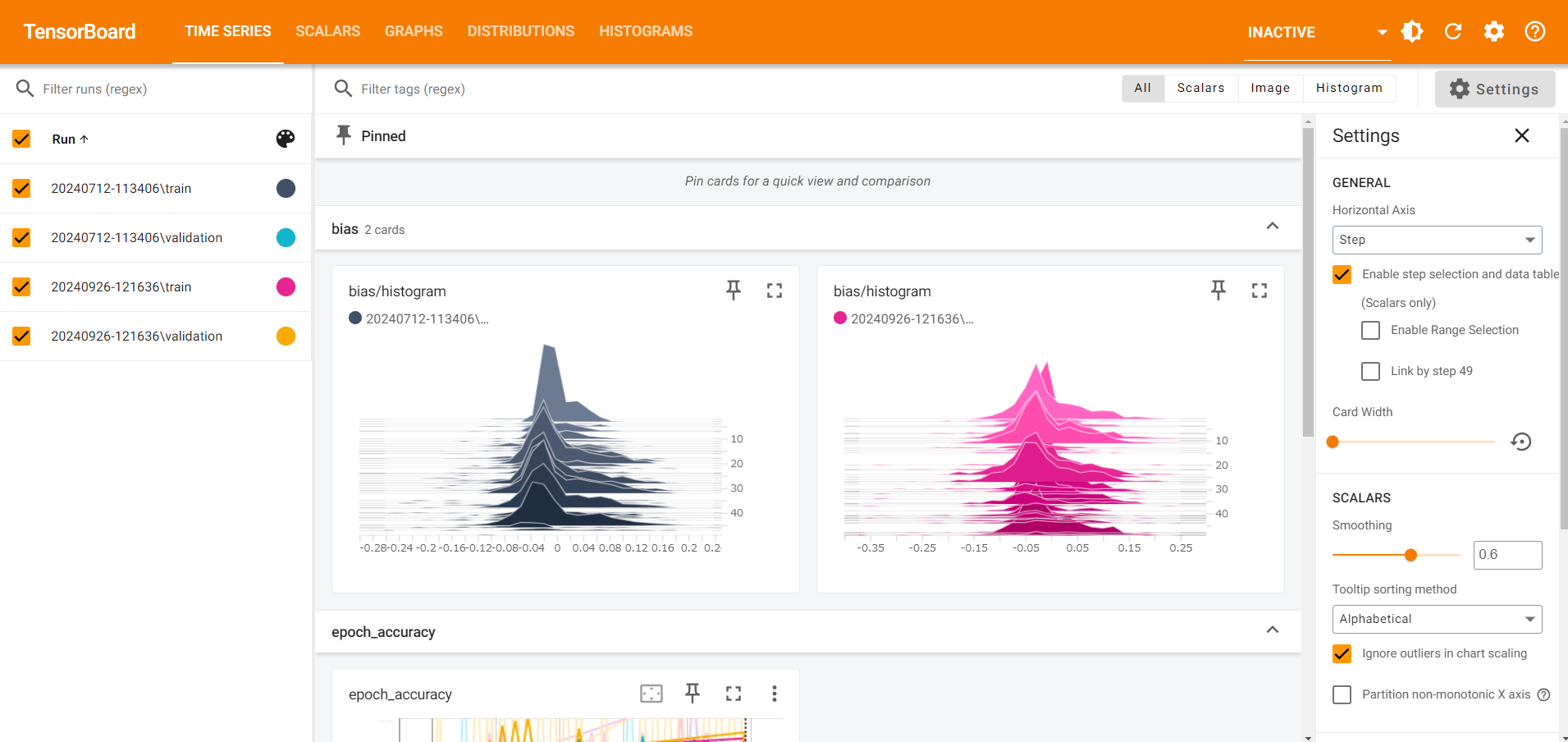
こちらがTensorBoardのダッシュボードになります。それぞれ見ていきます。
bias: エポックごとのバイアスパラメータのヒストグラムになります。各エポックごとにバイアスの値の分布がどのように変化しているかが確認できます。
epoch_accuracy: エポックごとのトレーニングと検証データの精度になります。 エポックが進むにつれて、精度が上がっていくことが望ましいです。もし精度が大きくぶれていたり、検証精度が上がらない場合、過学習(overfitting)やデータに問題がある可能性があります。
epoch_learning_rate: エポックごとの学習率になります。スクリプト内で0.001に設定しているため、エポックが進んでも一定です。
epoch_loss: エポックごとのトレーニングと検証データの損失になります。エポックが進むにつれて、損失は小さくなることが期待されます望ましいですが、検証損失がエポック後半で上昇する場合は過学習の可能性があります。
evaluation_accuracy_vs_iterations: イテレーションごとの検証データの精度を示しています。エポック内の各イテレーションでの精度の変化を見ることができます。黄色のラインで表されており、精度が安定しているかどうかを確認できます。
evaluation_loss_vs_iterations: イテレーションごとの検証データの損失を示したグラフです。損失が小さいほど、モデルがより良い予測をしていることを示します。この場合、損失が上がったり下がったりしているので、モデルがデータに対してどう適応しているかを確認できます。
kernel: エポックごとの重みパラメータ(カーネル)のヒストグラムを表示しています。重みの値の分布がどのように変化しているかを視覚化しています。
Settings: 画面左の項目は各グラフの表示方法を変更するメニューとなっています。
TensorBoard自体はTensorFlowに組み込まれており、実装方法も、既存スクリプトに追加するだけなので、とても簡単に実装することができます。
TensorBoardダッシュボード内でも表示の設定が変更できるので、モデルのトレーニングプロセスの理解を助けてくれると思います。

最近、衛星データを扱う機会があった為、忘備録も兼ねてデータアクセスから可視化までをご紹介したいと思います。
また、本記事では利用しているTellus APIを含むTellusプラットフォームの紹介と衛星データに対する簡単な解析も行います。
Tellus(テルース)は、政府衛星データを利用した新たなビジネスマーケットプレイスを創出することを目的とした、日本初のオープン&フリーな衛星データプラットフォームです。複数のデータをかけ合わせ、新たなビジネス創出を促進するためのあらゆるファンクションを提供します。
https://www.tellusxdp.com/ja/about
今回利用するTellus APIはTellusプラットフォームの内の一つです。
これまで衛星データを利用するとなると、特殊なデータフォーマットを扱い、高い処理能力を有したマシンが必要とされる面から産業に於いては限定的な利用状況でした。
これらの課題を解決する為に分析・アプリケーション開発などを行うクラウド環境を提供しているプラットフォームがTellusプラットフォームになります。
一口に衛星データといっても様々なセンサーデータが存在しています。
代表的なデータを紹介します。
光学衛星データは、可視光および近赤外線を使用して地表の画像を撮影します。特徴は以下の通りです。
代表的な光学衛星:Landsatシリーズ、Sentinel-2。
合成開口レーダー(SAR)データは、マイクロ波を利用して観測します。特徴は以下の通りです。
代表的なSAR衛星:Sentinel-1、ALOS-2。
ハイパースペクトルデータは、広範囲の波長にわたる詳細なスペクトル情報を提供します。特徴は以下の通りです。
代表的なハイパースペクトル衛星:Hyperion、EnMAP。
マルチスペクトルデータは、複数の波長帯域にわたるデータを取得します。特徴は以下の通りです。
代表的なマルチスペクトル衛星:Landsatシリーズ、Sentinel-2。
今回は光学衛星データを利用して可視化まで行います。
まずは、Tellus APIを利用する為にTellus Travelerに登録して、API tokenを発行する必要があります。
以下のURLにアクセスして新規アカウント作成を行います。
基本的には画面の案内に従って登録を行えば問題ないかと思います。
必要なものとしては、登録用のメールアドレスと2要素認証用の携帯電話番号が必要です。
アカウント作成が完了したら、以下のURLにアクセスするとアカウント設定画面にアクセスできます。
https://www.tellusxdp.com/account/setting/
「APIトークン」を押下するとAPIトークンの管理画面に移ります。
「トークンの発行」を押下してトークン名を決めるだけでAPIトークンが発行されます。
これで衛星データを利用する準備が整いました。
いよいよ衛星データを取得して可視化してみます。
今回は、Python(Jupyter notebook)を利用して行っていきます。
必要なライブラリをインストールしたいと思います。
APIを利用するのですが、今回はPythonクライアントを利用してデータの取得を行います。
また、衛星データを利用する際に地理データを参照する必要もある為、GISデータを扱えるGeoPandasもインストールします。
以下のコマンドにてインストールします。
python -m pip install geopandas tellus-traveler rioxarray matplotlibAPIコール時に緯度経度を利用して検索をかける為、GISデータを扱う必要がある為インストールします。
Tellus APIを利用する際のPythonクライアント
衛星データはGeoTiff形式で提供される為、画像処理する際に必要
最終的に可視化する為に利用
まずは、取得したAPIトークンをクライアントに設定します。
import tellus_traveler
# Tellus アクセストークンを取得
tellus_traveler.api_token = "[Your API Token]"Tellus APIでは、衛星データはデータセットと呼ばれる衛星センサー毎にまとめられた単位で管理されており、その中の特定エリアを観測した結果(光学センサなら画像)をシーンと呼びます。
今回は任意の場所のシーンを検索して表示するところまで行います。
まずは、どのようなデータセットが存在するのかデータセット一覧を取得します。
# 利用可能なデータセットを取得
datasets = tellus_traveler.datasets()
len(datasets)以下のような出力が得られました。
23どうやら23件のデータセットが利用可能なようです。
続いて取得したデータセット情報を見ていきましょう。
datasets[0]以下得られた出力です。
{'id': '1a41a4b1-4594-431f-95fb-82f9bdc35d6b',
'provider': {'name': 'テルース', 'description': 'テルースが提供する公式データです'},
'tags': [],
'published_at': '2021-10-08T14:24:12.960797+09:00',
'can_order_access_right': True,
'can_order_cut_data': False,
'is_order_required': False,
'minimum_purchase_square_kilometer': 0,
'square_kilometer_per_price': 0,
'related_site': 'https://www.eorc.jaxa.jp/ALOS/a/jp/index_j.htm',
'copyright': '©JAXA',
'properties': ['sat:orbit_state',
'sar:observation_direction',
'view:off_nadir',
'sar:polarizations',
'sar:frequency_band',
'sat:relative_orbit',
'tellus:sat_frame',
'sar:instrument_mode',
'processing:level',
'sar:product_type',
'gsd',
'palsar2:beam'],
'prices': [],
'name': '【Tellus公式】PALSAR-2_L1.1',
'description': 'JAXAが開発したPALSAR-2というSARセンサのデータです。',
'terms_of_use': '/api/traveler/v1/datasets/1a41a4b1-4594-431f-95fb-82f9bdc35d6b/terms-of-use-url/',
'manual': '/api/traveler/v1/datasets/1a41a4b1-4594-431f-95fb-82f9bdc35d6b/manual-url/',
'permission': {'allow_network_type': 'tellus'}}データセットの情報はJSON形式で返ってきます。
上記のデータセットは、JAXAが開発したPALSAR-2というSARセンサのデータセットの様です。
こちら調べると、JAXAが開発した「だいち2号(ALOS-2)」に搭載されたセンサのデータセットでした。
今回は、光学データを利用したいのでJAXAが開発した「だいち(ALOS)」に搭載されたAVNIR-2という光学センサで観測したデータに絞り込んでいきたいと思います。
# AVNIR-2のデータセットを抽出
avnir2_dataset = next(dataset for dataset in datasets if "AVNIR-2" in dataset["name"])
avnir2_dataset出力は以下の通りです。
{'id': 'ea71ef6e-9569-49fc-be16-ba98d876fb73',
'provider': {'name': 'テルース', 'description': 'テルースが提供する公式データです'},
'tags': [],
'published_at': '2021-10-08T14:26:06.089400+09:00',
'can_order_access_right': True,
'can_order_cut_data': False,
'is_order_required': False,
'minimum_purchase_square_kilometer': 0,
'square_kilometer_per_price': 0,
