こんにちは!2021年が後2ヶ月ぐらいで終わってしまうことに動揺を隠せないLeonです!
最近気温もガクっと下がってきて冬の雰囲気も近づいているなと感じてきますね。
体調管理に気をつけて引き続き頑張っていきましょう!
さて、今回は少し前になってしまいますが8月にAWSのGlue DataBrewというデータ準備サービスでTableau Hyper形式の出力が可能なったらしいです。。。
AWSに…TableauHyperが…?
マジかよ…これは確認してみるしかないな…ということで実際に触って確認してみます!
AWS Glue DataBrewとは?
公式サイトでは以下のように説明があります。
AWS Glue DataBrew は、事前構築済みの 250 以上の変換を使用して、コードを記述することなくデータを簡単にクリーニングし、正規化できるビジュアルデータ準備ツールです。外れ値の除外、標準形式へのデータの変換、無効な値の修正などのタスクを自動化することが可能です。
GUIでコード記載せずにデータクレンジングが行えるので
分析したいデータがあるけど加工できる環境が無いという方には良さげなサービスですね!
TableauDesktopでデータクレンジングする場合、
計算フィールドで関数など使って処理するかと思いますが
DataBrewを使って前もって処理しておくと項目がスッキリしてわかりやすく、Tableauの負荷軽減にも繋がると思います。
また1つのデータを複数人で使うと人によってデータの処理方法が違ってしまい
集計結果がそれぞれで違う…なんてことが発生する可能性がありますが
DataBrewで前もってデータ処理を行い共有するようにすればそういった事故を未然に防ぐことが可能になるのではと思います。
Hyper形式で出力してみる
早速DataBrewを使ってHyperを出力できるか試してみます!
プロジェクトの作成
まずはプロジェクトを作成します。
今回はサンプルデータでHyperを出力してみるので[サンプルプロジェクトを作成]をクリックします。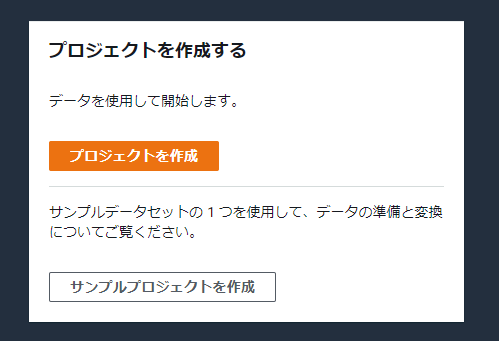
適当に国連総会投票の加盟国データを使ってみます。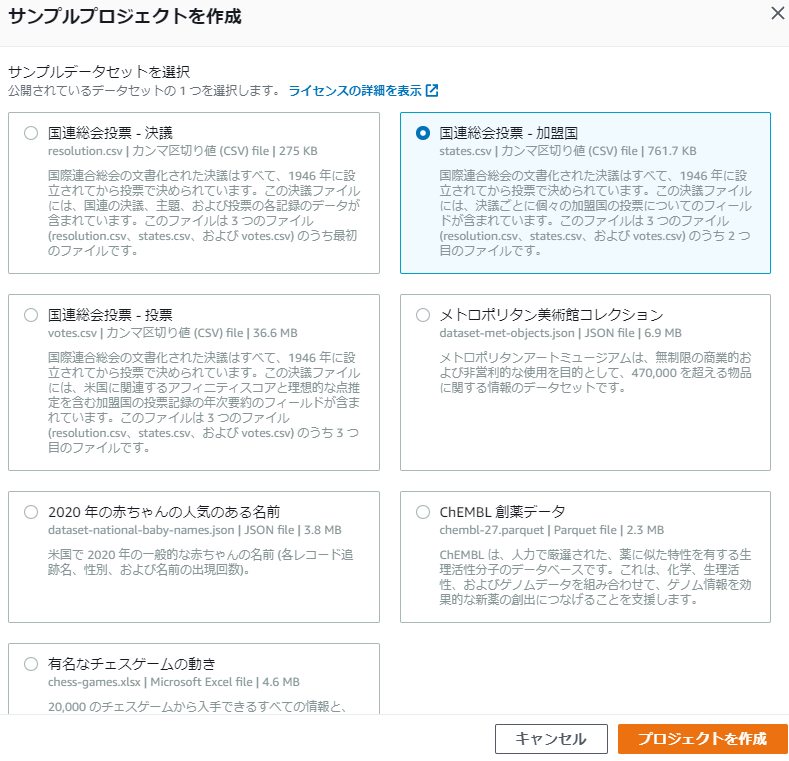
DataBrew用のロールを作成しプロジェクトを作成します。
プロビジョニングが開始されます!
