


最初に
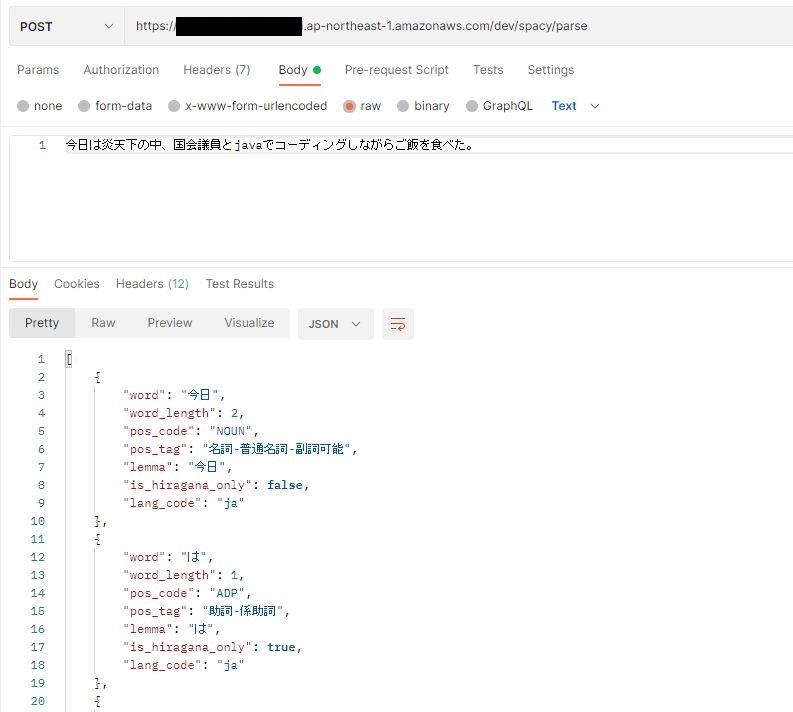
自然言語処理を行うにあたって文を単語毎に分け品詞を特定する形態素解析という処理があります。
この処理を行うことによりテキスト上で意味を持つ単語とそうでない単語を分けることができ、その結果を集計することがテキストマイニングの第一ステップと言えます。
日本語のみであれば、MeCabを利用する事で形態素解析が可能ですがシステムに組み込むとなると多言語対応が求められる事もあります。
その際に精度が良く、多言語対応可能なPythonライブラリを紹介したいと思います。
その名も「spaCy」です。
-3.png)