'related_site': 'https://www.eorc.jaxa.jp/ALOS/jp/alos/a1_about_j.htm',
'copyright': '©JAXA',
'properties': ['sat:orbit_state',
'tellus:pointing_angle',
'tellus:bands',
'sat:relative_orbit',
'tellus:sat_frame',
'processing:level',
'eo:cloud_cover',
'gsd'],
'prices': [],
'name': '【Tellus公式】AVNIR-2_1B1',
'description': '解像度10mの広域撮影を目的とした光学カラー画像です。\nJAXAのAVNIR-2センサデータから生成されています。',
'terms_of_use': '/api/traveler/v1/datasets/ea71ef6e-9569-49fc-be16-ba98d876fb73/terms-of-use-url/',
'manual': '/api/traveler/v1/datasets/ea71ef6e-9569-49fc-be16-ba98d876fb73/manual-url/',
'permission': {'allow_network_type': 'global'}}これでデータセットを特定できました。
つづいて、可視化したいシーンを検索していきます。
試しに東京都中野区のシーンを可視化したいので、まずは中野区の緯度経度を入手します。
国土地理院の行政区域データを
こちらから入手します。
ダウンロードが終わりましたら、zipファイルを解凍して.geojsonファイルを読み込んで中野区を矩形で囲える緯度経度を算出します。
# 国土地理院のデータから中野区の緯度経度を検索
import geopandas as gpd
tokyo_gdf = gpd.read_file('data/N03-20230101_13_GML/N03-23_13_230101.geojson')
nakano_ku_gdf = tokyo_gdf[tokyo_gdf['N03_004'] == '中野区']
nakano_ku_bbox = nakano_ku_gdf.total_bounds
print(nakano_ku_bbox)出力は以下の通りです。
[139.62432764 35.67634792 139.69433114 35.73538167]つづいて入手した緯度経度から指定範囲に該当するシーンを検索します。
検索後は、何件ヒットしたか確認します。
# tellus_travelerを使い検索
search = tellus_traveler.search(
datasets=[avnir2_dataset['id']],
bbox=nakano_ku_bbox,
start_datetime="2011-01-01T00:00:00Z",
end_datetime="2012-01-01T00:00:00Z",
)
search.total()出力は以下の通りです。
33つのシーンが検索できたようです。
では、実際にどの程度の範囲カバーできるシーンなのか確認してみます。
# 各シーンをリストに格納
scenes = list(search.scenes())
# 地図上での入手可能なシーンの位置を確認
# シーンの情報を元にGeoPandasデータフレームを作成
search_results_gdf = gpd.GeoDataFrame.from_features(scenes)
# 地図上での入手可能なシーンの位置を確認
# グラフで可視化
search_results_gdf.set_crs(epsg=4326).explore("tellus:name")出力は以下の通りです。
重なっていて分かりづらいですが、どのシーンでも中野区はカバー出来ている様です。
なので、最新のシーンを選びたいと思います。
# シーンを絞り込み
# 撮影時期が最新のシーンを検索
scenes_dates = [[x.__geo_interface__['properties']['end_datetime'], x['tellus:name']] for x in scenes]
scenes_dates = sorted(scenes_dates, key=lambda x:x[0], reverse=True)
scene = next(scene for scene in scenes if scene['tellus:name'] == scenes_dates[0][1])
scene.propertiesこれで可視化したいシーンを検索できました。
最後に得られたシーンをダウンロードして、指定の緯度経度で矩形に切り取り出力させてみたいと思います。
まずは、シーンのGeoTiffファイルをダウンロードします。
今回利用するGeoTiffはCOG(Cloud Optimized GeoTiff)と呼ばれるクラウドに特化したGeoTiffファイルをダウンロードします。
files = scene.files()
target_file = next(file for file in files if "webcog" in file["name"])
download_dir = 'data'
path = target_file.download(download_dir)続いてダウンロードしたファイルをrioxarrayを利用して読み込み、指定の緯度経度で画像を抜き出して表示します。
import matplotlib.pyplot as plt
import rioxarray
# COGを読み込み
data = rioxarray.open_rasterio(path, masked=True)
# 画像データを指定座標で切り抜き
clipped_data = data.rio.clip_box(*nakano_ku_bbox)
# Matplotlibで可視化
fig, ax = plt.subplots(figsize=(8, 8))
clipped_data.sel(band=[1, 2, 3]).astype("uint8").plot.imshow(ax=ax)
nakano_ku_gdf.plot(ax=ax, color="none")
ax.set_title(f"Nakano-Ku True Color\n{scene['tellus:name']}")
print(avnir2_dataset["copyright"])出力は以下の通りです。
これで、衛星データの可視化ができました。
今回利用した「だいち(ALOS)」に搭載されたAVNIR-2という光学センサですが、観測波長が可視光以外にも近赤外線をとらえることができております。
この近赤外線ですが、植物の葉に強く反射される為、植物の位置の可視化ができます。
先ほどの可視化例では、Bandの各波長に合わせてRGBを設定しましたが、Rの部分をBand4に設定することで植物を赤く可視化できます。
import matplotlib.pyplot as plt
import rioxarray
# COGを読み込み
data = rioxarray.open_rasterio(path, masked=True)
# 画像データを指定座標で切り抜き
clipped_data = data.rio.clip_box(*nakano_ku_bbox)
# Matplotlibで可視化
fig, ax = plt.subplots(figsize=(8, 8))
clipped_data.sel(band=[4, 1, 2]).astype("uint8").plot.imshow(ax=ax)
nakano_ku_gdf.plot(ax=ax, color="none")
ax.set_title(f"Nakano-Ku True Color\n{scene['tellus:name']}")
print(avnir2_dataset["copyright"])出力は以下の通りです。
赤みがかった部分が植物が存在していると考えられる場所です。
今回はTellus APIを利用して衛星データの取得から可視化までの方法を紹介しました。
衛星データもこんなに簡単に扱える時代になっていて驚きました。
次は光学センサ以外のデータも扱ってみたいと思います。
https://tellus-traveler.readthedocs.io/en/latest/
以前こちらの記事で、AWS SageMaker Canvas という AutoMLツールを使って、医療費の予測モデルを作成しました。本記事は、(自分の勉強用に)この回帰モデルをコーディングで作ってみようという主旨です。また、こちらの記事で、TensorFlow Playground を使用したので、ライブラリも TensorFlow を使おうと思います。
学習に使用するデータは CSV で、カラムの構成は以下になっています。
これらのデータを使用して、回帰モデルを TensorFlow を使用して作成します。
まず、必要なライブラリをインストールし、インポートします。
pip install pandas scikit-learn tensorflow次に、Pythonスクリプトで必要なライブラリをインポートします。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.metrics import mean_absolute_error, mean_squared_errorデータを読み込み、データを特徴量(X)とターゲット(y)に分割、カテゴリカルデータのエンコードと数値データの標準化を行い、データを学習用とテスト用に分割します。
# データの読み込み
data = pd.read_csv('insurance_data.csv')
# 特徴量とターゲットの分割
X = data.drop('charges', axis=1)
y = data['charges']
# カテゴリカルデータのエンコードと数値データの標準化
categorical_features = ['sex', 'smoker', 'region']
numeric_features = ['age', 'bmi', 'children']
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(), categorical_features)
])
# データの前処理
X_processed = preprocessor.fit_transform(X)