諸々処理が終わると…
データの中身が見えました!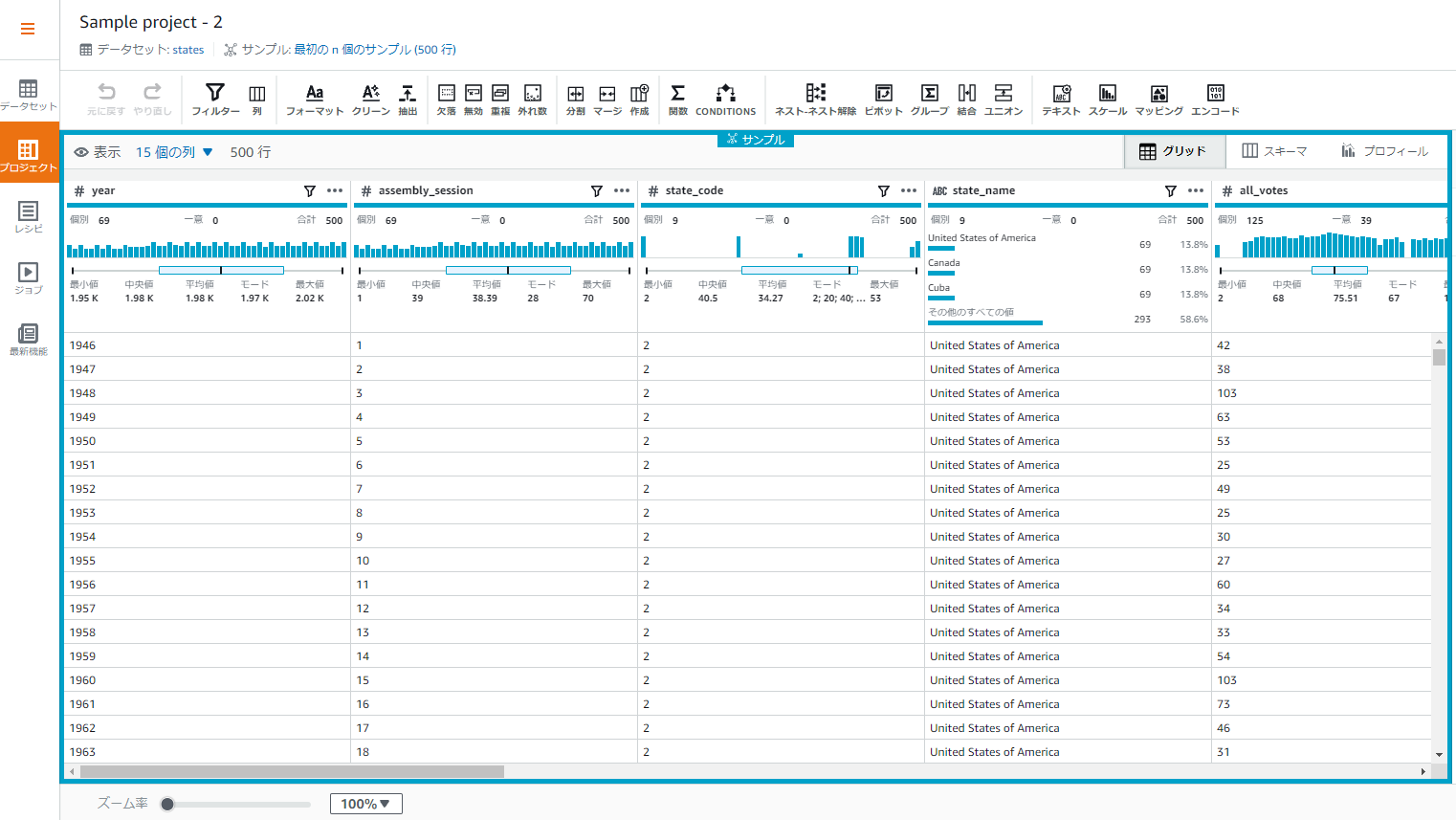
データ処理
今回Hyperが本当に出力できるかを確認することがメインなので
具体的な使い方についてのご紹介は省きます。。。
一応Hyperを出力するためには何か処理が必要になるため
[state_name]というカラムを大文字に変換してみます。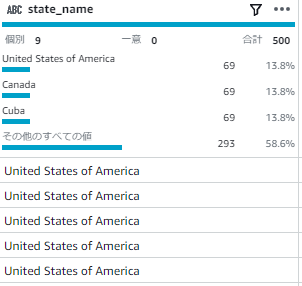