# トレーニングデータとテストデータの分割
X_train, X_test, y_train, y_test = train_test_split(X_processed, y, test_size=0.2, random_state=42)charges 列が予測対象(ターゲット)となるため、これを y として分離し、他の列を特徴量 X として扱います。categorical_features に指定された列(sex, smoker, region)はカテゴリカルデータです。これらは数値データではないため、モデルが直接利用できません。OneHotEncoder を使用してカテゴリカルデータをバイナリ(0または1)に変換します。この手法により、カテゴリカルデータを数値データとしてモデルに提供できます。numeric_features に指定された列(age, bmi, children)は数値データです。これらのデータはスケールが異なることが多いため、モデルが効率的に学習するためにはスケーリングが必要です。StandardScaler を使用して標準化を行います。標準化は、各特徴量を平均0、標準偏差1にスケーリングします。これにより、すべての数値データが同じスケールで扱われ、モデルの学習が安定します。ColumnTransformer を使用して、数値データの標準化とカテゴリカルデータのエンコードを一度に処理します。これにより、前処理のステップを簡潔に行うことができます。train_test_split を使用して、データを80%のトレーニングデータと20%のテストデータに分割します。random_state=42 を指定することで、分割の再現性を確保します。TensorFlowを使用してシーケンシャルモデルを構築します。
# モデルの構築
model = Sequential([
Dense(64, activation='relu', input_shape=(X_train.shape[1])), # 入力層と第1隠れ層
Dense(64, activation='relu'), # 第2隠れ層
Dense(1) # 出力層
])Sequential: モデルの各層が順に積み重なっていく単純なスタックモデルを定義するためのクラス。Dense: 全結合層。ユニット数と活性化関数を指定。各ニューロンが前の層のすべてのニューロンと接続されていることを示します。
64: ユニットの数。この場合、64個のユニットを持つ全結合層を追加します。(ここでは64)は層の出力の次元を指定。activation='relu': 活性化関数としてReLUを使用します。input_shape=(X_train.shape[1]): 最初の層にのみ必要で、入力データの形状を指定。X_train の特徴量の数を指定しています。モデルをコンパイルします。
# モデルのコンパイル
model.compile(optimizer='adam', loss='mean_squared_error')optimizer='adam': モデルの重みを最適化するためのアルゴリズム(ここではAdamオプティマイザーを使用)。loss='mean_squared_error': モデルがどれだけ悪いかを定量化するための損失関数(ここでは平均二乗誤差(MSE)を使用)。トレーニングデータを使用してモデルをトレーニングします。
# モデルのトレーニング
history = model.fit(X_train, y_train, epochs=100, validation_split=0.2, batch_size=32)model.fit: モデルのトレーニングを行うメソッドです。このメソッドを呼び出すことで、モデルは指定されたデータで学習を開始します。
epochs: トレーニングデータ全体を何回繰り返すかを指定。validation_split: トレーニングデータの一部を検証データとして使用する割合を指定(ここでは20%)。batch_size: 1エポックでトレーニングに使用するデータのサブセットのサイズを指定。トレーニング過程をプロットし、トレーニング中のモデルパフォーマンスを確認します。
# トレーニング過程のプロット
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
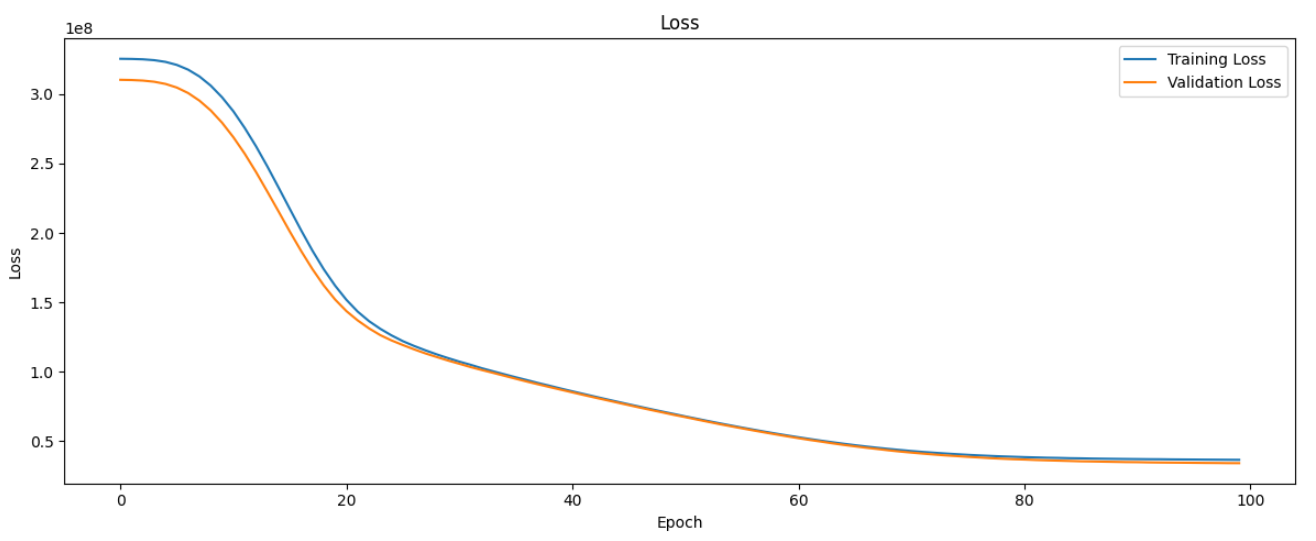
plt.show()Matplotlib に関しては割愛します。結果は以下の通り。
横軸はエポック数(Epoch)、縦軸は損失(Loss)を表しています。青い線はトレーニングデータに対する損失、オレンジの線は検証データに対する損失を示しています。
損失がエポック数が増えるにつれて安定していることから、モデルの学習が収束していることがわかります。つまり、これ以上学習を続けても損失の減少が期待できない状態に達しています。
テストデータを使用してモデルの予測を行い、評価指標を計算します。
# テストデータでの予測
y_pred = model.predict(X_test)
# モデルの評価
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = mean_squared_error(y_test, y_pred, squared=False)
print(f'MAE: {mae}')
print(f'MSE: {mse}')
print(f'RMSE: {rmse}')model.predict(X_test): トレーニング済みのモデルを使って、テストデータ (X_test) に対する予測を行う関数です。この関数は、テストデータに基づいてモデルが予測した値を返します。
mean_absolute_error(y_test, y_pred): 平均絶対誤差(MAE)を計算します。これは、予測値と実際の値の差の絶対値の平均です。MAEが小さいほど、予測の精度が高いことを示します。mean_squared_error(y_test, y_pred): 平均二乗誤差(MSE)を計算します。これは、予測値と実際の値の差の二乗の平均です。MSEが小さいほど、予測の精度が高いことを示します。mean_squared_error(y_test, y_pred, squared=False): 平方根平均二乗誤差(RMSE)を計算します。これは、MSEの平方根を取ったものです。RMSEが小さいほど、予測の精度が高いことを示します。結果ですが、以下が出力されました。
MAE: 4060.9136578962225
MSE: 32895051.458825566
RMSE: 5735.4207743482575
ちなみに AWS SageMaker Canvas の結果は以下でした。
MAE: -
MSE: 23578592.000
RMSE: 4855.799
どちらも良い結果ではないですが、比較では Canvas の方が良い結果となりました。
以上の手順で、医療費(Charges)の予測モデルを作成しました。評価を見るに、まだ改善の余地はありますが、回帰モデルを TensorFlow を使って作成することができました。Canvas の方が良い結果となりましたが、TensorFlow(ニューラルネットワーク)でなく他の手法を使うなどすればまた変わってくると思うのでまた試してみたいと思います。
Canvas については GUI ベースの使いやすい AutoMLツールであるので、興味があれば使ってみてください。
以前こちらの記事で、Google Teachable Machine という AutoMLツールを使って、顔写真の表情分類モデルを作成しました。本記事は、(自分の勉強用に)この分類モデルをコーディングで作ってみようという主旨です。また、こちらの記事で、TensorFlow Playground を使用したので、ライブラリも TensorFlow を使おうと思います。
学習に使用する画像は 48x48 の JPEG形式で、Happy, Angry, Sad, Surprise のフォルダに分かれており、それぞれのフォルダには以下の枚数の画像が含まれています。
これらの画像を使用して、感情分類モデルを TensorFlow を使用して作成します。
まず、必要なライブラリをインストールし、インポートします。
pip install tensorflow matplotlib次に、Pythonスクリプトで必要なライブラリをインポートします。
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as pltデータジェネレータを使用して、トレーニングデータとテストデータを準備します。
# データジェネレータの設定
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
validation_split=0.2 # トレーニングデータの20%を検証データとして使用
)ImageDataGenerator: 画像データの前処理やデータオーグメンテーションを行うためのクラスです。train_datagen: トレーニングデータの前処理とデータオーグメンテーションを設定します。
rescale=1./255: 画像のピクセル値を0-255から0-1に正規化します。shear_range=0.2: 画像をランダムに傾けます。zoom_range=0.2: 画像をランダムにズームします。horizontal_flip=True: 画像をランダムに水平反転します。validation_split=0.2: トレーニングデータの20%を検証データとして使用します。test_datagen: テストデータの前処理を設定します。
rescale=1./255: 画像のピクセル値を0-255から0-1に正規化します。# トレーニングデータのジェネレータ
train_generator = train_datagen.flow_from_directory(
'emotional/train',
target_size=(48, 48), # 画像のサイズを48x48に設定
color_mode='grayscale', # グレースケール画像として読み込む
batch_size=16, # バッチサイズを16に設定
class_mode='categorical',
subset='training' # トレーニングデータ
)
# 検証データのジェネレータ
validation_generator = train_datagen.flow_from_directory(
'emotional/train',
target_size=(48, 48), # 画像のサイズを48x48に設定
color_mode='grayscale', # グレースケール画像として読み込む
batch_size=16, # バッチサイズを16に設定
class_mode='categorical',
subset='validation' # 検証データ
)flow_from_directory: ディレクトリから画像を読み込み、前処理を行い、バッチ単位でデータを生成します。
'emotional/train': トレーニングデータが格納されているディレクトリのパス。target_size=(48, 48): すべての画像を48x48ピクセルにリサイズします。batch_size=16: 1バッチあたりの画像の数を16に設定します。(Google Teachable Machineの設定に合わせました)class_mode='categorical': 出力ラベルが複数クラスに分かれていることを示します。subset='training': トレーニング用のデータを生成します。TensorFlowを使用してシーケンシャルモデルを構築します。
# モデルの構築
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(48, 48, 1)),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(4, activation='softmax') # 出力層(4つのクラス)
])Sequential:ニューラルネットワークモデルの各レイヤーを順次積み重ねるためのクラスです。このモデルでは、各レイヤーが順番に追加されていきます。
Conv2D: 2次元の畳み込み層。フィルタの数、カーネルサイズ、活性化関数、入力形状を指定。
32: フィルターの数。この場合、32個のフィルターを使用します。(3, 3): フィルターのサイズ。この場合、3x3のフィルターを使用します。activation='relu': 活性化関数としてReLUを使用します。ReLUは、負の値を0にし、正の値をそのまま通します。input_shape=(48, 48 1): 入力データの形状を指定します48x48ピクセルのグレースケール画像(1チャンネル、カラー画像なら3)を入力とします。この指定は最初の層にのみ必要です。MaxPooling2D: プーリング層。プーリングサイズを指定。
pool_size=(2, 2): プーリングサイズ。この場合、2x2の領域ごとに最大値を取得します。Flatten: 2次元の特徴マップを1次元のベクトルに変換します。この変換により、全結合層(Dense Layer)にデータを渡すことができます。Dense: 全結合層。ユニット数と活性化関数を指定。
512: ユニットの数。この場合、512個のユニットを持つ全結合層を追加します。activation='relu': 活性化関数としてReLUを使用します。Dropout: ドロップアウト層。過学習を防ぐために一部のユニットをランダムに無効化。
0.5: ドロップアウト率。この場合、ランダムに50%のユニットを無効化します。softmax: 出力層の活性化関数。分類問題で使用され、クラスごとの確率を出力。モデルをコンパイルします。
# モデルのコンパイル
model.compile(
optimizer=Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy']
)optimizer=Adam(learning_rate=0.001): オプティマイザーは、モデルの重みをどのように更新するかを決定するアルゴリズムです。ここではAdamを使用します。Adamは、学習率の調整を自動で行い、収束が速いとされる最適化アルゴリズムです。学習率を0.001にしているのは、 Google Teachable Machine のデフォルトに合わせました。loss='categorical_crossentropy': 損失関数として、多クラス分類に適したカテゴリカルクロスエントロピーを使用します。metrics=['accuracy']: モデルの評価指標として精度を使用します。精度は、正しく分類されたサンプルの割合を示します。トレーニングデータを使用してモデルをトレーニングします。
# モデルのトレーニング
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // train_generator.batch_size,
validation_data=validation_generator,
validation_steps=validation_generator.samples // validation_generator.batch_size,
epochs=50
)model.fit: モデルのトレーニングを行うメソッドです。このメソッドを呼び出すことで、モデルは指定されたデータで学習を開始します。
train_generator:トレーニングデータのジェネレータです。このジェネレータは、ディスクからバッチ単位で画像を読み込み、前処理を行い、モデルに供給します。steps_per_epoch: 1エポックあたりのトレーニングステップ数です。train_generatorのサンプル数をバッチサイズで割った値です(train_generator.samples // train_generator.batch_size)。これは、1エポックでトレーニングデータ全体を一度処理するために必要なステップ数を示します。validation_data: 検証データのジェネレータです。トレーニング中にモデルの性能を評価するために使用されます。トレーニングデータと同じディレクトリから、検証用に指定された画像データを読み込みます。validation_steps: 1エポックあたりの検証ステップ数です。validation_generator のサンプル数をバッチサイズで割った値です(validation_generator.samples // validation_generator.batch_size)。steps_per_epoch と同様。epochs:トレーニングを行うエポック数です。1エポックは、モデルがトレーニングデータセット全体を一度学習することを意味します。ここでは、50エポックを指定しており、これも Google Teachable Machine のデフォルトに合わせています。history:
model.fit メソッドは、トレーニングの過程(各エポックごとの損失と精度の履歴)を含む History オブジェクトを返します。history オブジェクトを使用することで、トレーニング中のモデルのパフォーマンスを可視化することができます。トレーニング過程をプロットし、トレーニング中のモデルパフォーマンスを確認します。
# トレーニング過程のプロット
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
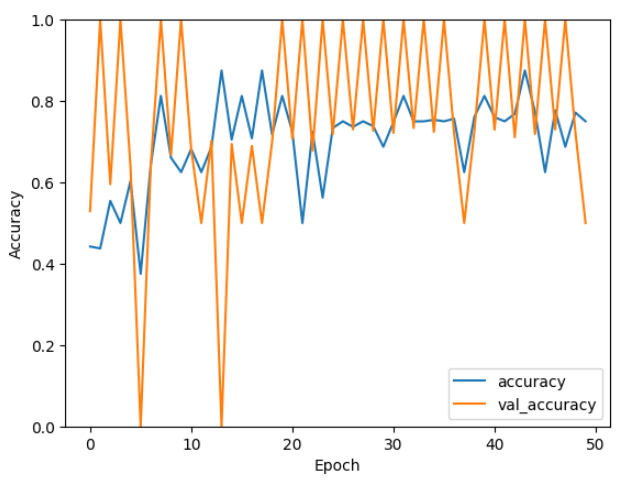
plt.show()Matplotlib に関しては割愛します。結果は以下の通り。
横軸はエポック数(Epoch)、縦軸は精度(Accuracy)を表しています。青い線はトレーニングデータに対する精度、オレンジの線は検証データに対する精度を示しています。
本来であればデータの前処理、学習率の調整など再度行ったりしますが、今回はこのモデルの評価を行ってみます。
テストデータを使って、モデルの評価を行います。テストデータも学習データと同様にフォルダ分けされており、それぞれ以下の枚数となっています。
# データジェネレータの設定
test_datagen = ImageDataGenerator(rescale=1./255)
# テストデータのジェネレータ
test_generator = test_datagen.flow_from_directory(
'emotional/test', # テストデータが含まれるディレクトリのパス
target_size=(48, 48), # 画像のサイズを48x48に設定
color_mode='grayscale', # グレースケール画像として読み込む
batch_size=16, # バッチサイズを16に設定
class_mode='categorical'
)
# テストデータの評価
test_loss, test_acc = model.evaluate(
test_generator,
steps=test_generator.samples // test_generator.batch_size
)
print(f'Test accuracy: {test_acc}')(テストデータのジェネレータについては学習データ・検証データと同様です。)
model.evaluate: モデルを評価するためのメソッド。このメソッドを使用して、モデルの損失と精度を計算します。
test_generator: train_generator, validation_generator と同様です。steps: 1エポックあたりのテストステップ数です。test_generator のサンプル数をバッチサイズで割った値です(test_generator.samples // test_generator.batch_size)。これは、テストデータ全体を一度処理するために必要なステップ数を示します。test_loss: テストデータに対する損失値です。損失値は、モデルの予測と実際の値との誤差を示します。この値が小さいほど、モデルの予測精度が高いことを示します。test_acc: テストデータに対する精度です。精度は、正しく分類されたサンプルの割合を示します。この値が大きいほど、モデルの予測精度が高いことを示します。結果ですが、以下が出力されました。
Test accuracy: 0.752916693687439
ちなみに Google Teachable Machine の結果は以下でした。
これと比較した限りでは悪くない結果ではないでしょうか。
以上の手順で、画像分類モデルを作成しました。やはり AutoMLツールと比較して手間がかかりますが、技術の理解は深まると思います。簡単にモデルを作りたい場合だと Google Teachable Machine で作ってみるというのも選択肢の一つとしてアリかと思います。
Google Teachable Machine についてはこちらから無料で使うことができますので、興味があれば使ってみてください。
以前 TensorFlow Playground というニューラルネットワークデモツールを使用したので、使い方などまとめてみました。

この記事では、AWSを利用してRAGを搭載したチャットシステムを構築する方法を紹介します。
また、この記事で紹介している内容は5/21, 22, 23にグランドニッコー東京 台場で開催された「ガートナー データ&アナリティクス サミット 2024」に出展しました。
こちら、シリーズものの記事になっており、初回の記事はこちらから読めますので、初回の記事から是非ご一読いただければと思います。
続いて生成AIを制御するサービスの設定を行います。
今回はClaude v3を利用する為、リージョンをus-west-2に変更して作業を行います。
Claude v3は東京リージョンでは、まだ利用できない為、リージョンを変更します。
コンソールでAmazon Bedrockにアクセスして「使用を開始」をクリックします。