処理メニューにある[フォーマット]をクリックし[大文字に変更]をクリックすると右側にソース列などの指定が出来るようになるのでそちらで情報を選択します。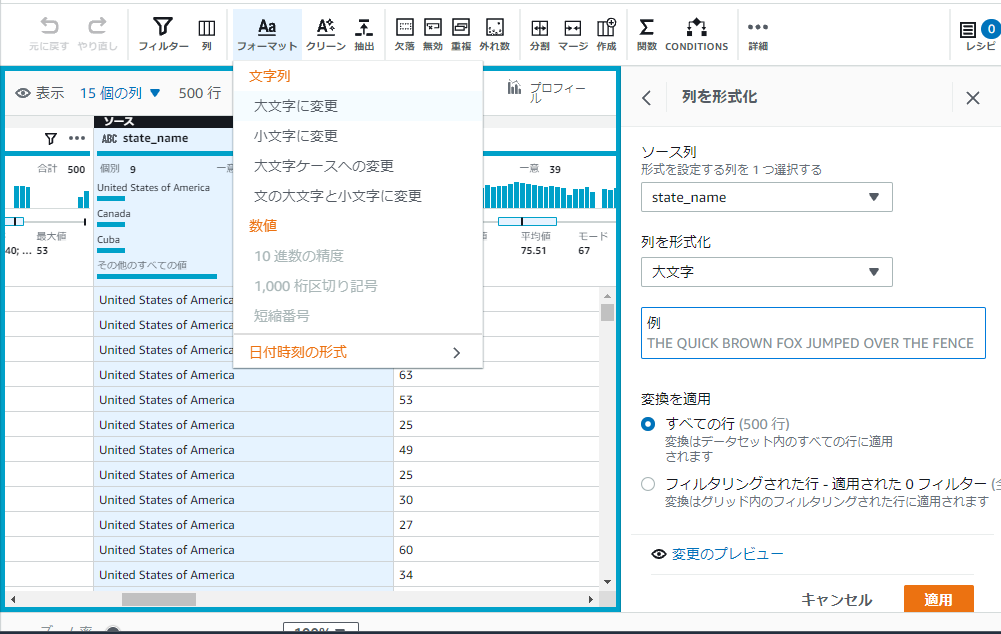
変更後どのようになるかプレビューしたい場合は[変更のプレビュー]をクリックすると内容が確認できます。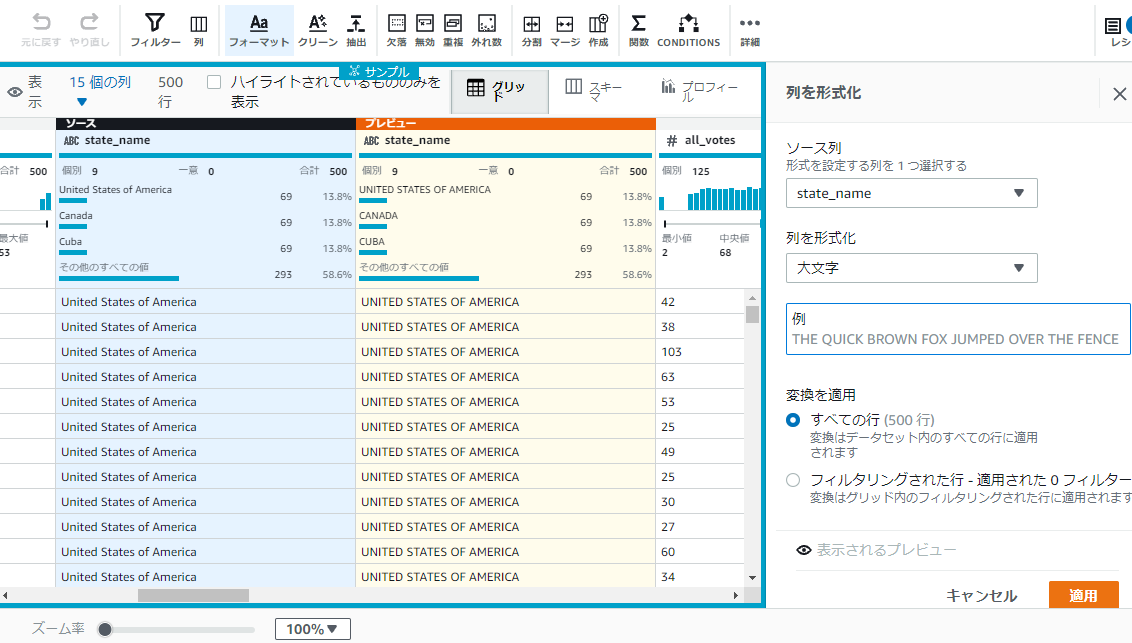
問題なく大文字に変換されてますね!