以下の画面に遷移したら、左下にある「モデルアクセス」をクリックします。
画面上部に「Enable specific model」をクリックします。
アクセス可能なモデルの一覧が出てくるので「Anthropic」にある「Claude 3 Haiku」をチェックして画面下部にある「Next」をクリックします。
ユースケースを聞かれますので、適宜入力していきます。
入力後、確認画面に行きますので「Submit」をクリックします。
暫くすると、Bedrockのモデルアクセス欄に「アクセスが付与されました」と表示されます。
表示されたら、準備は完了です。
今回のデモでは、EC2を立ち上げてそのインスタンス内にStreamlitで作成したアプリケーションを立ち上げています。
EC2の立ち上げに関しては割愛させて頂きます。
アプリケーションは以下のようなディレクトリ構成をしています。
anywhere/
│
├ data/
│ ├ id2url.json
│ └ app.ini
│
├ static/
│ └ 177419.png
│
└ app.py以下、配置しているファイルの説明です。
本来であれば、id2url.jsonのデータはAWSの何かしらのサービスに置き換えたり、認証情報周りは環境変数に置き換えたりする必要があるかと思います。(今回は時間の都合などで簡易的なつくりになってます。)
今回のアプリケーションの動作の流れとしては以下の画像のようなイメージとします。
ここからは、各関数の細かい動作を解説します。
まずは、必要なライブラリのインポートと各種サービスのインスタンス作成します。
import streamlit as st
import boto3
import json
import numpy as np
import configparser
from PIL import Image
# 認証情報を読み込み
config = configparser.ConfigParser()
config.read('data/app.ini')
ACCESS_KEY = config['AWS_ACCESS_INFO']['ACCESS_KEY']
SERCRET_KEY = config['AWS_ACCESS_INFO']['SERCRET_KEY']
KENDRA_INDEX_ID = config['AWS_ACCESS_INFO']['KENDRA_INDEX_ID']
BOT_AVATOR_IMG = np.array(Image.open("static/177419.jpg"))
# Kendraインスタンス作成
kendra = boto3.client(
'kendra',
region_name='ap-northeast-1',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SERCRET_KEY
)
# Bedrockインスタンス作成
bedrock = boto3.client(
service_name='bedrock-runtime',
region_name='us-west-2',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SERCRET_KEY
)
# 記事の付随情報読み込み
with open('data/id2url.json', 'r', encoding='utf-8')as f:
id2url = json.load(f)ここでは、bedrockのみオレゴン(us-west-2)にリージョンが変更になっていることに注意してください。
続いて、ユーザーとのやり取りや各種処理関数を扱うmain関数を作成します。
# アプリケーションメイン関数
def main():
st.set_page_config(page_title="INSIGH LAB Knowledge Searcher", page_icon="📖")
st.title('INSIGH LAB Knowledge Searcher')
with st.sidebar:
st.markdown(
"""
### アプリケーションについて
このアプリケーションは、INSIGHT LAB社内向けのKnowledge検索アプリケーションです。
本アプリには、RAG(Retrieval-Augmented Generation)機能が採用されており、機能を有効化するとINSIGHT LAB Knowledgeを元に回答を生成します。
下記のトグルをクリックすることでRAG機能を有効化することができます。
"""
)
st.write("")
st.markdown('### オプション')
is_rag = st.toggle('RAG有効化')
if "messages" not in st.session_state:
st.session_state.messages = []
# 既存のチャットメッセージを表示
all_messages = []
if st.session_state.messages:
for info in st.session_state.messages:
if info['role'] == 'Assistant':
with st.chat_message(info["role"], avatar=BOT_AVATOR_IMG):
st.write(info["content"])
else:
with st.chat_message(info["role"]):
st.write(info["content"])
all_messages.append(info['content'])
message_hist = '\n'.join(all_messages[:5])
# 新しいユーザー入力を処理
if prompt := st.chat_input("質問を入力してください。"):
# ユーザーメッセージ処理
st.session_state.messages.append({"role": "Human", "content": prompt})
with st.chat_message("Human"):
st.write(prompt)
# AIのレスポンスを準備して表示
with st.chat_message("Assistant", avatar=BOT_AVATOR_IMG):
message_placeholder = st.empty()
with st.spinner("回答生成中..."):
response = invoke_model(prompt, message_hist, is_rag)
response_body = json.loads(response.get("body").read())
results = response_body.get("content")[0].get("text")
# レスポンスを表示
message_placeholder.write(results)
# AIのレスポンスをセッション状態に追加
st.session_state.messages.append(
{"role": "Assistant", "content": results}
)基本的にはStreamlitのchat_message機能とSession_stateを利用してメッセージの表示を行っています。
回答を生成しているのは、invoke_modelという関数でcreate_queryやget_retrieval_resultは入れ子方式でinvoke_model関数内で利用されている形になっています。
この関数では、最終的な回答を生成している関数になります。
# 回答生成関数
def invoke_model(prompt, message_hit, is_rag=False):
if is_rag:
retrieval_result = get_retrieval_result(prompt, KENDRA_INDEX_ID, message_hit)
prompt = """
\n\nHuman:
[参考]情報に回答の参考となるドキュメントがあるので、すべて理解してください。
[回答のルール]を理解して、このルールを絶対守ってください。ルール以外のことは一切してはいけません。
[参考]情報を元に[回答のルール]に従って[質問]に適切に回答してください。
[回答のルール]
* [参考]内の'ORIGIN_URL'のリンクと'DOC_TITLE'を下記の形式で回答の末尾に表示してください。絶対に複数ある場合は改行で区切り、その間に空白行を一つ空けてください。
参考記事:[[DOC_TITLE]]([ORIGIN_URL])<br></br>
* [参考]の文章を理解した上で回答を作成してください。
* 質問に具体性がなく回答できない場合は、質問の仕方をアドバイスしてください。
* [参考]の文章に答えがない場合は、一般的な回答をお願いします。
* 質問に対する回答のみを行ってください。
* 雑談や挨拶には応じないでください。「私は雑談はできません。技術的な質問をお願いします。」とだけ出力してください。他の文言は一切出力しないでください。例外はありません。
* 回答文以外の文字列は一切出力しないでください。回答はJSON形式ではなく、テキストで出力してください。見出しやタイトル等も必要ありません。
[質問]
{}
[参考]
{}
Assistant:""".format(prompt, retrieval_result)
else:
prompt = """
\n\nHuman:
[回答のルール]を理解して、このルールを絶対守ってください。ルール以外のことは一切してはいけません。
[回答のルール]に従って[質問]に適切に回答してください。
[回答のルール]
* 質問に具体性がなく回答できない場合は、質問の仕方をアドバイスしてください。
* 質問に対する回答のみを行ってください。
* 雑談や挨拶には応じないでください。「私は雑談はできません。技術的な質問をお願いします。」とだけ出力してください。他の文言は一切出力しないでください。例外はありません。
* 回答文以外の文字列は一切出力しないでください。回答はJSON形式ではなく、テキストで出力してください。見出しやタイトル等も必要ありません。
[質問]
{}
Assistant:""".format(prompt)
prompt_config = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
],
}
],
}
body = json.dumps(prompt_config)
modelId = "anthropic.claude-3-haiku-20240307-v1:0"
accept = "application/json"
contentType = "application/json"
response = bedrock.invoke_model(
body=body, modelId=modelId, accept=accept, contentType=contentType
)
return responseUIを表示しているmain関数側でRAGのon/offが可能になる様にフラグで制御しております。
また、LLMの回答に対して質問文をそのまま投げるのではなく、細かいルールを設定することでLLMの回答をある程度制御しています。
続いて、Kendraでドキュメント検索を行っている関数を解説します。
# Kendra検索
def get_retrieval_result(query_text: str, index_id: str, query_hist: str):
custom_query = create_query(query_text, query_hist)
response = kendra.retrieve(
QueryText=custom_query,
IndexId=index_id,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
# Kendra の応答から最初の5つの結果を抽出
results = response['ResultItems'][:5] if response['ResultItems'] else []
extracted_results = []
for item in results:
content = item.get('Content')
document_uri = item.get('DocumentURI')
article_id = document_uri.split('/')[-1].replace('.txt', '')
url = id2url[article_id]['url']
title = id2url[article_id]['title']
extracted_results.append({
'Content': content,
'DocumentURI': document_uri,
'DOC_TITLE': title,
'ORIGIN_URL': url
})
return extracted_resultsここではシンプルにKendraで検索後、検索したドキュメントのIDを元にURLとタイトルを付与して結果を返しています。
最後に、Kendra検索用の文を生成している関数を解説します。
# Kendra検索用クエリ作成
def create_query(prompt, message_hist):
prompt = """
あなたは、文書検索で利用するQueryを生成するAIアシスタントです。
<Query生成の手順></Query生成の手順>の通りにQueryを生成してください。
<Query生成の手順>
* 以下の<Query履歴></Query履歴>の内容を全て理解してください。履歴は古い順に並んでおり、一番下が最新のQueryです。
* 「要約して」などの質問ではないQueryは全て無視してください
* 「〜って何?」「〜とは?」「〜を説明して」というような概要を聞く質問については、「〜の概要」と読み替えてください。
* ユーザが最も知りたいことは、最も新しいQueryの内容です。最も新しいQueryの内容を元に、30トークン以内でQueryを生成してください。
* 出力したQueryに主語がない場合は、主語をつけてください。主語の置き換えは絶対にしないでください。
* 主語や背景を補完する場合は、「# Query履歴」の内容を元に補完してください。
* Queryは「〜について」「〜を教えてください」「〜について教えます」などの語尾は絶対に使わないでください
* 出力するQueryがない場合は、「No Query」と出力してください
* 出力は生成したQueryだけにしてください。他の文字列は一切出力してはいけません。例外はありません。
</Query生成の手順>
<Query履歴>
{}
[最新のQuery履歴]
{}
</Query履歴>
""".format(message_hist, prompt)
bedrock = boto3.client(
service_name='bedrock-runtime',
region_name='us-west-2',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SERCRET_KEY
)
prompt_config = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
],
}
],
}
body = json.dumps(prompt_config)
modelId = "anthropic.claude-3-haiku-20240307-v1:0"
accept = "application/json"
contentType = "application/json"
response = bedrock.invoke_model(
body=body, modelId=modelId, accept=accept, contentType=contentType
)
custom_query = json.loads(response.get("body").read())
custom_query = custom_query.get("content")[0].get("text")
return custom_queryここでもプロンプトに細かなルール敷いてKendra検索用文を生成させています。
起動させて、アドレスにアクセスすると以下のような画面が出現します。
質問を投げるとこのような形でレスしてくれます。
きちんとルール通りに返してくれていますが、一部記事を読まないとわからない表現も出てきていますね。
今回は、「ガートナー データ&アナリティクス サミット 2024」に出展した生成AIを利用したChatbotシステムの構築を解説しました。
実態としては、ここにアプリケーションが動いているEC2を保護する為にVPNを設定していたりするのですが、今回は割愛させて頂きました。
KendraとBedrockを利用することで、非常に簡単にRAGを搭載したチャットボットが作成できたかと思います。
また、チャットボットに関してはLangChainといったフレームワークも存在するので、こちらも触ってみたいと思います。
この記事では、AWSを利用してRAGを搭載したチャットシステムを構築する方法を紹介します。
また、この記事で紹介している内容は5/21, 22, 23にグランドニッコー東京 台場で開催された「ガートナー データ&アナリティクス サミット 2024」に出展しました。
こちら、シリーズものの記事になっており、初回の記事はこちらから読めますので、初回の記事から是非ご一読いただければと思います。
準備の為に上記項目で入手したドキュメントをS3に配置します。
S3のバケットを作成して以下の画像の様にテキストファイルを配置します。
KendraからS3を扱う為にKendra用のロールを作成します。
今回は検証用なので、S3のフルコントロールを付与しますが、サービスとして機能させる場合はバケットレベルでの最小権限を付与する必要があるかと思います。
以下、付与している権限の例です。
画像上にカスタマー管理の権限もある為、そちらもJSON形式で表記していきます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"cloudwatch:namespace": "AWS/Kendra"
}
}
},
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogGroups"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup"
],
"Resource": [
"arn:aws:logs:[Region]:[Account-ID]:log-group:/aws/kendra/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:[Region]:[Account-ID]:log-group:/aws/kendra/*:log-stream:*"
]
}
]
}次にAmazon KendraでのIndex(ベクトルDB)を作成します。
コンソールでAmazon Kendraにアクセスします。
「Create an Index」をクリックすると以下のIndexの作成画面に遷移します。
「Index name」には任意の名前を入力します。
「IAM role」は先ほど作成したロールを指定します。
設定が完了しましたら「Next」をクリックします。
次はアクセスコントロールの項目を設定します。
今回は特に設定を行いません。
設定項目としては、以下の通りです。
Indexアクセス時にセキュリティトークンをチェックする設定にするかどうかの項目
Yesにすると以下の画面が出てきてトークンの種類が選べます。
AWS IAM Identity Centerを利用したアクセス制限をかけることができます。
例えば、とある部署には見せたくないドキュメントがあればドキュメントにタグをつけてAWS IAM Identity Centerのユーザーグループとタグの紐づけが可能です。
Kendraを呼び出す際にIAMユーザーが必要なので特定のユーザーグループに属する人には、Kendraの検索結果には載せないという設定ができます。
続いてIndexのエディションを選択します。
Kendraには、エディションが二つあり、「Developer edition」と「Enterprise edition」があります。
以下、各エディションの違いです。
Developer edition
Enterprise edition
利用可能なドキュメント件数や料金も異なってくるので、必要に応じて設定してください。
今回は、Developer editionを選択します。
最後は確認画面になります。
「Create」をクリックするとIndexが作成されます。
クリック後、作成には30分程度時間が掛かるのでご注意ください。
続いてドキュメントの同期を行います。
KendraはIndexというベクトルDBにドキュメントを格納する必要があります。
コンソールから作成したIndexの概要を開き「Add data sources」をクリックします。
クリックするとデータソースを選択する画面に遷移します。
ここではS3だけでなく、boxやconfluence等他のコネクタもあります。
今回は「Amazon S3 connector」を選択します。
選択するとデータソース設定画面に移ります。
「Data source name」は任意の名前を入力します。
「Default language of source documents」はデータソース内の言語を設定します。
ここでは、Japanese(ja)を選択します。
設定後、「Next」をクリックします。