適用をクリックするとレシピに先程の処理が追加されます。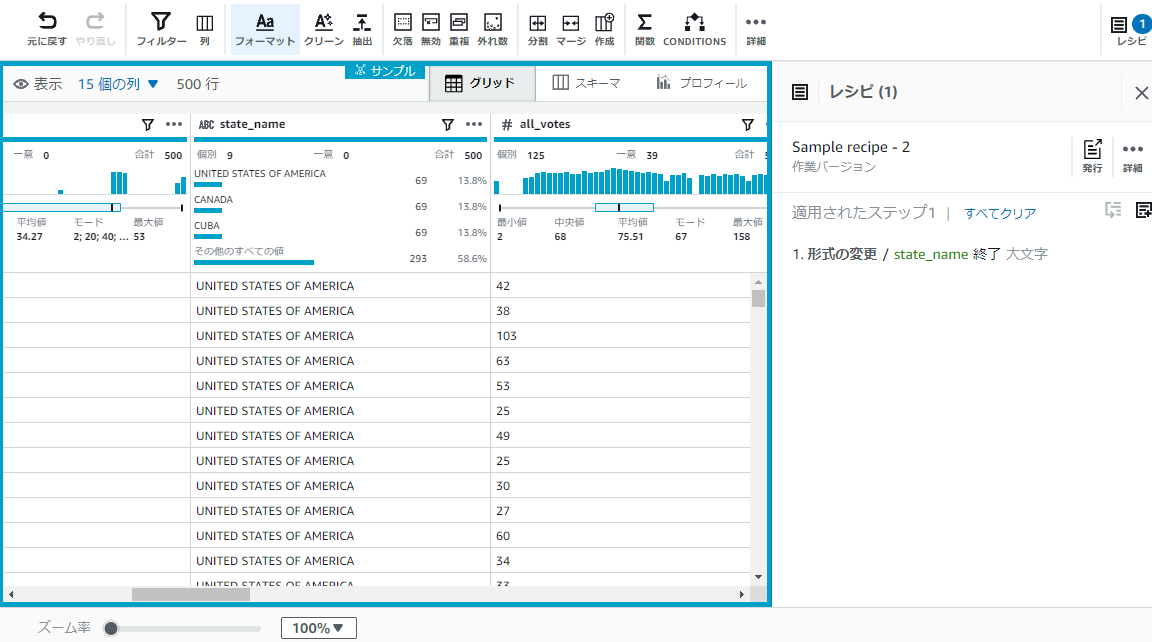
レシピの発行
念の為作成したレシピを発行しましょう。
レシピは処理の一覧のようなもので発行をすると処理のバージョンが作成されます。
バージョンの説明を記入し[発行]をクリックします。
現在のバージョンのレシピが発行されました。
ジョブ作成
それでは本題のHyperを出力するためジョブを作成します!
右上に[ジョブを作成]というボタンがあるのでそちらをクリックします。
[ジョブを作成]のページが開きます。
適当なジョブ名を記載しジョブ出力設定を確認します。
出力先にはS3のバケットが必要になりますので用意しておきましょう。
ファイルタイプをクリックしてみると…
お目当てのやつがありました!!本当にいます!!AWSに!!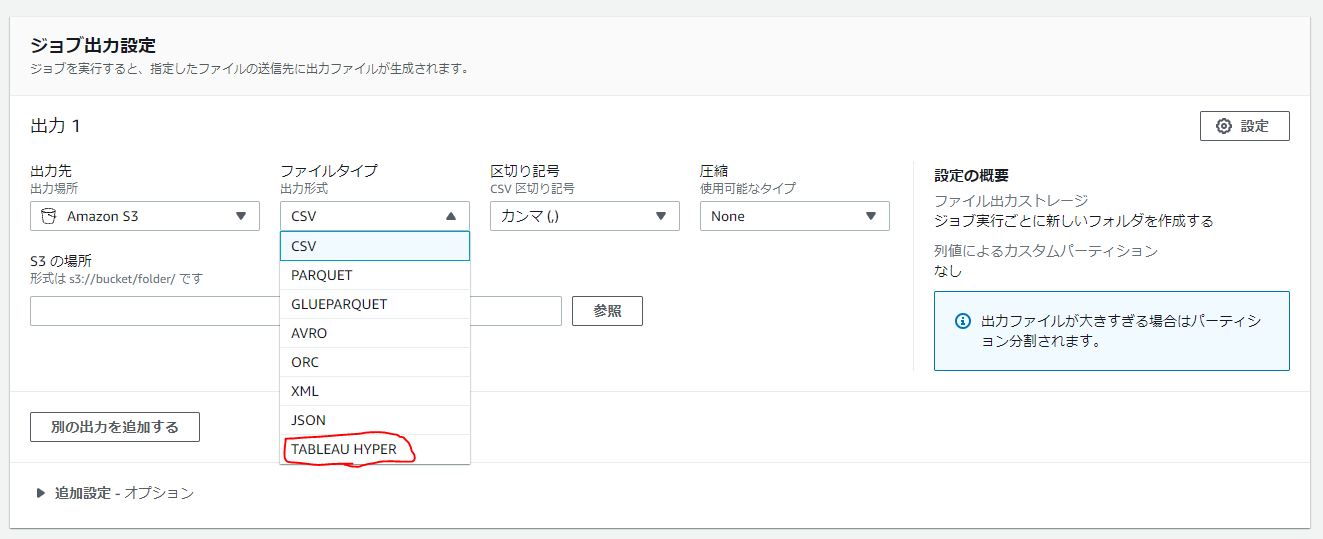
ファイルタイプで[TABLEAU HYPER]を選択し、
S3の場所で出力したいバケットを選択します。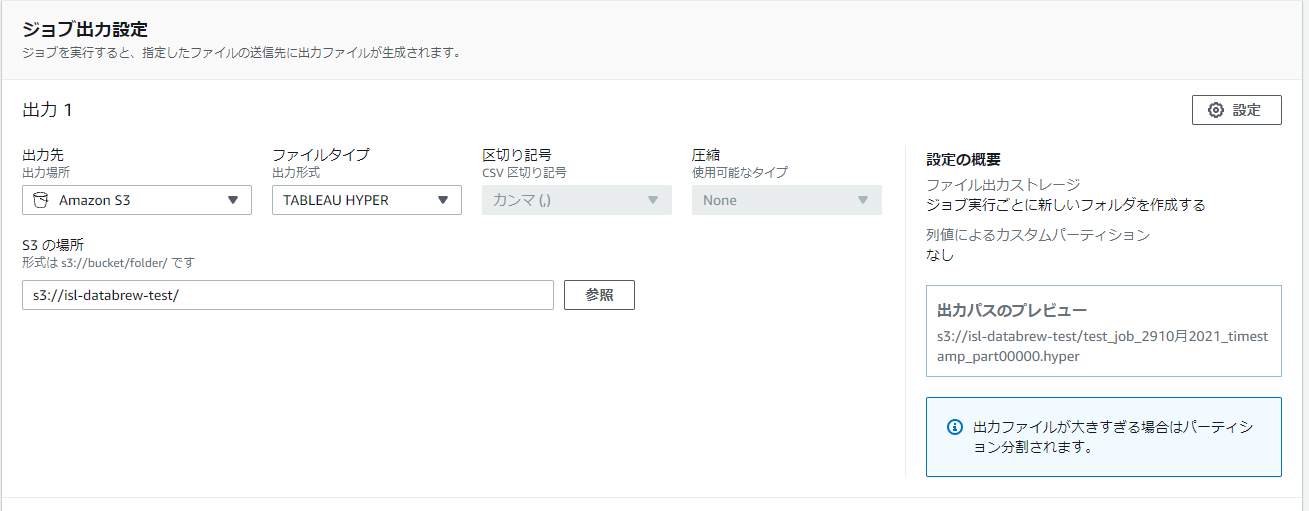
もちろんジョブなのでスケジュール設定も可能です。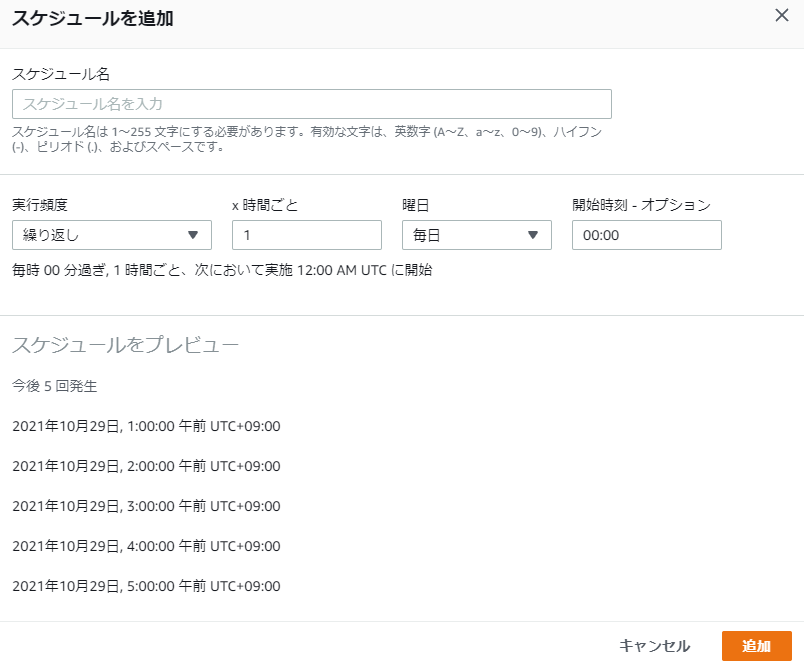
定期的に処理を実行してデータを出力したい場合に便利ですね。
これで概ね設定は完了です。
アクセス許可等設定し[ジョブを作成し実行する]をクリックします。