次にアクセスとセキュリティ設定を行います。
「IAM role」は、前項で作成したロールを設定します。
「Configure VPC and security group - optional」はVPC経由でドキュメントをロードする場合に設定します。
続いて、ロードするS3を選択します。
「Sync scope」では、ドキュメントを配置しているS3を指定します。
「Sync mode」は、「Sync scope」で指定した範囲内で更新があった場合の同期の方法を設定します。
以下、同期方法です。
変更に関係なく全ドキュメントを読み込みます。
変更された差分のみ読み込み、削除を行います。
「Sync run schedule」は同期のスケジュール設定を行います。
これらを設定後「Next」をクリックします。
次は、ドキュメントに対するメタデータの設定になります。
こちらはS3を設定しているので「s3_document_id」のみですが、他のコネクタですとドキュメントに対するメタデータを設定できます。
今回はこのまま「Next」をクリックします。
最後は、確認の画面になります。
「Add data source」をクリックするとデータソースが作成されます。
作成されると下記の画像のような画面に遷移します。
画面に遷移したら、「Sync Now」をクリックするとS3に配置されたドキュメントの読み込みが始まります。
完了すると下記の画像のような画面となります。
これで、Amazon Kendraの準備が完了しました。
本記事では、Amazon Kendraが利用できるようにIndexの作成解説を行いました。
次の記事では、Amazon Bedrockを有効化して、簡単なChatbotシステムを作成していきます。
次の記事もご一読頂ければ幸いです。
この記事では、AWSを利用してRAGを搭載したチャットシステムを構築する方法を紹介します。
また、この記事で紹介している内容は5/21, 22, 23にグランドニッコー東京 台場で開催された「ガートナー データ&アナリティクス サミット 2024」に出展しました。
RAG(Retrieval-Augmented Generation)とは、生成モデルとベクトルDBを組み合わせたアプローチ方法を指します。
基本的な構成は下記の画像の様になります。
事前にベクトルDBに生成モデルに参照させたいドキュメントをベクトル化しておきます。
ユーザーの入力文より類似した文を検索することで生成モデルが回答文を生成する為の参考文を検索します。
付随情報を参照するようなプロンプトを入力文と共に入力することで回答文を生成します。
このような構成にすることで、プロンプトの調整次第ですが付随情報の内容のみを参照させて回答させることができます。
RAGの利点としては以下のような点が挙げられます。
生成モデルを利用する上での注意点であるハルシネーション(生成モデルの嘘)を参考文の情報のみを参照させることで防止ができます。
また、定期的にベクトルDBを更新することで最新情報のキャッチアップが可能です。
生成モデルに専門性を持たせる際にファインチューニングや強化学習を行う必要がありますがRAGに於いては参照先のベクトルDBを切り替えることで対応可能です。
今回構築していくRAGの構成を解説します。
構成としては、下記のようになっています。
構成自体は単純で、ユーザーの入出力を制御するEC2内のアプリケーションをPythonで構築して、ベクトルDBをAmazon Kendraとし、生成AIをAmazon Bedrockを介してClaude v3 Haikuとする形になっています。
肝心の参考文に関しては、Notion内にあるISL Knowledgeの記事全件を読み込んでいます。
よって、今回のRAGはISLの技術力の集合知を表すものになるかと思います。
今回はNotionからAPIを利用して全件の記事を収集します。
まずは、全記事の概要データを収集します。
下記のPythonコードで実行します。
import requests
import json
import numpy as np
import pandas as pd
from tqdm import tqdm
# トークン情報
NOTION_ACCESS_TOKEN = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
NOTION_DATABASE_ID = 'XXXXXXXXXXXXXXXXXXXX'
# 各変数
loop_cnt = 1
has_more = True
data = []
all_titles = []
authors = []
create_times = []
article_ids = []
urls = []
statuses = []
tag_sets = []
author_emails = []
next_cursor = None
# APIでデータベース内のデータを全件取得
while has_more:
url = f"https://api.notion.com/v1/databases/{NOTION_DATABASE_ID}/query"
headers = {
'Authorization': 'Bearer ' + NOTION_ACCESS_TOKEN,
'Notion-Version': '2021-05-13',
'Content-Type': 'application/json',
}
payload = {'page_size': 100} if loop_cnt == 1 else {'page_size': 100, 'start_cursor': next_cursor}
result_json = requests.post(url, headers=headers, data=json.dumps(payload))
data += result_json.json().get('results')
has_more = result_json.json().get('has_more')
next_cursor = result_json.json().get('next_cursor')
print('loop: {}'.format(loop_cnt))
loop_cnt += 1
# 取得したデータを保存
with open('notion_knowledge_data.json', 'w')as f:
json.dump(data, f, indent=1)
# 各記事の情報を収集
for record in tqdm(data):
status = record['properties']['Status']['status']['name']
url = record['url']
article_id = record['id']
try:
title = record['properties']['Knowledge']['title'][0]['plain_text']
except IndexError:
title = ''
try:
author = record['properties']['Author']['created_by']['name']
except KeyError:
author = 'unknown'
try:
author_email = record['properties']['Author']['created_by']['person']['email']
except KeyError:
author_email = 'unknown'
create_time = record['properties']['CreateTime']['created_time']
tags = '&&'.join([x['name'] for x in record['properties']['Tag']['multi_select']])
article_ids.append(article_id)
all_titles.append(title)
authors.append(author)
create_times.append(create_time)
urls.append(url)
statuses.append(status)
tag_sets.append(tags)
author_emails.append(author_email)
# データフレーム化して保存
df = pd.DataFrame(
np.array([[i for i in range(len(all_titles))], all_titles, authors, author_emails, create_times, urls, article_ids, statuses, tag_sets]).T,
columns=[
'index', 'title', 'author',
'author_email', 'create_time', 'url',
'article_id', 'status', 'tags'
]
)
df.to_csv('notion_knowledges.csv', index=False, encoding='utf_8_sig')今回は継続的にドキュメント内容を更新させるわけではないので、上記のスクリプトのみとなっています。
実際に運用する場合は、差分を取りに行くlambda等を作成して更新するスクリプトを仕込む必要があります。
本記事では、構築するシステムの概要とAmazon Kendraに格納するドキュメントの収集をNotionから行いました。
次回の記事からは、Amazon KendraのベクトルDBに当たるIndexを作成していきます。
次回の記事もご一読頂けますと幸いです。
この記事では、#30DaysOfStreamlitの内容の紹介を行います。
#30DaysOfStreamlitについてはコチラの記事を参照してください。
この記事ではボタンウィジェットを理解します。
Streamlitは、データサイエンスや機械学習の分野で、Webアプリケーションを構築するためのPythonライブラリです。
Pythonを使った簡単なコーディングで、ユーザーインターフェースを作成し、データを可視化することができます。
以前、DataRobot、AWS SageMaker Canvas、Google Teachable Machine という3種のAutoMLツールについて学習したので、本記事ではそれらの機能などを比較したいと思います。
AWS SageMaker Canvas は AWS が提供する AutoMLツールです。本記事では、AWS SageMaker Canvas を使用してモデルを構築する方法に解説します。
Google Teachable Machine は、機械学習モデルを作成するための便利なツールです。本記事では、Google Teachable Machine の基本的な使い方を解説します。
みなさん、今日も元気にNotion使っていますか!