左側のメニューの[ジョブ]から実行履歴を確認できます。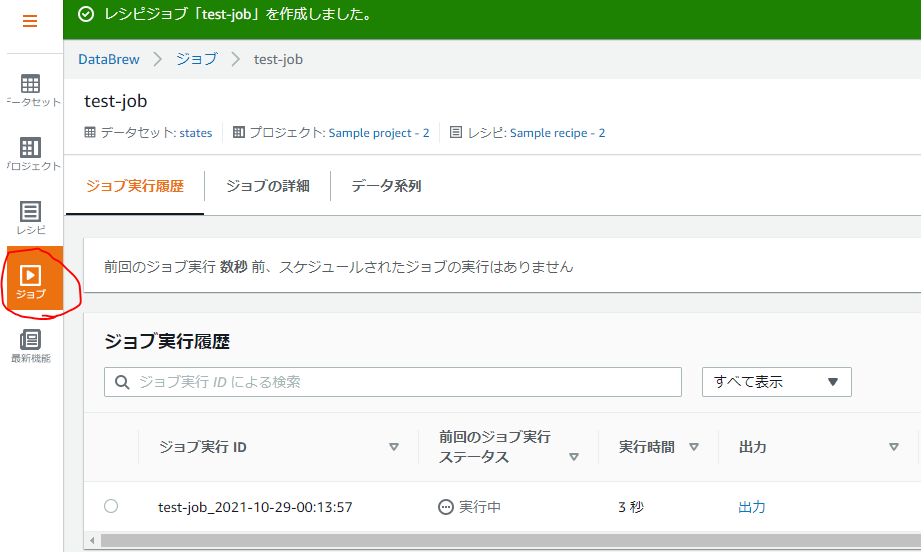
暫く待つと…
成功し、出力されたようです!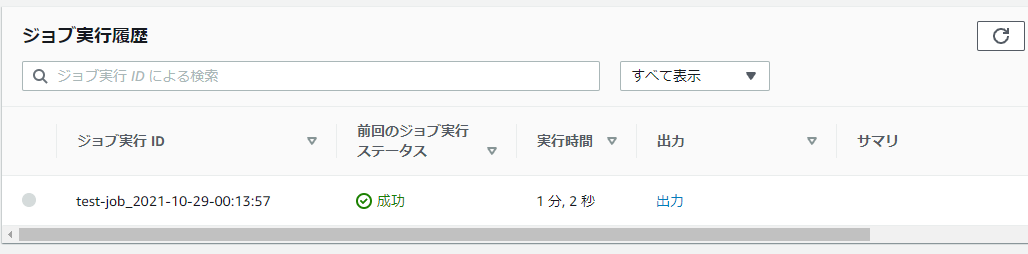
出力先のS3を確認すると出力されていたのでダウンロードしてみます。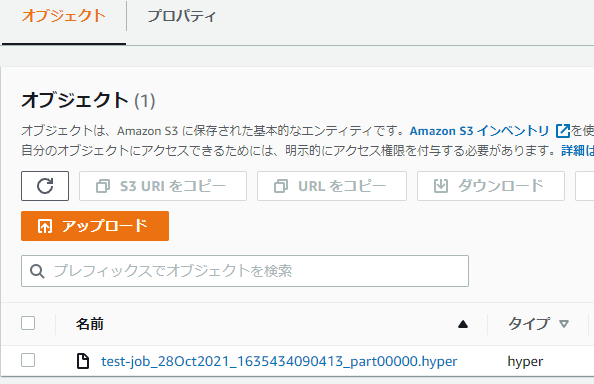
ちゃんとhyperだ…
実際にTableauで読み込んでみたところ…
ちゃんと読み込めました!Tableau抽出でStateNameも大文字になっています!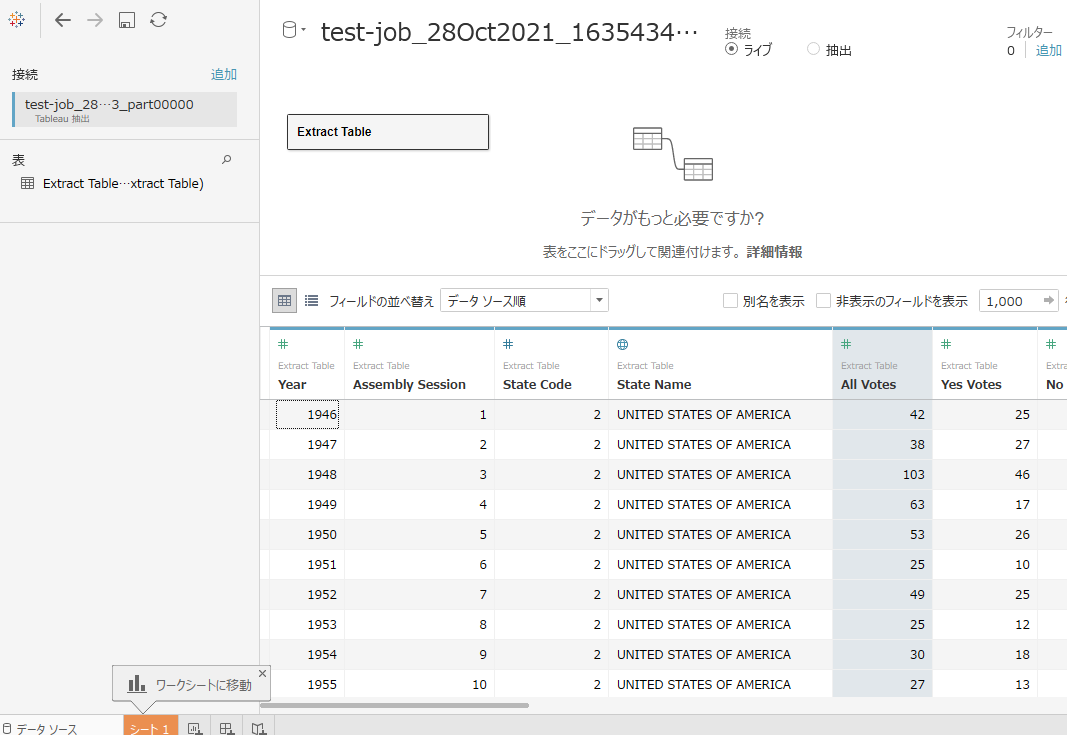
料金
利用される方は必ず料金について確認しておきましょう。
公式によると