今回はNotionライトユーザの私が、社内記事をNotionへ一括で自動移行しようとしたらAPIの仕様のおかげで結構大変だった話をさせてください…

本記事では、Amazon Comprehendについて紹介していきます。
Amazon Comprehendとは、AWSで展開している自然言語解析ツールになります。
できる事としては、以下の機能を持ってます。(今回は日本語対応できている機能のみ使います。)
最近、M2 Macbook Airを入手したBudoこと荻本です。
この記事では、教師なし学習であるK-meansやその発展形のアルゴリズムについて調査を行ったので、いくつかの手法を紹介したいと思います。
教師なし学習の手法の一つです。
非階層クラスタリング手法であり、以下のような工程となります。
自然言語処理を行うにあたって文を単語毎に分け品詞を特定する形態素解析という処理があります。
この処理を行うことによりテキスト上で意味を持つ単語とそうでない単語を分けることができ、その結果を集計することがテキストマイニングの第一ステップと言えます。
日本語のみであれば、MeCabを利用する事で形態素解析が可能ですがシステムに組み込むとなると多言語対応が求められる事もあります。
その際に精度が良く、多言語対応可能なPythonライブラリを紹介したいと思います。
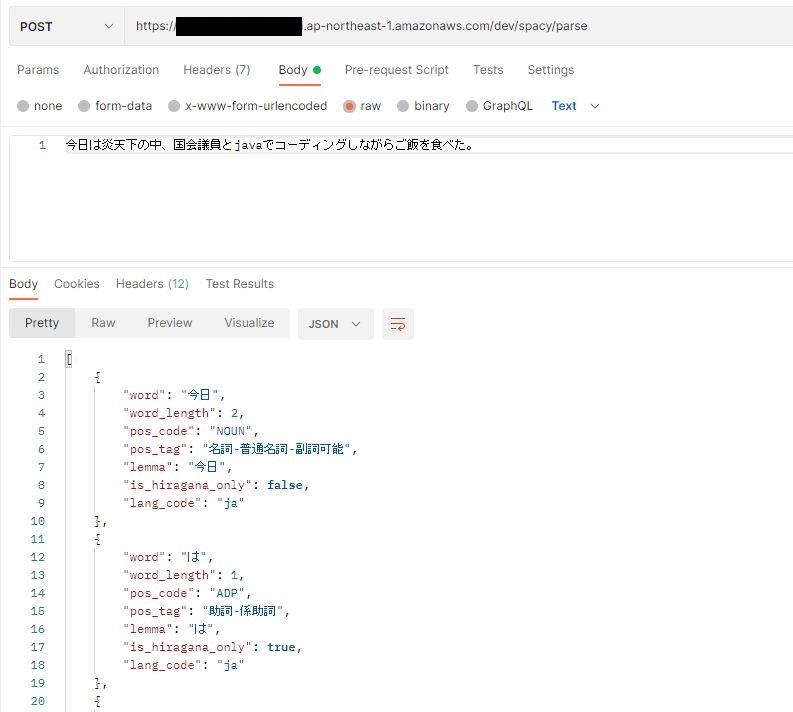
その名も「spaCy」です。
今回は、Serverless Frameworkを利用することやAWS CLIを利用してイメージ登録を行う為、事前に検証用のIAMユーザーを作成しております。
作成したユーザープロファイルは登録済みの状態です。
-3.png)
本記事は、2021/08/04(水)に登壇させていただいたSnowVillage生放送でのNLPパートの詳細解説記事になります。
生放送内では尺の都合上、紹介できなかった前処理やTF-IDFの解説を中心に紹介します。
SnowVillageとは...?
隔週水曜日にSnowflakeに関する情報発信を行っているアツいYoutubeチャンネルです。
Snowflakeはアメリカ・シリコンバレー 生まれのクラウド専用のデータコラボレーション基盤(Data Cloud)。日本では2020年から本格的に展開が進み、クラウドデータウェアハウス(DWH)やクラウドデータ基盤としての活用が始まっています。
以下、登壇時の動画を記載しますので、是非とも視聴していただけると幸いです。

DataRobotとは機械学習モデル作成を自動化するAIプラットフォームです。
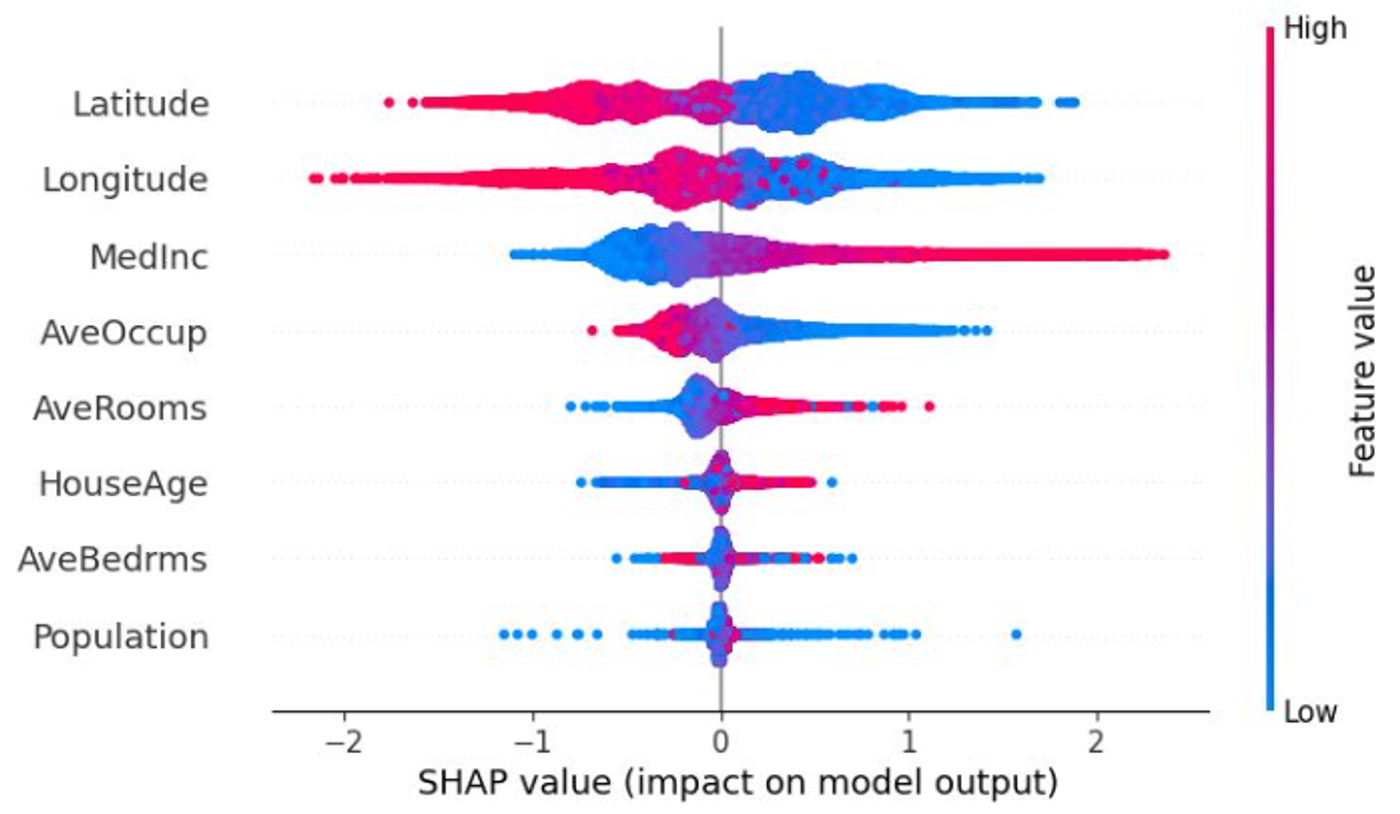
データの分析・モデル構築・システムへのデプロイまでを素早く行え、機械学習ソリューションにありがちな問題であるモデルの判定結果における要因解釈について、わかりやすく可視化も行えることが特徴です。
ここからは、実際の予測モデルを作成する流れを通して、各機能を紹介いたします。








{kind=link}
{kind=link}
{kind=link}
{kind=link}