AWS Glue DataBrew を使用すると、ジョブの実行時にデータのクリーンアップと正規化に使用した時間に対してのみ料金が発生します。ジョブの実行に使用された AWS Glue DataBrew ノードの数に基づいて 1 時間ごとの料金が請求されます。デフォルトでは、AWS Glue DataBrew は各ジョブに 5 ノードを割り当てます。AWS Glue DataBrew ジョブの請求期間は 1 分です。
単一の AWS Glue DataBrew ノードは、4 つの vCPU と 16 GB のメモリを提供します。リソースの管理や初期費用は不要で、スタートアップ時間やシャットダウン時間も課金されません。
ということで実際のTokyoの料金は
0.48USD/DataBrew ノード時間
なります。
詳しくは公式サイトでご確認ください。
このノードという部分がジョブ設定のアドバンスドジョブ設定に関わってきます。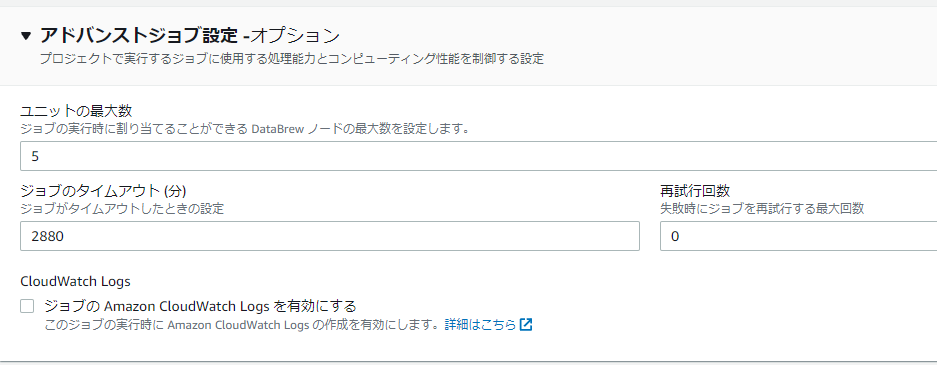
ユニットの最大数というところでノードの最大数を設定できます。
処理によって料金面を考慮しながらノード数を変えることが可能です。
終わりに
無事DataBrewを使ってTableauHyperを出力することができました。
AWS Glue DataBrewはブラウザ上でコードを書かずにデータ処理を作成でき、スケジュール実行できるジョブもあるため手軽に処理を作りたい方には扱いやすいサービスだと思います。
ちなみに出力先やデータソースはS3以外にもAmazon RedshiftやSnowflakeなどを選択することができるので色々な使い方ができそうなDataBrewでした。
気になる方は実際に触ってみてどのような処理ができるのか是非お試しください!
データ利活用のプロに相談してみませんか?
INSIGHT LABでは、Tableauだけではなく、他BI製品含めたご相談を承っております。導入済みのお客様からのご相談も多く頂いております。お気軽に以下よりご相談ください。

-3.png)